
Während Textsuchen ziemlich verbreitet sind, gibt es oft Szenarien, in denen wir nach Bildern mit einem Bild (opens new window) selbst als Suchanfrage suchen müssen – denken Sie an das Finden ähnlicher Fotos oder das Identifizieren von Produkten anhand eines Bildes. Dieser Ansatz, bekannt als bildbasierte Suche (opens new window) oder Rückwärtssuche nach Bildern, hat viele Anwendungsbereiche – beim Online-Shopping, wo man ein Foto von etwas macht, das einem gefällt, um herauszufinden, wo man es kaufen kann, bei der Identifizierung unbekannter Pflanzen oder Wahrzeichen und so weiter. Es ist ein faszinierendes Feld, das immer relevanter wird, da unsere visuellen Daten zunehmen.
Offensichtlich ist es herausfordernd, da wir keine direkte Textanfrage haben, mit der wir übereinstimmen können. Stattdessen brauchen wir eine Methode, um Bilder in einer Form darzustellen, die effektiv verglichen werden kann. Hier kommen Embeddings (opens new window) ins Spiel. Indem Bilder in numerische Vektoren in einem hochdimensionalen Raum umgewandelt werden, ermöglichen Embeddings es uns, die Ähnlichkeit zwischen Bildern auf Basis ihrer Merkmale zu messen.
In diesem Blogbeitrag werden wir einige dieser Methoden durchgehen. Wir werden untersuchen, wie Einbettungsmodelle in der Bildersuche verwendet werden, die dahinterstehenden Algorithmen betrachten und sehen, wie sie das Finden ähnlicher Bilder ermöglichen. Egal, ob Sie ein Entwickler sind, der die Bildersuche implementieren möchte, oder einfach nur neugierig darauf sind, wie sie funktioniert, dieser Beitrag wird einige Einblicke in das Thema geben.
# Klassische Methoden
In der Deep-Learning (opens new window)-Ära geht das Konzept des Findens ähnlicher Bildmerkmale in Suchmaschinen tatsächlich der weit verbreiteten Einführung von Deep-Learning-Techniken voraus. Bereits 2009 hat Google Bilder eine ähnliche Bildfunktion (opens new window) eingeführt, und kurz darauf wurden content-basierte Bildabfragesysteme (CBIR) (opens new window) vorgestellt. Dies wirft eine natürliche Frage auf: Welche Methoden ermöglichten diese Bildsuchen, ohne auf hochmoderne Deep-Learning-Modelle zurückzugreifen?
# SIFT
Die Scale-Invariant Feature Transform (SIFT) (opens new window) war einmal ein hoch effizienter und beliebter Algorithmus vor dem Aufkommen von Deep Learning-Architekturen. SIFT identifiziert Schlüsselpunkte in einem Bild, die invariant gegenüber Skalierung, Rotation und sogar einigen Grad an affiner Verzerrung und Beleuchtungsänderungen sind. Nach der Erkennung dieser Schlüsselpunkte berechnet SIFT Merkmalsdeskriptoren, indem es die lokale Gradienteninformation um jeden Punkt analysiert. Diese Deskriptoren sind in der Regel 128-dimensionale Vektoren, die die lokale Struktur eines Bildes effektiv erfassen. Sie können als Einbettungen in verschiedenen Anwendungen verwendet werden, einschließlich Bildabgleich und -abruf.
SIFT hat auch seine Kritiker. Es hat eine geringe Effizienz für kleinere Bilder, verwendet viel Speicher (stellen Sie sich 128-dimensionale Vektoren für Tausende von Schlüsselpunkten vor) und ist empfindlich gegenüber Beleuchtung. Außerdem wurde es erst kürzlich im Jahr 2020 patentiert und wurde daher in der Community nicht so populär wie andere Methoden.
