
# 混合搜索
注意
本指南仅适用于 DB 版本 1.6.2 或更高版本。
本指南介绍了如何在 MyScale 中执行全文和向量混合搜索。
全文搜索 和 向量搜索 各有其优势和劣势。全文搜索适用于基本的关键字检索和文本匹配,而向量搜索在跨文档语义匹配和深度语义理解方面表现出色,但在短文本查询方面可能缺乏效率。混合搜索结合了两种方法的优点,提高了文本搜索的准确性和速度,以满足用户对精确结果的期望。
# 教程概述
本指南涵盖以下内容:
- Wikipedia 数据集 和用于混合搜索的嵌入模型。
- 创建表 和 构建索引 的说明。
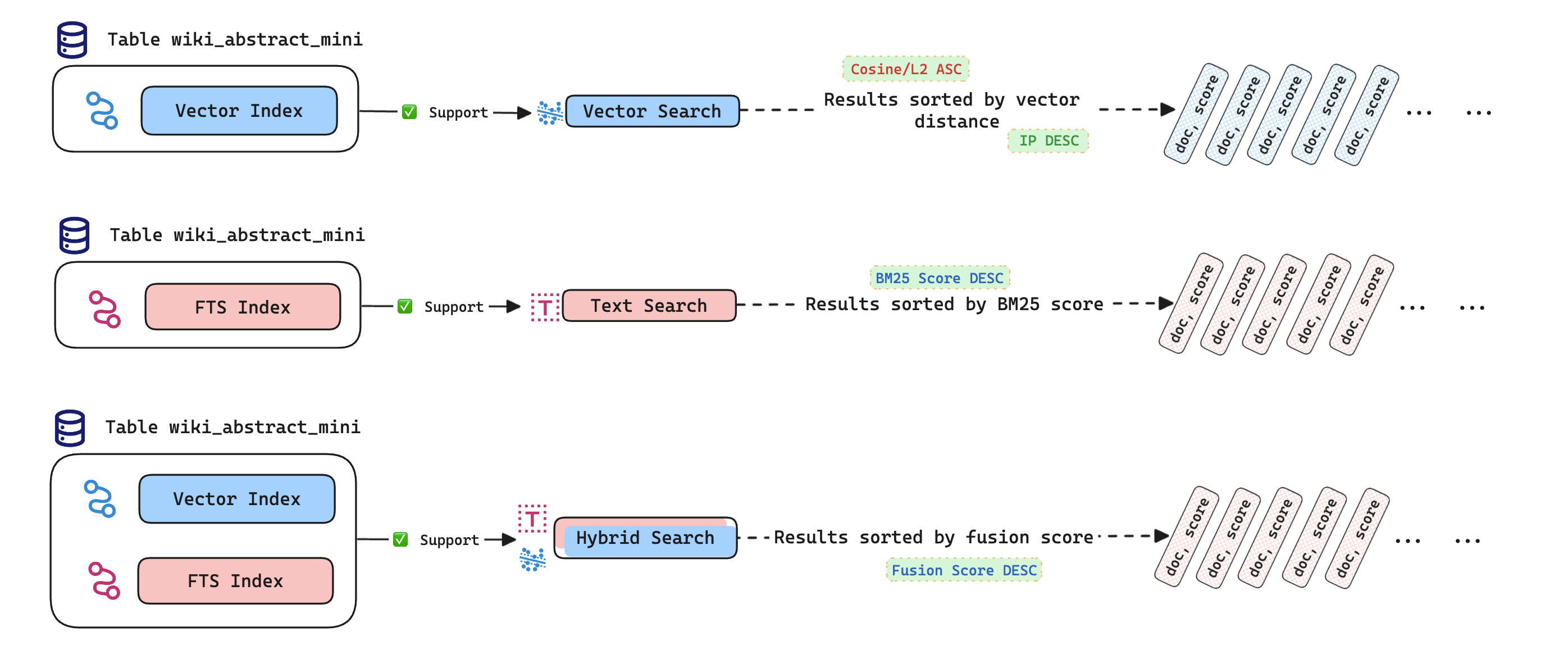
- 如何使用
HybridSearch()函数。 - 执行 向量、文本和混合搜索 的示例。
HybridSearch() 函数将向量搜索和文本搜索的结果进行组合,提高了在不同场景下的适应性,并提高了搜索准确性。
在开始之前,请确保已设置好 MyScale 集群。有关设置说明,请参阅我们的 快速入门指南 (opens new window)。
# 数据集
该实验使用了由 RediSearch 提供的 Wikipedia 摘要数据集 (opens new window),包含 5,622,309 个文档条目。我们选择了前 100,000 个条目,并使用 multilingual-e5-large (opens new window) 模型对其进行处理,创建了存储在 body_vector 列中的 1024 维向量。使用余弦距离计算向量之间的相似度。
提示
有关如何使用 multilingual-e5-large 的更多信息,请参阅 HuggingFace 的文档 (opens new window)。
数据集 wiki_abstract_100000_1024D.parquet (opens new window) 的大小为 668MB,包含 100,000 个条目。您可以在不需要将其下载到本地的情况下预览其内容,因为我们将在后续实验中直接通过 S3 导入到 MyScale 中。
| id | body | title | url | body_vector |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
| 78 | A total solar ... the Sun for a viewer on Earth. | Solar eclipse of November 12, 1985 | https://en.wikipedia.org/wiki/Solar_eclipse_of_November_12,_1985 (opens new window) | [1.4270141,...,-1.2265089] |
| 79 | Dhamangaon Badhe is a town ... Aurangabad districts. | Dhamangaon Badhe | https://en.wikipedia.org/wiki/Dhamangaon_Badhe (opens new window) | [0.6736672,....,0.12504958] |
| ... | ... | ... | ... | ... |
# 创建表和导入数据
在 MyScale 的 SQL 工作区中创建名为 wiki_abstract_mini 的表,执行以下 SQL 语句:
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 1024
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
从 S3 导入数据到表中。在数据导入过程中,请耐心等待。
INSERT INTO default.wiki_abstract_mini
SELECT * FROM s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/wiki_abstract_100000_1024D.parquet', 'Parquet');
注意
数据导入的预计时间约为 10 分钟。
通过运行以下查询验证表中是否有 100,000 行数据:
SELECT count(*) FROM default.wiki_abstract_mini;
输出:
| count() |
|---|
| 100000 |
# 构建索引
# 创建 FTS 索引
提示
要了解如何创建 FTS 索引,请参阅 文本搜索文档。
在设置 FTS 索引时,用户可以选择自定义分词器。在本示例中,我们使用 stem 分词器,并应用了停用词。stem 分词器可以忽略文本中的词态,以获得更精确的搜索结果。通过使用停用词,可以过滤掉常见词,如 "a"、"an"、"of" 和 "in",以提高搜索准确性。
ALTER TABLE default.wiki_abstract_mini
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
执行索引的物化:
ALTER TABLE default.wiki_abstract_mini MATERIALIZE INDEX body_idx;
# 创建向量索引
提示
有关 MSTG 向量索引的更多信息,请参阅 向量搜索文档。
要在 default.wiki_abstract_mini 表上创建 MSTG 向量索引,使用余弦距离,运行以下 SQL 语句:
ALTER TABLE default.wiki_abstract_mini
ADD VECTOR INDEX body_vec_idx body_vector
TYPE MSTG('metric_type=Cosine');
构建向量索引可能需要一些时间。要监视其进度,请运行以下 SQL 查询。如果状态列显示 Built,则索引已成功创建。如果显示 InProgress,则表示进程仍在进行中。
SELECT * FROM system.vector_indices;
# HybridSearch 函数
MyScale 的 HybridSearch() 函数通过组合向量搜索和文本搜索的结果来执行混合搜索,返回前几个候选结果。基本语法如下:
HybridSearch('dense_param1 = value1', 'param2 = value2')(vector_column, text_column, query_vector, query_text)
params:搜索特定参数。以dense_开头的参数用于向量搜索。例如,dense_alpha设置 MSTG 向量索引的alpha参数。vector_column:包含要搜索的向量数据的列。text_column:包含要搜索的文本数据的列。query_vector:要搜索的向量。query_text:要搜索的文本。
使用 HybridSearch 函数与 ORDER BY 子句和 LIMIT 子句一起使用,以检索前几个候选结果。ORDER BY 子句中的列的排序方向必须设置为 DESC。
# HybridSearch 参数说明
下面是对 HybridSearch() 参数的详细说明:
| Parameter | Default Value | Candidate Values | Description |
|---|---|---|---|
fusion_type | N/A | rsf, rrf | Determines the combination method in hybrid search. rsf stands for Relative Score Fusion, and rrf stands for Reciprocal Rank Fusion. This parameter is required. |
fusion_weight | 0.5 | Floating point number between 0 - 1 | Specifies the weight |
fusion_k | 60 | Positive integer no less than 1 | Specifies the sorting constant |
enable_nlq | true | true, false | Indicates whether to use natural language queries in text search. |
operator | OR | OR, AND | Specifies the logical operator used to combine terms in text search. |
# 融合类型
混合搜索将文本搜索的 BM25 分数(表示为
- 相对分数融合(RSF):在 RSF 中,向量搜索和文本搜索的分数在 0 到 1 之间进行归一化。最高原始分数设置为 1,最低原始分数设置为 0,所有其他值在此范围内按比例排名。最终分数是这些归一化分数的加权和:
使用的归一化公式为:
- 倒数排名融合(RRF):RRF 不需要分数归一化。相反,它根据每个结果集中的位置对结果进行排名,使用以下公式,其中
# 执行向量、文本和混合搜索
# 创建嵌入函数
为了将查询文本转换为向量,我们将使用 multilingual-e5-large (opens new window) 模型。
通过 MyScale 的嵌入函数,在线将文本转换为向量非常简单。我们将为此目的创建一个名为 MultilingualE5Large 的嵌入函数。
提示
您需要从 HuggingFace 获取一个免费密钥才能创建嵌入函数。
CREATE FUNCTION MultilingualE5Large
ON CLUSTER '{cluster}' AS (x) -> EmbedText (
concat('query: ', x),
'HuggingFace',
'https://api-inference.huggingface.co/models/intfloat/multilingual-e5-large',
'<your huggingface key, starts with `hf_`>',
''
);
# 执行向量搜索
提示
英国格雷厄姆陆地探险队(BGLE)是一支英国探险队。有关他们的详细信息,请参阅 维基百科 (opens new window)。
向量搜索通常在长文本领域表现良好,但在短文本领域可能效果下降。为了说明在不同文本长度的情况下搜索性能,我们将呈现两个向量搜索的示例。我们要搜索的内容与 BGLE 探险队标记的位置有关,两个句子之间的区别在于是否使用了队伍的名称缩写。
- 示例 1. 长文本查询:'Charted by the British Graham Land Expedition'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Charted by the British Graham Land Expedition')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
