
In der modernen Welt haben große Sprachmodelle (LLMs) (opens new window) die Welt durch ihre beeindruckende Fähigkeit, Texte zu produzieren, die menschlich geschriebenen Text imitieren, transformiert. Diese Modelle sind hochqualifiziert in Aufgaben wie der Erstellung neuer Inhalte und der Bereitstellung intelligenter Antworten, was das KI-Feld weiter vorantreibt. Sie werden auf großen Datenmengen trainiert, aber sie wissen nur, was in diesen Daten enthalten ist, was es ihnen schwer macht, die neuesten Informationen bereitzustellen. Dies kann zu veralteten Antworten oder falschen Informationen führen, die als Informationshalluzinationen bekannt sind. Um diese Probleme anzugehen, wurde ein dynamisches Framework namens Retrieval-Augmented Generation (RAG) entwickelt. Es kombiniert die Stärken traditioneller LLMs mit Rückgewinnungssystemen und erweitert die Anwendungsfälle dieser Modelle.
# Was ist RAG?
RAG ist eine strategische Verbesserung, die entwickelt wurde, um die Leistung von LLMs zu steigern. Durch die Einbeziehung eines Schritts, der Informationen während der Textgenerierung abruft, stellt RAG sicher, dass die Antworten des Modells genau und aktuell sind. RAG hat sich erheblich weiterentwickelt und hat zur Entwicklung von zwei Hauptmodi geführt:
- Naive RAG: Dies ist die einfachste Version, bei der das System einfach die relevanten Informationen aus einer Wissensdatenbank abruft und sie direkt an das LLM weitergibt, um die Antwort zu generieren.
- Advanced RAG: Diese Version geht einen Schritt weiter. Sie fügt zusätzliche Verarbeitungsschritte vor und nach dem Abruf hinzu, um die abgerufenen Informationen zu verfeinern. Diese Schritte verbessern die Qualität und Genauigkeit der generierten Antwort und stellen sicher, dass sie nahtlos in die Ausgabe des Modells integriert wird.
# Naive RAG
Naive RAG ist die ursprünglichste Version des RAG-Ökosystems. Es handelt sich um eine recht einfache Methode, um Abrufdaten und LLM-Modelle zu kombinieren und dem Benutzer eine effiziente Antwort zu liefern.
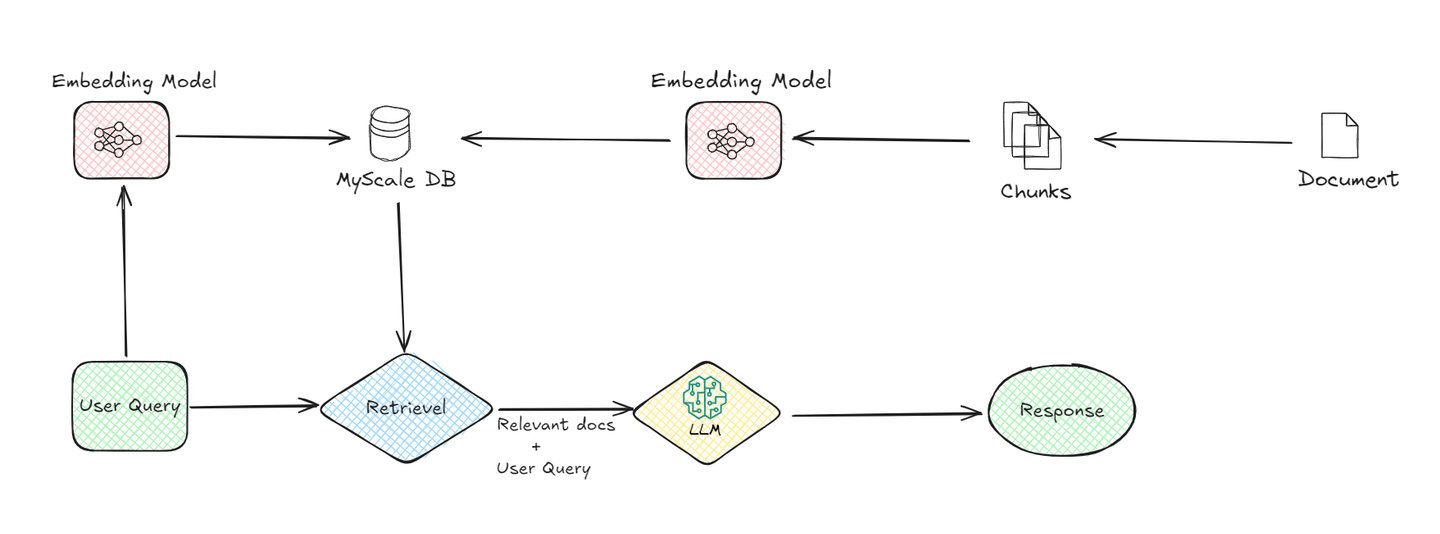
Ein grundlegendes System besteht aus den folgenden Komponenten:
# 1. Dokumenten-Chunking:
Der Prozess beginnt damit, dass Dokumente in kleinere Chunks aufgeteilt werden. Dies ist wichtig, da kleinere Chunks einfacher zu verwalten und zu verarbeiten sind. Wenn Sie beispielsweise ein langes Dokument haben, wird es in Segmente aufgeteilt, um es dem System später zu erleichtern, relevante Informationen abzurufen.