# SURF
Um einige der Kritikpunkte an der Berechnungskomplexität von SIFT anzugehen, wurde Speeded-Up Robust Features (SURF) (opens new window) als schnellere Alternative eingeführt. SURF opfert etwas an Leistungsgenauigkeit für die Rechengeschwindigkeit. Während SIFT auf Bildableitungen erster Ordnung (Gradienten) für die Merkmalsdetektion und -beschreibung angewiesen ist, verwendet SURF eine Approximation der Bildableitungen zweiter Ordnung (Hessische Matrix) für eine schnellere Berechnung. Die von SURF generierten Merkmalsdeskriptoren sind in der Regel 64-dimensionale Vektoren oder 128-dimensionale Vektoren für die erweiterte Version und eignen sich daher für Einbettungsrepräsentationen in Bildabrufaufgaben.
Neben diesen gibt es noch andere Methoden wie Histogram of Oriented Gradients (HOG), Oriented FAST and Rotated BRIEF (ORB) und mehr.
# Implementierung
Sowohl SIFT als auch SURF lassen sich leicht mit dem OpenCV-Paket implementieren. OpenCV (opens new window) (ab Version 4.4.0) verfügt über eine einsatzbereite SIFT_create()-Funktion, um die SIFT-Objekte zu initialisieren. Diese Objekte können dann verwendet werden, um die Schlüsselpunkte zu erkennen und zu berechnen, zusammen mit ihren Deskriptoren (Einbettungsvektoren).
import cv
image = cv2.imread('AdventureKKH/15.jpg')
grayScaleImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
keypoints, descriptors = sift.detectAndCompute(grayScaleImage, None)
Ein Bild kann viele Schlüsselpunkte haben. Sobald sie gefunden sind, können wir sie einfach zeichnen.
import matplotlib.pyplot as plt
image_with_keypoints = cv2.drawKeypoints(image, keypoints, None)
plt.imshow(cv2.cvtColor(image_with_keypoints, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()

Wie Sie sehen können, gibt es viele Schlüsselpunkte (genau 6433), aber aufgrund des geringen Kontrasts mit dem Bild können die meisten von ihnen nicht identifiziert werden. Als bessere Alternative können wir flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS setzen, um sie etwas besser zu visualisieren.