从下面的搜索结果可以看出,向量搜索在匹配长文本方面表现出色,前五个搜索结果中有四个符合我们的条件。
| id | title | body | score |
|---|---|---|---|
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.17197883 |
| 16459 | Link Stack | Link Stack () is a rocky pillar at the northwest end of Chavez Island, off the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37. | 0.17324567 |
| 47359 | Huitfeldt Point | Huitfeldt Point is a point southeast of Vorweg Point on the southwest side of Barilari Bay, on the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37, and was named by the UK Antarctic Place-Names Committee in 1959 for Fritz R. | 0.17347288 |
| 48138 | Santos Peak | Santos Peak () is a peak lying south of Murray Island, on the west coast of Graham Land. Charted by the Belgian Antarctic Expedition under Gerlache, 1897-99. | 0.17546016 |
| 15482 | Parvenu Point | Parvenu Point () is a low but prominent point forming the north extremity of Pourquoi Pas Island, off the west coast of Graham Land. First surveyed in 1936 by the British Graham Land Expedition (BGLE) under Rymill. | 0.17611909 |
- 示例 2. 短文本查询:'Charted by the BGLE'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Charted by the BGLE')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
然而,当检查短文本的搜索结果时,可以明显看出向量搜索在这个领域的效果较差,前五个文档中没有一个包含任何关于 BGLE 的信息。
| id | title | body | score |
|---|---|---|---|
| 17693 | Têtes Raides | | current_members = Christian OlivierGrégoire SimonPascal OlivierAnne-Gaëlle BisquaySerge BégoutÉdith BégoutPierre GauthéJean-Luc MillotPhilippe Guarracino | 0.19922233 |
| 92351 | Badr al-Din Lu'lu' | right|thumb|250px|Badr al-Din Lu'lu', manuscript illustration from the Kitāb al-Aghānī of [[Abu al-Faraj al-Isfahani (Feyzullah Library No. 1566, Istanbul). | 0.19949186 |
| 45934 | Singing All Along | |show_name_2=|simplified=|pinyin=Xiùlì Jiāngshān Zhī Cháng Gē Xíng|translation=Splendid and Beautiful Rivers and Mountains: Long Journey of Songs}} | 0.2003029 |
| 44708 | LinQ | | current_members =Yumi TakakiSakura ArakiAyano YamakiMYUChiaki Sara YoshikawaRana KaizukiAsaka SakaiKana FukuyamaManami SakuraMaina KohinataChisa Ando | 0.20089924 |
| 43706 | Shorty (crater) | | diameter = 110 mShorty, Gazetteer of Planetary Nomenclature, International Astronomical Union (IAU) Working Group for Planetary System Nomenclature (WGPSN) | 0.20098251 |
