
La búsqueda de vectores busca vectores o puntos de datos similares en un conjunto de datos basándose en sus representaciones vectoriales. Sin embargo, la búsqueda de vectores pura rara vez es suficiente en escenarios del mundo real. Los vectores suelen venir con metadatos y los usuarios a menudo necesitan aplicar uno o más filtros a estos metadatos. Es ahí donde entra en juego la búsqueda de vectores filtrados.
La búsqueda de vectores filtrados se está volviendo cada vez más vital para escenarios de recuperación complicados. Puede aplicar un mecanismo de filtrado para filtrar los vectores no deseados más allá de los mejores k/rango de incrustaciones multidimensionales.
En este blog, primero discutimos los desafíos técnicos de implementar la búsqueda de vectores filtrados. Luego, proporcionamos una solución considerando cómo MyScale optimiza la búsqueda de vectores filtrados utilizando nuestro algoritmo propietario, MSTG, junto con ClickHouse para un filtrado rápido en datos estructurales.
# Desafíos técnicos de implementar la búsqueda de vectores filtrados
Con la creciente diversidad de tipos de datos dentro de grandes conjuntos de datos en aplicaciones modernas, elegir el enfoque adecuado de búsqueda de vectores filtrados y el algoritmo de indexación de vectores realmente importa para mejorar la calidad de los resultados de búsqueda y proporcionar resultados de búsqueda más precisos. Ahora, profundicemos en cada uno de estos desafíos.
# Pre-filtrado vs. Post-filtrado
Según cuándo ocurre el filtrado en el proceso de búsqueda de vectores, la búsqueda filtrada se puede categorizar como pre-filtrado o post-filtrado, como se ilustra en la siguiente figura.
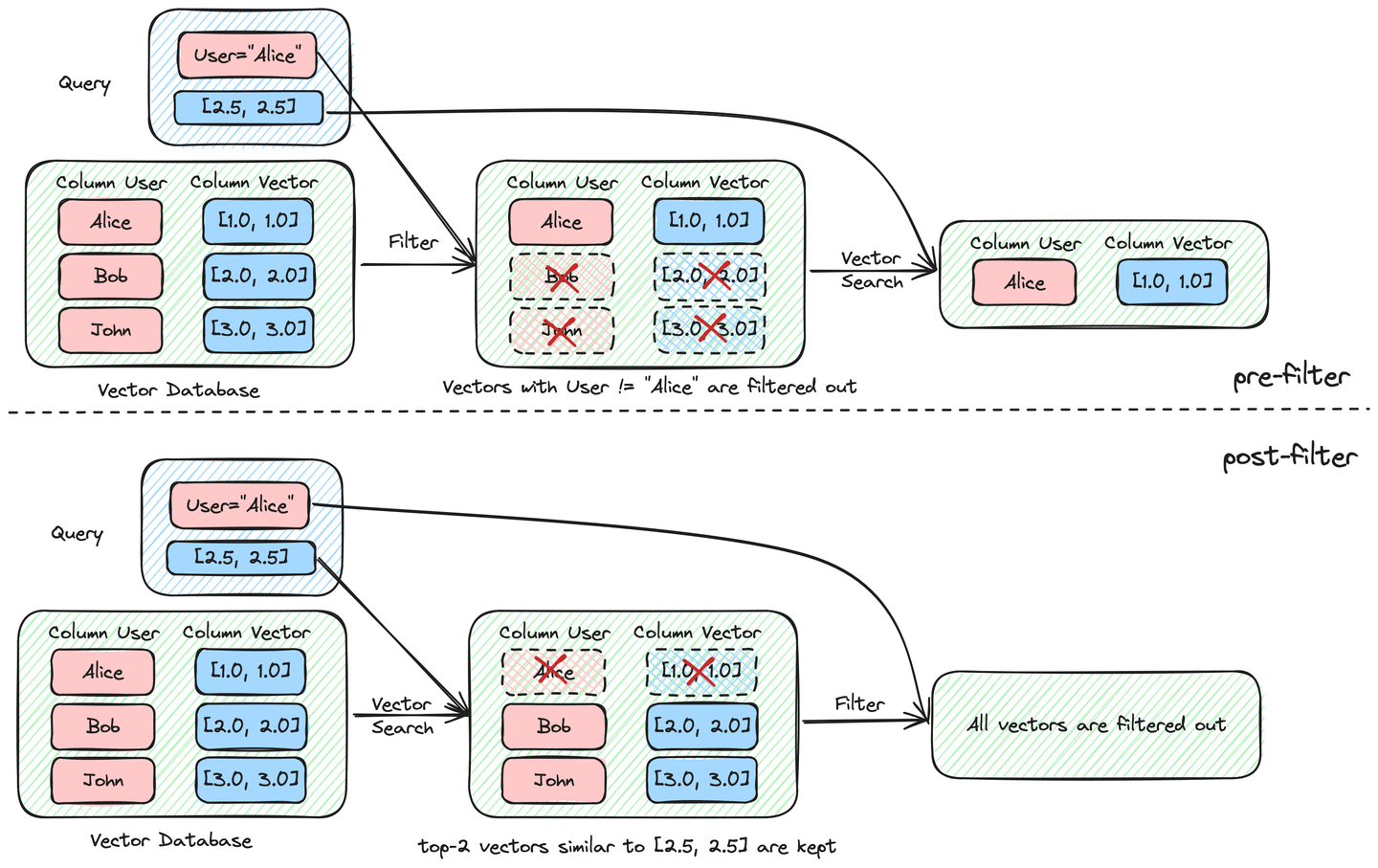 Cuando se utiliza el pre-filtrado, obtenemos la salida esperada
Cuando se utiliza el pre-filtrado, obtenemos la salida esperada ("Alice", [1.0, 1.0]). Sin embargo, el post-filtrado no produce ningún resultado.