Die Merkmale (Deskriptoren) können auch mit einem DataFrame besser visualisiert werden. Wie Sie sehen können, haben wir eine Zeile für jeden SIFT-Punkt (Schlüsselpunkte) und jedes Merkmal des Punktes ist 128-dimensional.
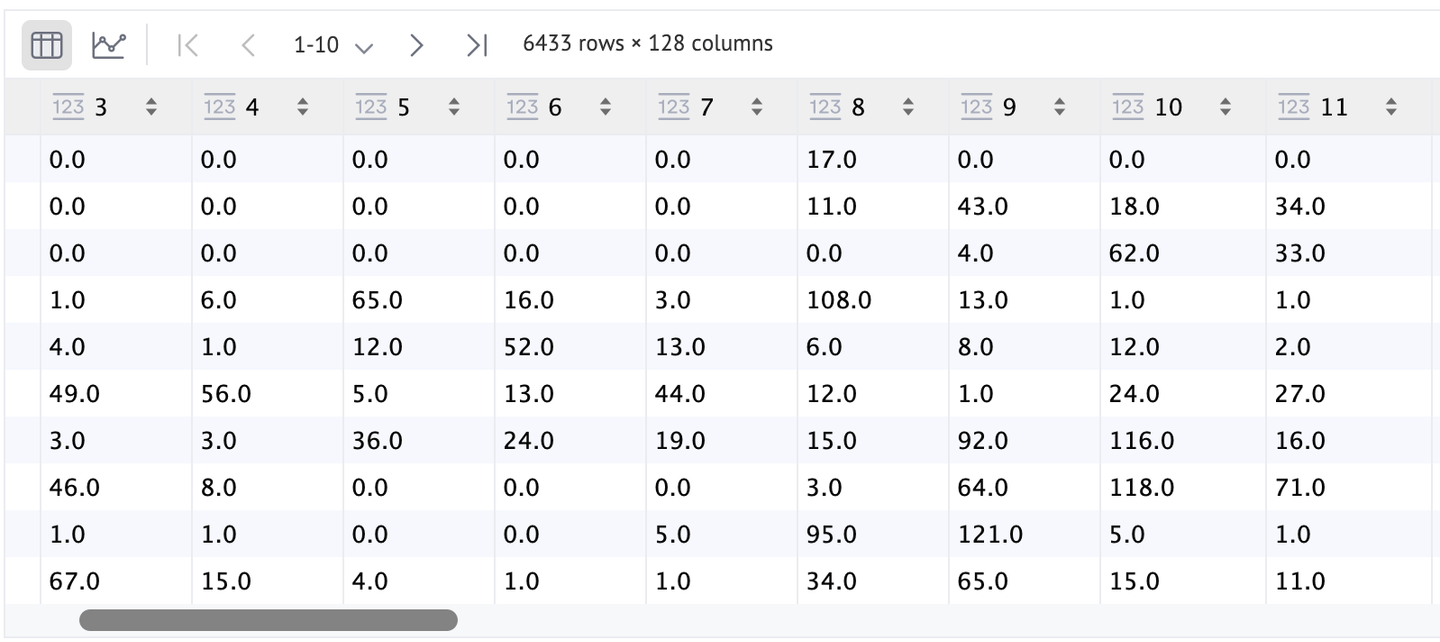
Da SURF ein patentierter Algorithmus ist, darf er nicht direkt aus dem OpenCV verwendet werden. Lassen Sie uns nun auf die gängigeren, auf tiefen Architekturen basierenden Modelle eingehen.
# Einbettungen basierend auf tiefen Architekturen
Aufbauend auf traditionellen Methoden wie SIFT und SURF, die sich auf die Extraktion lokaler Merkmale aus Bildern konzentrieren, bieten Deep-Learning-Modelle einen leistungsstärkeren Ansatz zur Bildrepräsentation. Diese Modelle lernen hierarchische Merkmale (opens new window) direkt aus den Daten und erfassen komplexe Muster und Strukturen, die von handgefertigten Algorithmen nicht leicht identifiziert werden können. Diese Fortschritte ermöglichen robustere und diskriminativere Einbettungen, die Aufgaben wie die Bildersuche und den Abruf verbessern.
Es gibt mehrere einsatzbereite (vortrainierte) Modelle wie VGG (opens new window), ResNets (opens new window), Inception (opens new window), MobileNet (opens new window) und andere. Diese faltenden neuronalen Netzwerke (CNNs) wurden auf großen Datensätzen wie ImageNet trainiert und können daher reiche und vielfältige Merkmale aus Bildern extrahieren. Im Gegensatz zu traditionellen Algorithmen können Deep-Learning-Modelle sowohl niedrigstufige Merkmale (wie Kanten und Texturen) als auch hochstufige Konzepte (wie Objekte und Szenen) erfassen.
Die Verwendung dieser Modelle zur Berechnung von Einbettungen ist relativ einfach. Wir nehmen ein vortrainiertes Modell und extrahieren nicht die Ausgabe aus der letzten Klassifizierungsschicht (opens new window) , sondern die Ausgabe aus einer früheren Schicht - in der Regel diejenige direkt vor der Klassifizierungsschicht. Diese Ausgabe ist ein hochdimensionaler Merkmalsvektor, der als Einbettung dient und das Bild effektiv in einer numerischen Form repräsentiert, die für Ähnlichkeitsvergleiche geeignet ist.
Nehmen wir zum Beispiel ResNet-50, ein beliebtes Deep-Learning-Modell, das für seine Restverbindungen bekannt ist, die dazu beitragen, tiefere Netzwerke effektiv zu trainieren. Indem wir seine letzte Schicht entfernen, können wir Einbettungen für ein gegebenes Bild erhalten:
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True)
model = torch.nn.Sequential(*(list(model.children())[:-1]))
with torch.no_grad():
embedding = model(image.unsqueeze(0))
# Einbettungen basierend auf ViT
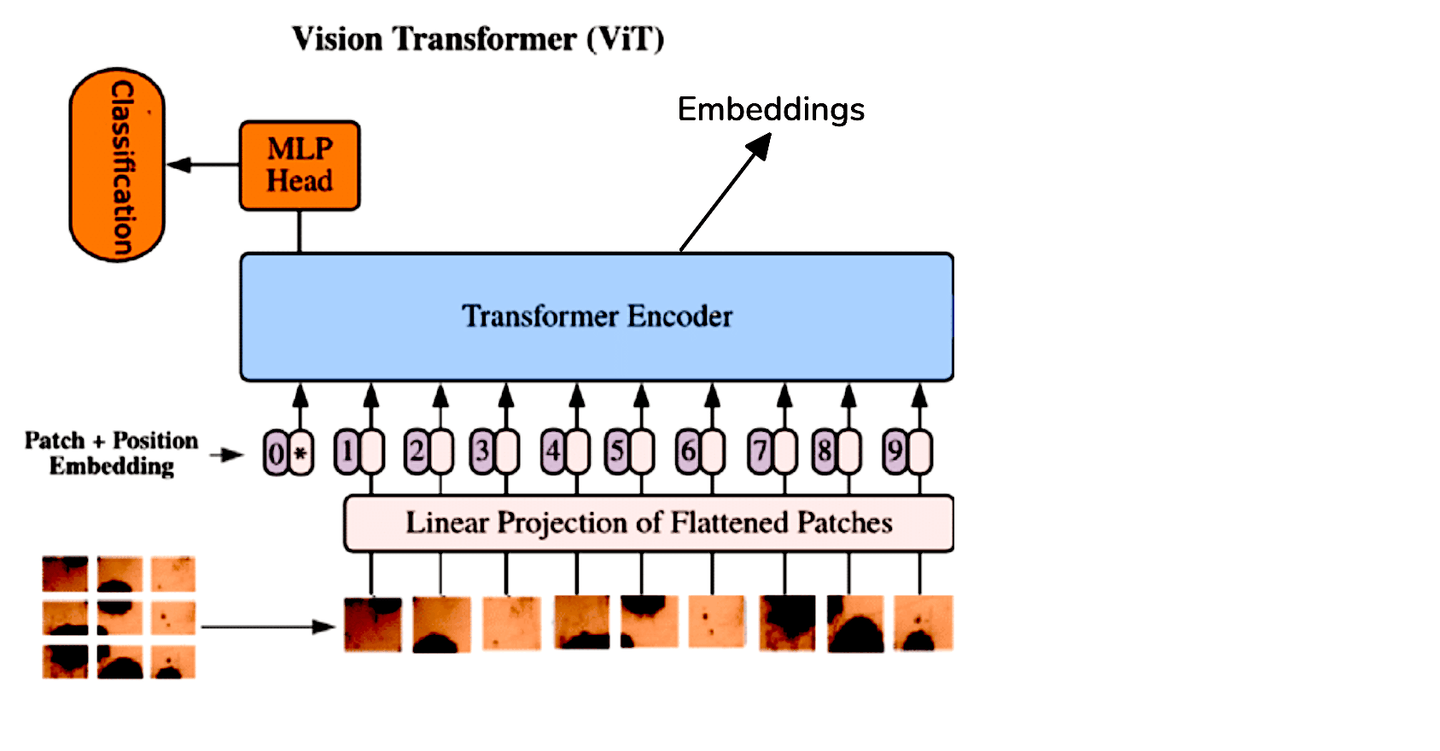
Während CNNs der Standard für Bildverarbeitungsaufgaben waren, bieten Vision Transformers (ViT) (ViT) einen anderen Ansatz, indem sie die Transformer-Architektur auf Bilddaten anwenden. ViT behandelt ein Bild als eine Sequenz von Patches und verarbeitet es ähnlich wie Transformer Sequenzen in der natürlichen Sprachverarbeitung. Diese Methode ermöglicht es dem Modell, globale Beziehungen innerhalb des Bildes effektiver zu erfassen.
Aufgrund der architektonischen Unterschiede zwischen ViTs und CNNs extrahieren wir Einbettungen aus ViTs, indem wir die Ausgabetoken des Transformer-Encoders durchschnittlich berechnen. Zur Vereinfachung können wir vortrainierte ViT-Modelle verwenden, die über Hugging Face verfügbar sind:
from transformers import ViTModel, ViTFeatureExtractor
import torch
model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
image = Image.open('AdventureKKH/15.jpg')
inputs = feature_extractor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
embedding = outputs.last_hidden_state.mean(dim=1)
print(embedding)
Da wir die Standard-ViT-Architektur verwenden (die in dem ursprünglichen Paper [1] verwendet wird), hat der Einbettungsvektor 768 Dimensionen, wie wir hier sehen können. Wenn Sie eine bessere Auflösung wünschen, können Sie zu ViT-Large oder ViT-Huge wechseln (jeweils 1024 und 1280 Längen).

# Feinabstimmung
Bei der Arbeit mit spezialisierten Bildtypen, die eine Modellfeinabstimmung erfordern, sei es mit einem Convolutional Neural Network (CNN) oder Vision Transformer (ViT), ist es oft vorteilhaft, alle außer der letzten Schicht des Modells einzufrieren. Dieser Ansatz ermöglicht die Feinabstimmung der letzten Schicht, ohne die gelernten Merkmale der vorhergehenden Schichten zu verändern.
Nach Abschluss des Feinabstimmungsprozesses kann die letzte Schicht entfernt werden, ähnlich wie bei früheren Verfahren. Mit dem modifizierten Modell können Bilder dann durch den Vorwärtsdurchlauf geleitet werden, um die gewünschten Einbettungen zu generieren. Diese Methode stellt sicher, dass das Modell sein grundlegendes Verständnis beibehält und sich gleichzeitig an die Feinheiten der spezifischen Bilddaten anpasst.
# Selbstüberwachte Methoden
Schauen Sie sich einfach Ihren eigenen Bilderordner an und beginnen Sie mit der Annotation. Sie werden nach 50 oder 100 Bildern sicher müde werden. Die Feinabstimmung erfordert eine große Menge an gelabelten Daten, die leider weder leicht verfügbar noch die Zeit wert sind. Eine bessere Lösung besteht daher darin, das selbstüberwachte Lernen zu verwenden. Es gibt eine Reihe von selbstüberwachten Lernmethoden, wie:
- SimCLR
- MoCo
- CLIP
Sowohl SimCLR als auch MoCo erzeugen zwei Kopien des Eingangsbildes und deren Einbettungen. Dann wird die zugrunde liegende Architektur (in der Regel ein ResNet) trainiert, um sicherzustellen, dass der Kontrastverlust minimiert wird.
CLIP hingegen verwendet sowohl Bild- als auch Texteinbettungen, um das Modell zu trainieren. Diese Methode ist berühmt geworden, da wir seitdem eine Reihe ähnlicher Methoden sehen. Beispiele sind BEiT (BErt Pre-training of Image Transformers), VisualBERT und ViLBERT.
Hinweis: Um mehr über CLIP zu erfahren, können Sie unseren Blog über die Zero-Shot-Klassifizierung mit CLIP (opens new window) lesen.
Hier verwenden wir Moco (v2), um Bild-Einbettungen zu berechnen.
import torch
import torch.nn as nn
from torchvision import models
class MoCoResNet(nn.Module):
def __init__(self, base_encoder=models.resnet50, feature_dim=128):
super(MoCoResNet, self).__init__()
self.encoder_q = base_encoder(pretrained=False)
self.encoder_q.fc = nn.Identity() # Entfernen der letzten Schicht
def forward(self, x):
return self.encoder_q(x)
model = MoCoResNet()
checkpoint = torch.load('/Users/talha/Downloads/moco_v2_800ep_pretrain.tar', map_location='mps', weights_only=True)
model.load_state_dict(checkpoint['state_dict'])
Bild-Einbettungen können genauso berechnet werden wie zuvor für die vortrainierten normalen CNN-Modelle.
with torch.no_grad():
embedding = model(image.unsqueeze(0))
Es gibt auch hier einen 2048-dimensionalen Vektor zurück, wie wir bestätigen können.

# Anwendungen
Diese Bild-Einbettungen können in einigen Bildsuchanwendungen sehr hilfreich sein. Zum Beispiel:
- E-Commerce: Wie bereits erwähnt, kann es beim Online-Shopping sehr hilfreich sein. Es kann auf verschiedene Arten verwendet werden. Und es ist eine von vielen Anwendungen von CBIR.
- Bildklassifizierung: Wir können diese Einbettungen auch verwenden, um CNNs und ViTs zu trainieren.
- Bildbeschreibung: Wenn wir auch Texteinbettungen verwenden, können wir ein Bildbeschreibungssystem erstellen. CLIP ist ein sehr gutes Beispiel.
# Vergleich
Es wäre gut, eine vergleichende Analyse aller entsprechenden Modelle anzubieten.
| Algorithmus | Geschwindigkeit | Stärken | Schwächen |
|---|---|---|---|
| SIFT | Moderat | Kann mit weniger Daten arbeiten | Nicht skalierbar, langsamer für eine nicht-DL-Methode |
| SURF | Schnell | Schneller | Nicht so robust wie andere Methoden |
| Vortrainierte CNNs | Schnell | Eine Reihe von Modellen zur Auswahl, robust | Zu generisch |
| Vortrainierte ViTs | Moderat bis schnell | Robust | Nicht signifikant |
| Feinabgestimmte Modelle | Langsam (Inferenz ist schnell, aber das Training kann viel Zeit in Anspruch nehmen) | Kann sich besser an die Ziel-Daten anpassen, kann die besten Ergebnisse liefern | Benötigt eine große Menge an annotierten Bildern und Trainingsressourcen |
| Selbstüberwachte Modelle | Hängt vom Trainingssatz ab, ist in der Regel langsam | Benötigt keine annotierten Bilder, liefert recht gute Ergebnisse | Benötigt Trainingsressourcen |

# Fazit
Einbettungsmethoden haben die Bildersuche transformiert und ermöglichen es uns, visuelle Inhalte mit beispielloser Geschwindigkeit und Präzision zu lokalisieren. Von klassischen Methoden wie SIFT und SURF bis hin zu modernen Deep-Learning-Architekturen hat die Entwicklung von Bild-Einbettungen diese Transformation ermöglicht.
Die Zukunft der Bild-Einbettungen sieht noch aufregender aus, mit Trends wie multimodalen Einbettungen (Kombination von Text-, Bild- und Audio-Daten) und selbstüberwachten Methoden, die die Abhängigkeit von großen gelabelten Datensätzen beseitigen. Mit Datenbanken wie MyScale (opens new window), die SQL und Vektor-Suche kombinieren, ist es jetzt einfacher denn je, fortschrittliche Bildsuchanwendungen zu entwickeln. MyScale unterstützt leistungsstarke Bild-Einbettungen und schnelle Abfrageergebnisse durch Vektorindizes und bietet eine solide Grundlage für zukünftige Innovationen in der Bildersuche.
Mit dem Fortschreiten der Forschung werden wir voraussichtlich noch schnellere, genauere und intelligentere Bildersuchfunktionen sehen. Diese Fortschritte werden nicht nur die Benutzererfahrungen auf verschiedenen Plattformen verbessern, sondern auch die Art und Weise neu definieren, wie wir mit visuellen Informationen online interagieren - indem wir die Bildersuche so natürlich und effizient gestalten wie die Textsuche.



