
# 介绍MyScale
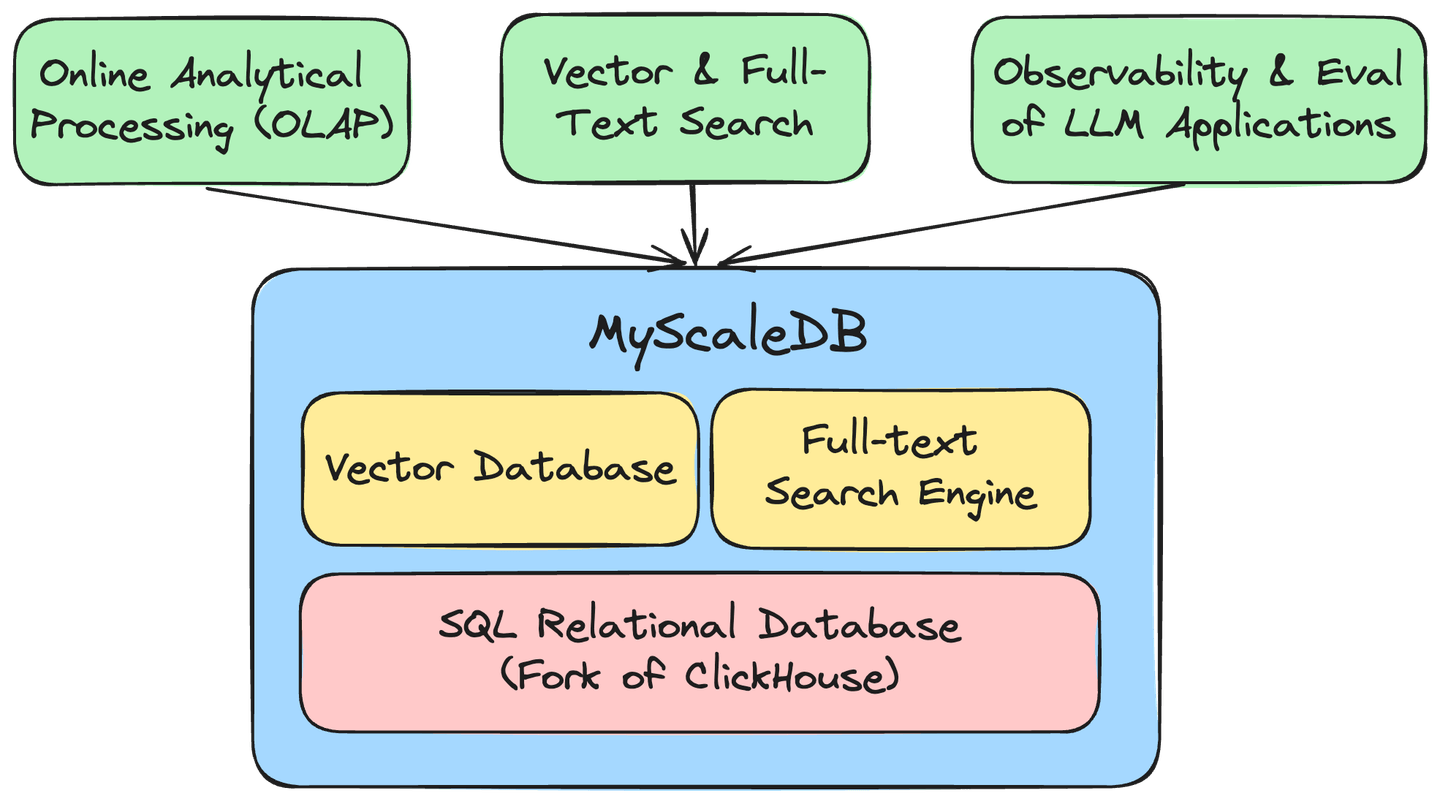
MyScale是一个基于云的数据库,针对 AI 应用和解决方案进行了优化,建立在开源的 ClickHouse 数据库上,使我们能够有效管理大量的结构化和向量数据,以开发强大的 AI 应用。使用 MyScale 的一些最显著优势包括:
- 为AI应用而建立: 在单一平台上管理和支持结构化和向量化数据的分析处理。
- 为性能而建立: 先进的OLAP数据库架构,以惊人的速度对向量化数据进行操作。
- 为普遍可访问性而建立: SQL是与MyScale交互所需的唯一编程语言。
与其他产品/平台的定制API相比,MyScale更易于使用,因此适合庞大的程序员社区。MyScale通过其成本效益高的数据管理支持、出色的线性可扩展性和标准SQL支持,消除了需要使用多种昂贵的数据仓库产品的必要性,这些产品需要不同的查询语言。在单一界面中,SQL查询可以同时快速利用不同的数据模式,以处理复杂的AI需求,而这些需求通常需要更多的步骤和时间。
MyScale的专有MSTG向量引擎利用NVMe SSD将数据密度提高了10倍。这一进步使MyScale在性能和成本效益方面均能超越最专业的向量数据库 (opens new window)4到10倍。包含的全文搜索(FTS)索引无缝集成了高性能文本搜索功能,使MyScale成为ElasticSearch的高效升级 (opens new window)。此外,MyScale Telemetry (opens new window)为LLM系统提供了全面的可观测性,确保了无缝的监控和高效的调试。
通过将SQL数据库/数据仓库、向量数据库和全文搜索引擎的功能集成到一个高效的系统中,MyScale显著降低了基础设施和维护成本。这种统一不仅促进了联合数据查询和分析,还建立了一个对所有AI应用至关重要的强大而多功能的数据基础。
# 关键概念
MyScale能够基于以下关键概念在不同的数据模态之间执行快速准确的查询。
# 相似度度量
衡量两个数据对象之间语义相似性的方法有两种不同的方法:
- 单模态(图像-图像或文本-文本): 单模态相似度衡量相同数据类型的对象之间的语义相似性。
- 多模态(图像-文本): 多模态相似度衡量不同数据类型的对象之间的语义相似性。
两个数据对象之间的语义相似性可以用一个称为相似度度量的分数来表示。选择一个好的相似度度量来表示大量对象的语义相似性对于MyScale中的数据分类和聚类性能至关重要。