# 2. Einbettungsmodell:
Das Einbettungsmodell ist ein entscheidender Bestandteil des RAG-Systems. Es wandelt sowohl die Dokumenten-Chunks als auch die Benutzeranfrage in eine numerische Form um, die oft als Einbettungen (opens new window) bezeichnet wird. Diese Umwandlung ist notwendig, da Computer numerische Daten besser verstehen. Das Einbettungsmodell verwendet fortschrittliche maschinelle Lernverfahren, um die Bedeutung von Text auf mathematische Weise darzustellen. Wenn ein Benutzer eine Frage stellt, wandelt das Modell diese Frage beispielsweise in eine Reihe von Zahlen um, die die Semantik der Anfrage erfassen.
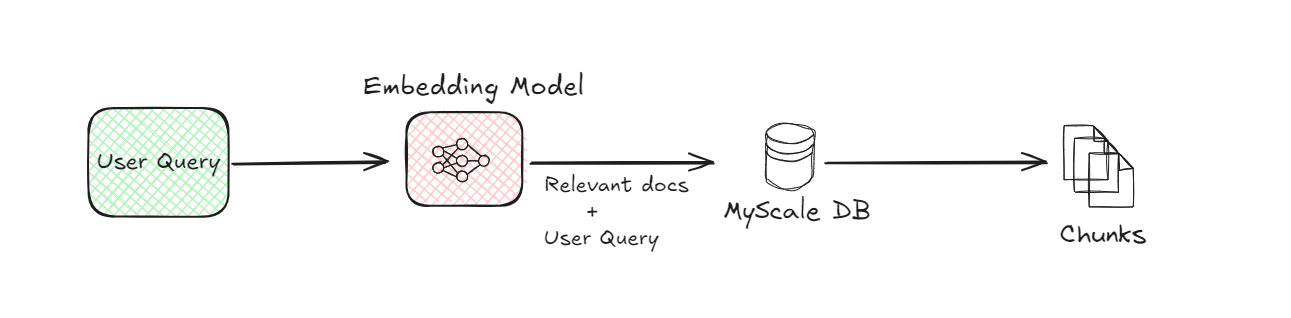
# 3. Vektordatenbank (MyScaleDB):
Sobald die Dokumenten-Chunks in Einbettungen umgewandelt wurden, werden sie in einer Vektordatenbank (opens new window) wie MyScaleDB (opens new window) gespeichert. Die Vektordatenbanken sind darauf ausgelegt, diese Einbettungen effizient zu speichern und abzurufen. Wenn ein Benutzer eine Anfrage stellt, verwendet das System die Vektordatenbank, um die relevantesten Dokumenten-Chunks zu finden, indem es die Einbettungen der Anfrage mit denen vergleicht, die in der Datenbank gespeichert sind. Dieser Vergleich hilft dabei, die Chunks zu identifizieren, die am ähnlichsten zu dem sind, wonach der Benutzer fragt.
