
# MyScaleの紹介
MyScaleは、オープンソースのClickHouseデータベースに基づいて構築された、AIアプリケーションおよびソリューション向けに最適化されたクラウドベースのデータベースであり、堅牢なAIアプリケーションの開発のために構造化データとベクターデータの膨大な量を効果的に管理することができます。MyScaleを使用することの最も重要な利点のいくつかは次のとおりです:
- AIアプリケーション向けに構築された: 1つのプラットフォームで構造化データとベクトル化データの分析処理を管理・サポートします。
- パフォーマンスに優れた設計: 最先端のOLAPデータベースアーキテクチャにより、ベクトル化データに対する処理を驚異的な速度で実行します。
- 普遍的なアクセシビリティのために構築された: MyScaleとの対話にはSQLのみが必要です。
他の製品/プラットフォームのカスタマイズされたAPIと比較して、MyScaleは使いやすく、多くのプログラマーコミュニティに適しています。MyScaleは、データ管理のコスト効率の高いサポート、優れたリニアスケーラビリティ、および標準SQLサポートにより、異なるクエリ言語を必要とする複数の高価なデータウェアハウジング製品の必要性を排除します。単一のインターフェースで、SQLクエリはさまざまなデータモダリティを同時に迅速に活用し、通常よりも多くのステップと時間を必要とする複雑なAIの要求に対応できます。
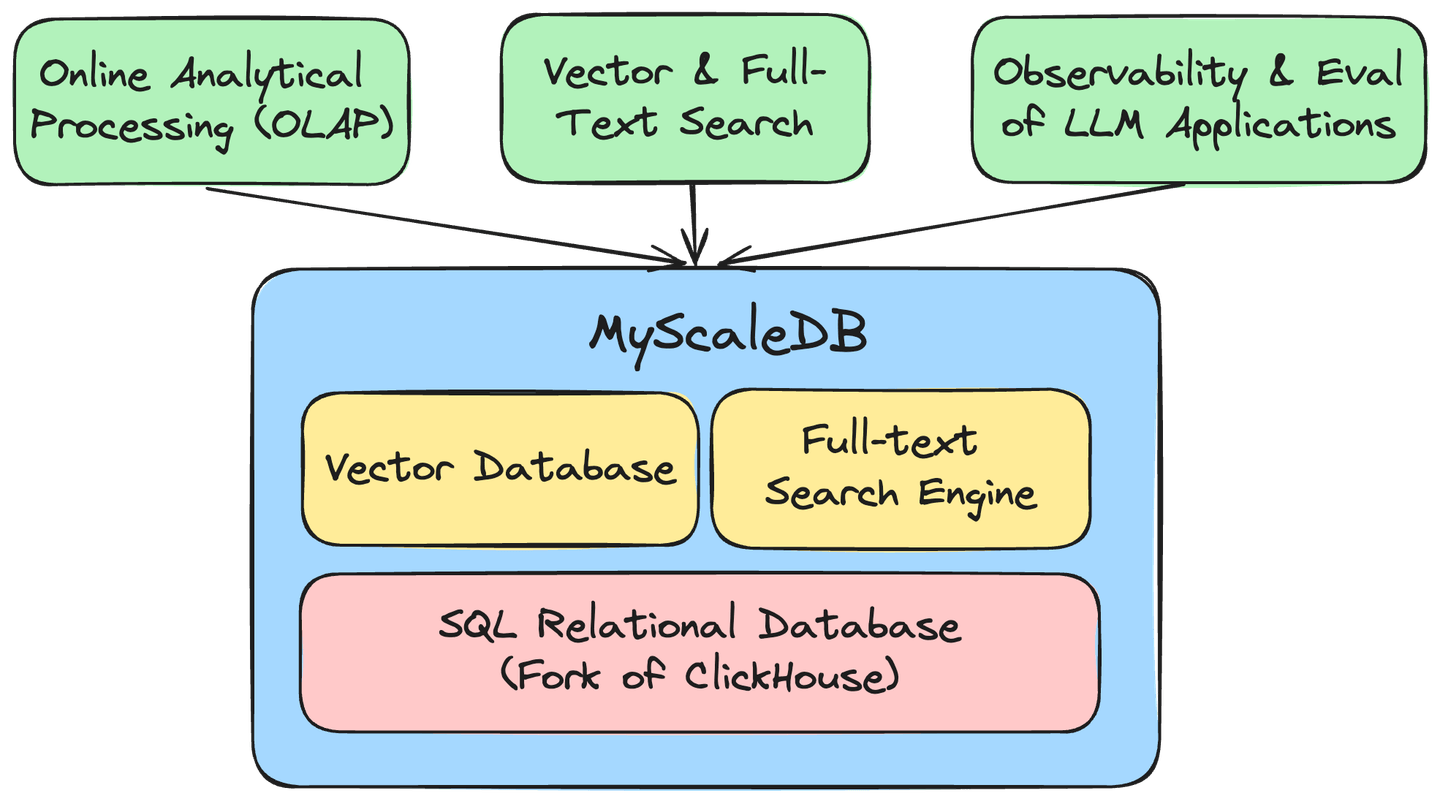
MyScaleの独自のMSTGベクターエンジンは、NVMe SSDを活用してデータ密度を10倍に高めます。この進歩により、MyScaleはパフォーマンスとコスト効率の両面で最も専門的なベクターデータベース (opens new window)を4倍から10倍上回ることができます。フルテキスト検索(FTS)インデックスの統合により、高性能なテキスト検索機能がシームレスに統合され、MyScaleはElasticSearchの効率的なアップグレード (opens new window)として位置付けられます。さらに、MyScale Telemetry (opens new window)はLLMシステムの包括的な観測機能を提供し、シームレスなモニタリングと効率的なデバッグを確保します。
SQLデータベース/データウェアハウス、ベクターデータベース、およびフルテキスト検索エンジンの機能を単一の効率的なシステムに統合することにより、MyScaleはインフラストラクチャとメンテナンスのコストを大幅に削減します。この統合により、共同データクエリと分析が容易になり、すべてのAIアプリケーションに不可欠な強力で多用途のデータ基盤が確立されます。
# 主要なコンセプト
MyScaleは、以下の主要なコンセプトに基づいて、異なるデータモダリティ間で迅速かつ正確なクエリを実行することができます。
# 類似度メトリクス
2つのデータオブジェクト間の意味的な類似性を測定するためには、2つの異なるアプローチがあります。
- 単一モーダル(画像-画像またはテキスト-テキスト): 単一モーダルの類似性は、同じデータ型のオブジェクト間の意味的な類似性を測定します。
- マルチモーダル(画像-テキスト): マルチモーダルの類似性は、異なるデータ型のオブジェクト間の意味的な類似性を測定します。
2つのデータオブジェクト間の意味的な類似性は、類似度メトリクスとして知られるスコアで表現することができます。MyScaleにおいて、大規模なオブジェクトデータベースにおける意味的な類似性を表現するための適切な類似度メトリクスの選択は、データの分類やクラスタリングのパフォーマンスにとって重要です。
