
El crecimiento explosivo de los datos globales, que se proyecta que alcance los 181 zettabytes para 2025 (opens new window), con un 80% de ellos siendo no estructurados, plantea un desafío para las bases de datos tradicionales que no pueden manejar eficazmente los datos de texto no estructurados. La búsqueda de texto completo aborda esto al permitir un acceso intuitivo y eficiente a los datos de texto no estructurados, lo que permite a los usuarios buscar según temas o ideas clave.
MyScaleDB (opens new window), un fork de código abierto de ClickHouse optimizado para la búsqueda vectorial, ha mejorado sus capacidades de búsqueda de texto con la integración de Tantivy (opens new window), una biblioteca de motor de búsqueda de texto completo.
Esta actualización beneficia significativamente a aquellos que utilizan ClickHouse para el registro, a menudo como sustituto de Elasticsearch o Loki. También beneficia a los usuarios que aprovechan MyScaleDB en la Generación de Recuperación Aumentada (RAG) con modelos de lenguaje grandes (LLMs), combinando la búsqueda vectorial y de texto para una mayor precisión.
En esta publicación, exploraremos los detalles técnicos del proceso de integración y cómo mejora el rendimiento de MyScaleDB.
# Limitaciones de la búsqueda de texto nativa de ClickHouse
ClickHouse proporciona funciones básicas de búsqueda de texto como hasToken, startsWith y multiSearchAny, adecuadas para escenarios de consulta de términos simples. Sin embargo, para requisitos más complejos como consultas de frases, coincidencia de texto difuso y clasificación de relevancia BM25, estas funciones son insuficientes. Por lo tanto, en MyScaleDB, introdujimos Tantivy como la implementación subyacente para la indexación de texto completo, dotando a MyScaleDB de capacidades de búsqueda de texto completo. El índice de texto completo de Tantivy admite consultas de texto difuso, clasificación de relevancia BM25 y acelera las funciones existentes como la coincidencia de términos hasToken y multiSearchAny.
# Por qué elegimos Tantivy
Tantivy es una biblioteca de motor de búsqueda de texto completo de código abierto escrita en Rust. Está diseñada para ser rápida y eficiente, especialmente en el manejo de grandes volúmenes de datos de texto.