# 4. Abruf:
Nachdem die Vektordatenbank die relevanten Dokumenten-Chunks identifiziert hat, werden sie abgerufen. Dieser Abrufprozess ist entscheidend, da er die Informationen einschränkt, die zur Generierung der endgültigen Antwort verwendet werden. Im Wesentlichen fungiert er als Filter und stellt sicher, dass nur die relevantesten Daten an die nächste Stufe weitergegeben werden.
# 5. LLM (Large Language Model):
Sobald die relevanten Chunks abgerufen sind, übernimmt das LLM. Seine Aufgabe besteht darin, die abgerufenen Informationen zu verstehen und eine kohärente Antwort auf die Anfrage des Benutzers zu generieren. Das LLM verwendet die Benutzeranfrage und die abgerufenen Chunks, um eine Antwort bereitzustellen, die nicht nur relevant, sondern auch kontextuell angemessen ist. Dieses Modell ist dafür verantwortlich, die Daten zu interpretieren und eine Antwort in natürlicher Sprache zu formulieren, die der Benutzer leicht verstehen kann.
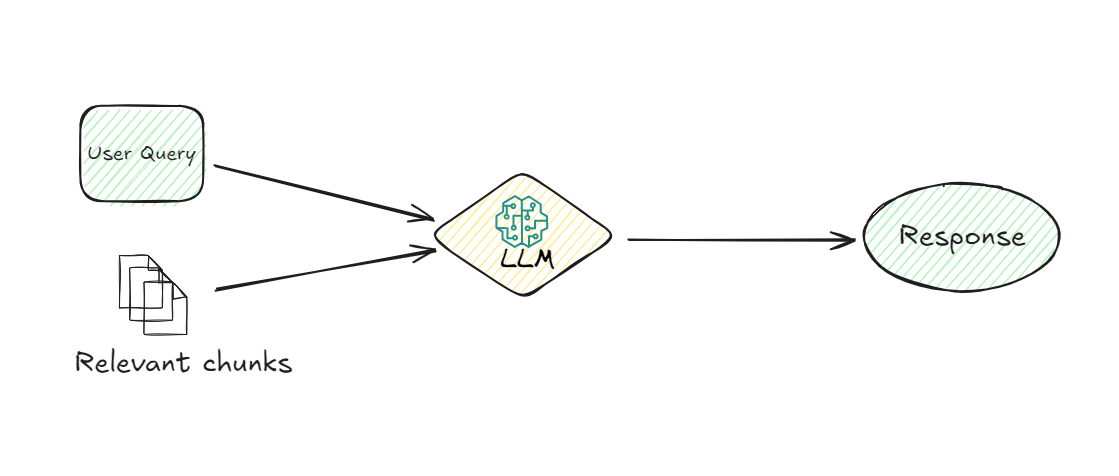
# 6. Antwortgenerierung:
Schließlich generiert das System eine Antwort basierend auf den vom LLM verarbeiteten Informationen. Diese Antwort wird dann dem Benutzer geliefert und liefert ihm die gesuchten Informationen auf klare und prägnante Weise.
Indem wir den Datenfluss von der Anfrage des Benutzers bis zur endgültigen Antwort verstehen, können wir schätzen, welche Rolle jede Komponente des Naive RAG-Systems spielt, um sicherzustellen, dass der Benutzer genaue und relevante Informationen erhält.
# Vorteile
- Einfache Implementierung: RAG ist einfach einzurichten, da es die Rückgewinnung direkt mit der Generierung integriert und die Komplexität bei der Verbesserung von Sprachmodellen reduziert, ohne aufwendige Modifikationen oder zusätzliche Komponenten zu benötigen.
- Keine Notwendigkeit für Feinabstimmung: Einer der wesentlichen Vorteile von RAG besteht darin, dass keine Feinabstimmung (opens new window) des LLM erforderlich ist. Dies spart nicht nur Zeit und reduziert Betriebskosten, sondern ermöglicht auch eine schnellere Bereitstellung von RAG-Systemen.
- Verbesserte Genauigkeit: Durch die Nutzung externer, aktueller Informationen verbessert Naive RAG die Genauigkeit der generierten Antworten erheblich. Dadurch wird sichergestellt, dass die Ausgaben nicht nur relevant sind, sondern auch die neuesten verfügbaren Daten widerspiegeln.
