
Der Aufstieg leistungsstarker großer Sprachmodelle (LLMs) wie GPT-4, Gemini 1.5 und Claude 3 hat die KI- und Technologiebranche revolutioniert. Mit Modellen, die über 1 Million Tokens (opens new window) verarbeiten können, ist ihre Fähigkeit, lange Kontexte zu verarbeiten, beeindruckend. Allerdings:
- Viele Datenstrukturen sind für LLMs zu komplex und ständig im Wandel, um effektiv alleine damit umgehen zu können.
- Die Verwaltung massiver, heterogener Unternehmensdaten innerhalb eines Kontextfensters ist schlichtweg unpraktikabel.
Die erweiterte Generierung durch Abruf (RAG) hilft, diese Probleme anzugehen, aber die Abrufgenauigkeit ist ein wesentlicher Engpass für die End-to-End-Leistung, und viele Vektor-Datenbanken skalieren nicht gut für komplexe Anwendungsfälle. Eine Lösung besteht darin, LLMs mit Big Data durch fortschrittliche SQL-Vektor-Datenbanken zu integrieren. Diese Art der Synergie zwischen LLMs und Big Data macht nicht nur LLMs effektiver, sondern ermöglicht es den Menschen auch, bessere Erkenntnisse aus Big Data zu gewinnen. Darüber hinaus reduziert es die Modell-Halluzinationen und bietet Daten-Transparenz und Zuverlässigkeit.
# Aktueller Stand der Vektor-Datenbanken
Als Grundlage von RAG-Systemen haben sich Vektor-Datenbanken im letzten Jahr rasant entwickelt. Sie können im Allgemeinen in drei Typen unterteilt werden: dedizierte Vektor-Datenbanken, Schlüsselwort- und Vektor-Abrufsysteme sowie SQL-Vektor-Datenbanken. Jeder Typ hat Vor- und Nachteile.
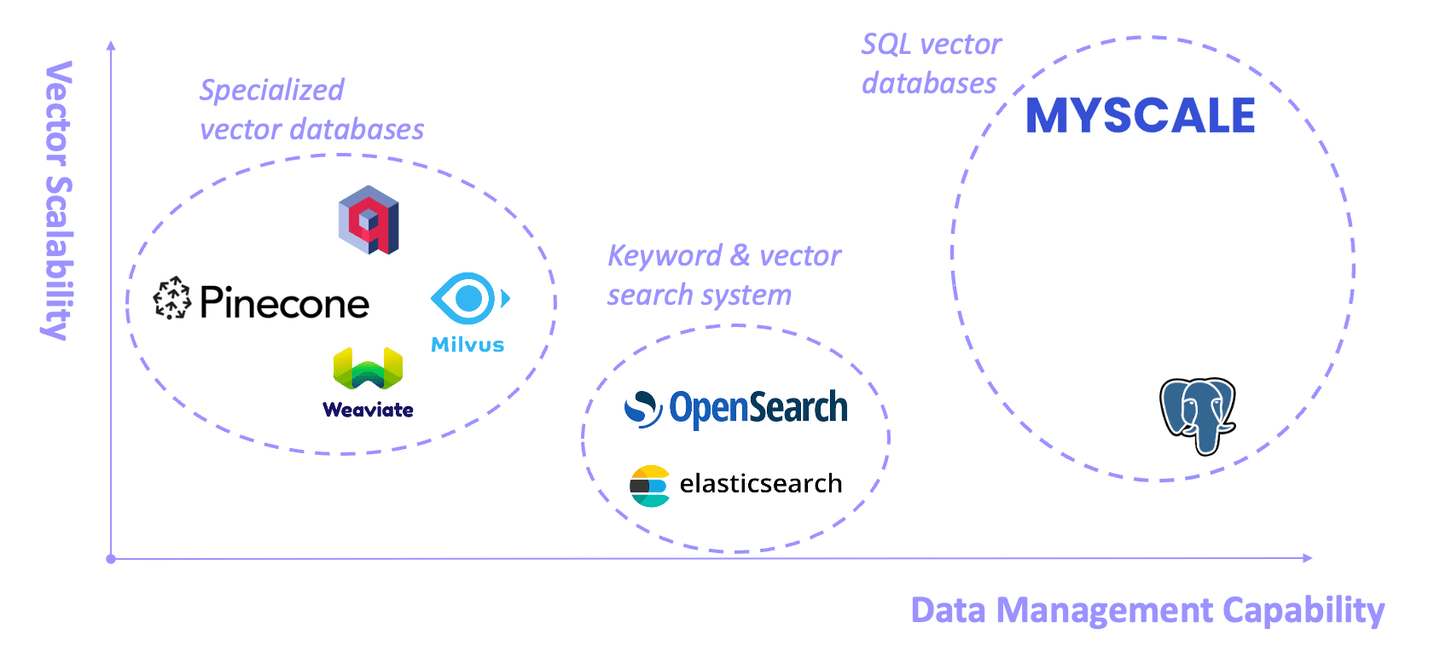
# Spezialisierte Vektor-Datenbanken
Einige Vektor-Datenbanken (wie Pinecone, Weaviate und Milvus) sind von Anfang an speziell für die Vektorsuche konzipiert. Sie zeigen gute Leistung in diesem Bereich, haben jedoch etwas eingeschränkte allgemeine Datenverwaltungsfähigkeiten (opens new window).