# 执行文本搜索
BM25 是一种广泛使用的文本搜索算法,非常成熟,特别适用于短文本匹配。然而,当涉及到理解长文本的语义时,BM25 的效果不如向量搜索。以下示例演示了 TextSearch() 在短文本领域的强大搜索能力。
- 示例. 短文本查询:'Charted by the BGLE'
SELECT
id,
title,
body,
TextSearch(body, 'Charted by the BGLE') AS bm25_score
FROM default.wiki_abstract_mini
ORDER BY bm25_score DESC
LIMIT 5;
| id | title | body | bm25_score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.392099 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
| 49006 | Somers Glacier | Somers Glacier () is a glacier flowing northwest into Trooz Glacier on Kiev Peninsula, the west coast of Graham Land. First charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
# 执行混合搜索
MyScale 提供了 HybridSearch() 函数,这是一种结合了向量搜索和文本搜索优势的搜索方法。这种方法不仅增强了对长文本语义的理解,还解决了向量搜索在短文本领域的语义缺陷。
- 示例. 短文本查询:Charted by the BGLE
SELECT
id,
title,
body,
HybridSearch('fusion_type=RSF', 'fusion_weight=0.6')(body_vector, body, MultilingualE5Large('Charted by the BGLE'), ' BGLE') AS score
FROM default.wiki_abstract_mini
ORDER BY score DESC
LIMIT 5;
根据从 HybridSearch() 函数获得的结果,即使在搜索短文本时,我们也可以获得出色的搜索结果,大大提高了准确性。
| id | title | body | score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.6 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 49000 | Sooty Rock | Sooty Rock () is a rock midway between Lumus Rock and Betheder Islands in Wilhelm Archipelago. Discovered and named "Black Reef" by the British Graham Land Expedition (BGLE), 1934-37. | 0.5404912 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.4274415 |
从DB版本v1.8或更高版本开始,HybridSearch()函数中允许从多列FTS索引中搜索某个文本列。
# 在数据库外执行混合搜索
我们还可以在数据库外部利用 Python 中的 ranx (opens new window) 库将向量搜索和文本搜索结果进行组合,实现 RRF 融合策略(Reciprocal Rank Fusion)以提高搜索准确性。对于其他融合策略,您可以参考 ranx/fusion (opens new window)。
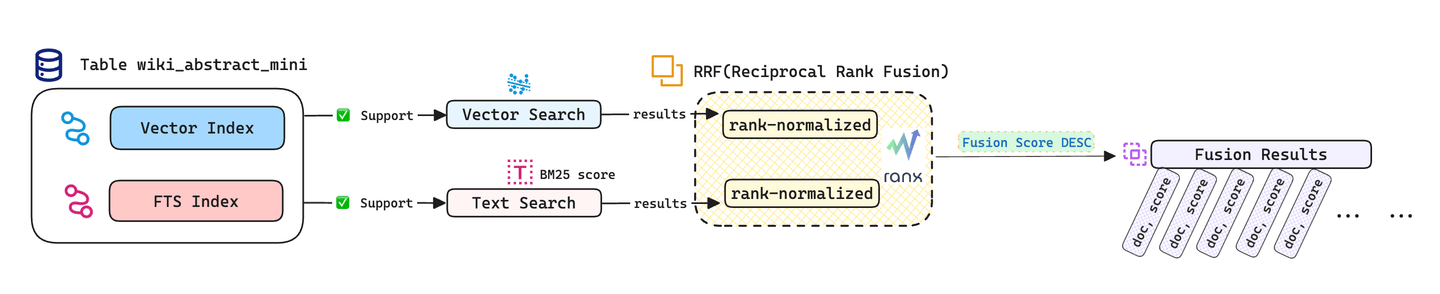
在运行下面的演示代码之前,您应该安装 ranx:
pip install -U ranx
Python 示例代码:
import clickhouse_connect
from numba import NumbaTypeSafetyWarning
from prettytable import PrettyTable
from ranx import Run, fuse
from ranx.normalization import rank_norm
import warnings
warnings.filterwarnings('ignore', category=NumbaTypeSafetyWarning)
# MyScale 信息
host = "your cluster end-point"
port = 443
username = "your user name"
password = "your password"
database = "default"
table = "wiki_abstract_mini"
# 初始化 MyScale 客户端
client = clickhouse_connect.get_client(host=host, port=port, username=username, password=password)
# 使用表输出内容
def print_results(result_rows, field_names):