选择一个好的相似度度量来表示大量对象的语义相似性对于MyScale中的数据分类和聚类性能至关重要。其中三个较流行的度量包括:
- 欧氏距离(L2): L2在计算机视觉应用中常用。
- 内积(IP): IP在自然语言处理(NLP)应用中最常用。
- 余弦相似度: 与IP不同,余弦相似度只比较规范化数据上的“角度”上的差异,而不考虑表示两个对象之间的向量的“大小”和“角度”。
# 搜索算法
嵌入向量(或向量)是一个对象、概念或实体在多维空间中的数值表示。它通常用于表示自然语言处理(NLP)文本、物联网传感器数据、社交媒体照片、生物和化学结构或其他数据对象,以捕捉它们的语义关系和附加的上下文信息。
嵌入向量旨在捕捉数据的有意义的特征或特性,以较低维度的方式表示数据,使机器学习算法更容易处理和分析数据。
提示
现代嵌入技术用于将非结构化数据转换为向量,将高维数据转换为更紧凑和结构化的形式。
为了比较两个对象之间的语义相似性,您需要向MyScale数据库提供一个查询向量。然后,MyScale使用近似最近邻(ANN)等搜索算法,快速准确地返回与查询向量相似的向量列表。
# 使用SQL与MyScale
与Pinecone、Milvus、Qdrant和Weaviate等专有向量数据库不同,MyScale是基于开源的与SQL兼容的ClickHouse数据库构建的。这样做有几个原因,包括:
- 通过利用ClickHouse成熟的代码库和生态系统,我们可以为用户提供功能丰富的数据库。
- SQL被广泛用于管理关系数据库。借助MyScale的SQL支持,开发人员和数据分析师可以利用他们现有的知识和技能,更容易地集成和使用。
- SQL支持广泛的数据操作、查询和报告功能。因此,由于MyScale与SQL完全兼容,用户可以以许多不同的方式执行复杂的查询和分析数据。
- 由于MyScale构建在ClickHouse之上,它不仅为向量搜索提供快速和可扩展的性能,还为过滤向量搜索和复杂的SQL加向量查询(例如将向量搜索结果与另一个表连接)提供了快速和可扩展的性能。
# 这为什么重要?
随着复杂数据的指数增长,需要能够处理新的数据模态、数据库大小和查询答案的挑战的未来解决方案。虽然这很重要,但不能以计算性能和不同数据模态之间的集成缺失为代价。
除了传统的数据格式,MyScale还可以处理未来的数据模态。在MyScale中,将传统的结构化数据与SQL中的向量搜索结果相结合,是解决复杂的与AI相关问题并保持性能的强大方法。
继续阅读,了解MyScale的工作原理以及如何将其集成到您的解决方案中。
 京公网安备 11010802042981号
京公网安备 11010802042981号