# Schlüsselwort- und Vektor-Abrufsysteme
Vertreten durch Elasticsearch und OpenSearch, werden diese Systeme aufgrund ihrer umfassenden schlüsselwortbasierten Abruffähigkeiten häufig in der Produktion eingesetzt. Sie verbrauchen jedoch erhebliche Systemressourcen, und die Genauigkeit und Leistung von Schlüsselwort- und Vektor-Hybridabfragen sind oft unbefriedigend (opens new window).
# SQL-Vektor-Datenbanken
SQL-Vektor-Datenbanken (opens new window) sind eine spezialisierte Art von Datenbank, die die Fähigkeiten herkömmlicher SQL-Datenbanken mit den Fähigkeiten einer Vektor-Datenbank kombiniert. Sie ermöglichen Ihnen die effiziente Speicherung und Abfrage von hochdimensionalen Vektoren mit Hilfe von SQL.
Die beiden wichtigsten SQL-Vektor-Datenbanken sind in der obigen Abbildung dargestellt: pgvector und MyScaleDB. pgvector ist ein Vektorsuch-Plugin für PostgreSQL. Es ist einfach einzurichten und nützlich für die Verwaltung kleiner Datensätze. Aufgrund der Nachteile der Zeilenspeicherung von Postgres und der Begrenzungen des Vektoralgorithmus hat pgvector jedoch tendenziell eine geringere Genauigkeit und Leistung für groß angelegte, komplexe Vektorabfragen.
MyScaleDB (opens new window) ist eine Open-Source-SQL-Vektor-Datenbank, die auf ClickHouse (einer spaltenorientierten SQL-Datenbank) aufbaut. Sie wurde entwickelt, um eine leistungsstarke und kostengünstige Datenbasis für GenAI-Anwendungen bereitzustellen. MyScaleDB ist auch die erste SQL-Vektor-Datenbank, die spezialisierte Vektor-Datenbanken in Bezug auf Gesamtleistung und Kosteneffizienz übertrifft (opens new window).

Quelle: https://myscale.github.io/benchmark (opens new window)
# Die Kraft von SQL und Vektor-basierter Datenmodellierung
Trotz des Aufkommens von NoSQL- und Big-Data-Technologien dominieren SQL-Datenbanken weiterhin den Datenmanagement-Markt, ein halbes Jahrhundert nach der Einführung von SQL. Selbst Systeme wie Elasticsearch und Spark haben SQL-Schnittstellen hinzugefügt. Mit der SQL-Unterstützung ermöglicht MyScaleDB, eine SQL-Vektor-Datenbank, eine hohe Leistungsfähigkeit bei der Vektorsuche und -analyse (opens new window).
