
El surgimiento de modelos de lenguaje grandes y poderosos (LLMs) como GPT-4, Gemini 1.5 y Claude 3 ha sido un cambio de juego en IA y tecnología. Con algunos modelos capaces de procesar más de 1 millón de tokens (opens new window), su capacidad para manejar contextos largos es realmente impresionante. Sin embargo:
- Muchas estructuras de datos son demasiado complejas y están en constante evolución para que los LLMs las manejen de manera efectiva por sí solos.
- Gestionar datos empresariales masivos y heterogéneos dentro de una ventana de contexto es simplemente impráctico.
La generación de recuperación mejorada (RAG) ayuda a abordar estos problemas, pero la precisión de la recuperación es un cuello de botella importante para el rendimiento de extremo a extremo, y muchas bases de datos vectoriales no se escalan bien para casos de uso complejos. Una solución es integrar LLMs con big data a través de bases de datos vectoriales SQL avanzadas. Este tipo de sinergia entre LLMs y big data no solo hace que los LLMs sean más efectivos, sino que también permite a las personas obtener una mejor inteligencia de los datos masivos. Además, reduce aún más la alucinación del modelo al tiempo que proporciona transparencia y confiabilidad de los datos.
# Estado actual de las bases de datos vectoriales
Como piedra angular de los sistemas RAG, las bases de datos vectoriales han desarrollado rápidamente en el último año. En general, se pueden clasificar en tres tipos: bases de datos vectoriales dedicadas, sistemas de recuperación de palabras clave y vectores, y bases de datos vectoriales SQL. Cada uno tiene ventajas y limitaciones.
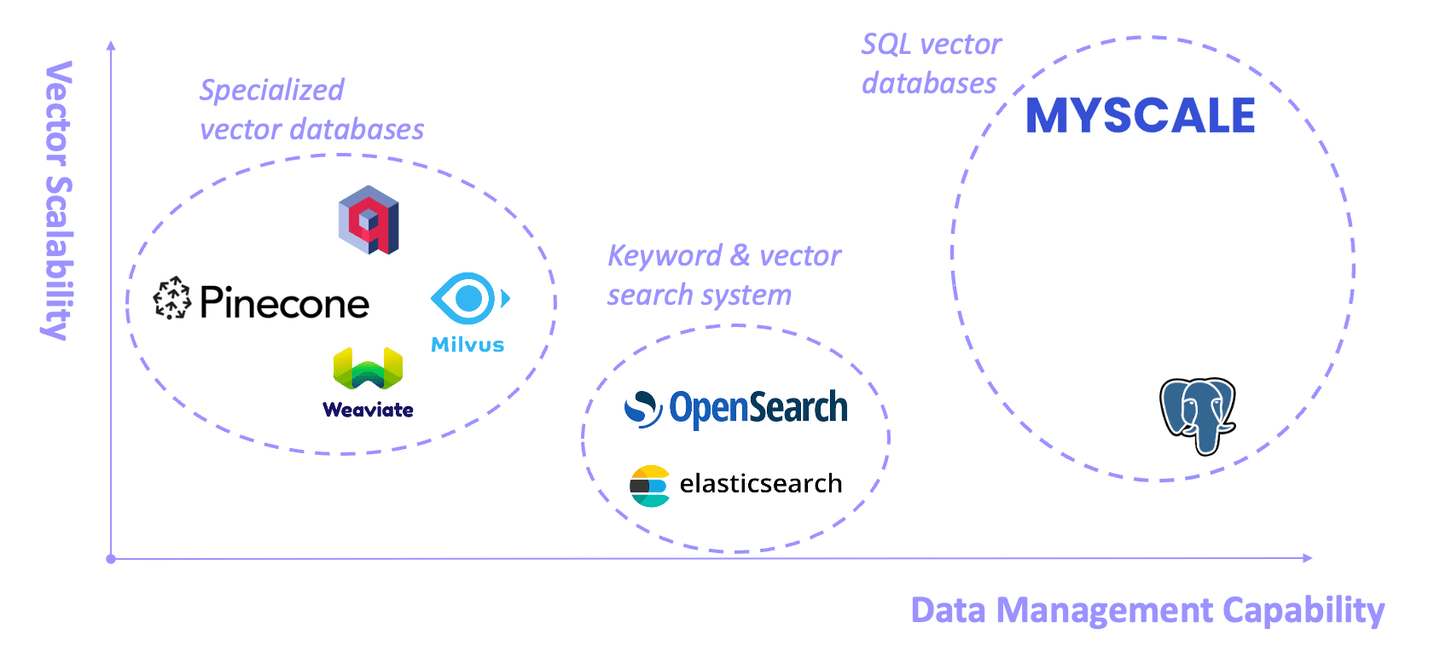
# Bases de datos vectoriales especializadas
Algunas bases de datos vectoriales (como Pinecone, Weaviate y Milvus) están diseñadas específicamente para la búsqueda vectorial desde el principio. Exhiben un buen rendimiento en esta área, pero tienen capacidades de gestión de datos generales algo limitadas (opens new window).
# Sistemas de recuperación de palabras clave y vectores
Representados por Elasticsearch y OpenSearch, estos sistemas se utilizan ampliamente en producción debido a sus completas capacidades de recuperación basadas en palabras clave. Sin embargo, consumen recursos sustanciales del sistema y la precisión y el rendimiento de las consultas híbridas de palabras clave y vectores suelen ser insatisfactorios (opens new window).
# Bases de datos vectoriales SQL
La base de datos vectorial SQL (opens new window) es un tipo especializado de base de datos que combina las capacidades de las bases de datos SQL tradicionales con las capacidades de una base de datos vectorial. Te permite almacenar y consultar eficientemente vectores de alta dimensión con la ayuda de SQL.
En la figura anterior se ilustran dos bases de datos vectoriales SQL principales: pgvector y MyScaleDB. pgvector es un complemento de búsqueda vectorial para PostgreSQL. Es fácil de empezar a usar y útil para gestionar conjuntos de datos pequeños. Sin embargo, debido a las desventajas de almacenamiento de filas de Postgres y las limitaciones del algoritmo vectorial, pgvector tiende a tener una precisión y rendimiento más bajos para consultas vectoriales complejas a gran escala.
MyScaleDB (opens new window) es una base de datos vectorial SQL de código abierto construida sobre ClickHouse (una base de datos SQL de almacenamiento columnar). Está diseñada para proporcionar una base de datos de alto rendimiento y rentable para aplicaciones GenAI. MyScaleDB es también la primera base de datos vectorial SQL que supera a las bases de datos vectoriales especializadas (opens new window) en rendimiento general y rentabilidad.

Fuente: https://myscale.github.io/benchmark (opens new window)
# El poder de la modelización conjunta de datos SQL y vectoriales
A pesar del surgimiento de tecnologías NoSQL y big data, las bases de datos SQL siguen dominando el mercado de gestión de datos medio siglo después del inicio de SQL. Incluso sistemas como Elasticsearch y Spark han agregado interfaces SQL. Con el soporte de SQL, MyScaleDB, una base de datos vectorial SQL, permite un alto rendimiento en la búsqueda y análisis de vectores (opens new window).
En aplicaciones de IA del mundo real, la integración de SQL y vectores mejora la flexibilidad de la modelización de datos y simplifica el desarrollo. Por ejemplo, un producto académico a gran escala utiliza MyScaleDB para preguntas y respuestas inteligentes sobre datos masivos de literatura científica. El esquema SQL principal incluye más de 10 tablas, varias de ellas con estructuras de índices invertidos basados en vectores y palabras clave, conectadas mediante claves primarias y foráneas. El sistema maneja consultas complejas que involucran datos estructurados, vectoriales y basados en palabras clave, así como consultas conjuntas en múltiples tablas. Esta es una tarea desafiante para las bases de datos vectoriales especializadas, que a menudo conduce a una iteración lenta, consultas ineficientes y altos costos de mantenimiento.
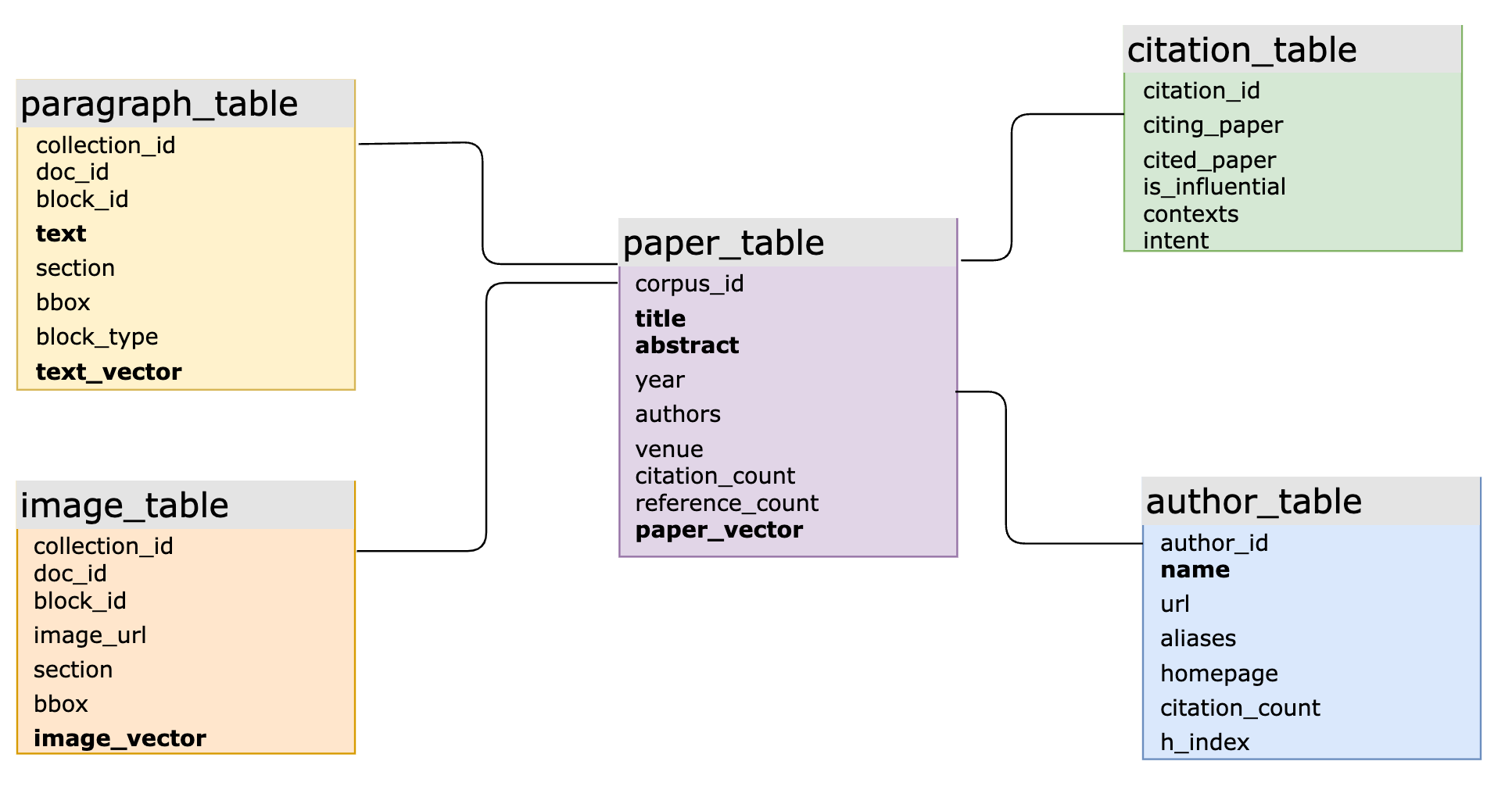
El esquema principal de la base de datos vectorial SQL de un producto académico a gran escala respaldado por MyScale (las columnas en negrita tienen índices vectoriales o índices invertidos asociados)
# Mejorando la precisión y rentabilidad de RAG
En los sistemas RAG del mundo real, superar la precisión de la recuperación (y los cuellos de botella de rendimiento asociados) requiere una forma eficiente de combinar la consulta de datos estructurados, vectoriales y basados en palabras clave.
Por ejemplo, en una aplicación financiera, cuando los usuarios consultan una base de datos de documentos preguntando: "¿Cuál fue el ingreso de <nombre_de_compañía> en 2023 a nivel mundial?", los metadatos estructurados como "<nombre_de_compañía>" y "2023" pueden no estar capturados por vectores semánticos o presentes en texto consecutivo. La recuperación vectorial en toda la base de datos puede producir resultados ruidosos, reduciendo la precisión final.
Sin embargo, la información como los nombres de las compañías y los años a menudo se puede obtener como metadatos del documento. El uso de WHERE year=2023 AND company LIKE "%<nombre_de_compañía>%" como condiciones de filtrado para consultas vectoriales puede ubicar con precisión la información relevante, aumentando significativamente la confiabilidad del sistema. En finanzas, manufactura e investigación, se ha observado que la modelización de datos vectoriales SQL y las consultas conjuntas mejoran la precisión del 60% al 90%.
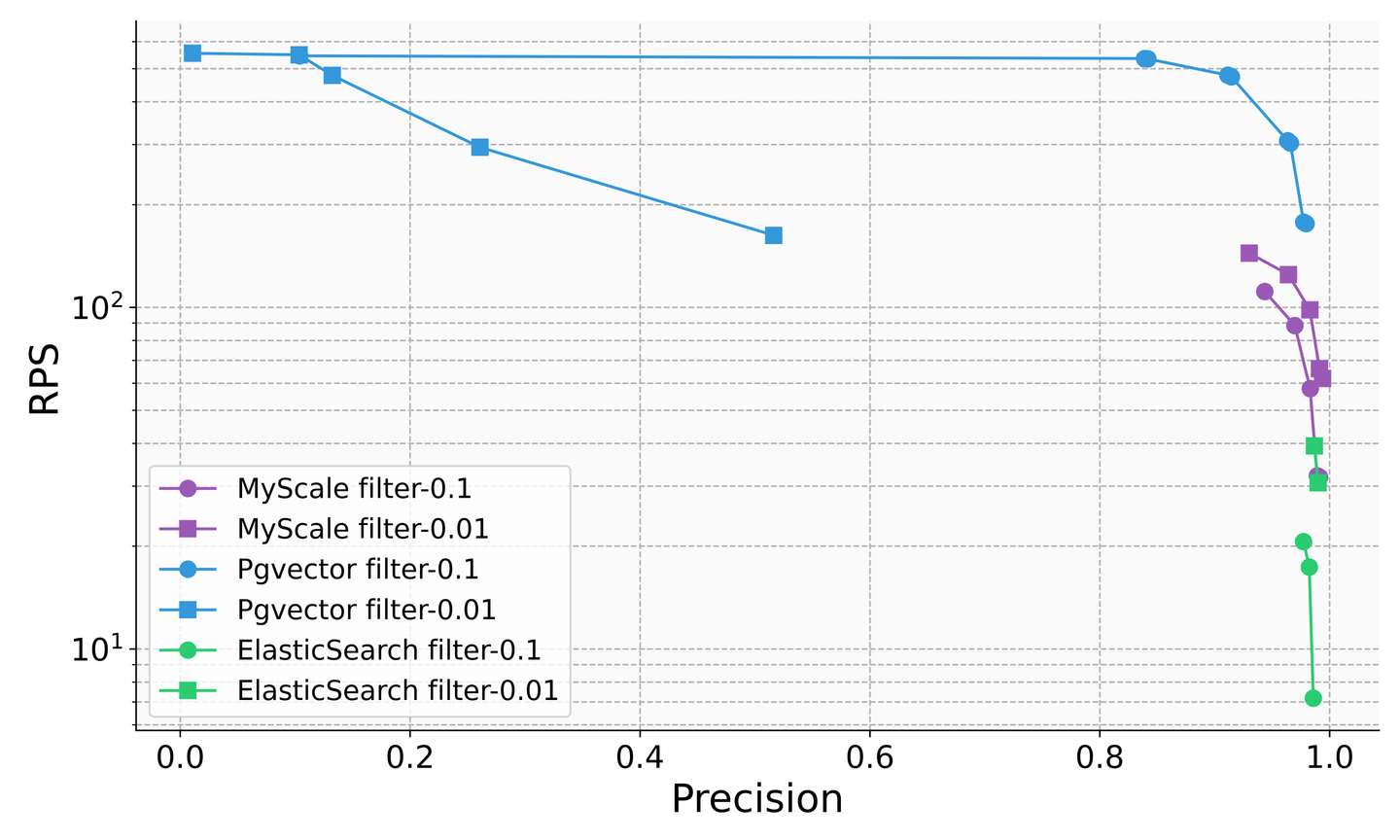
Si bien los productos de bases de datos tradicionales han reconocido la importancia de las consultas vectoriales en la era de LLM y han comenzado a agregar capacidades vectoriales, todavía existen problemas significativos con la precisión de sus consultas combinadas. Por ejemplo, en escenarios de búsqueda con filtros, la tasa de consultas por segundo (QPS) de Elasticsearch cae a aproximadamente cinco cuando la proporción de filtrado es 0.1, y PostgreSQL con el complemento pgvector tiene una precisión de solo alrededor del 50% cuando la proporción de filtrado es 0.01. Esto demuestra una precisión y rendimiento de consulta inestables que limitan en gran medida su uso. En contraste, la base de datos vectorial SQL MyScale logra más de 100 QPS y una precisión del 98% en varios escenarios de proporción de filtrado, a un costo del 36% del pgvector y el 12% del Elasticsearch.

# LLM + Big Data: Construyendo una plataforma de agente de próxima generación
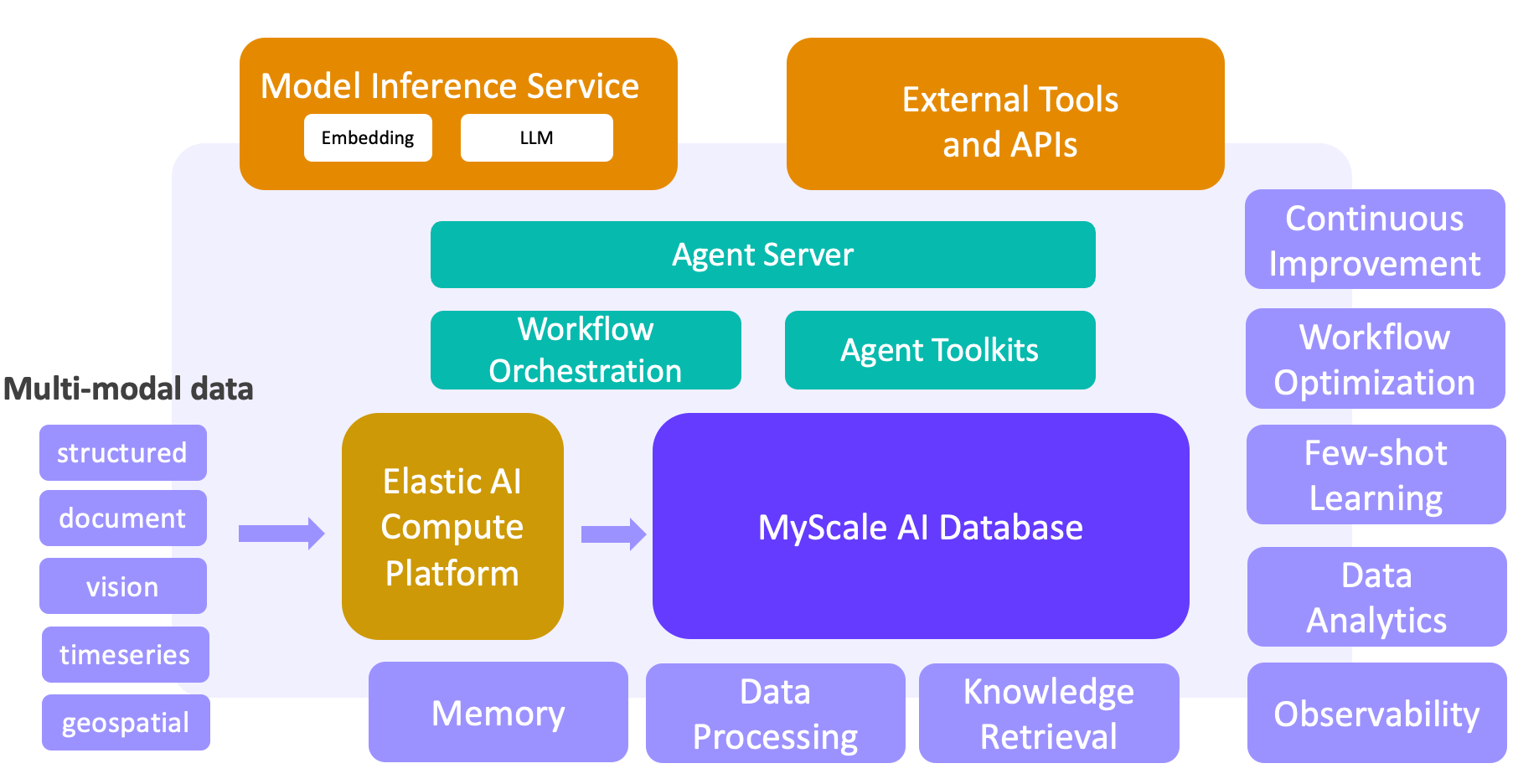
El aprendizaje automático y el big data han impulsado el éxito de las aplicaciones web y móviles. Pero con el surgimiento de los LLMs, estamos cambiando de marcha para construir una nueva generación de soluciones LLM + big data. Impulsadas por MyScaleDB, nuestra base de datos vectorial SQL de alto rendimiento, estas soluciones desbloquean capacidades clave para el procesamiento de datos a gran escala, la recuperación de conocimientos, la observabilidad, el análisis de datos, el aprendizaje de pocos ejemplos y más. Basado en MyScaleDB, se crea un ciclo cerrado entre los datos y la IA, formando la base de nuestra plataforma de agente LLM + big data de próxima generación. Este cambio de paradigma ya está en marcha en sectores como la investigación científica, las finanzas, la industria y la atención médica.
Con el rápido desarrollo de la tecnología, se espera que algún tipo de inteligencia artificial general (AGI) emerja en los próximos cinco a diez años. Ante este problema, debemos preguntarnos: ¿Necesitamos un modelo virtual estático u otra solución más integral? Los datos son sin duda el eslabón importante que conecta los LLMs, los usuarios y el mundo. Nuestra visión es integrar orgánicamente los LLMs y el big data para crear un sistema de IA más profesional, en tiempo real y colaborativo, que también esté lleno de calidez humana y valor.
Te invitamos a explorar el repositorio de MyScaleDB de código abierto en GitHub (opens new window) y aprovechar SQL y los vectores para construir aplicaciones de IA innovadoras de nivel de producción.