# Comprendiendo los principios fundamentales de Tantivy
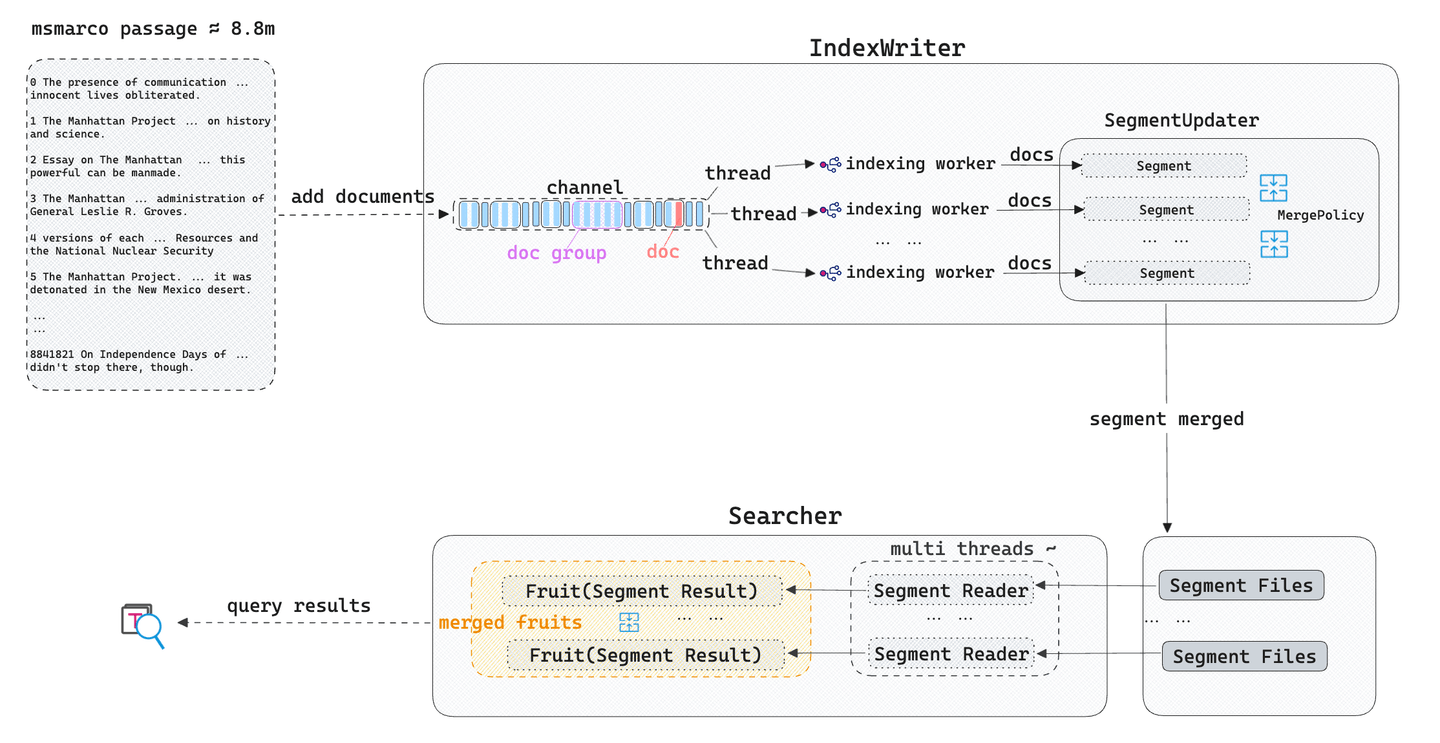
Construcción del índice: Tantivy tokeniza el texto de entrada, dividiéndolo en tokens independientes. Luego crea un índice invertido (lista de publicaciones) y lo escribe en archivos de índice (segmentos). Mientras tanto, los hilos de fondo de Tantivy utilizan estrategias de fusión para combinar y actualizar estos archivos de índice de segmento.
Ejecución de búsquedas de texto: Cuando un usuario inicia una consulta de búsqueda de texto, Tantivy analiza la declaración de consulta, extrae los tokens y en cada segmento, ordena y puntúa los documentos en función de las condiciones de consulta y el algoritmo de relevancia BM25. Finalmente, los resultados de la consulta de estos segmentos se fusionan en función de las puntuaciones de relevancia y se devuelven al usuario.
# Características clave de Tantivy
- Clasificación de relevancia BM25: Elasticsearch, Lucene y Solr utilizan todos BM25 como el algoritmo de clasificación de relevancia predeterminado. La puntuación BM25 evalúa la precisión y relevancia de las búsquedas de texto, mejorando la experiencia de búsqueda del usuario.
- Tokenizadores configurables: Admite varios tokenizadores de idiomas, adaptándose a diversas necesidades de tokenización de los usuarios.
- Consultas de lenguaje natural: Los usuarios pueden combinar de manera flexible las consultas de texto utilizando palabras clave como AND, OR, IN, lo que reduce la complejidad de la escritura de declaraciones SQL.
Para obtener más funcionalidades, consulta la documentación de Tantivy (opens new window).
# Integración perfecta con MyScaleDB
MyScaleDB, escrito en C++, se desarrolla sobre la base de ClickHouse y sirve como un motor de búsqueda robusto para aplicaciones nativas de IA. Para enriquecer la funcionalidad de búsqueda de texto completo de MyScaleDB, necesitábamos una biblioteca que pudiera integrarse directamente en MyScaleDB.
Tantivy es una biblioteca de búsqueda de texto completo inspirada en Apache Lucene. A diferencia de Elasticsearch, Apache Solr y otros motores similares, Tantivy se puede integrar en varias bases de datos como MyScaleDB. Tantivy está escrito en el lenguaje de programación Rust, que se puede integrar fácilmente con programas C++ utilizando Corrosion (opens new window).
# El proceso de integración
# Creación de un envoltorio C++ para Tantivy
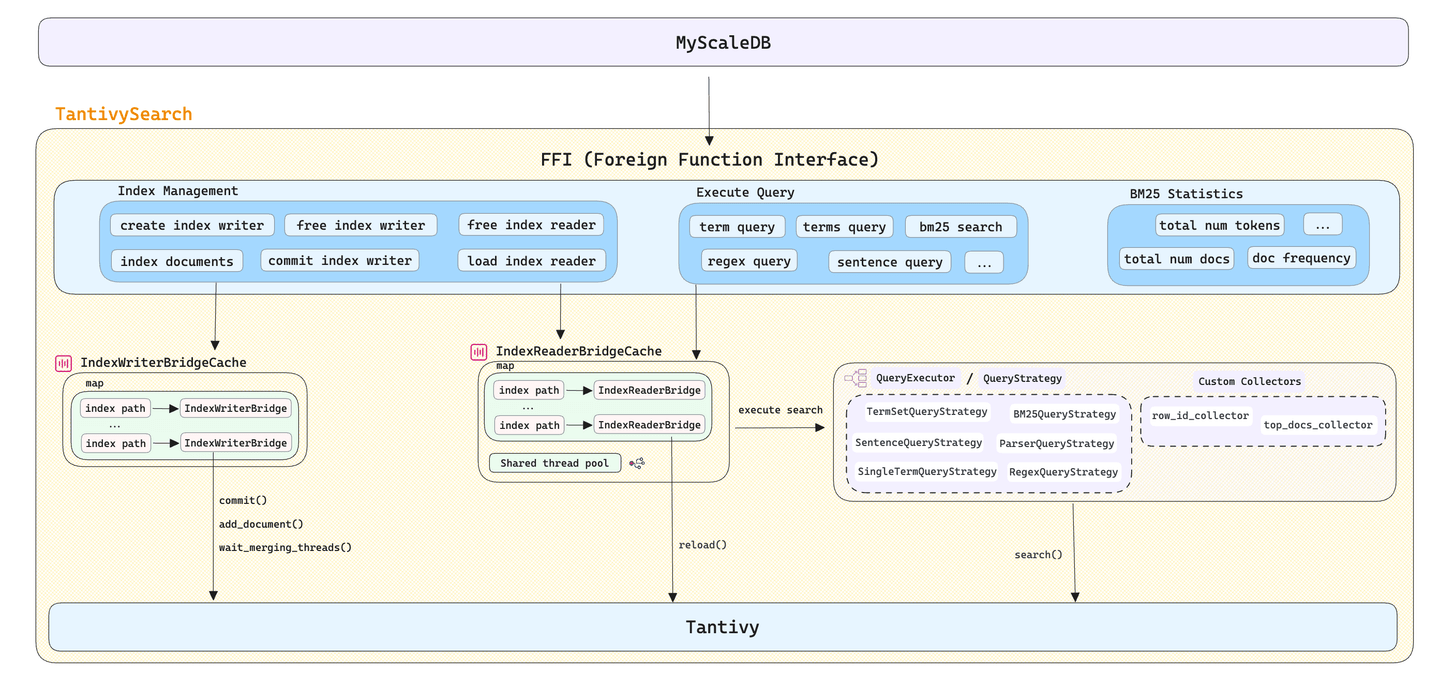
No pudimos usar directamente la biblioteca Tantivy en MyScaleDB. Para abordar el desafío del desarrollo entre lenguajes (C++ y Rust), desarrollamos tantivy-search (opens new window), un envoltorio C++ para Tantivy. Proporciona un conjunto de interfaces FFI para MyScaleDB, lo que permite la gestión directa de la creación, destrucción, carga y manejo flexible de los requisitos de búsqueda de texto en varios escenarios.
# Implementación de Tantivy como un índice de salto en ClickHouse
El índice de salto de ClickHouse (opens new window) se utiliza principalmente para acelerar las consultas con cláusulas WHERE. Implementamos un nuevo tipo de índice de salto llamado FTS (Búsqueda de Texto Completo), con Tantivy como implementación subyacente. Por lo tanto, para cada parte de datos en ClickHouse con el índice FTS, construimos un índice Tantivy para ella. Como se mencionó anteriormente, Tantivy genera varios archivos de segmento para cada índice. Para reducir el número de archivos que deben almacenarse en una parte de datos, MyScaleDB serializa estos archivos de segmento en dos archivos y los almacena en la parte de datos. El archivo skp_idx_[nombre_del_índice].meta registra el nombre y el desplazamiento de cada archivo de segmento, mientras que el archivo skp_idx_[nombre_del_índice].data almacena los datos originales de cada archivo de segmento.