In realen KI-Anwendungen verbessert die Integration von SQL und Vektoren die Flexibilität der Datenmodellierung und vereinfacht die Entwicklung. Zum Beispiel verwendet ein groß angelegtes wissenschaftliches Produkt MyScaleDB für intelligente Frage-Antwort-Systeme über umfangreiche wissenschaftliche Literaturdaten. Das Haupt-SQL-Schema umfasst über 10 Tabellen, mehrere davon mit Vektor- und schlüsselwortbasierten Invertierungsindex-Strukturen, die über Primär- und Fremdschlüssel verbunden sind. Das System verarbeitet komplexe Abfragen, die strukturierte, vektorbasierte und schlüsselwortbasierte Daten sowie verbundene Abfragen über mehrere Tabellen umfassen. Dies ist eine anspruchsvolle Aufgabe für spezialisierte Vektor-Datenbanken, die oft zu langsamer Iteration, ineffizienter Abfrage und hohen Wartungskosten führt.
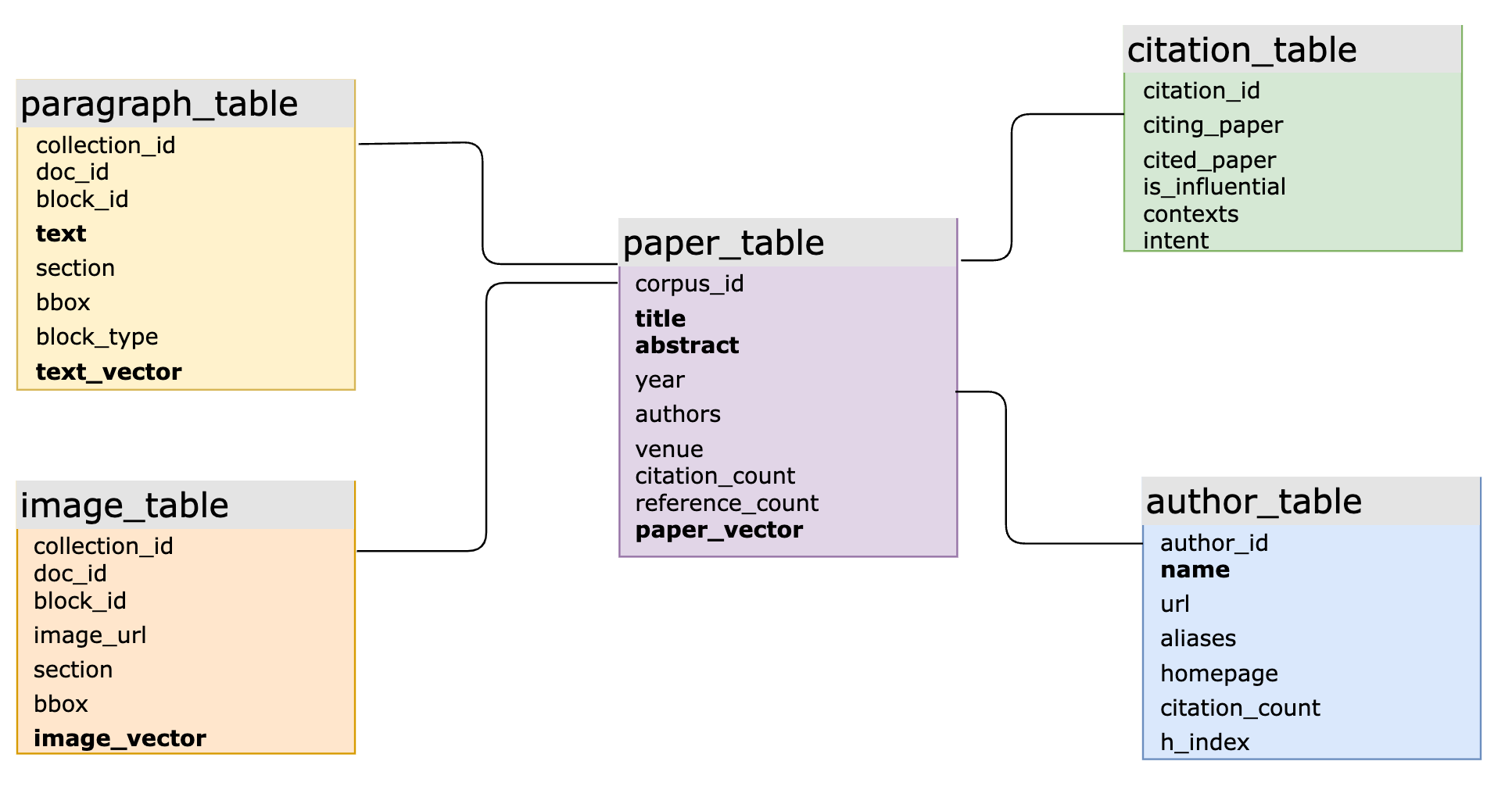
Das Haupt-SQL-Vektor-Datenbankschema eines groß angelegten wissenschaftlichen Produkts, das von MyScale unterstützt wird (Spalten in Fettschrift haben zugehörige Vektor-Indizes oder Invertierungsindizes)
# Verbesserung der RAG-Genauigkeit und Kosteneffizienz
In realen RAG-Systemen erfordert die Überwindung der Abrufgenauigkeit (und der damit verbundenen Leistungsengpässe) eine effiziente Möglichkeit, strukturierte, vektorbasierte und schlüsselwortbasierte Datenabfragen zu kombinieren.