- Verminderte Halluzinationen: RAG mindert das häufige Problem, dass LLMs falsche oder erfundene Informationen generieren, indem es die Antworten auf echten, faktischen Daten basiert, die während des Prozesses abgerufen wurden.
- Skalierbarkeit und Flexibilität: Die Einfachheit von Naive RAG erleichtert die Skalierung auf verschiedene Anwendungen, da es ohne wesentliche Änderungen an vorhandenen Rückgewinnungs- oder Generierungskomponenten angepasst werden kann. Diese Flexibilität ermöglicht den Einsatz in verschiedenen Bereichen mit geringfügiger Anpassung.
# Nachteile
- Begrenzte Verarbeitung: Die abgerufenen Informationen werden direkt verwendet, ohne weitere Verarbeitung oder Verfeinerung, was zu Kohärenzproblemen in den generierten Antworten führen kann.
- Abhängigkeit von der Qualität der Rückgewinnung: Die Qualität der endgültigen Ausgabe hängt stark von der Fähigkeit des Rückgewinnungsmoduls ab, die relevantesten Informationen zu finden. Eine schlechte Rückgewinnung kann zu weniger genauen oder relevanten Antworten führen.
- Skalierbarkeitsprobleme: Mit zunehmender Datensatzgröße kann der Rückgewinnungsprozess langsamer werden und sich auf die Gesamtleistung und Reaktionszeit auswirken.
- Kontextbeschränkungen: Naive RAG kann Schwierigkeiten haben, den größeren Kontext einer Anfrage zu verstehen, was zu Antworten führen kann, die zwar korrekt, aber nicht vollständig mit der Absicht des Benutzers übereinstimmen.
Durch die Untersuchung dieser Vorteile und Nachteile können wir umfassend verstehen, wo Naive RAG glänzt und wo es auf Herausforderungen stoßen kann. Dies ebnet den Weg für Verbesserungen und schafft die Möglichkeit, Advanced RAG zu entwickeln.
