
La búsqueda vectorial puede localizar rápidamente candidatos semánticamente similares o relacionados dentro de grandes cantidades de texto, imágenes y otros datos. Sin embargo, en escenarios del mundo real, la búsqueda vectorial pura a menudo es insuficiente.
Los datos reales generalmente incluyen atributos como tiempo, categoría, ID de usuario y otras palabras clave. Aplicar una o más condiciones de filtrado a estos atributos puede mejorar significativamente la precisión de los sistemas de Generación con Recuperación Mejorada (RAG, por sus siglas en inglés), así como formar la base de sistemas multiinquilino a gran escala. MyScale (opens new window), desarrollado en la base de datos ClickHouse, admite una amplia gama de tipos de datos SQL, logrando una alta precisión y eficiencia en búsquedas con cualquier proporción de filtrado.
Este artículo trata sobre la importancia de la búsqueda de vectores filtrados, así como las tecnologías detrás de su implementación, incluyendo la prefiltración y la postfiltración, así como el almacenamiento por filas y columnas.
# La búsqueda vectorial filtrada es esencial para mejorar la precisión de los sistemas RAG
La búsqueda filtrada desempeña un papel vital en el soporte de aplicaciones LLM/AI de alta precisión. La recuperación vectorial pura a menudo produce candidatos relativamente precisos en escenarios con contenido de documentos limitado. Sin embargo, a medida que aumenta el volumen de documentos, la tasa de recuperación generalmente disminuye rápidamente.
Este problema surge principalmente en entornos de documentos complejos como las finanzas, donde el contenido relevante suele ser abundante. En estos casos, la recuperación vectorial pura puede devolver muchos párrafos similares pero incorrectos, lo que afecta negativamente la precisión de la respuesta final.
Por ejemplo, en escenarios de análisis financiero, un usuario podría preguntar: "¿Cuál es el estilo de gestión de <Compañía>?" Cuando <Compañía> es un nombre de empresa menos común, la recuperación vectorial pura a menudo puede llevar a una multitud de contenido similar pero inexacto, como párrafos sobre el estilo de gestión de empresas similares, lo que dificulta la generación precisa de respuestas por parte del LLM.
Sin embargo, si sabemos de antemano que los títulos de los documentos relacionados con <Compañía> incluyen esta palabra clave en sus títulos, podemos usar WHERE title ILIKE '%<Compañía>%' para el filtrado previo, reduciendo así los resultados de búsqueda solo a documentos relevantes. Además, el <Compañía> puede ser extraído automáticamente por el LLM, por ejemplo, como un parámetro en una llamada de función o generando cláusulas SQL WHERE a partir del texto de la consulta, lo que garantiza que el sistema sea flexible y fácil de usar.
Al utilizar estos atributos estructurados para el filtrado, hemos observado un aumento de la precisión del 60% al 90% en aplicaciones del mundo real como el análisis de documentos financieros y las bases de conocimiento empresariales. Por lo tanto, para garantizar consultas de alta precisión dentro de los sistemas RAG, necesitamos un enfoque flexible y universal para el modelado y consulta de datos estructurados + vectoriales, así como una recuperación vectorial que garantice alta precisión y eficiencia independientemente de la proporción de filtrado.

# La búsqueda vectorial filtrada es la base para implementar sistemas multiusuario a gran escala
La búsqueda vectorial filtrada es fundamental en aplicaciones como preguntas y respuestas de documentos a gran escala, chat con personajes virtuales con memoria semántica y redes sociales, donde el sistema necesita admitir consultas en datos de millones de usuarios, y cada consulta generalmente implica datos de un solo usuario o un pequeño conjunto de usuarios.
Esto requiere una precisión de consulta excepcionalmente alta con una proporción de filtrado muy baja en un gran conjunto de datos vectoriales. Bases de datos vectoriales especializadas como Pinecone, Weaviate y Milvus, diseñadas para este tipo de aplicaciones, han introducido un mecanismo de namespace donde los desarrolladores pueden colocar los datos de cada usuario en un namespace separado, lo que garantiza la precisión de la consulta.