Zum Beispiel, in einer Finanzanwendung, wenn Benutzer eine Dokumentendatenbank abfragen und fragen: "Was war der Umsatz von <company_name> im Jahr 2023 weltweit?", können strukturierte Metadaten wie "<company_name>" und "2023" von semantischen Vektoren nicht erfasst oder in aufeinanderfolgendem Text vorhanden sein. Eine Vektorabfrage über die gesamte Datenbank kann zu ungenauen Ergebnissen führen und die endgültige Genauigkeit verringern.
Informationen wie Firmennamen und Jahre können jedoch oft als Dokumentenmetadaten erhalten werden. Die Verwendung von WHERE year=2023 AND company LIKE "%<company_name>%" als Filterbedingungen für Vektorabfragen kann relevante Informationen präzise lokalisieren und die Zuverlässigkeit des Systems erheblich erhöhen. In den Bereichen Finanzen, Produktion und Forschung wurde beobachtet, dass die SQL-Vektor-Datenmodellierung und gemeinsame Abfragen die Präzision von 60% auf 90% verbessern.
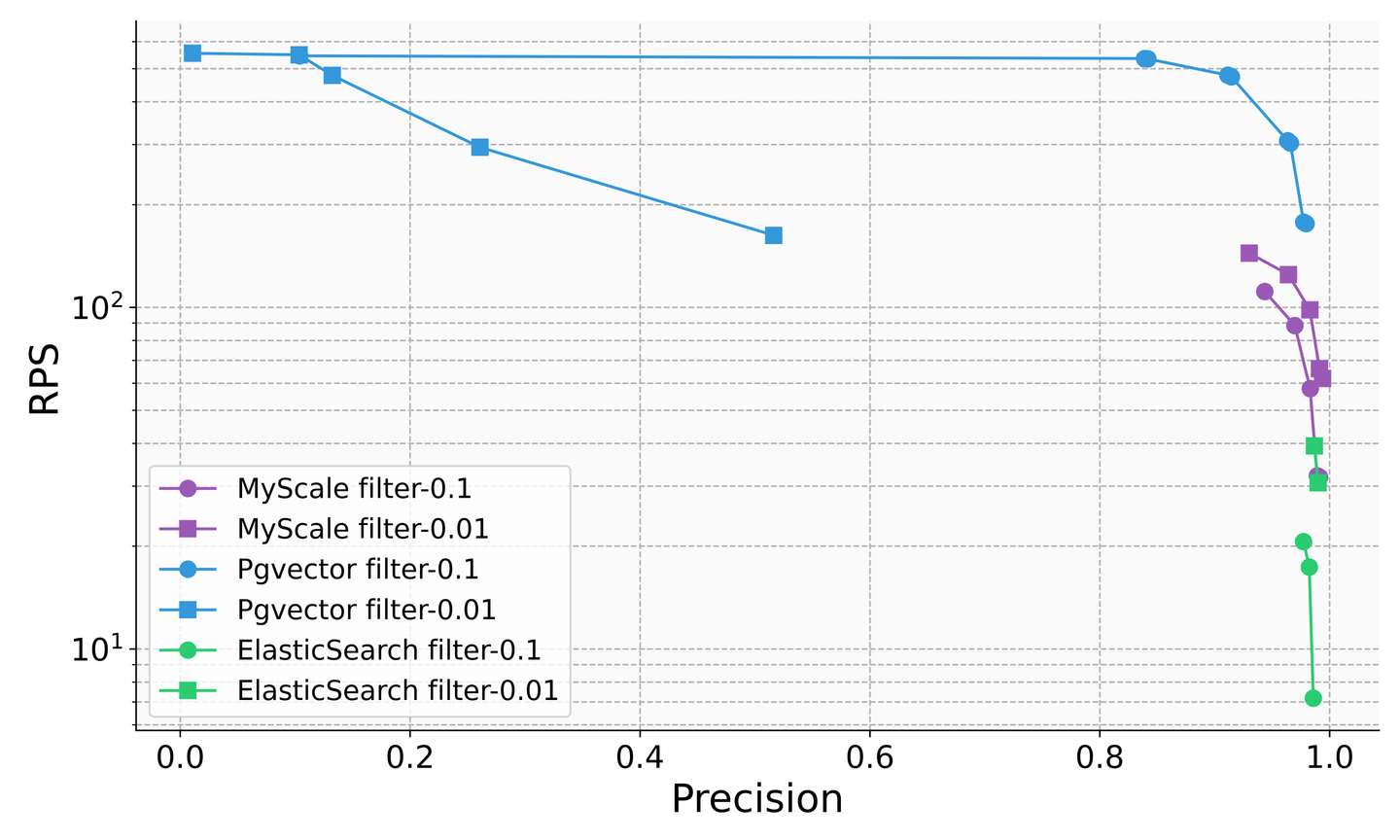
Während herkömmliche Datenbankprodukte die Bedeutung von Vektorabfragen im Zeitalter von LLMs erkannt und begonnen haben, Vektorfähigkeiten hinzuzufügen, gibt es immer noch erhebliche Probleme