# Advanced RAG
Aufbauend auf dem Fundament von Naive RAG führt Advanced RAG eine Schicht von Raffinesse in den Prozess ein. Im Gegensatz zu Naive RAG, das abgerufene Informationen direkt integriert, beinhaltet Advanced RAG zusätzliche Verarbeitungsschritte, die die Relevanz und die Gesamtqualität der Antwort optimieren.
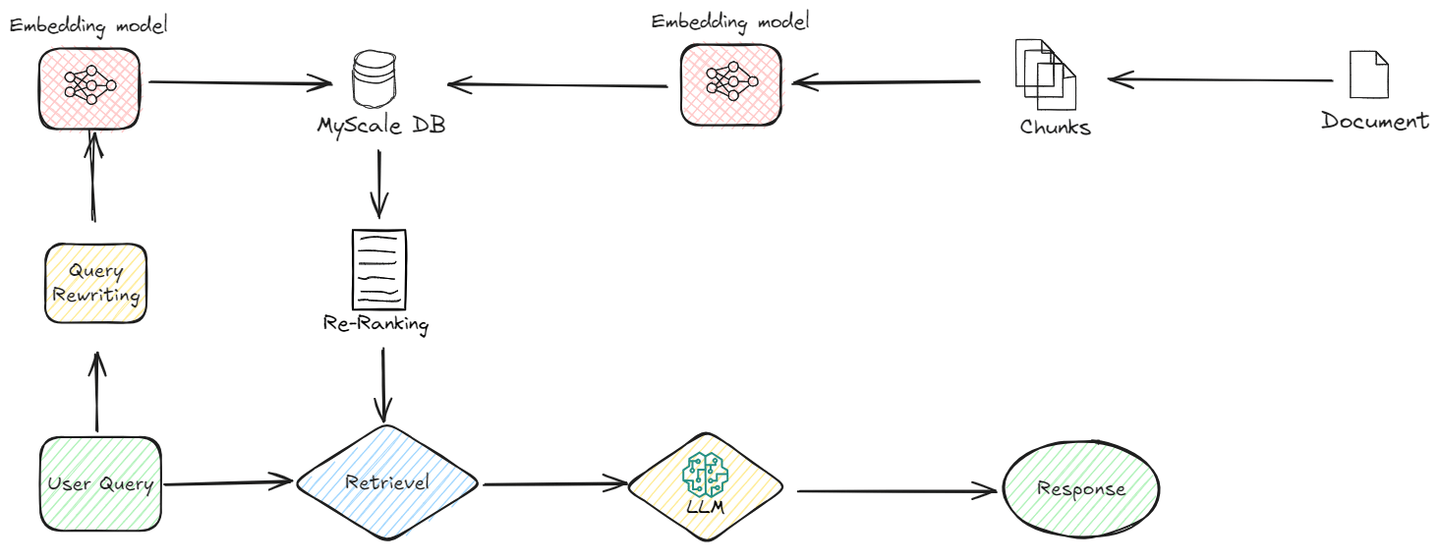
Lassen Sie uns verstehen, wie es funktioniert:
# Vor-Rückgewinnungs-Optimierungen
Bei Advanced RAG wird der Rückgewinnungsprozess bereits vor dem eigentlichen Rückgewinnungsvorgang verfeinert. Hier ist, was in dieser Phase passiert:
# Verbesserungen der Indizierung
Indexierungsmethoden (opens new window) spielen eine wichtige Rolle bei der effizienten Organisation und Rückgewinnung von Daten in Datenbanken. Traditionelle Indexierungsmethoden wie B-Bäume (opens new window) und Hash-Indexierung (opens new window) wurden dafür weit verbreitet eingesetzt. Die Suchgeschwindigkeit dieser Algorithmen nimmt jedoch ab, wenn die Datenmenge zunimmt. Daher benötigen wir effizientere Indexierungsmethoden für größere Datensätze. Der MSTG (Multi-Strategy Tree-Graph) (opens new window)-Indexierungsalgorithmus von MyScale ist ein herausragendes Beispiel für eine solche Weiterentwicklung. Dieser Algorithmus übertrifft andere Indexierungsmethoden in Bezug auf Geschwindigkeit und Leistung.
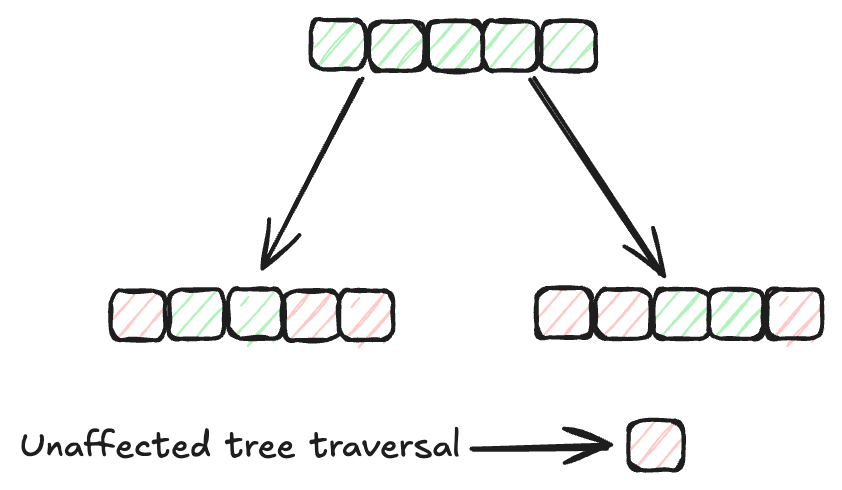
MSTG vereint die Stärken von hierarchischen Graphen (opens new window) und Baumstrukturen (opens new window). Typischerweise sind Graphalgorithmen schneller für ungefilterte Suchen, aber möglicherweise nicht effizient für gefilterte Suchen. Baumalgorithmen hingegen sind für gefilterte Suchen hervorragend geeignet, aber für ungefilterte Suchen langsamer. Durch die Kombination dieser beiden Ansätze gewährleistet MSTG eine hohe Leistung und Genauigkeit sowohl für ungefilterte als auch für gefilterte Suchen und ist somit eine robuste Wahl für verschiedene Suchszenarien.
# Query-Umschreibung
Vor dem Rückgewinnungsprozess wird die ursprüngliche Benutzeranfrage mehrfach verbessert, um ihre Genauigkeit und Relevanz zu verbessern. Dieser Schritt stellt sicher, dass das Rückgewinnungssystem die relevantesten Informationen abruft. Hier werden Techniken wie Query-Umschreibung (opens new window), Erweiterung und Transformation eingesetzt. Wenn beispielsweise eine Benutzeranfrage zu allgemein ist, kann die Query-Umschreibung sie verfeinern, indem sie mehr Kontext oder spezifische Begriffe hinzufügt, während die Query-Erweiterung Synonyme oder verwandte Begriffe hinzufügen kann, um eine breitere Palette relevanter Dokumente zu erfassen.
# Dynamische Einbettungen
In Naive RAG kann ein einzelnes Einbettungsmodell für alle Arten von Daten verwendet werden, was zu Ineffizienzen führen kann. Advanced RAG hingegen feinabstimmt und passt Einbettungen an die spezifische Aufgabe oder das spezifische Gebiet an. Dies bedeutet, dass das Einbettungsmodell für eine bestimmte Art von Anfrage oder Datensatz trainiert oder angepasst wird, um das erforderliche kontextuelle Verständnis besser zu erfassen.
Durch die Verwendung dynamischer Einbettungen wird das System effizienter und genauer, da die Einbettungen enger mit den Feinheiten der spezifischen Aufgabe übereinstimmen.
# Hybrid-Suche
Advanced RAG nutzt auch einen hybriden Suchansatz (opens new window), der verschiedene Suchstrategien kombiniert, um die Rückgewinnungsleistung zu verbessern. Dies kann keywordbasierte Suchen, semantische Suchen und neuronale Suchen umfassen. MyScaleDB unterstützt beispielsweise gefilterte Vektorsuche (opens new window) und Volltextsuche (opens new window), was komplexe SQL-Abfragen aufgrund seiner SQL-freundlichen Syntax ermöglicht. Dieser hybride Ansatz stellt sicher, dass das System Informationen mit einem hohen Maß an Relevanz abrufen kann, unabhängig von der Art der Anfrage.
# Nach-Rückgewinnungs-Verarbeitung
Nach dem Rückgewinnungsprozess endet Advanced RAG nicht. Es verarbeitet die abgerufenen Daten weiter, um die höchste Qualität und Relevanz in der endgültigen Ausgabe sicherzustellen.
# Re-Ranking
Nach dem Rückgewinnungsprozess unternimmt Advanced RAG einen zusätzlichen Schritt, um die Informationen zu verfeinern. Dieser Schritt, bekannt als Re-Ranking, stellt sicher, dass die relevantesten und nützlichsten Daten priorisiert werden. Zunächst ruft das System mehrere Informationen ab, die mit der Anfrage des Benutzers zusammenhängen könnten. Allerdings ist nicht alle diese Information gleich wertvoll. Das Re-Ranking hilft dabei, diese Daten basierend auf zusätzlichen Faktoren wie der Nähe zur Anfrage und der Passung zum Kontext zu sortieren.
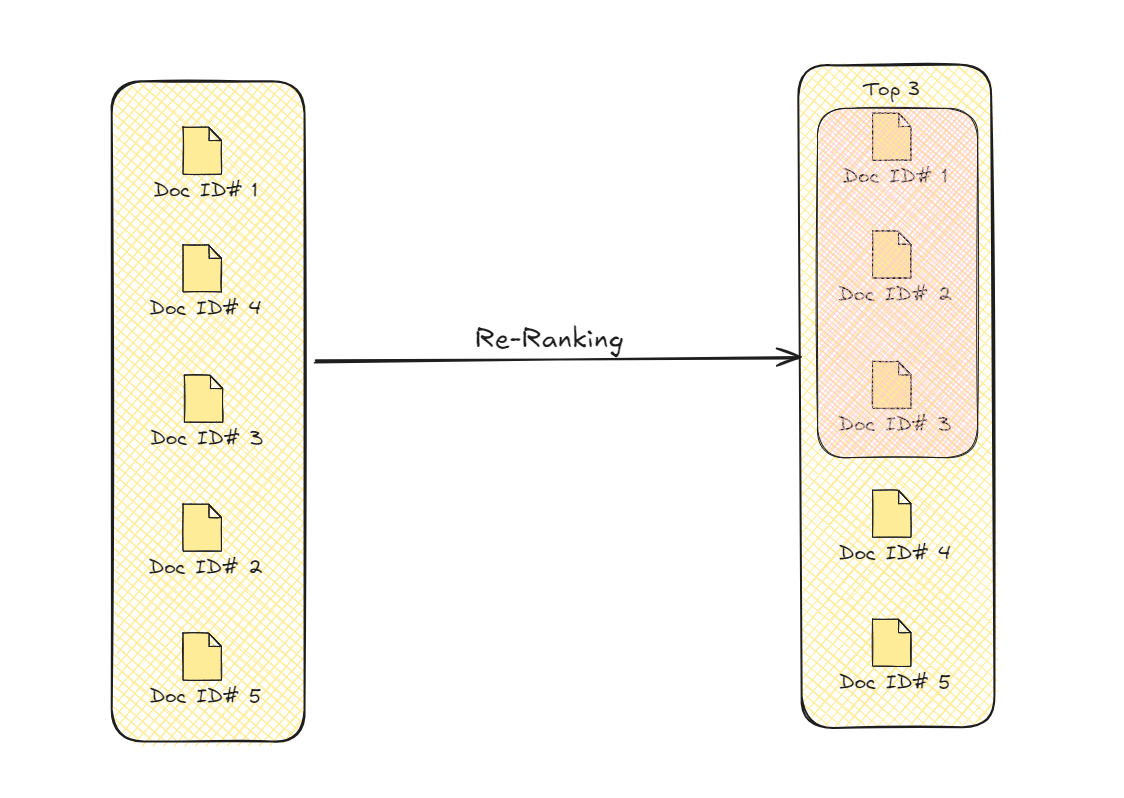
Durch die erneute Bewertung des abgerufenen Inhalts platziert das Re-Ranking die relevantesten Stücke oben. Dadurch wird sichergestellt, dass die generierte Antwort nicht nur genau, sondern auch kohärent ist und den Bedürfnissen des Benutzers direkt entspricht. Der Prozess verwendet verschiedene Kriterien wie semantische Relevanz und kontextuelle Angemessenheit, um die Informationen neu zu ordnen. Diese Verfeinerung führt zu einer endgültigen Antwort, die fokussierter und präziser ist und die Gesamtqualität der Ausgabe verbessert.
# Kontextkompression
Nach der Filterung der relevanten Dokumente kann es trotz Verwendung eines Re-Ranking-Algorithmus immer noch irrelevante Daten in diesen gefilterten Dokumenten geben, um die Benutzeranfrage zu beantworten. Der Prozess, diese überflüssigen Daten zu eliminieren oder zu entfernen, bezeichnen wir als Kontextkompression. Dieser Schritt wird unmittelbar vor der Weitergabe der relevanten Dokumente an das LLM angewendet, um sicherzustellen, dass das LLM nur die relevantesten Informationen erhält und so die bestmöglichen Ergebnisse liefern kann.
# Vorteile
Um die Unterschiede zwischen diesen beiden Ansätzen besser zu verstehen, betrachten wir die spezifischen Vorteile, die Advanced RAG gegenüber Naive RAG bietet.
- Bessere Relevanz mit Re-Ranking: Re-Ranking stellt sicher, dass die relevantesten Informationen zuerst kommen und sowohl die Genauigkeit als auch den Fluss der endgültigen Antwort verbessern.
- Dynamische Einbettungen für besseren Kontext: Dynamische Einbettungen werden für spezifische Aufgaben angepasst, um dem System zu helfen, verschiedene Anfragen genauer und genauer zu verstehen und zu beantworten.
- Genauere Rückgewinnung mit Hybrid-Suche: Hybrid-Suche verwendet mehrere Strategien, um Daten effektiver zu finden und eine höhere Relevanz und Präzision in den Ergebnissen sicherzustellen.
- Effiziente Antworten mit Kontextkompression: Kontextkompression entfernt unnötige Details, macht den Prozess schneller und führt zu fokussierteren, qualitativ hochwertigen Antworten.
- Verbessertes Verständnis der Benutzeranfrage: Durch die Umschreibung und Erweiterung von Anfragen vor dem Rückgewinnungsprozess stellt Advanced RAG sicher, dass Benutzeranfragen vollständig verstanden werden, was zu genaueren und relevanteren Ergebnissen führt.
Advanced RAG markiert eine wesentliche Verbesserung in der Qualität der von Sprachmodellen generierten Antworten. Durch die Hinzufügung einer Verfeinerungsstufe werden wichtige Probleme in Naive RAG, wie Kohärenz und Relevanz, effektiv angegangen.
# Vergleichende Analyse: Naive RAG gegen Advanced RAG
Durch den Vergleich von Naive RAG und Advanced RAG können wir beobachten, wie Advanced RAG das grundlegende Framework von Naive RAG erweitert. Es führt wesentliche Verbesserungen ein, die die Genauigkeit, Effizienz und Gesamtqualität der Rückgewinnung verbessern.
| Kriterien | Naive RAG | Advanced RAG |
|---|---|---|
| Genauigkeit und Relevanz | Bietet grundlegende Genauigkeit durch Verwendung der abgerufenen Informationen. | Verbessert die Genauigkeit und Relevanz durch erweiterte Filterung, Re-Ranking und bessere Verwendung des Kontexts. |
| Datenrückgewinnung | Verwendet grundlegende Ähnlichkeitsprüfungen, die einige relevante Daten übersehen können. | Optimiert die Rückgewinnung mit Techniken wie Hybrid-Suche und dynamischen Einbettungen, um hochrelevante und genaue Daten sicherzustellen. |
| Anfragenoptimierung | Verarbeitet Anfragen auf einfache Weise ohne viel Verbesserung. | Verbessert die Verarbeitung von Anfragen mit Methoden wie Query-Umschreibung und Hinzufügen von Metadaten, um die Rückgewinnung präziser zu machen. |
| Skalierbarkeit | Kann bei zunehmender Datensatzgröße weniger effizient werden und die Rückgewinnung beeinträchtigen. | Wurde entwickelt, um große Datensätze effizient zu verarbeiten, indem bessere Indexierungs- und Rückgewinnungsmethoden verwendet werden, um die Leistung hoch zu halten. |
| Mehrstufige Rückgewinnung | Führt einen einzigen Durchlauf der Rückgewinnung durch, der wichtige Daten übersehen kann. | Verwendet einen mehrstufigen Prozess, um die anfänglichen Ergebnisse mit Schritten wie Re-Ranking und Kontextkompression zu verfeinern und sicherzustellen, dass die endgültigen Ausgaben genau und relevant sind. |

# Fazit
Bei der Wahl zwischen Naive RAG und Advanced RAG sollten Sie die spezifischen Anforderungen Ihrer Anwendung berücksichtigen. Naive RAG eignet sich ideal für einfachere Anwendungsfälle, bei denen Geschwindigkeit und einfache Implementierung Priorität haben. Es verbessert die Leistung von LLMs in Szenarien, in denen ein tiefes kontextuelles Verständnis nicht entscheidend ist. Advanced RAG hingegen eignet sich besser für komplexere Anwendungen und bietet eine verbesserte Genauigkeit und Kohärenz durch zusätzliche Verarbeitungsschritte wie verfeinerte Filterung und Re-Ranking. Es ist die bevorzugte Wahl für die Verarbeitung großer Datensätze und komplexe Anfragen.
MyScale hebt diese Fortschritte weiter an, indem es skalierbare und effiziente Rückgewinnungslösungen bietet. Seine ausgeklügelten Indexierungs (opens new window)- und Datenverarbeitungstechniken verbessern sowohl die Geschwindigkeit als auch die Genauigkeit der Informationsrückgewinnung und unterstützen die verbesserte Leistung von RAG-Systemen. Durch die Nutzung von MyScale können Entwickler ihre Verwendung fortschrittlicher RAG-Methoden optimieren und Verbesserungen in KI-Systemen und deren Fähigkeit zur Bereitstellung präziser und relevanter Informationen vorantreiben.