Sin embargo, este enfoque limita la flexibilidad, ya que una sola consulta solo puede buscar dentro de un namespace. Por ejemplo, en las redes sociales, los usuarios pueden necesitar consultar contenido relacionado con sus amigos, lo que implica consultas para cientos o miles de datos de amigos. A menudo se requieren consultas filtradas complejas en análisis de contexto y sistemas de recomendación, basadas en tiempo, autor, palabras clave, etc.
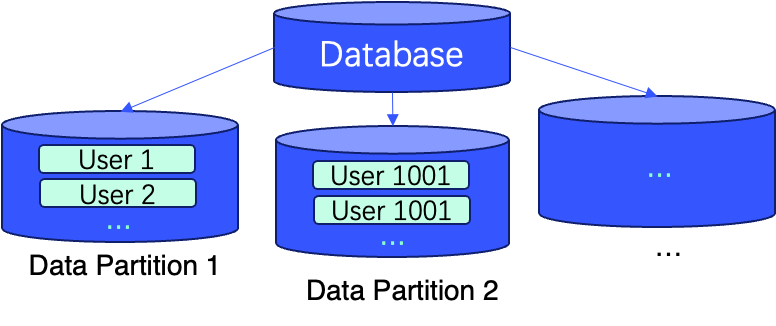
En estos casos, y más, el uso de condiciones WHERE para consultas filtradas proporciona un enfoque más flexible. Además, el uso de particionamiento de datos y ordenamiento de datos mediante claves primarias puede mejorar aún más la eficiencia de las consultas al mejorar la localidad de los datos.
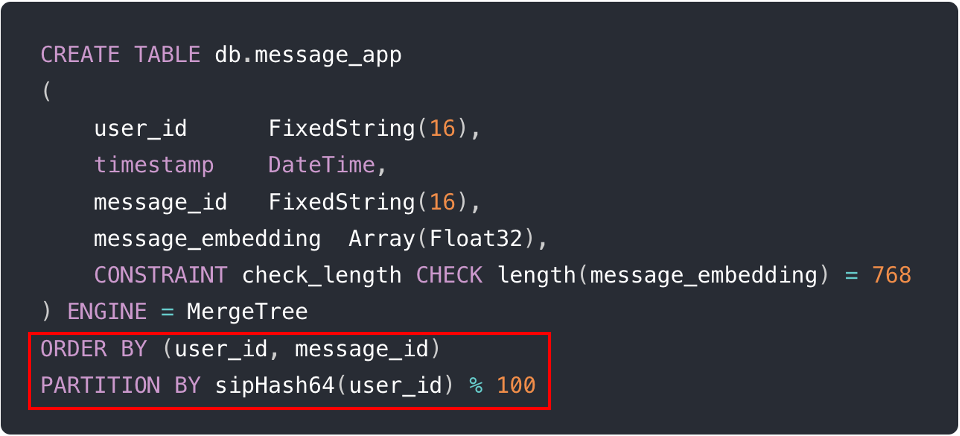
Las siguientes figuras describen un ejemplo del mundo real que muestra la implementación de estas técnicas con dos líneas de SQL durante la creación de una tabla (es decir, ORDER BY (user_id, message_id) y PARTITION BY sipHash64(user_id) % 100).
Nota:
Consulte nuestra documentación de multiinquilino (opens new window) para obtener más detalles.