# Pre-filtrado
La búsqueda de vectores con pre-filtrado es una técnica que implica la selección inicial de posibles coincidencias antes de realizar la consulta principal de búsqueda de vectores en un conjunto de datos. El propósito es reducir el espacio de búsqueda y eliminar resultados no elegibles o innecesarios en una etapa temprana, mejorando la eficiencia y precisión de la búsqueda de vectores posterior. Este método es particularmente beneficioso en escenarios donde el conjunto de datos es grande y los recursos computacionales deben utilizarse de manera prudente.
Considere un escenario en el que tiene una vasta base de datos de imágenes y desea recuperar imágenes que se asemejen estrechamente a una imagen de consulta dada. En lugar de realizar una búsqueda detallada de vectores en todo el conjunto de datos de imágenes, puede prefiltrar posibles candidatos en función de características simples como histogramas de color, relaciones de aspecto o descriptores de bajo nivel. Por ejemplo, puede prefiltrar imágenes que tengan distribuciones de color o formas similares a la imagen de consulta.
En resumen, el pre-filtrado es un enfoque estratégico para mejorar el rendimiento general de las búsquedas de similitud al reducir inteligentemente el alcance de la operación de búsqueda.
Nota:
El pre-filtrado siempre se utiliza en la implementación de búsqueda filtrada de MyScale.
# Post-filtrado
A diferencia del pre-filtrado, que ocurre antes de la búsqueda principal de vectores, el post-filtrado es una técnica en la que se ejecuta una consulta de búsqueda de vectores pura en un conjunto de datos y luego, después de obtener los resultados iniciales, se aplican pasos adicionales de filtrado o refinamiento. Sin embargo, este método tiene ciertas limitaciones y desventajas que pueden afectar la eficiencia y precisión de los resultados de búsqueda. Estos resultados pueden ser impredecibles debido a que el filtro se aplica a un conjunto reducido de resultados. En casos en los que el filtro es altamente restrictivo, apuntando solo a un pequeño porcentaje de puntos de datos en relación con el tamaño del conjunto de datos, existe la posibilidad de que no haya coincidencias en la búsqueda inicial de vectores.