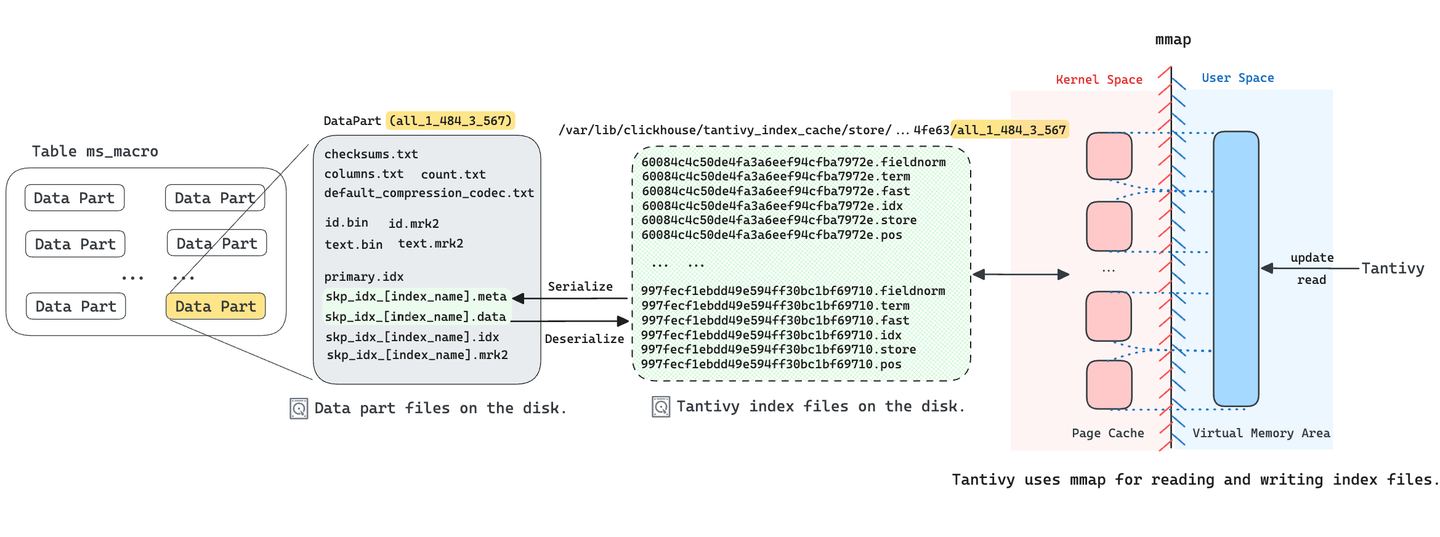
Tantivy utiliza el mapeo de memoria (mmap) para acceder a los archivos de segmento. Este enfoque no solo mejora la velocidad de búsqueda concurrente, sino que también mejora la eficiencia de la construcción del índice. Dado que Tantivy no puede asignar directamente el archivo skp_idx_[nombre_del_índice].data a la memoria, cuando un usuario inicia una consulta que necesita el índice FTS, MyScaleDB deserializará los archivos de índice (.meta y .data) a archivos de segmento de Tantivy en un directorio temporal y cargará el índice Tantivy. Estos archivos de segmento deserializados se cargan mediante el mapeo de memoria por Tantivy para ejecutar varios tipos de búsquedas de texto. Por lo tanto, la solicitud de consulta inicial de los usuarios puede tardar varios segundos en completarse.
En el servicio administrado de MyScaleDB (opens new window), almacenamos los archivos de índice de segmento de Tantivy en SSD NVMe. Esto reduce el tiempo de espera de E/S y mejora el rendimiento de mmap en escenarios que requieren acceso aleatorio y manejo de excepciones de falta de página.
# Mejora de las funciones de búsqueda de texto nativas de ClickHouse
Cuando se inician solicitudes con condiciones de filtrado en columnas que contienen índices FTS, MyScaleDB accede primero al índice FTS. Recupera todos los identificadores de fila de la columna que cumplen las condiciones de filtro SQL y almacena estos identificadores de fila en una estructura de datos de mapa de bits avanzada, conocida como mapa de bits comprimido (opens new window). Al recorrer los gránulos, determinamos si el rango de identificadores de fila de un gránulo se interseca con el mapa de bits, lo que indica si se puede descartar el gránulo. En última instancia, MyScaleDB solo accede a aquellos gránulos que no se han descartado, logrando así la aceleración de la consulta.
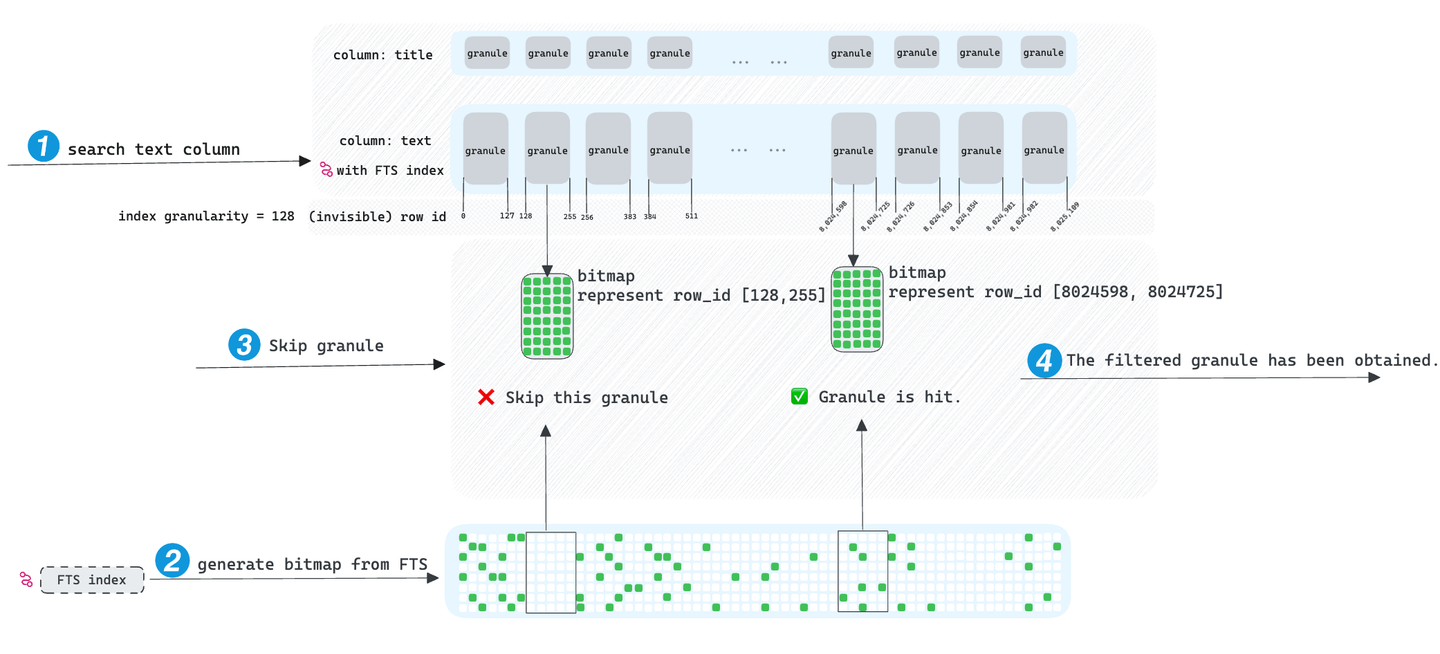
Idealmente, el índice de salto acelera las consultas, pero encontramos que su efecto es limitado. Si el término buscado aparece en casi todos los gránulos, MyScaleDB solo puede omitir un pequeño número de gránulos, lo que requiere el acceso a un gran número de gránulos para la consulta, lo que hace que el índice de salto sea ineficaz en tales casos. Emocionantemente, MyScaleDB introdujo la función TextSearch, que no solo aborda la ineficiencia del índice de salto, sino que también aporta otras funcionalidades prácticas.
# Introducción de la función TextSearch
Para aprovechar al máximo las capacidades de búsqueda de texto completo de Tantivy, incorporamos la función TextSearch en MyScaleDB. Esto permite a los usuarios ejecutar solicitudes de recuperación de texto difuso y obtener un conjunto de documentos ordenados por relevancia de puntuación BM25. Además, los usuarios pueden utilizar la consulta de lenguaje natural dentro de la función TextSearch, lo que reduce significativamente la complejidad de la escritura de SQL.
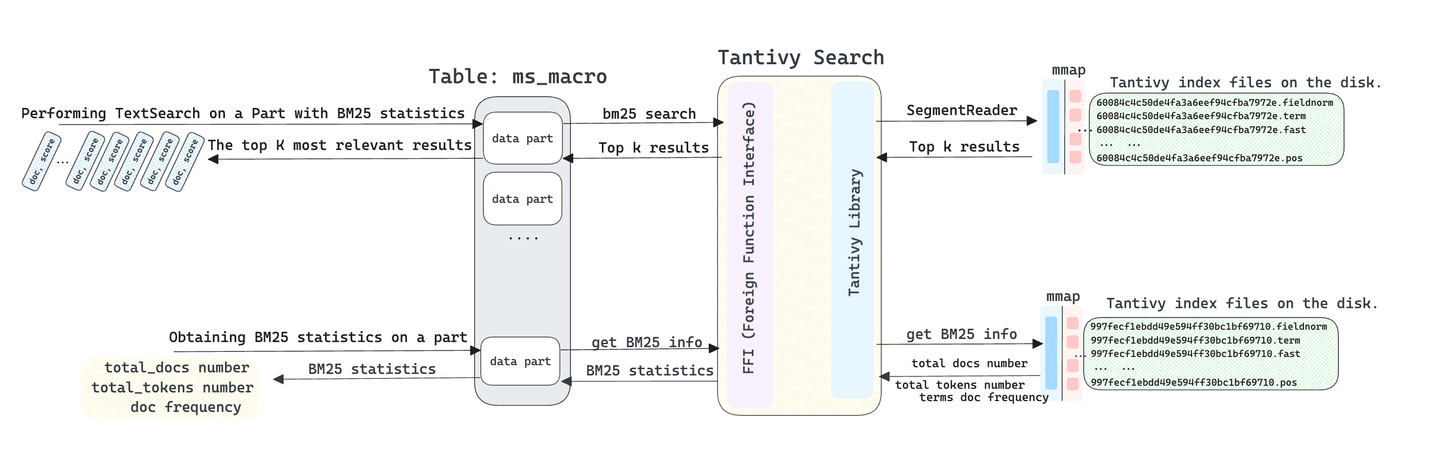
La función TextSearch recupera los K resultados más relevantes de la tabla al buscar texto. En cuanto a la ejecución, MyScaleDB realiza de manera concurrente la recuperación de texto de TextSearch en todas las partes de datos. En consecuencia, cada parte recopila los K resultados más relevantes ordenados por puntuación BM25. Luego, MyScaleDB agrega estos resultados obtenidos de las partes de datos en función de las puntuaciones BM25. Finalmente, MyScaleDB conserva los K resultados principales según las cláusulas ORDER BY y LIMIT especificadas en la consulta SQL del usuario. La función TextSearch no lee directamente los datos de la parte de datos. En cambio, recupera los resultados de búsqueda de índice directamente a través de Tantivy, lo que la hace extremadamente rápida.
Es importante tener en cuenta que MyScaleDB utiliza múltiples partes de datos para almacenar datos, y cada parte de datos es responsable de almacenar una parte de los datos de la tabla completa. No podemos simplemente promediar las puntuaciones BM25 correspondientes a los mismos textos de respuesta obtenidos de cada parte y ordenarlos. Esto se debe a que cada parte solo considera el "número total de documentos", el "número total de tokens" y la "frecuencia de documentos" dentro de la parte actual al calcular las puntuaciones BM25, sin tener en cuenta otros parámetros relacionados con el algoritmo BM25 dentro de otras partes. Por lo tanto, esto llevaría a una disminución en la precisión de los resultados finales fusionados.
