
Las bases de datos vectoriales y las búsquedas vectoriales están ganando rápidamente popularidad debido a su velocidad y escalabilidad. A diferencia de los modelos tradicionales de aprendizaje automático que requieren un entrenamiento extenso, las búsquedas vectoriales se pueden realizar rápidamente utilizando medidas de similitud básicas como la distancia euclidiana y la similitud del coseno en una base de datos vectorial. Esto las hace altamente escalables y más rentables en comparación con los modelos basados en aprendizaje automático.
A medida que el uso de las bases de datos vectoriales continúa creciendo, es natural buscar la base de datos más adecuada según las necesidades específicas, teniendo en cuenta diversos factores como el rendimiento y el costo. Para ayudar a los usuarios a tomar decisiones informadas, estamos lanzando una serie de artículos que proporcionan comparaciones detalladas de diferentes bases de datos vectoriales. En nuestro último blog, realizamos una comparación exhaustiva entre MyScale y Pinecone (opens new window). Esta vez, nos sumergiremos en una comparación en profundidad de MyScale y Zilliz.
# MyScale
MyScale es una base de datos basada en la nube diseñada específicamente para aplicaciones y soluciones de IA, aprovechando la base de datos ClickHouse de código abierto y altamente escalable. Las principales ventajas de usar MyScale incluyen:
- Admite y gestiona el procesamiento analítico de datos estructurados y vectorizados en una plataforma unificada.
- Utiliza una arquitectura avanzada de base de datos OLAP para ejecutar operaciones en datos vectorizados con una velocidad excepcional.
- Solo requiere SQL como lenguaje de programación para interactuar con MyScale.
# Introducción a Zilliz
Zilliz, basado en el proyecto de código abierto Milvus, es una potente base de datos vectorial nativa de la nube diseñada para la búsqueda de similitud y el aprendizaje automático de alto rendimiento. Si bien Milvus sirve como base, Zilliz ofrece un servicio en la nube completamente administrado con niveles gratuitos y de pago según el uso, diseñado para usuarios que necesitan gestionar vectores escalables sin la carga de la gestión de la infraestructura.
En este blog, compararemos las ofertas en la nube de MyScale y Zilliz para ayudarte a comprender cuál de ellos podría ser más adecuado para tus necesidades. Comencemos la comparación desde el alojamiento.
# Alojamiento
El alojamiento es un aspecto crítico a considerar al elegir una solución de base de datos, ya que afecta significativamente el rendimiento, la escalabilidad y la gestión. Una opción de alojamiento sólida garantiza que tu base de datos pueda manejar cargas variables, mantenerse accesible y ser fácilmente mantenida. Además, comprender las opciones de alojamiento ayuda a determinar si debes implementar la base de datos localmente utilizando tus propios recursos o optar por un servicio alojado en la nube.
En cuanto al alojamiento, tanto MyScale como Zilliz ofrecen versiones de código abierto, soluciones basadas en la nube y soluciones alojadas localmente. El alojamiento en la nube ofrece niveles gratuitos y de pago, como veremos en detalle en breve.
Para el alojamiento local, una opción general es la imagen de Docker. Podemos lanzar la imagen de Docker de MyScale de la siguiente manera:
docker run --name MyScale --net=host myscale/MyScale:1.6
Para Zilliz, podemos usar Docker compose de la siguiente manera:
curl <https://github.com/milvus-io/milvus/releases/download/v2.0.2/milvus-standalone-docker-compose.yml> -o docker-compose.yml
docker-compose up -d
# Funcionalidades principales
Ahora comenzaremos la comparación en términos de las funcionalidades principales de las dos bases de datos.
# Lenguaje de consulta y soporte de API
Tanto Zilliz como MyScale ofrecen soporte para clientes en varios lenguajes de programación, incluyendo Python, Node.js y Go. Zilliz también admite C++, .Net (parcialmente), RESTful y Ruby.
Sin embargo, el verdadero poder de MyScale radica en su soporte para SQL. Puedes utilizar consultas SQL tradicionales con MyScale, y funcionará perfectamente con bases de datos vectoriales o incluso una combinación de bases de datos tradicionales y vectoriales.
TL;DR:
Tanto Zilliz como MyScale ofrecen SDK en varios lenguajes, pero MyScale tiene una ventaja distintiva con su soporte completo de SQL.
# Soporte de metadatos
Zilliz admite expresiones regulares en la filtración de metadatos. También admite un nuevo índice invertido escalar en su última versión (basado en Milvus 2.4).
MyScale admite la filtración de metadatos a través de su integración con ClickHouse, que proporciona capacidades sólidas de indexación y procesamiento paralelo. Esto permite que MyScale realice búsquedas filtradas de alto rendimiento y precisas, especialmente cuando se trata de conjuntos de datos a gran escala. Además, se adopta una estrategia de prefiltrado para reducir el conjunto de datos antes de la búsqueda vectorial principal, mejorando el rendimiento y la precisión.
TL;DR:
Zilliz tiene la ventaja de las expresiones regulares en la filtración de metadatos, mientras que la filtración de metadatos de MyScale, gracias a la escalabilidad de ClickHouse, no se degrada en rendimiento, incluso para conjuntos de datos más grandes.
# Tipos de datos admitidos
Tanto MyScale como Zilliz admiten obviamente datos vectoriales. La última versión de Zilliz también incluye soporte para vectores dispersos y binarios. Sin embargo, MyScale se destaca con su soporte completo de SQL, lo que le permite manejar todos los tipos de datos SQL. Por ejemplo, aquí hay una tabla que tiene un vector (body_vector) y algunos otros tipos de datos (como UInt64 y String en este caso) como sus atributos.
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 1024
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
TL;DR:
Zilliz tiene la ventaja del soporte de vectores dispersos, mientras que MyScale tiene una ventaja mucho mayor con los tipos de datos SQL completos.
# Indexación
Tanto MyScale como Zilliz admiten muchos algoritmos de indexación como HNSW, IVF (y sus variantes), FLAT, etc. Zilliz proporciona autoindex, que utiliza características como el almacenamiento en caché dinámico y la cuantización dinámica. Autoindex no es un algoritmo de indexación completamente nuevo y utiliza estos algoritmos de indexación admitidos en segundo plano.
MyScale va más allá de Zilliz y de todas las bases de datos vectoriales populares al admitir el Multi-Scale Tree Graph (MSTG), un algoritmo que combina agrupación jerárquica en árbol y búsqueda basada en gráficos. MSTG supera a los algoritmos contemporáneos al proporcionar búsquedas más rápidas con un consumo de recursos reducido.
# Búsqueda vectorial filtrada y búsqueda de texto completo
MyScale optimiza la búsqueda vectorial filtrada a través de su algoritmo Multi-Scale Tree Graph (MSTG), junto con técnicas de enmascaramiento de bits. Esta combinación, junto con las capacidades avanzadas de indexación y procesamiento paralelo de ClickHouse, permite que MyScale maneje eficientemente conjuntos de datos grandes. Al utilizar una estrategia de prefiltrado, MyScale reduce el conjunto de datos antes de la búsqueda vectorial principal, asegurando que solo se procesen los datos más relevantes, lo que mejora significativamente tanto el rendimiento como la precisión.
Zilliz, por otro lado, también utiliza máscaras de bits para administrar y aplicar condiciones de filtrado de manera efectiva en conjuntos de datos grandes. Este enfoque permite que Zilliz realice operaciones de filtrado complejas con un impacto mínimo en el rendimiento.
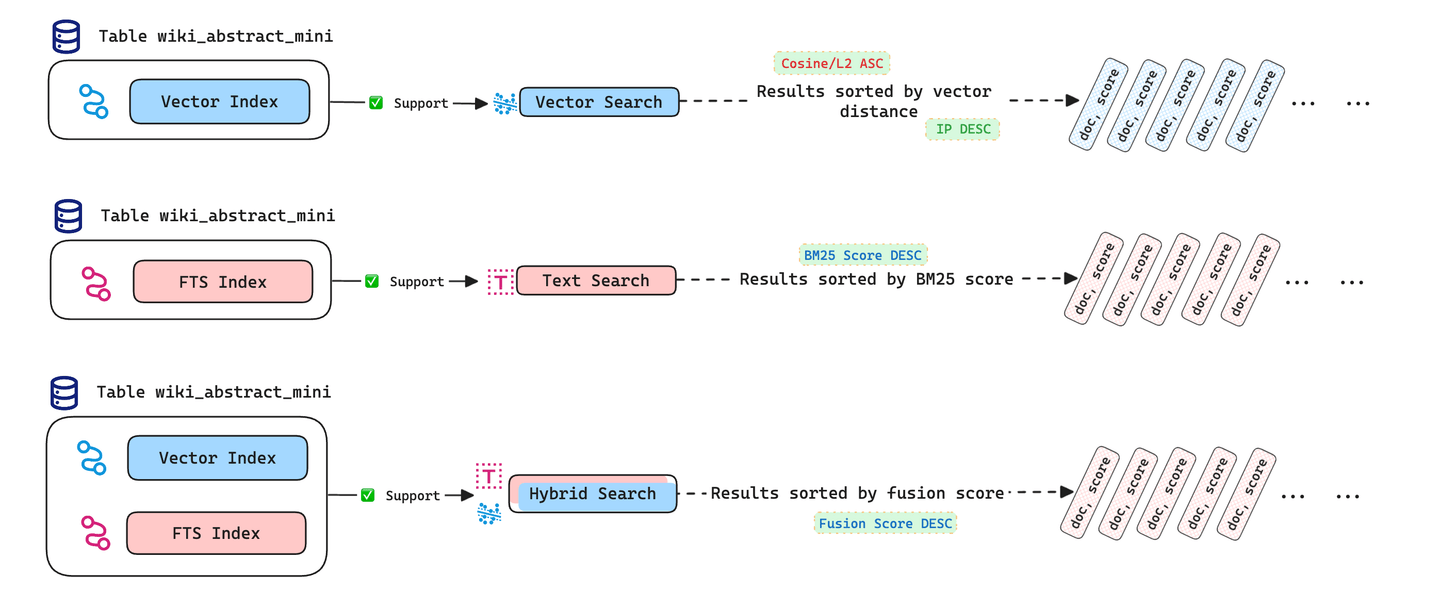
Ambas bases de datos, gracias a Tantivy, tienen una amplia funcionalidad de búsqueda. Admiten la búsqueda de texto completo, que la mayoría de las otras bases de datos vectoriales no admiten. Aparentemente, no hay nada que separe a las dos ya que ambas admiten la búsqueda híbrida (opens new window) también. Aunque realizarla en MyScale es mucho más fácil utilizando la función HybridSearch(). Combina los resultados de las búsquedas de texto completo y vectoriales para proporcionar mejores resultados. La imagen anterior lo explica bastante bien para una tabla dada wiki_abstract_mini.
# Búsqueda de Múltiples Vectores
Tanto MyScale como Zilliz admiten la búsqueda de múltiples vectores. Además, Zilliz ofrece búsqueda de agrupación, donde las entidades almacenadas en múltiples vectores se pueden agrupar en los resultados de búsqueda para obtener resultados consolidados. De manera similar, MyScale admite la búsqueda de agrupación a través de la cláusula GROUP BY en SQL. Esto permite a los usuarios agregar y agrupar resultados de búsqueda de manera eficiente, facilitando el manejo y análisis de conjuntos de datos grandes dentro de MyScale.
# Búsqueda Geoespacial
La búsqueda geoespacial es algo de gran importancia no solo para mapas y aplicaciones SIG, sino también en muchas otras aplicaciones. Incluso una aplicación simple como FoodPanda o alguna tienda de comestibles puede requerirlo. Mientras que Zilliz no lo proporciona, MyScale tiene una serie de funciones geoespaciales (opens new window) para admitir la búsqueda geoespacial. Por ejemplo, esta función encuentra la distancia entre dos puntos en la Tierra (tomados como una variedad):
greatCircleDistance(lon1Deg, lat1Deg, lon2Deg, lat2Deg)
# Integración de APIs LLM
Tanto MyScale como Zilliz admiten varias APIs de LLM como OpenAI, LLamaIndex, LangChain, etc. Ambos también admiten modelos Cohere y DSPy para generar sugerencias automáticas. Como ejemplo, aquí hay un código que integra LangChain con MyScale.
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs,embeddings)
output= docsearch.similarity_search("How LLMs operate?",3)
# Precios
Al final, cada solución está limitada por dos parámetros fundamentales: el precio y la eficiencia. Para la eficiencia, los compararemos en breve. En primer lugar, los compararemos económicamente.
Tanto Zilliz como MyScale ofrecen niveles gratuitos y de pago. Aquí proporcionaré una comparación breve (y al punto) de ambos.
# Nivel gratuito
El nivel gratuito de Zilliz admite dos colecciones de hasta 0.5 millones de vectores de 768 dimensiones (con alojamiento en GCP; Azure y AWS solo están disponibles en servidores dedicados).
Por otro lado, MyScale ofrece almacenamiento gratuito para hasta 5 millones de vectores de 768 dimensiones, lo que significa 10 veces más que la capacidad de una colección o 5 veces más que la capacidad combinada de las dos colecciones. Esto es significativamente mayor que el nivel gratuito de Zilliz (equivalente a 1CU de optimización de capacidad en el nivel de pago), lo que hace que MyScale sea una opción más atractiva para los usuarios que necesitan gestionar conjuntos de datos más grandes sin costos iniciales.
# Nivel de pago
Los niveles gratuitos son buenos para experimentar, pero al final, debemos implementar nuestras soluciones en servidores dedicados, lo que requiere dinero. Aquí analizaremos cuán valiosos son MyScale y Zilliz para tu inversión.
Nota:
Los nodos físicos de Zilliz se conocen como Computing Uni (CU), mientras que los de MyScale se conocen como Pod (y se hará referencia a ellos en adelante en consecuencia).
Tanto Zilliz como MyScale ofrecen dos tipos de alojamiento de pago:
- Optimización de capacidad: Apunta a tener un almacenamiento más grande por pod/CU. MyScale proporciona 10 millones de vectores por pod, mientras que Zilliz proporciona hasta 5 millones de vectores por CU.
- Optimización de rendimiento: Es para las aplicaciones que priorizan el rendimiento (latencia más baja, mayor QPS). Aquí, MyScale proporciona hasta 5 millones de vectores por pod. Zilliz proporciona hasta 1.5 millones de vectores por CU.
Si no estás seguro de cuál elegir, opta por el alojamiento optimizado para capacidad.
En un mundo basado en datos, sería útil mostrar las cifras exactas, ya que te permitiría hacer una comparación mucho más fácilmente. Para la comparación, utilizaremos dimensiones de vector de 768, asumiremos un mes de 30 días ****y será alojamiento en GCP, a menos que se indique lo contrario.
# Zilliz sin servidor
Para el alojamiento sin servidor de Zilliz (que utiliza CUs virtuales), asumiremos 1 millón de operaciones de lectura y 1 millón de operaciones de escritura en un mes en todas las configuraciones.
| Capacidad de Vectores | Tarifa por Hora |
|---|---|
| 1 millón | 0.09$ |
| --- | --- |
| 5 millones | 0.21$ |
| 10 millones | 0.31$ |
| 20 millones | 0.47$ |
| 40 millones | 0.74$ |
| 80 millones | 1.15$ |
# Optimización de Capacidad
Para los CUs optimizados para capacidad, Zilliz proporciona 5 millones por CU y MyScale proporciona 10 millones por pod. Esta diferencia se traduce en un costo por hora mucho más bajo para MyScale.
| Capacidad de Vectores | Zilliz ($) | Unidades de Cómputo (CUs) | MyScale ($) | Pods |
|---|---|---|---|---|
| 10 Millones | 0.276 | 2 | 0.094 | 1 |
| --- | --- | --- | --- | --- |
| 20 Millones | 0.55 | 4 | 0.19 | 2 |
| 40 Millones | 1.1 | 8 | 0.38 | 4 |
| 80 Millones | 2.2 | 16 | 0.76 | 8 |
# Optimización de Rendimiento
Si bien discutimos anteriormente que MyScale proporciona 5 millones por pod en la configuración optimizada para rendimiento, que es más de 3 veces más que el límite proporcionado por Zilliz (1.5 millones por pod), hay mucho más que eso. Zilliz cobra CUs adicionales (aparentemente sin motivo). Si calculas la cantidad de CUs necesarios para, digamos, 10 millones de vectores, deberían ser:
1.510=6.67≈7
Pero muestra 8 CUs. Lo mismo para los 20 millones, donde debería cobrar 14 pero cobra un par de CUs adicionales. Finalmente, lo soluciona para los 40 millones para cobrarte el número exacto de CUs (que aún está muy por debajo de las tarifas por hora de la solución respectiva de MyScale).
| Capacidad de Vectores | Zilliz | CUs | MyScale | Pods |
|---|---|---|---|---|
| 5 Millones | 0.55 | 4 | 0.17 | 1 |
| --- | --- | --- | --- | --- |
| 10 Millones | 1.1 | 8 (deberían ser 7) | 0.33 | 2 |
| 20 Millones | 2.2 | 16 (deberían ser 14) | 0.67 | 4 |
| 40 Millones | 3.84 | 28 | 1.33 | 8 |
| 80 Millones | 7.68 | 56 | 2.67 | 16 |
TL;DR**:
Cuando se trata de la relación valor-precio, no hay competencia con MyScale. Proporciona 2 veces y más de 3 veces más vectores para los niveles optimizados para capacidad y rendimiento que Zilliz, todo a una tarifa por hora (aún) más baja.
# Evaluación
Sería una comparación justa evaluar las dos bases de datos en términos de algunos atributos básicos. Para la evaluación, utilizaremos MyScale (utilizando MSTG) frente a estas dos configuraciones diferentes de Zilliz. Para brindar a los usuarios una comparación imparcial, utilizaremos las últimas versiones de Zilliz:
- 2024-Optimizado para capacidad (1 CU)
- 2024-Optimizado para rendimiento (4 CUs)
# Rendimiento
El número de consultas por segundo es una buena medida básica de una base de datos vectorial. Podemos ver claramente que MyScale (verde lima oscuro) supera a Zilliz con una sola unidad de cómputo. Zilliz con múltiples unidades (color naranja) supera a MyScale en términos de QPS. MyScale, gracias a la afinación de precisión, puede alcanzar una precisión más alta.
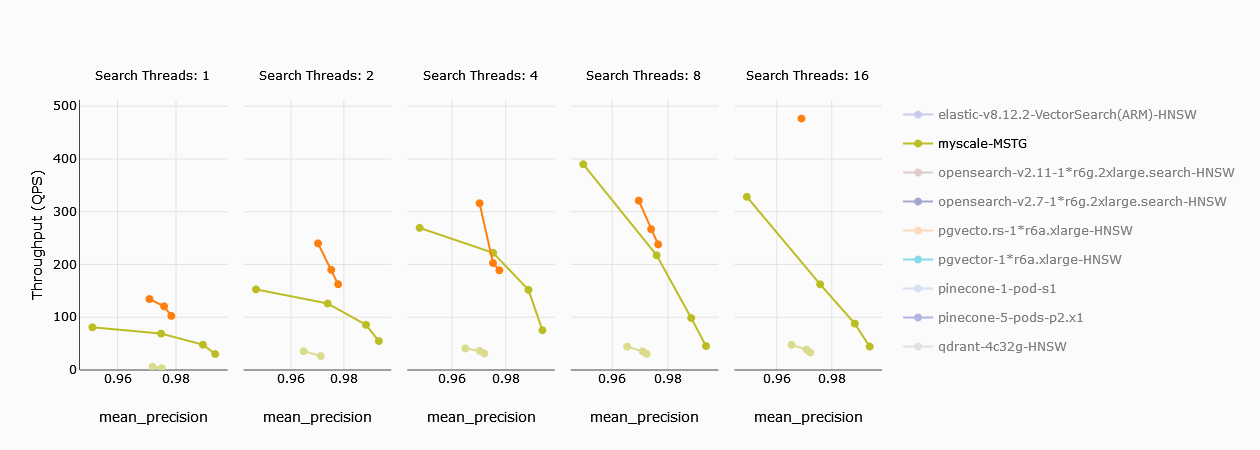
TL;DR**:
MyScale supera a Zilliz con una sola unidad de cómputo. Para 4 unidades, Zilliz supera a MyScale, aunque MyScale tiene una mejor precisión.
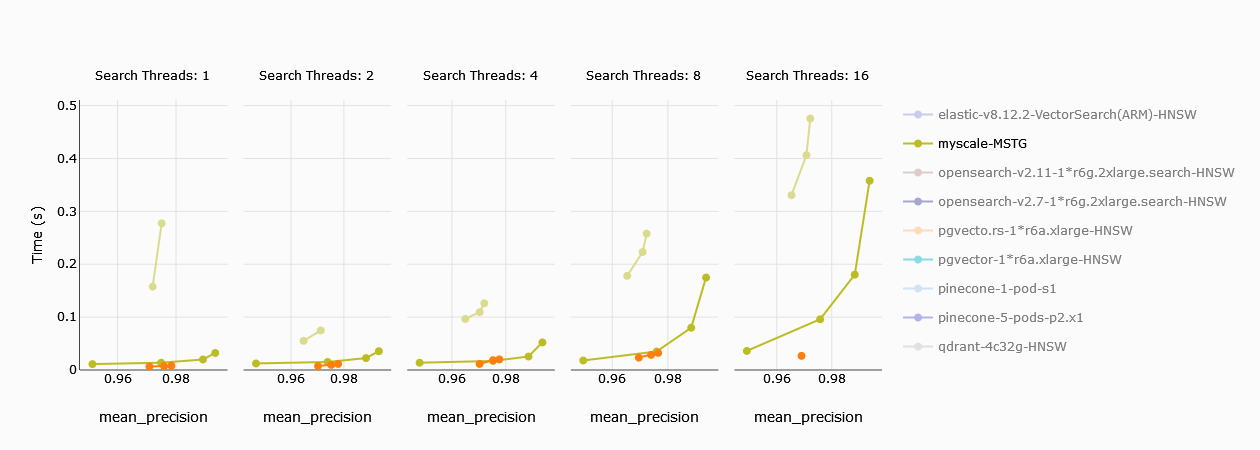
# Latencia Promedio de Consulta
La latencia promedio de consulta se puede definir como el tiempo (cuanto menor, mejor) que le lleva a la base de datos devolver los resultados de la consulta en promedio. MyScale supera cómodamente a los nodos de Zilliz con una sola unidad de cómputo aquí. Incluso para las unidades más altas, la latencia de consulta es del mismo orden para MyScale y Zilliz. Para 16 hilos, el nodo de Zilliz con 4 CUs muestra una mejora sobre MyScale.
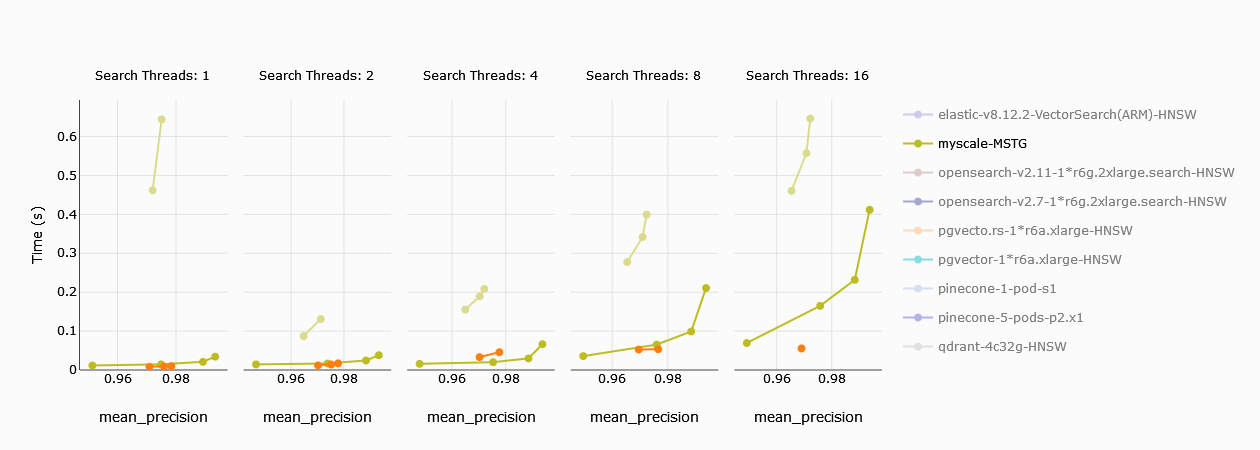
# Latencia P95
Tenemos resultados similares en la latencia P95 también. Una vez que los hilos superan los 8, el nodo de Zilliz con 4 CUs muestra una latencia mejor (más rápida) que MyScale, mientras que para una sola CU, MyScale supera a Zilliz por un margen considerable.
# Tiempo de Ingestión de Datos
Esta evaluación está restringida a un solo hilo, por lo que mostraremos un solo gráfico aquí. MyScale (en verde mar) supera cómodamente a Zilliz en cuanto al tiempo que lleva cargar y construir los datos.
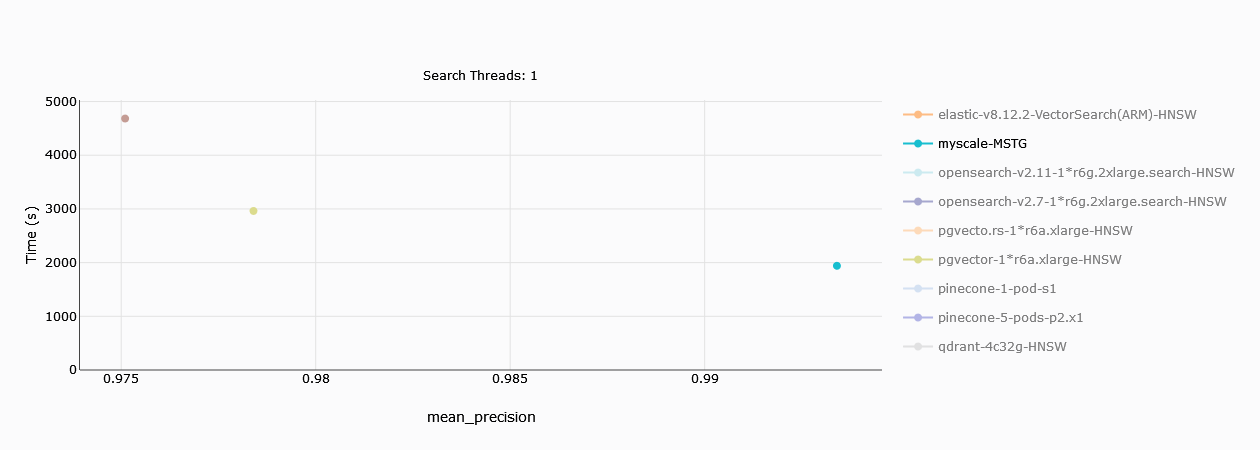
# Comparación de Costos Mensuales
Para una sola unidad de cómputo, Zilliz es comparable a MyScale (aunque aún está rezagado) en términos del costo mensual (por 100 QPS), pero las configuraciones de 4 CUs son mucho más caras que MyScale.
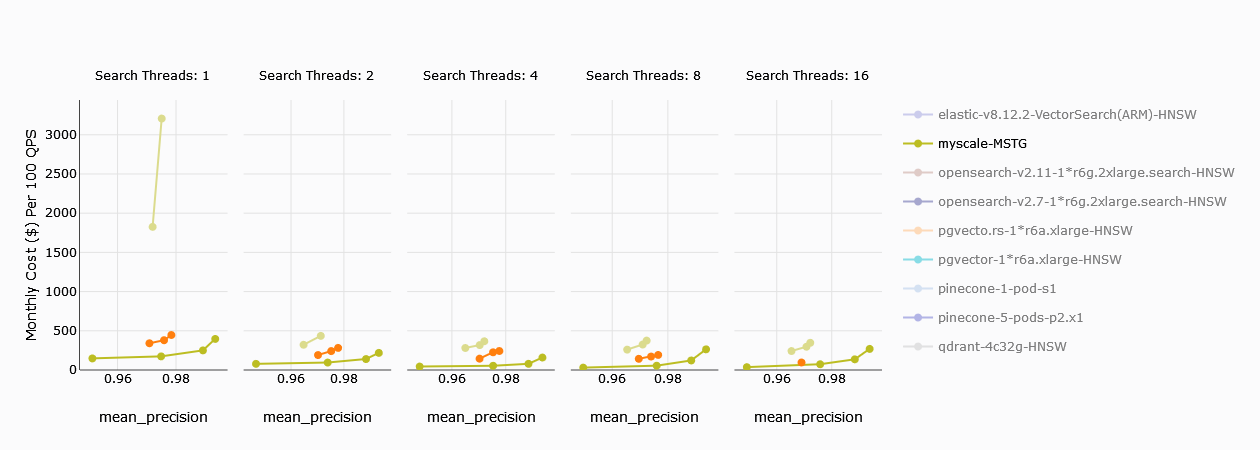
TL;DR**:
MyScale te proporciona el mejor valor para la eficiencia de costos al proporcionar un costo mensual mínimo por QPS.

# Conclusión
Si tienes un presupuesto generoso, tanto Zilliz como MyScale ofrecen características competitivas, lo que dificulta la elección entre ellos según las necesidades específicas del usuario.
Sin embargo, cuando se trata de rentabilidad, MyScale se destaca. Si bien la última versión de Zilliz incluye características avanzadas como la búsqueda de múltiples vectores y el soporte para vectores dispersos, estas mejoras aún están en versión beta y no compensan la importante diferencia de precios.
MyScale ofrece un mejor valor, especialmente en sus niveles de pago. Además, ofrece otras ventajas convincentes, como el soporte completo de SQL, el algoritmo de indexación MSTG superior y niveles gratuitos más generosos. Estos factores hacen de MyScale una opción más atractiva para los usuarios que priorizan tanto el rendimiento como el presupuesto.