x = PrettyTable()
x.field_names = field_names
for row in result_rows:
x.add_row(row)
print(x)
# 我们要搜索一个短文本。
terms = "Charted by BGLE"
# 执行 VectorSearch。
vector_search = f"SELECT id, title, body, distance('alpha=3')" \
f"(body_vector, MultilingualE5Large('{terms}')) AS distance FROM {database}.{table} " \
f"ORDER BY distance ASC LIMIT 100"
vector_search_res = client.query(query=vector_search)
# 执行 TextSearch。
text_search = f"SELECT id, title, body, TextSearch(body, '{terms}') AS score " \
f"FROM {database}.{table} " \
f"ORDER BY score DESC LIMIT 100"
text_search_res = client.query(query=text_search)
# 提取 VectorSearch 和 TextSearch 结果。
stored_data = {}
for row in vector_search_res.result_rows:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
for row in text_search_res.result_rows:
if str(row[0]) not in stored_data:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
# 从结果中提取 id 和 score。
bm25_dict = {"query-0": {str(row[0]): float(row[3]) for row in text_search_res.result_rows}}
# 对于 ranx 库,预期较高的分数表示更高的相关性,
# 因此需要对向量距离计算方法(如余弦和 L2)进行预处理。
max_value = max(float(row[3]) for row in vector_search_res.result_rows)
vector_dict = {"query-0": {str(row[0]): max_value - float(row[3]) for row in vector_search_res.result_rows}}
# 标准化查询结果分数。
vector_run = rank_norm(Run(vector_dict, name="vector"))
bm25_run = rank_norm(Run(bm25_dict, name="bm25"))
# 使用 RRF 融合查询结果。
combined_run = fuse(
runs=[vector_run, bm25_run],
method="rrf",
params={'k': 10}
)
print("\nFusion results:")
pretty_results = []
for id_, score in combined_run.get_doc_ids_and_scores()[0].items():
if id_ in stored_data:
pretty_results.append([id_, stored_data[id_]["title"], stored_data[id_]["body"], score])
print_results(pretty_results[:5], ["ID", "Title", "Body", "Score"])
融合查询结果如下:混合搜索准确匹配了与 BGLE 探险队标记的位置相关的五篇文章,展示了混合搜索在处理短文本查询时的优势。
| ID | Title | Body | Score |
|---|---|---|---|
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.06432246998284734 |
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.049188640973630834 |
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.047619047619047616 |
| 64566 | Want You Back (Haim song) | format=Digital download | recorded= |
| 45934 | Singing All Along | show_name_2= |
# 结论
本文提供了关于使用MyScale混合搜索的用法的见解,重点关注搜索非结构化文本数据的方法和技术。在实际练习中,我们使用维基百科摘要开发了一个示例。通过结合关键词和语义信息,使用MyScale的高级全文和向量搜索功能进行混合搜索非常容易,并且可以获得更准确的结果。
 京公网安备 11010802042981号
京公网安备 11010802042981号