Para abordar este problema, primero calculamos las estadísticas BM25 dentro de cada parte antes de iniciar la consulta TextSearch. Luego, los consolidamos en estadísticas BM25 lógicamente correspondientes para la tabla completa. Además, hemos modificado la biblioteca Tantivy para admitir el uso de información BM25 compartida. Esto garantiza la corrección de los resultados de búsqueda de TextSearch en varias partes.
A continuación se muestra un ejemplo sencillo de cómo utilizar la función TextSearch para realizar una búsqueda básica de texto en el conjunto de datos ms_macro. Para obtener más información sobre cómo utilizar la función TextSearch, consulta nuestro documento de TextSearch (opens new window).
SELECT
id,
text,
TextSearch(text, 'who is Obama') AS score
FROM ms_macro
ORDER BY score DESC
LIMIT 5
Salida:
| id | text | score |
|---|---|---|
| 2717481 | Sasha Obama Biography. Name at birth: Natasha Obama. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. Sasha Obama has one older sister, Malia, who was born in 1998. | 15.448088 |
| 5016433 | Sasha Obama Biography. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. Sasha Obama has one older sister, Malia, who was born in 1998. | 15.407547 |
| 564474 | Michelle Obama net worth: $11.8 Million. Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $11.8 million.Michelle Obama was born January 17, 1964 in Chicago, Illinois.ichelle Obama net worth: $11.8 Million. Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $11.8 million. | 14.88242 |
| 5016431 | Name at birth: Natasha Obama. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. | 14.63069 |
| 1939756 | Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $40 million. Michelle Obama was born January 17, 1964 in Chicago, Illinois. She is best known for being the wife of the 44th President of the United States, Barack Obama. She attended Princeton University, graduating cum laude in 1985, and went on to earn a law degree from Harvard Law School in 1988. | 14.230849 |

# Evaluación de rendimiento
Comparamos el rendimiento de búsqueda de MyScaleDB bajo diferentes índices utilizando clickhouse-benchmark (opens new window), incluido el índice FTS implementado en MyScaleDB, el índice invertido incorporado de ClickHouse y el escenario sin ningún índice.
# Configuración de referencia
# Detalles del conjunto de datos
Para probar el rendimiento de TextSearch, utilizamos el conjunto de datos ms_macro (opens new window) proporcionado por Microsoft. El conjunto de datos ms_macro consta de 8,841,823 registros de texto, que convertimos al formato parquet para facilitar la importación en MyScaleDB. Además, creamos un conjunto de archivos SQL para probar el rendimiento de búsqueda en función de diferentes frecuencias de palabras. Los lectores pueden acceder al conjunto de datos utilizado en esta prueba a través de S3:
- ms_macro_text.parquet (opens new window): 1.6GB
- ms_macro_query_files.tar.gz (opens new window): 5.8MB
El archivo ms_macro_query_files.tar.gz abarca todos los archivos SQL utilizados en esta prueba. Por ejemplo, el nombre de cada archivo SQL indica la frecuencia de la palabra buscada en el conjunto de datos ms_macro y el número de consultas incluidas en el archivo SQL. Por ejemplo, el archivo ms_macro_count_hastoken_100_100k.sql contiene 100k consultas y la palabra en cada consulta aparece 100 veces en el conjunto de datos.
A continuación se muestran ejemplos de consultas hasToken y TextSearch:
SELECT count(*) FROM ms_macro WHERE hasToken(text, 'Crimp');
SELECT count(*) FROM (
SELECT TextSearch(text, 'Crimp') AS score
FROM ms_macro ORDER BY score DESC LIMIT 10000000
) as subquery;
# Entorno de prueba
A pesar de que nuestro entorno de prueba tiene 64GB de memoria, el consumo de memoria de MyScaleDB durante las pruebas se mantiene alrededor de 2.5GB.
| Item | Value |
|---|---|
| Versión del sistema | Ubuntu 22.04.3 LTS |
| CPU | 16 núcleos (AMD Ryzen 9 6900HX) |
| Velocidad de memoria | 64GB |
| Disco | 512GB NVMe SSD |
| MyScaleDB | v1.5 |
# Procedimiento de importación de datos
Crear una tabla para el conjunto de datos ms_macro:
CREATE TABLE default.ms_macro
(
`id` UInt64,
`text` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
Importar los datos directamente desde S3 a MyScaleDB:
INSERT INTO default.ms_macro
SELECT * FROM
s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/ms_macro_text.parquet','Parquet');
Combinar las partes de datos de ms_macro en una para mejorar la velocidad de búsqueda. Ten en cuenta que esta operación es opcional.
OPTIMIZE TABLE default.ms_macro final;
SELECT count(*) FROM system.parts WHERE table = 'ms_macro';
Salida:
| count() |
|---|
| 1 |
Verificar si ms_macro contiene 8,841,823 registros:
SELECT count(*) FROM default.ms_macro;
Salida:
| count() |
|---|
| 8841823 |
# Creación de índices
Evaluaremos el rendimiento de tres tipos de índices: FTS, Inverted y None (un escenario sin ningún índice).
- Crear índice FTS
-- Asegúrate de que al crear el índice FTS, no exista ningún otro índice en la columna de texto de ms_macro.
ALTER TABLE default.ms_macro DROP INDEX IF EXISTS fts_idx;
ALTER TABLE default.ms_macro ADD INDEX fts_idx text TYPE fts;
ALTER TABLE default.ms_macro MATERIALIZE INDEX fts_idx;
- Crear índice Inverted
-- Asegúrate de que al crear el índice Inverted, no exista ningún otro índice en la columna de texto de ms_macro.
ALTER TABLE default.ms_macro DROP INDEX IF EXISTS inverted_idx;
ALTER TABLE default.ms_macro ADD INDEX inverted_idx text TYPE inverted;
ALTER TABLE default.ms_macro MATERIALIZE INDEX inverted_idx;
- Ningún índice: Asegúrate de que la columna de texto de la tabla ms_macro no contenga ningún índice.
# Ejecución de la prueba de referencia
Utiliza clickhouse-benchmark para realizar pruebas de estrés. Para obtener más instrucciones de uso, consulta la documentación de ClickHouse (opens new window).
clickhouse-benchmark -c 8 --timelimit=60 --randomize --log_queries=0 --delay=0 < ms_macro_count_hastoken_100_100k.sql -h 127.0.0.1 --port 9000
# Resultados de evaluación
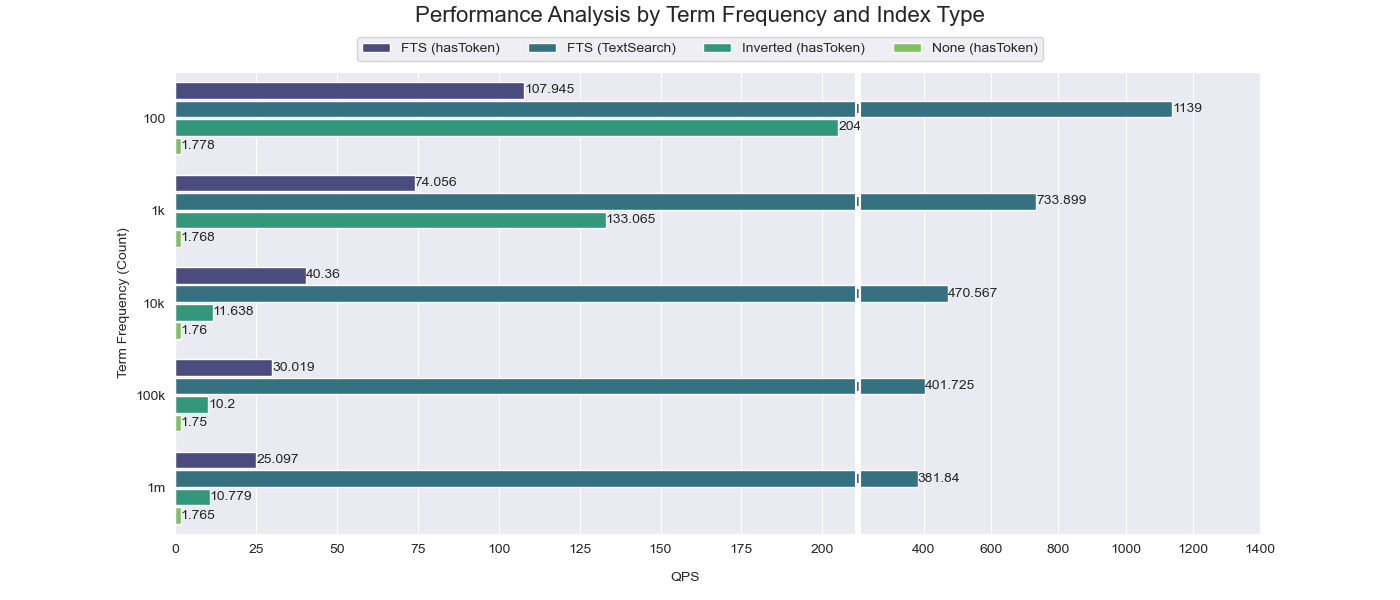
A partir de los resultados de comparación, es evidente que cuando la frecuencia de la palabra buscada es alta (100K~1M), el efecto de aceleración del índice de salto es bastante limitado (solo una mejora de diez veces en comparación con el rendimiento sin establecer ningún índice). Sin embargo, cuando la frecuencia de la palabra buscada es baja (100~1K), el índice de salto puede lograr un efecto de aceleración significativo (hasta una mejora de cien veces en comparación con el rendimiento sin establecer ningún índice).
La función TextSearch, por otro lado, supera consistentemente tanto al índice de salto como al índice invertido en todos los escenarios. Esto se debe a que TextSearch aprovecha directamente las capacidades de búsqueda de texto completo de Tantivy, evitando la necesidad de escanear gránulos y en su lugar recuperando resultados directamente del índice. Esto resulta en un proceso de búsqueda mucho más rápido y eficiente.
# Conclusión
La integración de Tantivy en MyScaleDB ha mejorado significativamente sus capacidades de búsqueda de texto, convirtiéndolo en una herramienta poderosa para el análisis de datos de texto y la Generación de Recuperación Aumentada (RAG) con modelos de lenguaje grandes (LLMs). Al abordar las limitaciones de las funciones de búsqueda de texto nativas de ClickHouse e introducir características avanzadas como la clasificación de relevancia BM25, los tokenizadores configurables y las consultas de lenguaje natural, MyScaleDB ahora ofrece una solución sólida y eficiente para requisitos de búsqueda de texto complejos.
La implementación de un envoltorio C++ para Tantivy, la creación de un nuevo tipo de índice de salto y la introducción de la función TextSearch han contribuido a esta mejora. Estas mejoras no solo aumentan el rendimiento de MyScaleDB, sino que también amplían sus casos de uso, convirtiéndolo en la opción principal para la búsqueda de texto eficiente y precisa en diversas aplicaciones.
Para obtener más información sobre cómo utilizar la función TextSearch y otras características, consulta nuestra documentación sobre búsqueda de texto (opens new window) y búsqueda híbrida (opens new window).
Esperamos que esta publicación haya proporcionado información valiosa sobre el proceso de integración y los beneficios que aporta a MyScaleDB. Mantente atento a más actualizaciones y mejoras a medida que continuamos mejorando las capacidades de MyScaleDB.



