
Actualización (2023-10-17): Echa un vistazo a nuestra nueva publicación en el blog Comparando MyScale con Postgres y OpenSearch: Una exploración de las bases de datos vectoriales integradas (opens new window) para una comparación exhaustiva entre MyScale y PostgreSQL.
El rápido crecimiento de las aplicaciones de IA y ML, especialmente aquellas que involucran análisis de datos a gran escala, ha aumentado la demanda de bases de datos vectoriales que puedan almacenar, indexar y consultar eficientemente vectores de incrustación. Por lo tanto, se siguen desarrollando y expandiendo bases de datos vectoriales como MyScale, Pinecone y Qdrant para satisfacer estos requisitos.
Al mismo tiempo, las bases de datos tradicionales continúan mejorando sus capacidades de almacenamiento y recuperación de datos vectoriales. Por ejemplo, la conocida base de datos relacional PostgreSQL y su extensión pgvector proporcionan funcionalidades similares, aunque menos eficientes que una base de datos vectorial bien optimizada.
Existen diferencias significativas en rendimiento, precisión y otros aspectos al utilizar una base de datos de propósito general como PostgreSQL. Estas diferencias pueden generar cuellos de botella en el rendimiento y la escala de datos. Para solucionar estos problemas, se recomienda actualizar a una base de datos vectorial más eficiente como MyScale.
Lo que distingue a MyScale de otras bases de datos vectoriales especializadas es su capacidad para proporcionar soporte completo de SQL sin comprometer el alto rendimiento. Esto hace que el proceso de migración de PostgreSQL a MyScale sea mucho más fluido y sencillo.
Para agregar valor a esta afirmación, consideremos un caso de uso en el que tenemos datos vectoriales almacenados en una base de datos PostgreSQL pero encontramos cuellos de botella de rendimiento y escala de datos. Por lo tanto, como solución, hemos decidido actualizar a MyScale.
# Migrar datos de PostgreSQL a MyScale
Una parte fundamental de la actualización a MyScale desde PostgreSQL es migrar los datos de la base de datos antigua a la nueva. Veamos cómo se hace esto.
Nota:
Para demostrar cómo migrar datos de PostgreSQL a MyScale, debemos configurar ambas bases de datos, aunque nuestro caso de uso indica que ya tenemos datos vectoriales en una base de datos PostgreSQL.
Antes de comenzar, es importante tener en cuenta que utilizaremos los siguientes entornos y conjuntos de datos:
# Entornos
| Base de datos | Nivel | Versión de la BD | Versión de la extensión |
|---|---|---|---|
| PostgreSQL en Supabase (opens new window) | Gratis (hasta 500 MB de espacio en la base de datos) | 15.1 | pgvector 4.0 |
| MyScale (opens new window) | Desarrollo (hasta 5 millones de vectores de 768 dimensiones) | 0.10.0.0 |
# Conjunto de datos
Utilizamos las primeras 1 millón de filas (exactamente 1,000,448 filas) del LAION-400-MILLION OPEN DATASET (opens new window) para este ejercicio, con el fin de demostrar un escenario en el que la escala de datos continúa aumentando después de la migración.
Nota:
Este conjunto de datos tiene 400 millones de entradas, cada una de ellas consiste en un vector de 512 dimensiones.
# Cargar los datos en PostgreSQL
Si ya conoces PostgreSQL y pgvector, puedes saltar al proceso de migración haciendo clic aquí.
El primer paso es cargar los datos en una base de datos PostgreSQL siguiendo la siguiente guía paso a paso:
# Crear una base de datos PostgreSQL y establecer variables de entorno
Crea una instancia de PostgreSQL con pgvector en Supabase de la siguiente manera:
- Accede al sitio web de Supabase (opens new window) e inicia sesión.
- Crea una organización y dale un nombre.
- Espera a que se cree la organización y su base de datos.
- Habilita la extensión
pgvector.
El siguiente GIF describe este proceso con más detalle.