mit der Genauigkeit ihrer kombinierten Abfragen. Zum Beispiel sinkt die Anzahl der Abfragen pro Sekunde (QPS) von Elasticsearch in Filter-Suchszenarien auf etwa fünf, wenn das Filterverhältnis 0,1 beträgt, und PostgreSQL mit dem pgvector-Plugin hat eine Genauigkeit von nur etwa 50%, wenn das Filterverhältnis 0,01 beträgt. Dies zeigt eine instabile Abfragegenauigkeit und -leistung, die ihren Einsatz stark einschränkt. Im Gegensatz dazu erreicht die SQL-Vektor-Datenbank MyScale in verschiedenen Szenarien von Filterverhältnissen über 100 QPS und 98% Genauigkeit, bei 36% der Kosten von pgvector und 12% der Kosten von Elasticsearch.

# LLM + Big Data: Aufbau einer Agentenplattform der nächsten Generation
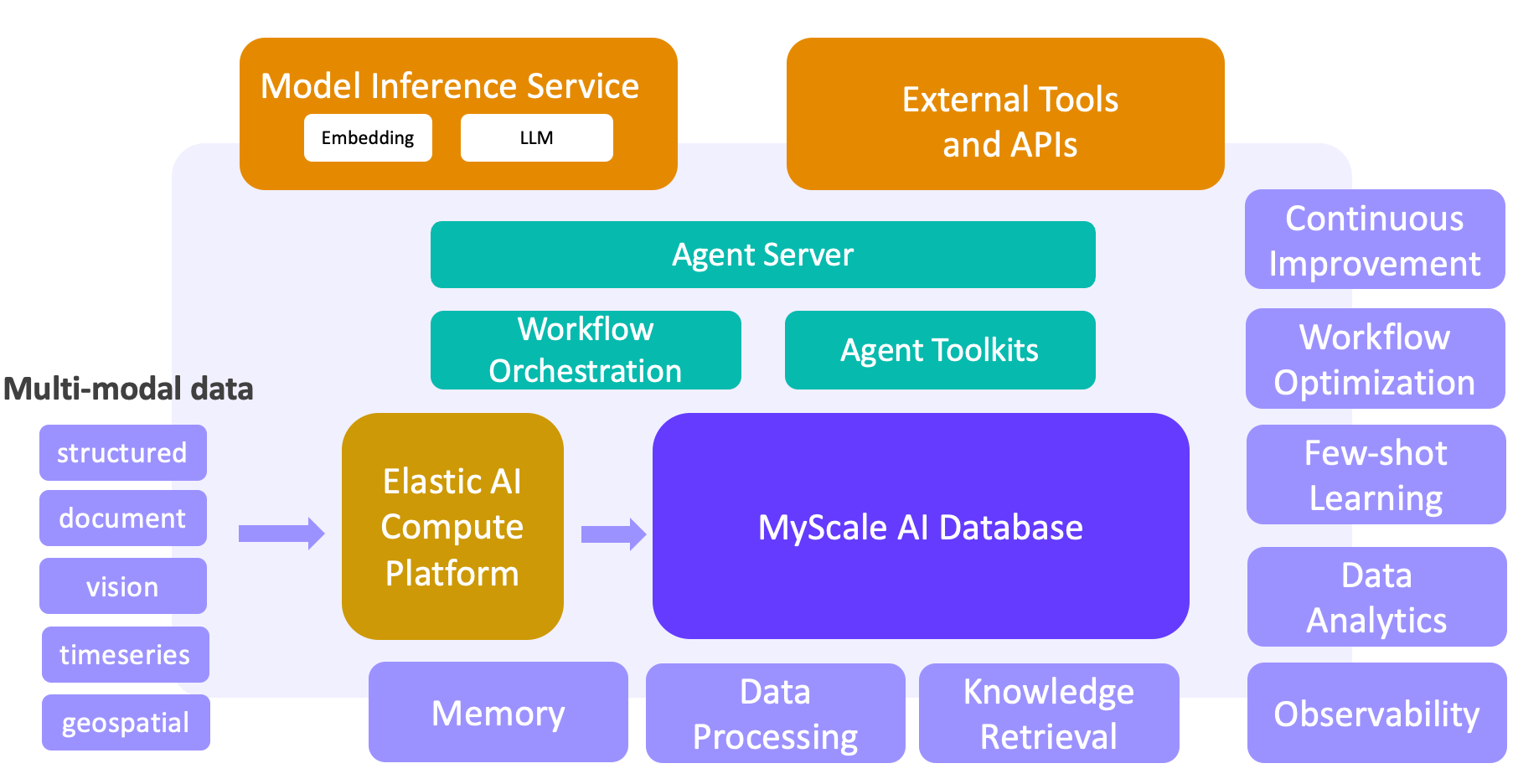
Maschinelles Lernen und Big Data haben den Erfolg von Web- und mobilen Apps vorangetrieben. Aber mit dem Aufstieg von LLMs schalten wir einen Gang höher, um eine neue Generation von LLM + Big Data-Lösungen aufzubauen. Mit MyScaleDB, unserer leistungsstarken SQL-Vektor-Datenbank, werden diese Lösungen entscheidende Fähigkeiten für die Verarbeitung großer Datenmengen, Wissensabruf, Beobachtbarkeit, Datenanalyse, Few-Shot-Learning