# MyScale admite búsqueda filtrada de alta precisión y alta eficiencia en cualquier proporción
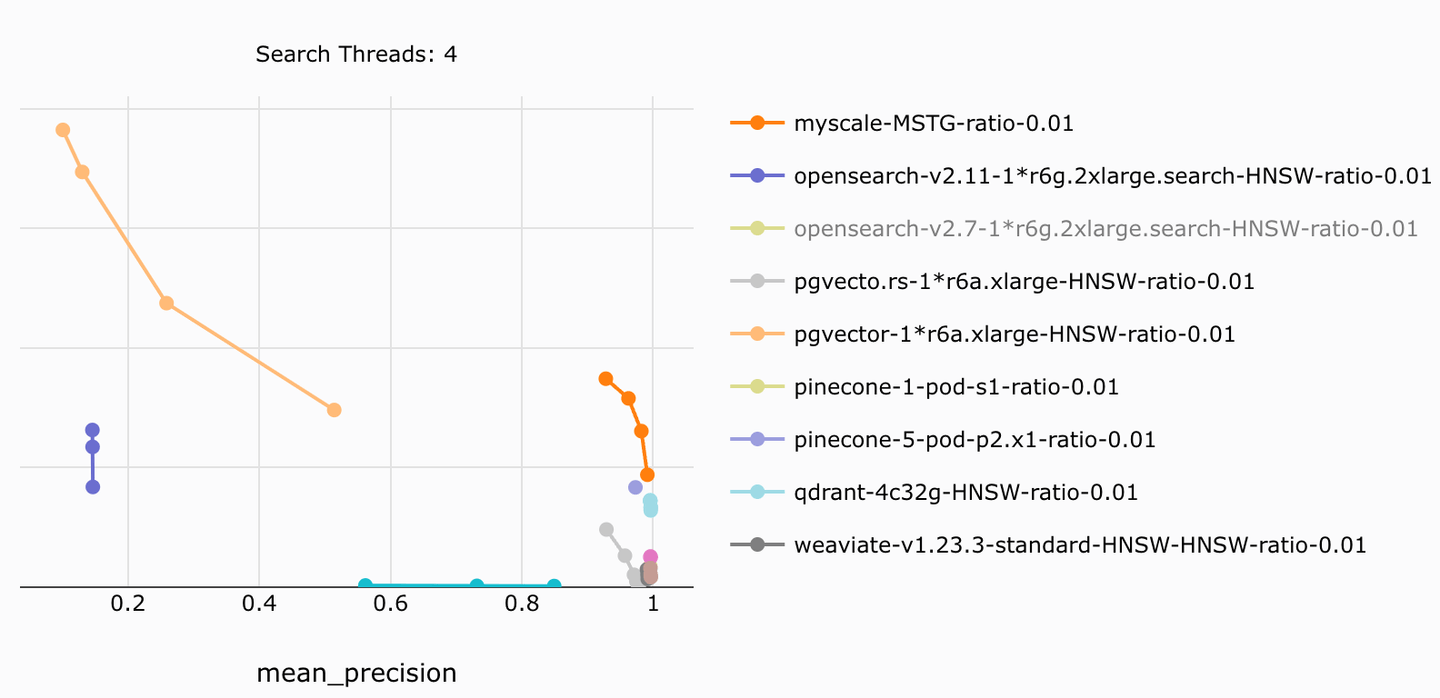
MyScale logra una búsqueda filtrada de alta precisión y alta eficiencia en cualquier proporción de filtrado combinando el almacenamiento columnar, el filtrado previo y algoritmos de búsqueda eficientes. Ofrece una relación de costo por QPS de 4x-10x más baja en comparación con otros productos.
Por ejemplo, MyScale logra la mayor velocidad y precisión de búsqueda en nuestra prueba de referencia de código abierto (opens new window), superando a sistemas similares que quedan rezagados en precisión y velocidad, al tiempo que son hasta 5 veces más baratos. Esta capacidad de búsqueda filtrada precisa y eficiente es una base crucial para los sistemas RAG de producción.
Nota:
Para obtener más resultados, consulte el artículo comparativo sobre MyScale vs. pgvector y OpenSearch (opens new window).
Como se destacó anteriormente, MyScale se desarrolla en base a la ampliamente utilizada base de datos SQL ClickHouse, que admite una amplia gama de tipos de datos y funciones (opens new window), como numéricos, fecha y hora, geoespaciales, JSON, cadenas, etc. Esto mejora significativamente las capacidades de consulta de filtrado en comparación con bases de datos vectoriales especializadas como Pinecone, Weaviate y Qdrant.
Además, dado que los LLM son altamente competentes en SQL, pueden convertir automáticamente el lenguaje natural en condiciones SQL WHERE. Esto significa que los usuarios sin conocimientos técnicos pueden ejecutar consultas filtradas utilizando lenguaje natural, lo que mejora aún más la flexibilidad y precisión de los sistemas RAG. Hemos implementado tecnología similar en el LangChain MyScale Self-Query (opens new window), que se ha aplicado ampliamente en sistemas de producción.

# Detrás de escena
A pesar de la importancia de las búsquedas vectoriales filtradas en muchos escenarios, implementar búsquedas vectoriales filtradas precisas y eficientes implica numerosas decisiones técnicas detalladas, como el filtrado previo o posterior, el almacenamiento de filas o columnas y los algoritmos de gráficos o árboles optimización de búsqueda vectorial filtrada (opens new window). Al integrar tecnologías como el filtrado previo, el almacenamiento columnar y los algoritmos de gráficos de árbol a múltiples escalas, MyScale ha logrado una precisión y velocidad sobresalientes en la búsqueda vectorial filtrada.
# Filtrado previo vs. Filtrado posterior
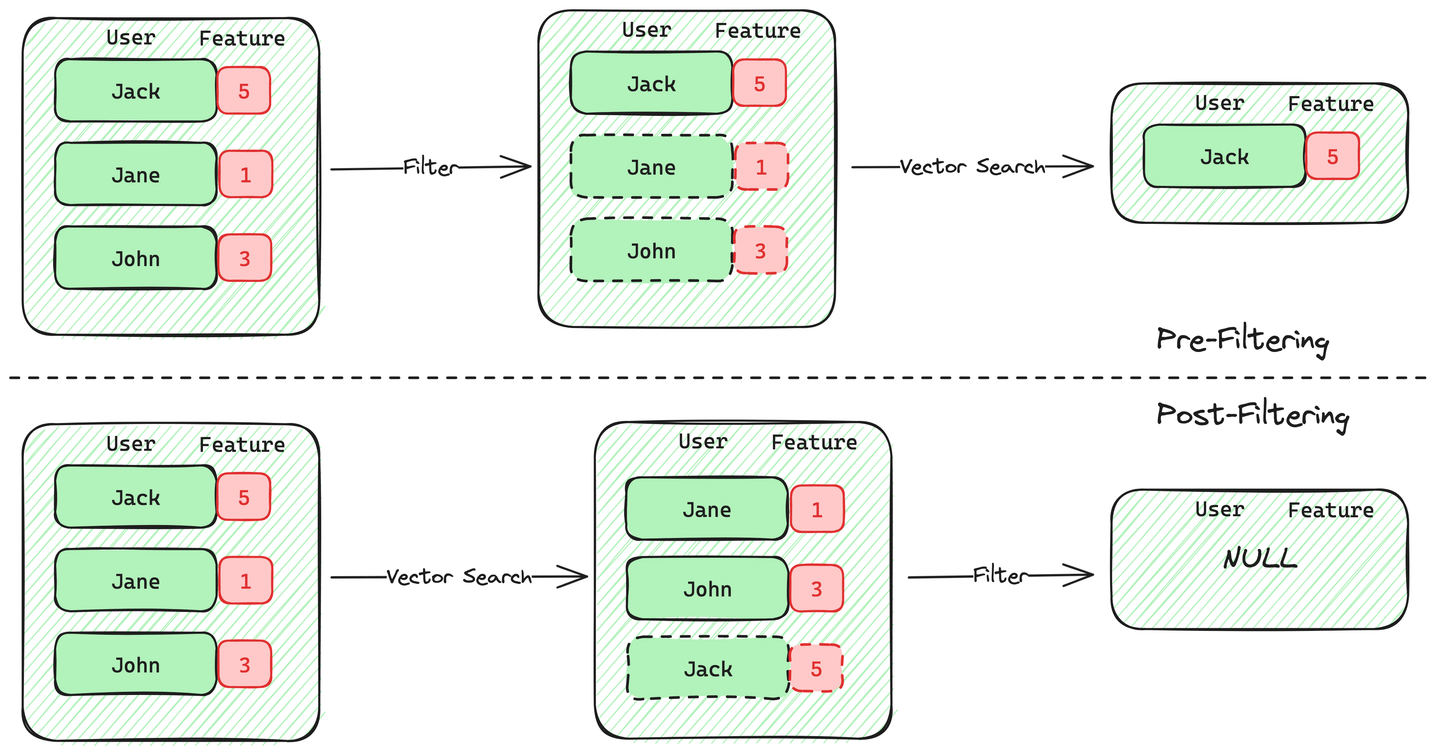
Existen dos enfoques para implementar el filtrado de metadatos en la búsqueda vectorial filtrada: el filtrado previo y el filtrado posterior.
El filtrado previo selecciona primero los vectores que cumplen los criterios utilizando metadatos y luego busca estos vectores. La ventaja de este método es que si los usuarios necesitan los k documentos más similares, la base de datos puede garantizar k resultados.
El filtrado posterior, por otro lado, implica realizar una búsqueda vectorial primero para obtener m resultados y luego aplicar filtros de metadatos a estos resultados. La desventaja de este método es la incertidumbre de cuántos de los m resultados cumplen los criterios del filtro de metadatos, lo que potencialmente resulta en menos de k resultados finales. Cuando los vectores que cumplen los criterios del filtro son escasos, la precisión del filtrado posterior disminuye significativamente. El complemento de recuperación vectorial de PostgreSQL, pgvector, adopta este enfoque, sufriendo una pérdida significativa de precisión cuando la proporción de datos que cumplen los criterios es baja.
El desafío con el filtrado previo radica en filtrar eficientemente los datos y mantener la eficiencia de búsqueda en los índices vectoriales cuando el número de vectores que cumplen los criterios es pequeño.
Por ejemplo, el algoritmo HNSW (Hierarchical Navigable Small World) ampliamente utilizado experimenta una disminución significativa en la efectividad de la búsqueda cuando la proporción de filtrado es baja, por ejemplo, solo el 1% de los vectores permanecen después del filtrado. Para abordar este problema, una solución común en toda la industria es recurrir a la búsqueda de fuerza bruta cuando la proporción de filtrado cae por debajo de un umbral específico.
Pinecone, Milvus y ElasticSearch, por ejemplo, emplean este método, pero puede afectar gravemente el rendimiento con conjuntos de datos grandes. MyScale, por otro lado, garantiza alta precisión y eficiencia en cualquier proporción de filtrado combinando un filtrado previo altamente eficiente con innovaciones algorítmicas.
# Almacenamiento basado en filas vs. Almacenamiento basado en columnas
Al adoptar una estrategia de filtrado previo, escanear los metadatos de manera eficiente es fundamental para el rendimiento de recuperación. El almacenamiento de la base de datos generalmente se clasifica como basado en filas o basado en columnas.
El almacenamiento basado en filas se utiliza generalmente en bases de datos de transacciones, como MySQL o PostgreSQL, y es más adecuado para lecturas y escrituras puntuales, especialmente para el procesamiento de transacciones. Por otro lado, las bases de datos basadas en columnas (como ClickHouse) son altamente eficientes para el procesamiento analítico, especialmente para escanear varias columnas de datos, ingestión de datos por lotes y almacenamiento comprimido.
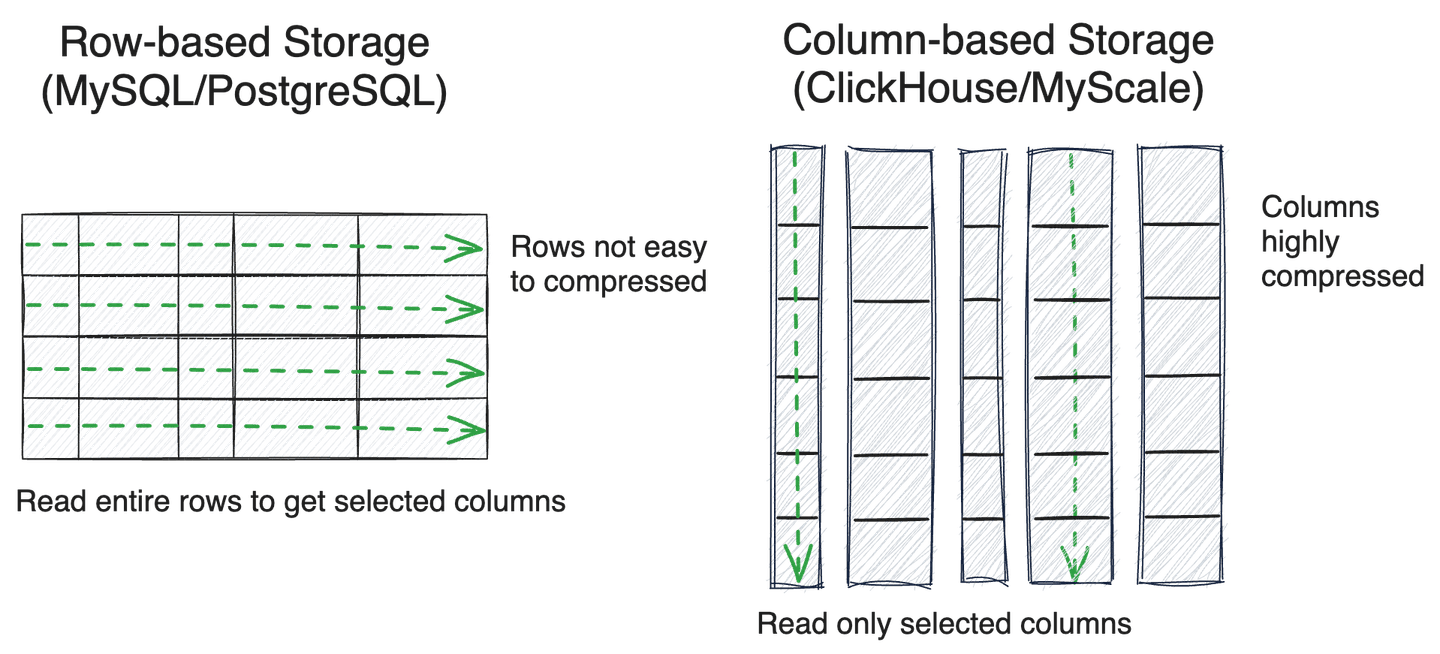
Debido a la necesidad de escanear metadatos de manera eficiente, muchas bases de datos vectoriales especializadas, como Milvus y Qdrant, también han adoptado el almacenamiento columnar. Después de años de optimización en consultas analíticas de datos estructurados masivos, las bases de datos SQL columnares como ClickHouse, consulte ClickBench (opens new window) para obtener más información, se destacan aún más, utilizando técnicas como índices de salto y operaciones SIMD, mejorando significativamente las eficiencias de escaneo de datos en muchos escenarios prácticos.
A través de una extensa investigación de usuarios, descubrimos que en aplicaciones de IA/LLM como RAG hay menos necesidad de transacciones de escritura pequeñas, pero el escaneo y análisis eficientes de datos son imperativos. Por lo tanto, para nosotros, el almacenamiento columnar es una opción más adecuada.
Esta es una razón clave por la que MyScale eligió desarrollarse en base a ClickHouse. Por otro lado, sistemas como pgvector y pgvecto.rs, debido a las limitaciones del almacenamiento basado en filas de PostgreSQL, enfrentan problemas con la precisión o velocidad de búsqueda filtrada.
Por último, el desafío más importante con las bases de datos columnares es que sus lecturas de varios columnas son ineficientes debido a la amplificación de lectura de datos y la sobrecarga de descompresión. La buena noticia es que esto se puede solucionar utilizando tecnologías como el almacenamiento en caché de datos sin comprimir. También hay mucho margen de mejora en la consulta conjunta de datos estructurados y vectoriales, como las optimizaciones de monotonía relajada en vbase (opens new window).
# Resumen
Al combinar datos estructurados y vectoriales en una consulta, la búsqueda vectorial filtrada tiene aplicaciones amplias y significativas en sistemas RAG avanzados, sistemas multiusuario a gran escala y más. MyScale, construido sobre la base de datos columnar ClickHouse SQL, admite una amplia gama de tipos y funciones de metadatos, junto con capacidades flexibles de autoconsulta.
Al emplear el filtrado previo, el almacenamiento columnar y las optimizaciones algorítmicas, MyScale logra alta precisión y velocidad en la búsqueda filtrada en cualquier proporción de filtrado, sentando una base sólida de datos para aplicaciones LLM.
Si tienes más ideas sobre búsquedas filtradas o deseas compartir tus ideas, síguenos en Twitter (opens new window) y únete a nuestra comunidad de Discord (opens new window).