大規模なオブジェクトデータベースにおける意味的な類似性を表現するための適切な類似度メトリクスの選択は、データの分類やクラスタリングのパフォーマンスにとって重要です。よく知られているメトリクスの中には、以下の3つがあります。
- ユークリッド距離(L2): L2はコンピュータビジョン(CV)アプリケーションでよく使用されます。
- 内積(IP): IPは自然言語処理(NLP)アプリケーションでよく使用されます。
- コサイン類似度: IPとは異なり、コサイン類似度は2つのオブジェクト間のベクトルとして表される「大きさ」と「角度」の違いのみを比較します。
# 検索アルゴリズム
埋め込みベクトル(またはベクトル)は、多次元空間におけるオブジェクト、概念、またはエンティティの数値表現です。自然言語処理(NLP)のテキスト、IoTセンサーデータ、ソーシャルメディアの写真、生物学的および化学的な構造、またはその他のデータオブジェクトを表現するためにしばしば使用されます。これにより、データの意味的な関係や追加の文脈情報を捉えることができます。
埋め込みは、データの意味的な特徴や特性を低次元空間で捉えるように設計されており、機械学習アルゴリズムがデータを処理・分析しやすくする役割を果たしています。
TIP
近年の埋め込み技術は、非構造化データをベクトルに変換し、高次元データをよりコンパクトで構造化された形式に変換するために使用されています。
2つのオブジェクト間の意味的な類似性を比較するために、MyScaleデータベースにクエリベクトルを提供します。MyScaleは、近似最近傍探索(ANN)などの検索アルゴリズムを使用して、クエリベクトルに類似したベクトルのリストを迅速かつ正確に返します。
# MyScaleでのSQLの使用
Pinecone、Milvus、Qdrant、Weaviateなどのプロプライエタリなベクトルデータベースとは異なり、MyScaleはオープンソースのSQL互換のClickHouseデータベース上に構築されています。これにはいくつかの理由があります。
- ClickHouseの成熟したコードベースとエコシステムを活用することで、ユーザーに機能豊富なデータベースを提供することができます。
- SQLはリレーショナルデータベースの管理に広く使用されています。MyScaleのSQLサポートにより、開発者やデータアナリストは既存の知識とスキルを活用することができ、統合と使用が容易になります。
- SQLはさまざまなデータ操作、クエリ、レポート機能をサポートしています。したがって、MyScaleはSQLと完全に互換性があり、ユーザーは複雑なクエリを実行し、さまざまな方法でデータを分析することができます。
- MyScaleはClickHouseの上に構築されているため、ベクトル検索だけでなく、フィルタリングされたベクトル検索やベクトル検索結果を別のテーブルと結合するなど、複雑なSQLとベクトルクエリを実行する際にも高速かつスケーラブルなパフォーマンスを提供します。
# なぜこれが重要なのか?
複雑なデータが指数関数的に増加する中で、新しいデータモダリティ、データベースのサイズ、クエリに対する回答の見つけ方に対応できる将来に対応したソリューションが必要です。これは重要ですが、計算パフォーマンスや異なるデータモダリティ間の統合の欠如によって犠牲にしてはなりません。
MyScaleは、従来のデータ形式に加えて、将来のデータモダリティも扱うことができます。MyScaleでは、伝統的な構造化データとベクトル検索結果をSQLで組み合わせることで、複雑なAI関連の問題に取り組む強力な手法を提供し、パフォーマンスを維持します。
MyScaleの動作方法とそれをソリューションに統合する方法については、続きを読んでください。