und mehr freischalten. Basierend auf MyScaleDB entsteht eine geschlossene Schleife zwischen Daten und KI und bildet das Fundament für unsere Agentenplattform der nächsten Generation, die LLM + Big Data kombiniert. Dieser Paradigmenwechsel ist bereits in Bereichen wie wissenschaftlicher Forschung, Finanzen, Industrie und Gesundheitswesen im Gange.
Mit der raschen Entwicklung der Technologie wird voraussichtlich innerhalb der nächsten fünf bis zehn Jahre eine Form von künstlicher Allgemeinintelligenz (AGI) entstehen. In Bezug auf dieses Thema müssen wir uns fragen: Brauchen wir ein statisches, virtuelles Modell oder eine umfassendere Lösung? Daten sind zweifellos das wichtige Bindeglied zwischen LLMs, Benutzern und der Welt. Unsere Vision besteht darin, LLMs und Big Data organisch zu integrieren, um ein professionelleres, Echtzeit- und kollaboratives KI-System zu schaffen, das auch menschliche Wärme und Wertigkeit enthält.
Sie sind herzlich eingeladen, das Open-Source-MyScaleDB-Repository auf GitHub (opens new window) zu erkunden und SQL und Vektoren zu nutzen, um innovative KI-Anwendungen auf Produktionsniveau zu entwickeln.