Una vez creada la base de datos PostgreSQL y habilitada la extensión pgvector, el siguiente paso es configurar las siguientes tres variables de entorno para establecer la conexión a PostgreSQL utilizando psql:
export PGHOST=db.qwbcctzfbpmzmvdnqfmj.supabase.co
export PGUSER=postgres
export PGPASSWORD='********'
Además, ejecuta el siguiente script para aumentar los límites de memoria y duración de las solicitudes, asegurándote de que las consultas SQL que ejecutemos no se interrumpan:
$ psql -c "SET maintenance_work_mem='300MB';"
SET
$ psql -c "SET work_mem='350MB';"
SET
$ psql -c "SET statement_timeout=4800000;"
SET
$ psql -c "ALTER ROLE postgres SET statement_timeout=4800000;";
ALTER ROLE
# Crear una tabla de datos en PostgreSQL
Ejecuta la siguiente instrucción SQL para crear una tabla de datos en PostgreSQL. Asegúrate de que las columnas de vector (text_embedding e image_embedding) sean del tipo vector(512).
Nota:
Las columnas de vector deben ser coherentes con las dimensiones vectoriales de nuestros datos.
$ psql -c "CREATE TABLE laion_dataset (
id serial,
url character varying(2048) null,
caption character varying(2048) null,
similarity float null,
image_embedding vector(512) not null,
text_embedding vector(512) not null,
constraint laion_dataset_not_null_pkey primary key (id)
);"
# Insertar los datos en la tabla de PostgreSQL
Inserta los datos en lotes de 500,000 filas.
Nota:
Solo hemos insertado el primer conjunto de 500,000 filas para probar la inserción exitosa de los datos antes de agregar el resto.
$ wget https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion_dataset.sql.tar.gz
$ tar -zxvf laion_dataset.sql.tar.gz
$ cd laion_dataset
$ psql < laion_dataset_id_lt500K.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
# Construir un índice ANN
El siguiente paso es crear un índice que utilice la búsqueda del vecino más cercano aproximado (ANN).
Nota:
Establece el parámetro lists en 1000, ya que se espera que el número de filas en la tabla de datos sea de 1 millón de filas. (https://github.com/pgvector/pgvector#indexing (opens new window))
$ psql -c "CREATE INDEX ON laion_dataset
USING ivfflat (image_embedding vector_cosine_ops)
WITH (lists = 1000);";
CREATE INDEX
# Ejecutar una consulta SQL
El último paso es probar que todo funciona ejecutando la siguiente instrucción SQL:
$ psql -c "SET ivfflat.probes = 100;
SELECT id, url, caption, image_embedding <=> (SELECT image_embedding FROM laion_dataset WHERE id=14358) AS dist
FROM laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;"
Si tu conjunto de resultados se parece al nuestro, podemos continuar.
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.0749262628626345 | |
| 195973 | cat sitting in front and looking at camera isolated on white background Stock Photo | 0.0929287358264965 | |
| 83158 | Abyssinian Cat Pictures | 0.105731256045087 | |
| 432425 | Russian blue kitten Stock Images | 0.108455925228164 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white Norwegian Forest Cat, on white background royalty free stock image | 0.111603095925331 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.115501832572401 | |
| 281881 | Sealpoint Ragdoll lying on white background Stock Images | 0.121348724151614 | |
| 497148 | Frightened black kitten standing in front of white background | 0.127657010206311 | |
| 490374 | Lying russian blue cat Stock Photo | 0.129595023570348 | |
| 401134 | Maine coon cat on pastel pink Stock Image | 0.130214431419139 |
# Insertar el resto de los datos
Agrega el resto de los datos a la tabla de PostgreSQL. Esto es importante para validar el rendimiento de pgvector a escala.
$ psql < laion_dataset_id_ge500K_lt1m.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
ERROR: cannot execute INSERT in a read-only transaction
ERROR: cannot execute INSERT in a read-only transaction
Como se puede ver en la salida de este script (y en la siguiente imagen), la inserción del resto de los datos devuelve errores. Supabase establece la instancia de PostgreSQL en modo de solo lectura, lo que impide el consumo de almacenamiento más allá de los límites de su nivel gratuito.
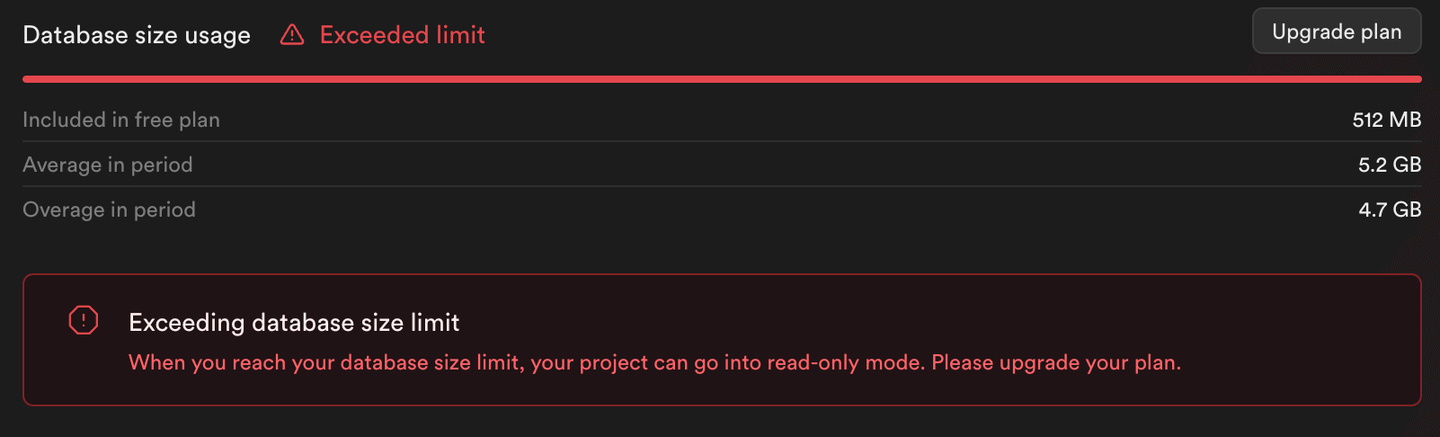
Nota:
Solo se han insertado 500,000 filas en la tabla de PostgreSQL y no 1 millón de filas.
# Migrar a MyScale
Ahora, migremos los datos a MyScale siguiendo la guía paso a paso descrita a continuación:
Nota:
MyScale no solo es una base de datos vectorial integrada de alto rendimiento, sino que los informes de referencia indican que MyScale puede superar a otras bases de datos vectoriales especializadas en cuanto a rendimiento de búsqueda, precisión y utilización de recursos. El algoritmo de indexación vectorial propietario de MyScale, Multi-Scale Tree Graph (MSTG), utiliza un disco NVMe SSD local como caché, lo que aumenta significativamente la escala de índice admitida en comparación con las situaciones en memoria.
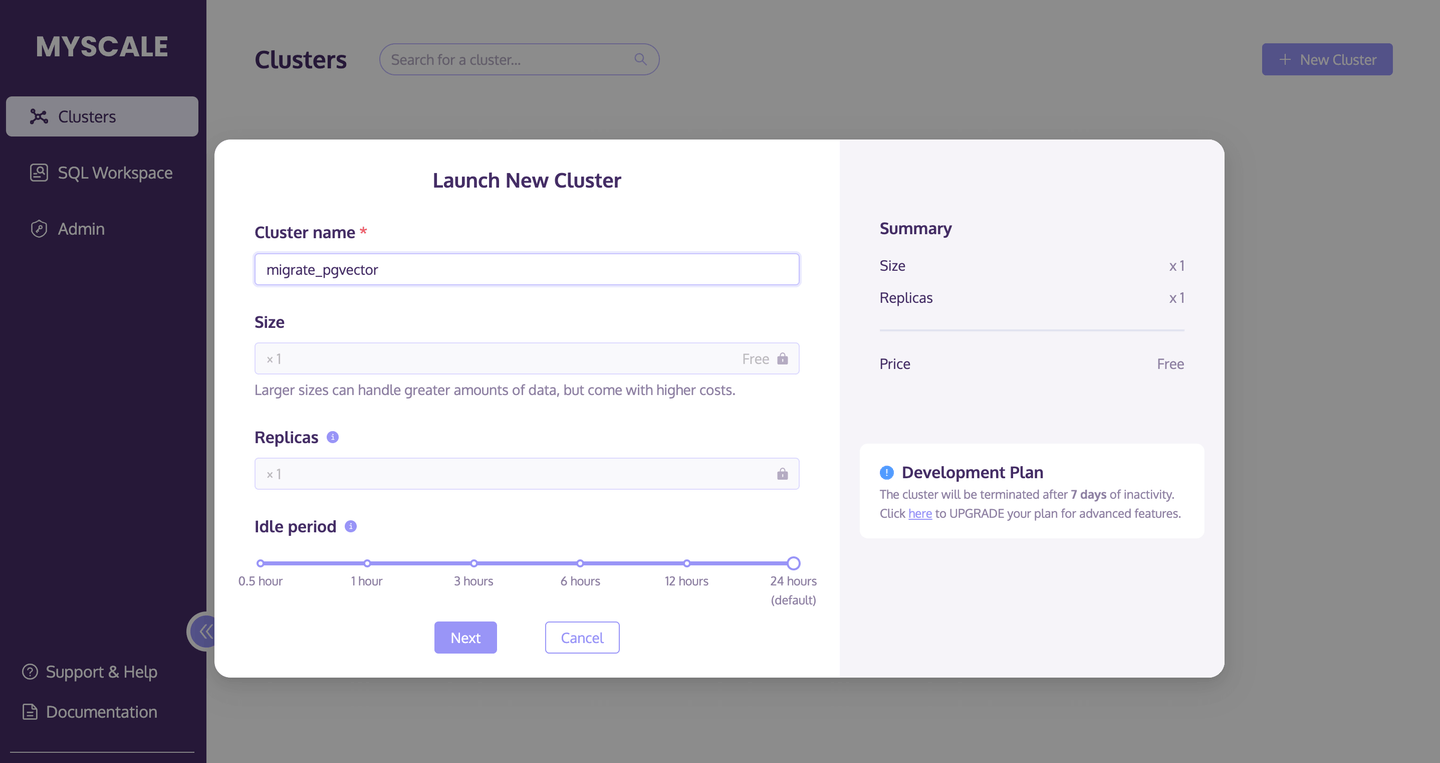
# Crear un clúster de MyScale
El primer paso es crear y lanzar un nuevo clúster de MyScale.
- Accede a la página de clústeres (opens new window) y haz clic en el botón +Nuevo clúster para lanzar un nuevo clúster.
- Asigna un nombre a tu clúster.
- Haz clic en Lanzar para ejecutar el clúster.
La siguiente imagen describe este proceso con más detalle:
# Crear una tabla de datos
Una vez que el clúster esté en funcionamiento, ejecuta el siguiente script SQL para crear una nueva tabla de base de datos:
CREATE TABLE laion_dataset
(
`id` Int64,
`url` String,
`caption` String,
`similarity` Nullable(Float32),
`image_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(image_embedding) = 512,
`text_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(text_embedding) = 512
)
ENGINE = MergeTree
ORDER BY id;
# Migrar datos desde PostgreSQL
Una vez que hayas creado la tabla de base de datos, utiliza el motor de tabla PostgreSQL() (opens new window) para migrar los datos desde PostgreSQL fácilmente.
INSERT INTO default.laion_dataset
SELECT id, url, caption, similarity, image_embedding, text_embedding
FROM PostgreSQL('db.qwbcctzfbpmzmvdnqfmj.supabase.co:5432',
'postgres', 'laion_dataset',
'postgres', '************')
SETTINGS min_insert_block_size_rows=65505;
Nota:
Se agrega la configuración min_insert_block_size_rows para limitar el número de filas insertadas por lote, evitando el uso excesivo de memoria.
# Confirmar el número total de filas insertadas
Utiliza la instrucción SELECT count(*) para confirmar si todos los datos se han migrado correctamente a MyScale desde la tabla de PostgreSQL.
SELECT count(*) FROM default.laion_dataset;
El siguiente conjunto de resultados muestra que la migración se ha realizado correctamente, ya que esta consulta devuelve 500,000 (500000) filas.
| count() |
|---|
| 500000 |
# Construir un índice de la tabla de base de datos
El siguiente paso es construir un índice con el tipo de índice MSTG y el tipo de métrica (método de cálculo de distancia) como cosine.
ALTER TABLE default.laion_dataset
ADD VECTOR INDEX laion_dataset_vector_idx image_embedding
TYPE MSTG('metric_type=cosine');
Una vez que esta instrucción ALTER TABLE haya terminado de ejecutarse, el siguiente paso es verificar el estado del índice. Ejecuta el siguiente script y, si el status devuelve "Built", el índice se ha creado correctamente.
SELECT database, table, type, status FROM system.vector_indices;
| database | table | type | status |
|---|---|---|---|
| default | laion_dataset | MSTG | Built |
# Ejecutar una consulta ANN
Ejecuta el siguiente script para ejecutar una consulta ANN utilizando el índice MSTG que acabamos de crear.
SELECT id, url, caption,
distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)
) AS dist
FROM default.laion_dataset where id!=14358 ORDER BY dist ASC LIMIT 10;
Si el siguiente conjunto de resultados es consistente con los resultados de la consulta de PostgreSQL, la migración de datos es exitosa.
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.0749262628626345 | |
| 195973 | cat sitting in front and looking at camera isolated on white background | 0.0929287358264965 | |
| 83158 | Abyssinian Cat Pictures | 0.105731256045087 | |
| 432425 | Russian blue kitten Stock Images | 0.108455925228164 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white... | 0.111603095925331 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.115501832572401 | |
| 281881 | Sealpoint Ragdoll lying on white background Stock Images | 0.121348724151614 | |
| 497148 | Frightened black kitten standing in front of white background | 0.127657010206311 | |
| 490374 | Lying russian blue cat Stock Photo | 0.129595023570348 | |
| 401134 | Maine coon cat on pastel pink Stock Image | 0.130214431419139 |

# Insertar el resto de los datos en la tabla de MyScale
Agreguemos el resto de los datos a la tabla de MyScale.
# Importar datos desde CSV/Parquet
La buena noticia es que podemos importar los datos directamente desde el bucket de Amazon S3 utilizando el siguiente método de MyScale:
INSERT INTO laion_dataset
SELECT * FROM s3(
'https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion-1m-pic-vector.csv',
'CSV',
'id Int64, url String, caption String, similarity Nullable(Float32), image_embedding Array(Float32), text_embedding Array(Float32)')
WHERE id >= 500000 SETTINGS min_insert_block_size_rows=65505;
Esto automatiza el proceso de inserción de datos, reduciendo el tiempo dedicado a agregar manualmente las filas en lotes de 500,000.
# Confirmar el número total de filas insertadas
Una vez más, ejecuta la siguiente instrucción SELECT count(*) para confirmar si todos los datos del bucket de S3 se han importado correctamente en MyScale.
SELECT count(*) FROM default.laion_dataset;
El siguiente conjunto de resultados muestra que se han importado el número correcto de filas.
| count() |
|---|
| 1000448 |
Nota:
El pod gratuito de MyScale puede almacenar un total de 5 millones de vectores de 768 dimensiones.
# Ejecutar una consulta ANN
Podemos utilizar la misma consulta SQL que utilizamos anteriormente para realizar consultas en un conjunto de datos de 1 millón de filas.
Para refrescar tu memoria, aquí está nuevamente la instrucción SQL:
SELECT id, url, caption, distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)) AS dist
FROM default.laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;
Aquí está el conjunto de resultados de la consulta, incluidos los datos recién agregados:
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Linda gata Ragdoll en fondo blanco Imagen de archivo sin royalties | 0.07492614 | |
| 195973 | Gato sentado frente a la cámara, mirando a la cámara, aislado en fondo blanco Foto de stock | 0.09292877 | |
| 693487 | Gato Azul Ruso, gato misterioso, gato amigable, Frances Simpson, razas de gatos, criadores de gatos | 0.09316337 | |
| 574275 | Gato de raza mixta, Felis catus, 6 meses de edad Foto de stock sin royalties | 0.09820753 | |
| 83158 | Imágenes de gatos Abisinios | 0.10573125 | |
| 797777 | Nombres de gatos machos para gatos naranjas | 0.10775411 | |
| 432425 | Imágenes de gatitos azules rusos | 0.10845572 | |
| 99628 | Gato del Bosque Noruego en fondo blanco. Campeón de exposiciones, blanco y negro... | 0.1116029 | |
| 864554 | Vista trasera de un gatito Maine Coon sentado, mirando hacia arriba, 4 meses de edad, aislado en blanco | 0.11200631 | |
| 478216 | gato himalayo: Gato aislado sobre fondo blanco | 0.11550176 |
# En conclusión
Esta discusión describe cómo migrar datos vectoriales de PostgreSQL a MyScale es sencillo. Y a medida que aumentamos el volumen de datos en MyScale migrando datos de PostgreSQL e importando nuevos datos, MyScale continúa mostrando un rendimiento confiable independientemente del tamaño del conjunto de datos. La frase coloquial: Cuanto más grande, mejor, es cierta en este sentido. El rendimiento de MyScale sigue siendo confiable incluso al consultar conjuntos de datos super grandes.
Por lo tanto, si su negocio experimenta una escala de datos o cuellos de botella de rendimiento, le recomendamos encarecidamente migrar sus datos a MyScale siguiendo los pasos descritos en este artículo.