Bases de datos de vectores populares como PostgreSQL/pgvector y OpenSearch han adoptado este enfoque, lo que conduce a una baja precisión de búsqueda filtrada, como se muestra en nuestro blog anterior (opens new window).
# Por qué HNSW tiene un rendimiento deficiente para la búsqueda filtrada
Aunque los algoritmos de gráficos populares como HNSW funcionan bien para la búsqueda de vectores no filtrados, su rendimiento puede disminuir significativamente para las búsquedas de vectores filtrados.
Primero, definamos la relación de filtro de una búsqueda de vectores filtrados de la siguiente manera:
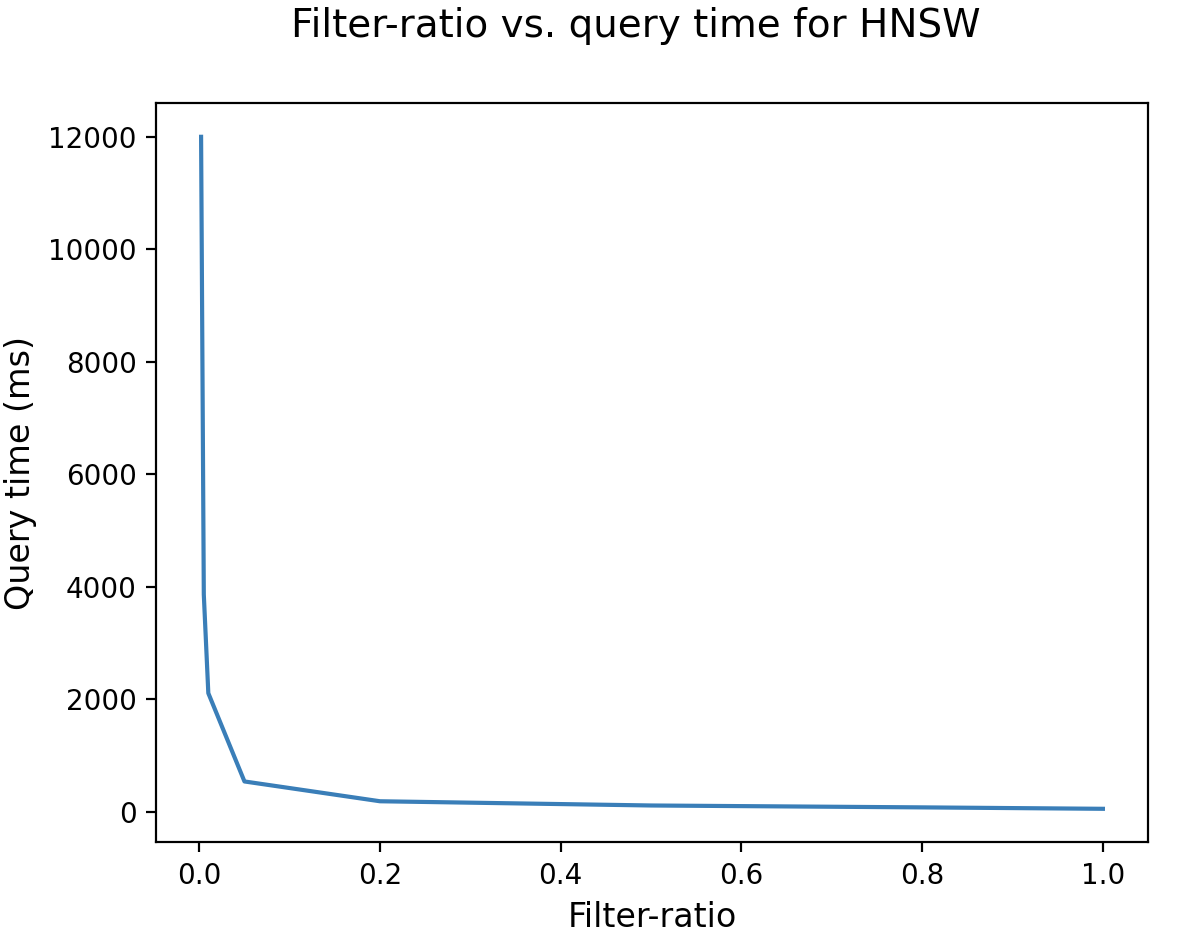
Cuando la relación de filtro es baja, el filtrado se vuelve muy restrictivo. Como se muestra en la siguiente figura, el algoritmo HNSW tiene un rendimiento deficiente en este caso, tardando varios segundos cuando la relación de filtro es inferior al 1%:
Analicemos por qué HNSW tiene un rendimiento deficiente cuando la relación de filtro es baja, comenzando por examinar su proceso de búsqueda. Durante esta búsqueda de vectores, la búsqueda de nodos del nivel base es el proceso que consume más tiempo. Al igual que la búsqueda de nodos en la mayoría de los algoritmos de gráficos, HNSW utiliza un conjunto de candidatos para almacenar los nodos a visitar y un conjunto de candidatos principales para almacenar los nodos principales potenciales. Las condiciones para terminar la búsqueda incluyen:
- El número de candidatos principales ya cumple con los requisitos del algoritmo, y
- Si la distancia máxima entre los candidatos principales y el vector de consulta es menor que la distancia mínima entre el conjunto de candidatos y el vector de consulta.
A diferencia del proceso de búsqueda de vectores ordinario, HNSW con búsqueda filtrada verificará si el nodo está en el conjunto seleccionado antes de agregarlo a la lista de candidatos principales potenciales.
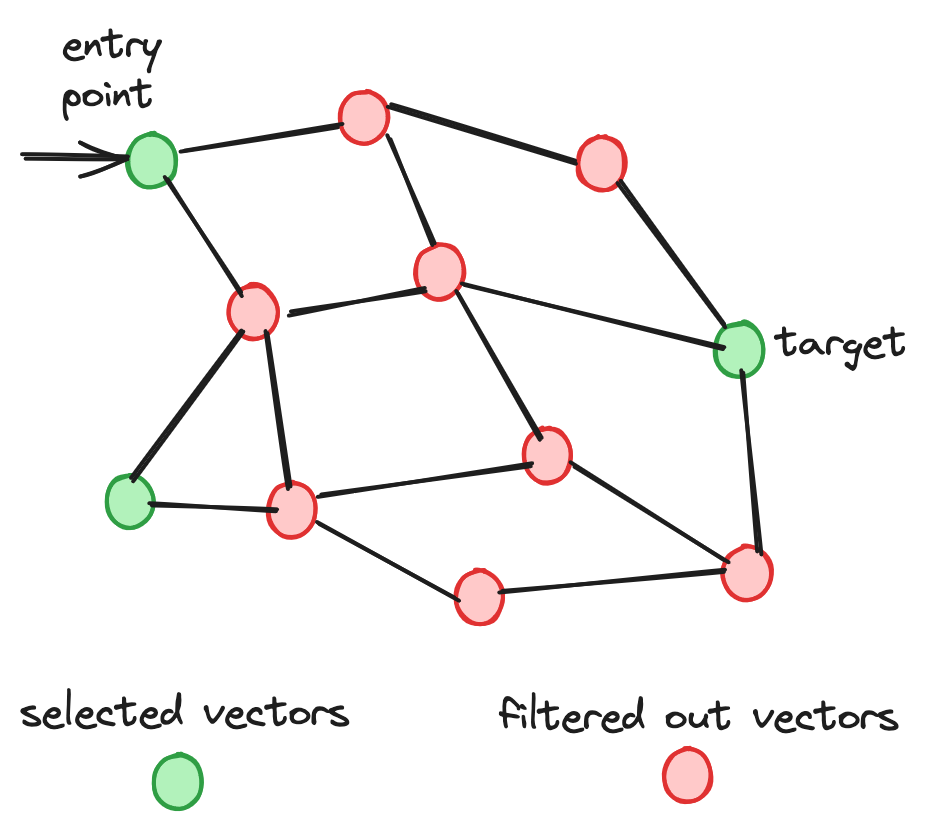
La baja relación de filtro plantea un desafío significativo para el índice al identificar un número suficiente de candidatos principales. Esta limitación conduce a una extensa travesía de nodos. Además, el desafío se ve agravado por la dificultad de recorrer el gráfico de manera eficiente para localizar los vecinos más cercanos filtrados.
Una técnica común de optimización para la búsqueda de vectores filtrados utilizando HNSW es cambiar a una búsqueda de fuerza bruta cuando la relación de filtro cae por debajo de un umbral específico. Sin embargo, no recomendamos este enfoque, ya que no es práctico para vectores a gran escala, como bases de datos que contienen cientos de millones o incluso miles de millones de vectores. En estas circunstancias, incluso una relación de filtro del 1% requiere calcular las distancias entre el vector de consulta y millones de vectores en la base de datos.
# Búsqueda avanzada de vectores filtrados en MyScale
Dado que identificamos el problema, trabajemos en una solución. MyScale es una base de datos de vectores SQL que combina un motor de ejecución de SQL rápido (basado en ClickHouse) con el algoritmo propietario de árbol de gráficos de múltiples escalas (MSTG) para una búsqueda filtrada rápida. Esta sección explora nuestra justificación para construir MyScale sobre ClickHouse, conocido como la base de datos analítica de código abierto más rápida, y explica nuestras mejoras en el algoritmo de vectores para una búsqueda filtrada eficiente. Estas optimizaciones han contribuido a una capacidad de búsqueda de vectores filtrados de alto rendimiento, flexible y robusta en MyScale.
Nota:
MyScale es una base de datos de vectores integrada con soporte completo de SQL.
# Aprovechando ClickHouse para la búsqueda de vectores filtrados
La elección de ClickHouse como base para MyScale se basó en su eficiencia comprobada en el manejo de datos a gran escala. La velocidad superior de escaneo de datos de ClickHouse fue clave para esta decisión, fundamental para búsquedas de vectores filtrados de alto rendimiento. Los siguientes diseños han mejorado enormemente su eficiencia:
- Almacenamiento orientado a columnas: A diferencia de las bases de datos tradicionales orientadas a filas, ClickHouse almacena los datos en columnas, lo que hace que la lectura y el procesamiento de datos sean más rápidos. Este diseño es especialmente beneficioso para funciones de agregación y filtros, ya que lee eficientemente solo las columnas necesarias del disco, reduciendo las operaciones de E/S.
- Ejecución de consultas vectorizadas: ClickHouse procesa los datos en lotes, no fila por fila. Este enfoque vectorizado le permite realizar operaciones en varios puntos de datos simultáneamente, acelerando significativamente la ejecución de consultas. Esto es particularmente ventajoso para búsquedas de vectores filtrados en conjuntos de datos extensos.
- Indexación avanzada: ClickHouse utiliza técnicas de indexación sofisticadas, como índices de salto. La base de datos salta rápidamente sobre bloques de datos irrelevantes durante una consulta, lo que resulta en un filtrado más rápido, ya que la base de datos pasa menos tiempo escaneando datos no relacionados.
- Procesamiento paralelo: La arquitectura de ClickHouse admite el procesamiento paralelo, lo que le permite distribuir la carga de trabajo en múltiples núcleos y nodos. Esta paralelización es crucial para manejar consultas y filtros a gran escala de manera eficiente, asegurando un alto rendimiento incluso con conjuntos de datos grandes y complejos.
Estas características hacen de ClickHouse una plataforma ideal para implementar búsquedas de vectores filtrados rápidas y eficientes. Esta integración ofrece lo mejor de ambos mundos: las potentes capacidades analíticas de ClickHouse y las funcionalidades de la base de datos de vectores sutiles y esenciales para manejar datos vectoriales complejos y ricos en metadatos.
# Algoritmo de árbol de gráficos de múltiples escalas
El árbol de gráficos de múltiples escalas (MSTG) es un nuevo índice de vectores desarrollado por MyScale. A diferencia de los algoritmos populares como HNSW, que se basa únicamente en gráficos jerárquicos, y IVF (índice de archivo invertido), que se puede ver como un árbol de dos niveles, MSTG combina las mejores partes de las estructuras de gráficos jerárquicos y de árbol en su diseño.
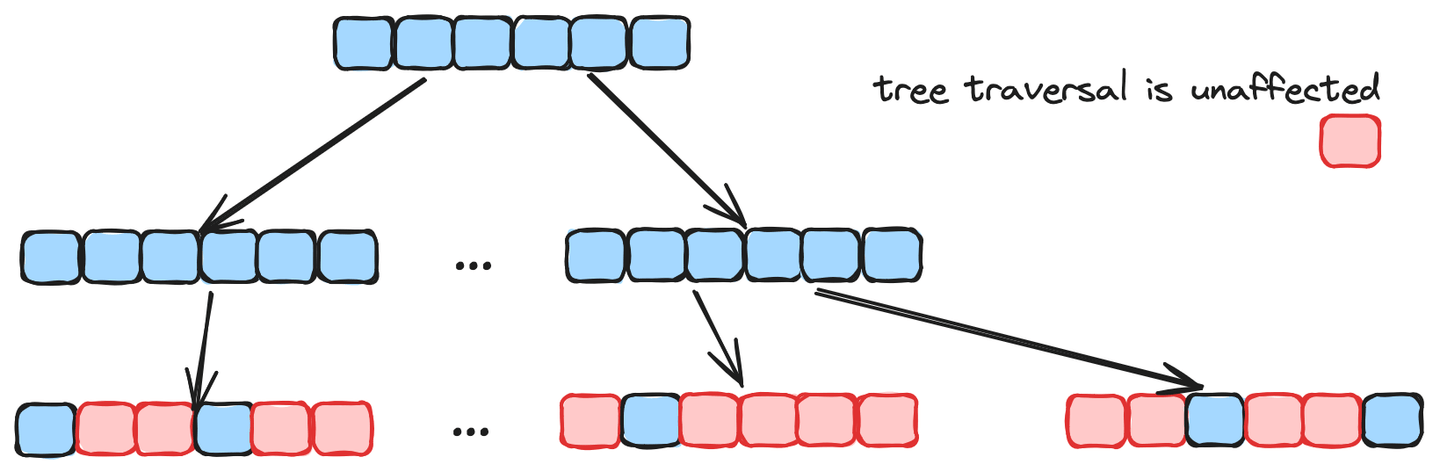
Un algoritmo de gráficos destaca en la convergencia inicial y generalmente es más rápido en la búsqueda no filtrada. Sin embargo, su eficiencia se ve gravemente afectada en la búsqueda filtrada. Por otro lado, los algoritmos de árbol son más lentos y tienen una menor precisión en la búsqueda no filtrada, pero el recorrido del árbol no se ve afectado por los elementos filtrados y mantiene el rendimiento en la búsqueda filtrada, como se ilustra en la siguiente figura. Por lo tanto, combinar estos dos algoritmos en MSTG produce un alto rendimiento y alta precisión para ambos casos y logra un tiempo de construcción de índice rápido. Además, MSTG ha acelerado tanto el pre-filtrado como el cálculo de la distancia de vectores con SIMD (Instrucción única, datos múltiples), mejorando en gran medida el rendimiento de cálculo en las CPU modernas.

# Conclusión
La búsqueda de vectores busca puntos de datos similares basándose en representaciones vectoriales, pero los escenarios del mundo real requieren más que una búsqueda de vectores pura. Los vectores con metadatos a menudo requieren una búsqueda de vectores filtrados, que es crucial para escenarios de recuperación complicados.
El enfoque innovador de MyScale para la búsqueda de vectores filtrados, combinando las fortalezas de ClickHouse y el algoritmo propietario MSTG, ofrece una solución potente para búsquedas de vectores complejas a gran escala. Esta integración proporciona velocidad y precisión, convirtiendo a MyScale en líder en tecnología de bases de datos de vectores.
Puede encontrar informes de referencia entre MyScale y otros competidores en el siguiente contenido:



