
A medida que los volúmenes y la complejidad de los datos continúan creciendo, las soluciones escalables de bases de datos NoSQL se están convirtiendo en una alternativa popular a las bases de datos relacionales tradicionales. Un tipo que está generando mucho interés es la base de datos vectorial. Prometiendo capacidades avanzadas de búsqueda semántica, las bases de datos vectoriales utilizan la búsqueda de vectores de alta dimensión en lugar de las consultas SQL tradicionales para organizar y recuperar datos en función de su significado y similitud.
Antes de elegir una base de datos vectorial, hay algunos factores clave que debes considerar cuidadosamente para asegurarte de que cumpla con los requisitos de tu aplicación y análisis tanto ahora como en el futuro. Eso es lo que discutiremos en este blog. Estos factores se dividen en tres categorías principales: las funcionalidades principales de una base de datos vectorial, las consideraciones operativas y la usabilidad y el ecosistema. ¡Comencemos!
# Funcionalidades principales
Las funcionalidades principales de una base de datos vectorial incluyen el rendimiento, los métodos de indexación, el lenguaje de consulta y el soporte de API, y el modelo de datos y el esquema.
# Rendimiento
Al seleccionar una base de datos vectorial, el rendimiento es crucial, ya que garantiza el funcionamiento fluido de la aplicación, facilitando búsquedas eficientes de elementos similares, vectores de vecinos más cercanos y análisis de datos. El rendimiento de una base de datos vectorial se puede medir a través de los siguientes factores:
- Número de consultas por segundo (QPS): Esto mide cuántas consultas puede manejar tu base de datos en un segundo. Un QPS más alto significa que la base de datos puede admitir más búsquedas concurrentes, lo cual es crucial para aplicaciones que requieren análisis de datos en tiempo real o interacciones de usuario.
- Latencia promedio de consulta: Se trata de cuánto tiempo tarda la base de datos en devolver un resultado después de realizar una consulta. Una latencia más baja garantiza que tu aplicación se sienta más rápida y receptiva para el usuario, mejorando la experiencia general del usuario.
- Tiempo de ingestión de datos: La velocidad con la que se pueden agregar nuevos datos a la base de datos es vital, especialmente en entornos dinámicos donde los datos se actualizan constantemente. Una ingestión de datos eficiente garantiza que tu base de datos esté siempre actualizada y lista para las consultas.
MyScaleDB es una base de datos vectorial con un rendimiento excepcional en comparación con otras bases de datos vectoriales. Para conjuntos de datos más grandes, MyScaleDB ahora informa un rendimiento mejorado (opens new window) con 390 QPS (consultas por segundo) en el conjunto de datos LAION 5M, logrando una tasa de recuperación del 95% y manteniendo una latencia promedio de consulta de 18 ms con el pod x1.
MyScaleDB también superó a otras bases de datos vectoriales en el tiempo de ingestión de datos al completar las tareas en casi 30 minutos para 5M puntos de datos. Si te registras, puedes usar el pod x1 de forma gratuita, que puede manejar hasta 5 millones de vectores.
Artículo relacionado: ¿Cómo MyScale supera a otras bases de datos vectoriales especializadas? (opens new window)
# Método de indexación
La clave de una base de datos vectorial es cómo procesa los datos vectoriales de alta dimensión. Diferentes bases de datos vectoriales utilizan diferentes métodos de indexación para asegurarse de que los datos se puedan encontrar de manera rápida y precisa, manteniendo todo organizado y eficiente. Aquí hay algunos métodos de indexación comunes en las bases de datos vectoriales:
- Árboles k-d son estructuras de árbol utilizadas para indexar puntos en un espacio k-dimensional. Son particularmente útiles para datos multidimensionales, como vectores. Los árboles k-d dividen el espacio en regiones, facilitando búsquedas rápidas de vecinos más cercanos.
- Árboles de bolas son similares a los árboles k-d pero son efectivos para conjuntos de datos con densidades variables. Representan el conjunto de datos mediante la inclusión de puntos dentro de hiperesferas, lo que los hace adecuados para aplicaciones como búsquedas de vecinos más cercanos.
- Hashing sensible a la localidad (LSH) es un método probabilístico para hashear elementos de entrada de manera que los elementos similares se asignen a los mismos cubos con alta probabilidad. Es útil para búsquedas de similitud aproximada, lo que lo hace adecuado para aplicaciones como sistemas de recomendación.
- Índice basado en gráficos representa los datos como un grafo, donde los nodos y las aristas se representan como vectores y relaciones. Este índice es beneficioso para capturar relaciones complejas y se utiliza frecuentemente en aplicaciones como análisis de redes sociales.
- Índice vectorial de archivo invertido (IVF) es un método para búsquedas de similitud eficientes en espacios vectoriales de alta dimensión, utilizando agrupamiento para dividir los vectores en celdas de Voronoi, donde cada celda corresponde a un centroide, y se construye un índice invertido para localizar rápidamente vectores dentro de una celda dada durante las consultas.
- Quantización de productos (PQ) divide los vectores en subvectores más pequeños y los cuantiza de forma independiente. Es eficiente para datos de alta dimensión y se utiliza frecuentemente en aplicaciones de recuperación de imágenes. PQ se puede combinar eficazmente con índices basados en gráficos y IVF.
- Hashing espacial implica dividir el espacio vectorial en celdas y asignar cada vector a una celda según su ubicación. Este método es útil para consultas espaciales y se utiliza comúnmente en gráficos por computadora y diseño asistido por computadora.
Muchos algoritmos enfrentan limitaciones, especialmente cuando hay un aumento significativo en el tamaño del índice para conjuntos de datos masivos, lo que requiere almacenar todos los datos vectoriales en memoria. Multi-Scale Tree Graph (MSTG) (opens new window) fue desarrollado por MyScaleDB y supera las limitaciones al combinar agrupamiento jerárquico de árboles con recorrido de gráficos, y memoria con SSDs NVMe rápidos. MSTG reduce significativamente el consumo de recursos de IVF/HNSW mientras mantiene un rendimiento excepcional. Se construye rápido, se busca rápido y se mantiene rápido y preciso bajo diferentes ratios de búsqueda filtrada, al mismo tiempo que es eficiente en recursos y costos.
# Lenguaje de consulta y soporte de API
El lenguaje de consulta y el soporte de interfaz de programación de aplicaciones (API) definen cómo los usuarios interactúan y obtienen información de la base de datos. Son factores cruciales para evaluar si una base de datos vectorial es fácil de usar, adaptable e integrable de manera fluida en diversos ecosistemas tecnológicos. Estos componentes permiten a los usuarios extraer información valiosa al interactuar con la base de datos, lo que facilita una experiencia de gestión de datos fluida y efectiva.
MyScaleDB es una base de datos vectorial todo en uno y totalmente compatible con SQL, lo que no solo simplifica las operaciones de datos complejas, la búsqueda semántica y las consultas de datos estructurados a través de SQL, sino que también la hace ideal para casi todos los desarrolladores para aprovechar los conocimientos de SQL existentes para comenzar a utilizar una base de datos vectorial y realizar tareas de datos. Al mismo tiempo, el soporte de API de MyScaleDB facilita la automatización e integración con otros sistemas.
# Modelo de datos y esquema
El modelo de datos y el esquema de una base de datos vectorial son sus planos que dictan cómo se almacenan y acceden a los datos. Esto afecta la eficiencia de almacenamiento, el rendimiento de las consultas, la escalabilidad y la experiencia del desarrollador. MyScaleDB utiliza un modelo de datos híbrido que combina las fortalezas de las representaciones de datos estructurados y vectoriales, lo que significa que puede almacenar eficazmente datos tabulares (como las bases de datos tradicionales) y vectores de alta dimensión también.
# Consideraciones operativas
Discutamos la escalabilidad, la seguridad y el monitoreo como consideraciones operativas de una base de datos vectorial.
# Escalabilidad
La escalabilidad se refiere a su capacidad para manejar el aumento del volumen de datos y las demandas de los usuarios sin comprometer el rendimiento o la funcionalidad. En las bases de datos vectoriales, existen dos tipos de escalabilidad: la escalabilidad vertical y la escalabilidad horizontal. La escalabilidad vertical implica expandir la potencia computacional del hardware y el software. Mientras tanto, la escalabilidad horizontal implica la adición de nodos de servidor adicionales. Es crucial para futurizar tu base de datos vectorial y asegurarte de que pueda soportar el crecimiento de tus aplicaciones de inteligencia artificial. MyScaleDB proporciona escalabilidad vertical.
# Seguridad
La seguridad en una base de datos vectorial abarca varios aspectos que protegen tanto los datos en sí como la funcionalidad del sistema de base de datos. Busca características como el cifrado, los controles de acceso, los mecanismos de autenticación, la seguridad de la red y la recuperación ante desastres en tu base de datos vectorial, ya que actúan como el escudo digital que mantiene tus datos seguros y protegidos.
MyScaleDB es confiable para equipos y organizaciones como la tuya por diversas razones.
- MyScaleDB se ejecuta en un clúster de Kubernetes multiinquilino en una infraestructura de AWS completamente administrada y segura.
- Asegura que los datos del cliente se almacenen en contenedores aislados.
- El acceso a tus datos por cualquier motivo más allá de las llamadas de servicio de API está estrictamente prohibido.
- MyScaleDB monitorea exclusivamente las métricas operativas para mantener la salud y el rendimiento del sistema.
- MyScaleDB ha logrado la conformidad SOC 2 Tipo 1, cumpliendo con el estándar mundial más alto para mantener la información segura.
# Monitoreo
El monitoreo juega un papel crucial al elegir una base de datos vectorial por varias razones. Nos proporciona información y seguimiento del progreso para tomar decisiones oportunas para la optimización del rendimiento, la mejora continua y la adaptabilidad.
MyScaleDB ofrece herramientas de monitoreo completas para realizar un seguimiento de las métricas de rendimiento, la utilización de recursos y los eventos de seguridad, proporcionando información en tiempo real sobre la salud y la actividad de tu base de datos.
Artículo relacionado: Ganancia de rendimiento con Generación Aumentada de Recuperación (opens new window)
# Usabilidad y ecosistema
La usabilidad y el ecosistema comprenden el precio, la documentación, la comunidad, el soporte y la integración del ecosistema.
# Comunidad y soporte
El soporte de la comunidad juega un papel vital en el uso efectivo de las bases de datos vectoriales. Empodera a los usuarios, fomenta la colaboración y contribuye a la mejora y el éxito continuo de las implementaciones de bases de datos vectoriales en diversas aplicaciones e industrias. También ayuda a depurar problemas y hacer consultas para aclaraciones. MyScaleDB ofrece un soporte integral a través de múltiples canales como Discord (opens new window), Twitter (opens new window), LinkedIn (opens new window) y Medium (opens new window). Y puedes obtener respuestas de los expertos técnicos de MyScaleDB de manera rápida a través de estos canales.
# Precios
El precio es un factor importante para seleccionar una base de datos vectorial. Una comprensión clara de los precios garantiza una relación rentable y sostenible con la base de datos vectorial. Examina los modelos de precios ofrecidos por diferentes bases de datos y evalúa cómo se alinean con tu presupuesto y requisitos de uso.
MyScaleDB ofrece múltiples opciones de precios (opens new window), incluidos servicios gratuitos para individuos para aplicaciones pequeñas. También ofrece un paquete estándar para servicios de inteligencia artificial y un paquete empresarial para grandes organizaciones. MyScaleDB cobra por el almacenamiento y la computación por separado, lo que significa que la tarifa de computación se cobra solo cuando se ejecutan consultas. Y recientemente, MyScaleDB lanzó un nuevo pod optimizado para la capacidad por solo $68/mes que puede alojar 10 millones de vectores de 768 dimensiones, lo que facilita más que nunca la creación de aplicaciones GenAI potentes sin gastar mucho dinero.
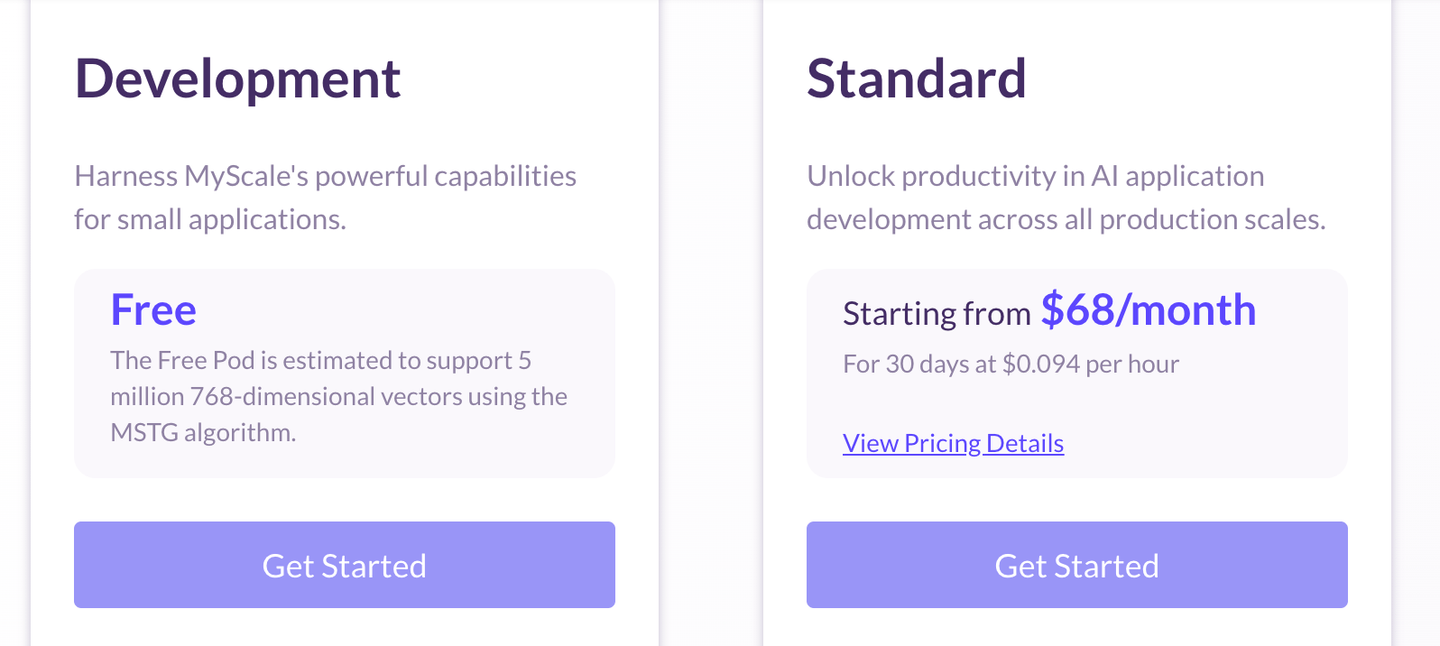
Si tienes una estimación del tamaño de tu vector de datos, también puedes calcular el precio utilizando el estimador de precios.
# Integraciones del ecosistema
Discutamos las integraciones del ecosistema a continuación:
Herramientas para desarrolladores: Las herramientas para desarrolladores son cruciales para elegir la base de datos vectorial adecuada para tu proyecto. Pueden aumentar la productividad y la eficiencia al integrar las herramientas de desarrollo existentes con las que te sientas cómodo. MyScaleDB ha integrado varias herramientas para desarrolladores como Cliente de Python (opens new window), Node.js (opens new window), Cliente de Go (opens new window), Controlador JDBC (opens new window) y Interfaz HTTPS (opens new window).
Modelos de lenguaje grandes (LLM): La integración de LLM amplía significativamente las capacidades de una base de datos vectorial al desbloquear la búsqueda semántica avanzada, la contextualización de datos, las recomendaciones personalizadas, el aumento de conocimientos y las interfaces conversacionales. MyScaleDB proporciona múltiples integraciones de LLM, incluyendo OpenAI (opens new window), LangChain (opens new window), LangChain JS/TS (opens new window) y LlamaIndex (opens new window).
Artículo relacionado: Análisis avanzado de datos de eventos de Facebook con una base de datos vectorial (opens new window)
# Documentación
La disponibilidad de una documentación detallada es importante al seleccionar una base de datos vectorial. Ayuda a comprender la funcionalidad, el desarrollo eficiente, la integración, el soporte a largo plazo y garantiza una curva de aprendizaje fluida.
MyScaleDB proporciona una documentación extensa y detallada que cubre guías de usuario (opens new window), tutoriales (opens new window), blogs (opens new window), aplicaciones de muestra (opens new window) y documentación de integración de API, y canales de soporte activos como Discord y Twitter.

# Comparación
Comparemos MyScaleDB con algunas bases de datos vectoriales populares.
| Funcionalidades | MyScaleDB | Pinecone | Weaviate | Milvus | Qdrant |
|---|---|---|---|---|---|
| Código abierto | Sí | No | Sí | Sí | Sí |
| SQL | Sí | No | No | No | No |
| Implementación en la nube | Sí | Sí | Sí | Sí | Sí |
| Lenguajes de consulta | SQL y SDKs | SDKs | GraphQL | C++, Python SDKs | SDKs |
| Integración de LLM | Llamalindex, LangChain | Llamalindex, LangChain | Llamalindex, LangChain | Llamalindex, LangChain | Llamalindex, LangChain |
| Costo | Tiers gratuitos y de pago | Tiers de pago | 14 días gratuitos y Tiers de pago | Tiers de pago | Tiers gratuitos y de pago |
# Conclusión
No es fácil seleccionar una base de datos vectorial adecuada, hemos discutido diferentes factores que puedes considerar antes de seleccionar cualquier base de datos vectorial, incluyendo tres categorías principales que cubren las funcionalidades principales, las consideraciones operativas, la usabilidad y la integración del ecosistema.
Además, si el manejo eficiente de volúmenes de datos a gran escala y la complejidad de los datos son tus criterios de selección principales, considera utilizar MyScaleDB. Al combinar las fortalezas de ClickHouse y el algoritmo MSTG, MyScaleDB proporciona soluciones rentables para búsquedas vectoriales complejas y a gran escala tanto en velocidad como en precisión.
También puedes encontrar informes de referencia entre MyScaleDB y otros competidores en el siguiente contenido:



