
Imagina que eres un desarrollador de software en busca de técnicas de optimización de bases de datos, especialmente para mejorar la eficiencia de las consultas en bases de datos a gran escala. En una base de datos SQL tradicional, podrías usar palabras clave como "indexación de árbol B" o simplemente "indexación" para encontrar blogs o artículos relacionados. Sin embargo, este enfoque basado en palabras clave podría pasar por alto blogs o artículos importantes que utilizan frases diferentes pero relacionadas, como "ajuste de SQL" o "estrategias de indexación".
Considera otro escenario en el que tienes conocimiento del contexto pero no del nombre exacto de una técnica específica. Las bases de datos tradicionales, al depender de coincidencias exactas de palabras clave, fallan en tales situaciones, ya que no pueden buscar solo en función del contexto.
Lo que necesitamos, entonces, es una técnica de búsqueda que vaya más allá de la simple coincidencia de palabras clave y ofrezca resultados basados en similitudes semánticas. Aquí es donde entra en juego la búsqueda vectorial. A diferencia de las técnicas tradicionales de coincidencia de palabras clave, la búsqueda vectorial compara la semántica de tu consulta con las entradas de la base de datos, devolviendo resultados más relevantes y precisos.
En este blog, discutiremos todo lo relacionado con la búsqueda vectorial, comenzando por los conceptos básicos y luego pasando a técnicas más avanzadas. Comencemos con una descripción general de la búsqueda vectorial.
# Una descripción general de la búsqueda vectorial
La búsqueda vectorial es una técnica sofisticada de recuperación de datos que se centra en la coincidencia de los significados contextuales de las consultas de búsqueda y las entradas de datos, en lugar de la simple coincidencia de texto. Para implementar esta técnica, primero debemos convertir tanto la consulta de búsqueda como una columna específica del conjunto de datos en representaciones numéricas, conocidas como incrustaciones vectoriales. Luego, calculamos la distancia (similitud del coseno o distancia euclidiana) entre el vector de consulta y las incrustaciones vectoriales en la base de datos. A continuación, identificamos las entradas más cercanas o más similares en función de estas distancias calculadas. Por último, devolvemos los mejores k resultados con las distancias más pequeñas al vector de consulta.
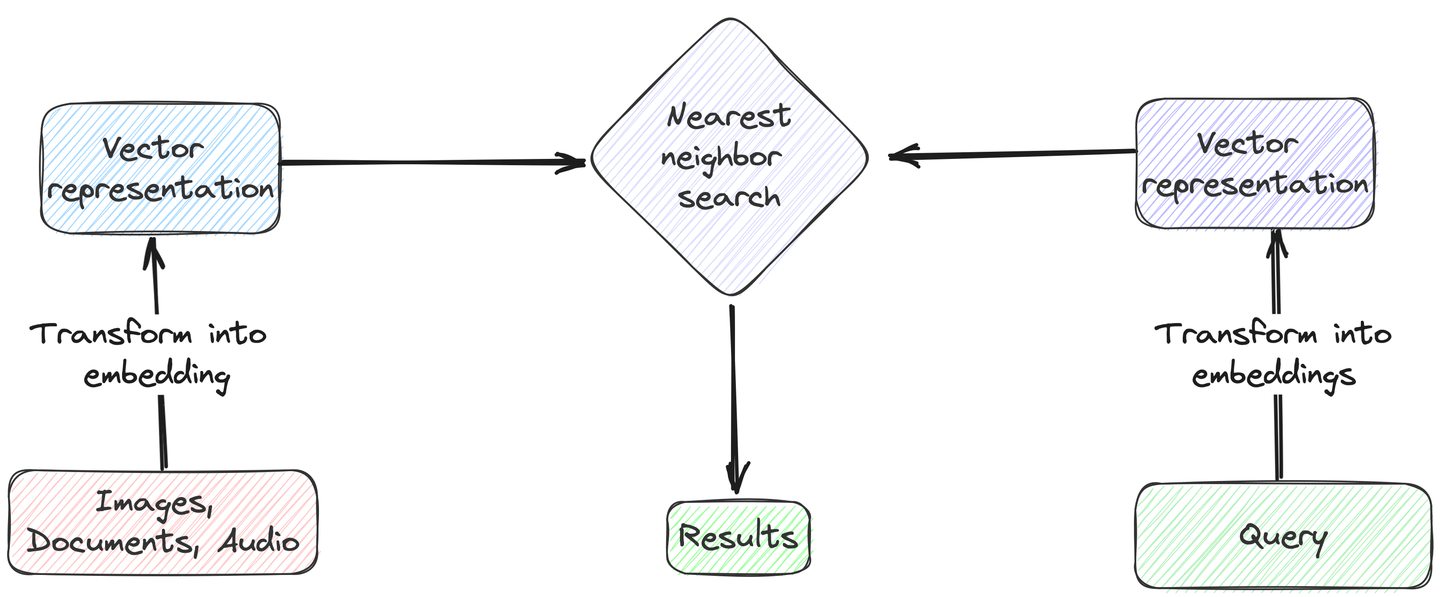
# Escenarios típicos para la búsqueda vectorial
- Búsqueda de similitud: Se utiliza para encontrar otros vectores en el espacio de características que sean similares a un vector dado, ampliamente aplicado en campos como el análisis de imágenes, audio y texto.
- Sistemas de recomendación: Logra recomendaciones personalizadas mediante el análisis de representaciones vectoriales de usuarios y elementos, como recomendaciones de películas, productos o música.
- Procesamiento del lenguaje natural: Busca similitud semántica en datos de texto, admitiendo la búsqueda semántica y el análisis de relevancia.
- Sistema de preguntas y respuestas (QA): Busca pasajes relacionados cuyas representaciones vectoriales sean más similares a la pregunta de entrada. La respuesta final puede generarse con un modelo de lenguaje grande (LLM) basado en la pregunta y los pasajes recuperados.
La búsqueda vectorial por fuerza bruta funciona muy bien para la búsqueda semántica cuando el conjunto de datos es pequeño y las consultas son simples. Sin embargo, su rendimiento disminuye a medida que el conjunto de datos crece o las consultas se vuelven más complejas, lo que resulta en algunas desventajas.
# Desafíos en la implementación de la búsqueda vectorial
Discutamos algunos de los problemas asociados con el uso de una búsqueda vectorial simple, especialmente cuando el tamaño del conjunto de datos aumenta:
- Rendimiento: Como se mencionó anteriormente, la búsqueda vectorial por fuerza bruta calcula la distancia entre un vector de consulta y todos los vectores en la base de datos. Funciona bien para conjuntos de datos más pequeños, pero a medida que el número de vectores aumenta a millones de entradas, el tiempo de búsqueda y el costo computacional para encontrar la distancia entre las millones de entradas también aumenta.
- Escalabilidad: Los datos están creciendo exponencialmente, lo que dificulta mucho que la búsqueda vectorial por fuerza bruta logre resultados con la misma velocidad y precisión al consultar conjuntos de datos masivos. Esto requiere formas innovadoras de gestionar datos voluminosos mientras se mantiene la misma velocidad y precisión.
- Combinación con datos estructurados: En aplicaciones simples, se utiliza una consulta SQL para consultar datos estructurados o una búsqueda vectorial para datos no estructurados, pero a menudo las aplicaciones requieren las capacidades de ambos. Integrar estos dos puede ser técnicamente desafiante, especialmente cuando se procesan en sistemas diferentes. Cuando utilizamos la búsqueda vectorial y aplicamos simultáneamente cláusulas WHERE de SQL para filtrar, el tiempo de procesamiento de la consulta aumenta como resultado de la mayor variedad y tamaño de los datos.
Como solución a estos desafíos, existen técnicas eficientes de indexación vectorial.
# Técnicas comunes de indexación vectorial
Para abordar los desafíos de los datos vectoriales a gran escala, se emplean diversas técnicas de indexación para organizar y facilitar búsquedas vectoriales aproximadas eficientes. Veamos algunas de estas técnicas.
# Hierarchical Navigable Small World (HNSW)
El algoritmo HNSW aprovecha una estructura de grafo multicapa para almacenar y buscar eficientemente vectores. En cada capa, los vectores están conectados no solo a otros vectores en la misma capa, sino también a vectores en las capas inferiores. Esta estructura permite una exploración eficiente de vectores cercanos mientras se mantiene el espacio de búsqueda manejable. Las capas superiores contienen un número pequeño de nodos, mientras que el número de nodos aumenta exponencialmente a medida que descendemos en la jerarquía. La capa inferior finalmente abarca todos los puntos de datos en la base de datos. Este diseño jerárquico define la arquitectura distintiva del algoritmo HNSW.
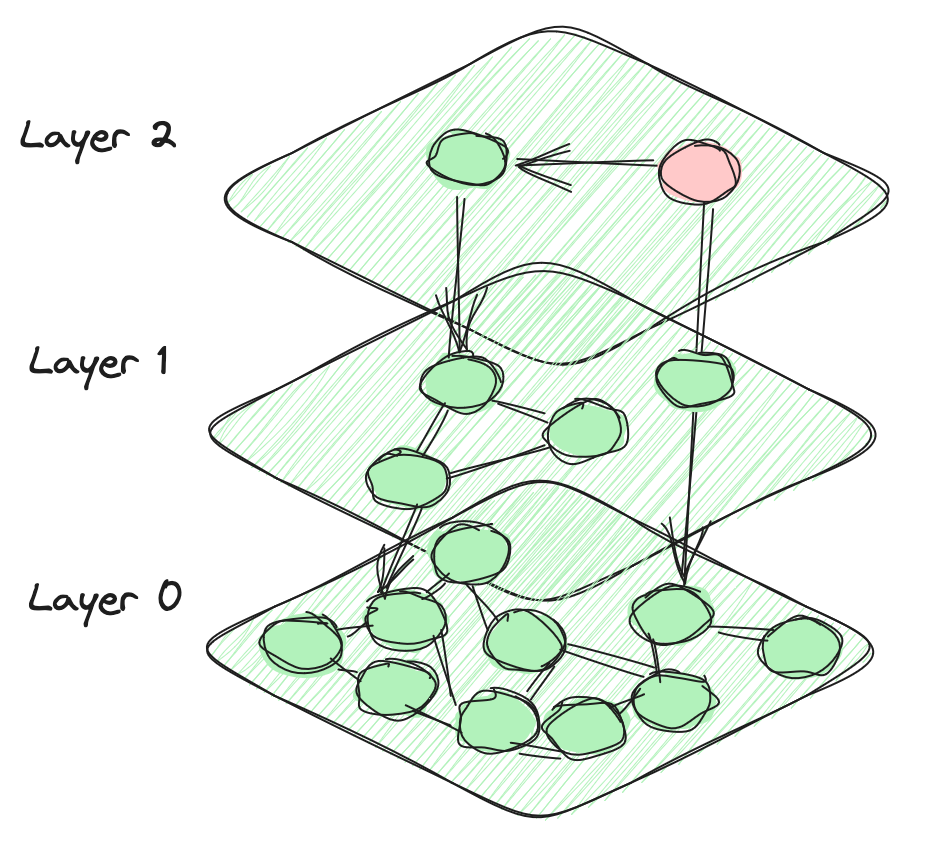
El proceso de búsqueda comienza con un vector seleccionado, a partir del cual se calculan las distancias a los vectores conectados tanto en la capa actual como en las capas anteriores. Este método es voraz, avanzando continuamente hacia el vector más cercano a la posición actual, iterando hasta que se identifica un vector que es el más cercano entre todos sus vectores conectados. Si bien el índice HNSW generalmente sobresale en búsquedas vectoriales sencillas, requiere recursos considerables y lleva mucho tiempo construirlo. Además, la precisión y eficiencia de las búsquedas filtradas pueden disminuir sustancialmente debido a la conectividad gráfica disminuida en estas condiciones.
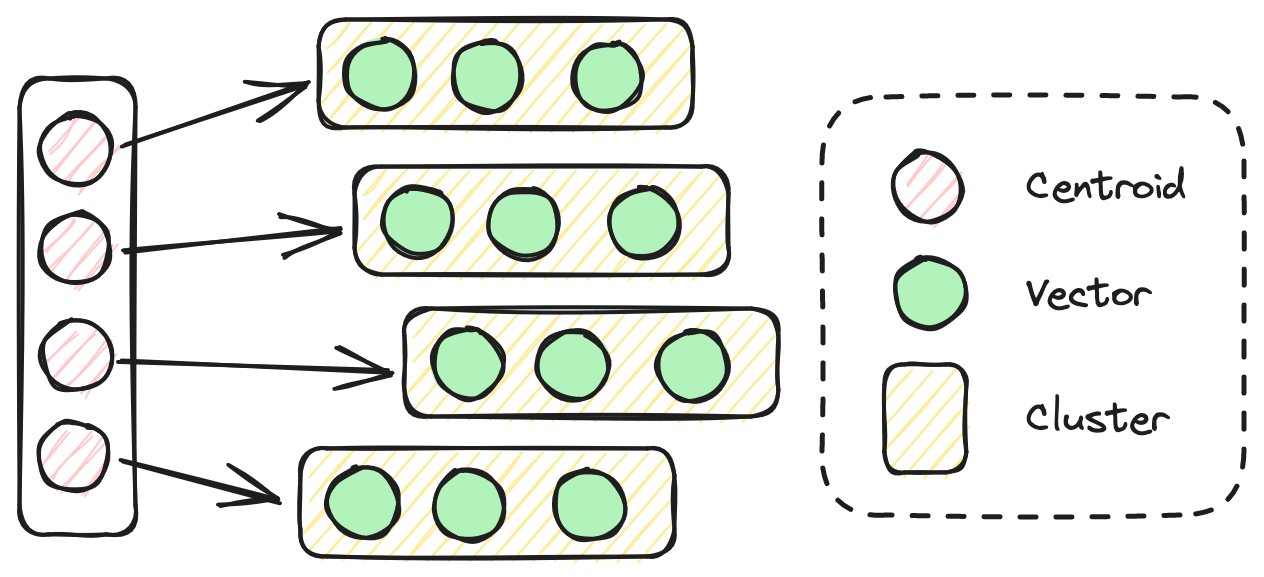
# Índice de archivo vectorial invertido (IVF)
El índice IVF gestiona eficientemente búsquedas de datos de alta dimensionalidad utilizando centroides de clústeres como su índice invertido. Segmenta los vectores en clústeres en función de la proximidad geométrica, siendo el centroide de cada clúster una representación simplificada. Al buscar los elementos más similares a un vector de consulta, el algoritmo primero identifica los centroides más cercanos al vector de consulta. Luego, busca solo dentro de la lista asociada de vectores para esos centroides, en lugar de buscar en todo el conjunto de datos. El índice IVF tarda menos tiempo en construir en comparación con HNSW, pero también logra una menor precisión y velocidad durante el proceso de búsqueda.


# MyScale en acción: soluciones y aplicaciones prácticas
Como base de datos vectorial SQL, MyScale (opens new window) está diseñado para manejar consultas complejas, permitir una recuperación rápida de datos y almacenar grandes cantidades de datos de manera eficiente. Lo que hace que supere a las bases de datos vectoriales especializadas (opens new window) es que combina un motor de ejecución SQL rápido (basado en ClickHouse) con nuestro algoritmo Multi-scale Tree Graph (MSTG) propietario. MSTG combina las ventajas de los algoritmos basados en árboles y en grafos, lo que permite a MyScale construir y buscar de manera rápida, y mantener velocidad y precisión bajo diferentes relaciones de búsqueda filtrada, todo ello manteniendo la eficiencia de recursos y costos.
Ahora echemos un vistazo a varias aplicaciones prácticas donde MyScale puede ser de gran ayuda:
- Aplicaciones de preguntas y respuestas basadas en conocimiento: Al desarrollar un sistema de preguntas y respuestas (QA), MyScale es una base de datos vectorial ideal con la capacidad de autoconsulta y filtrado flexible para obtener resultados altamente relevantes de tus documentos. Además, MyScale destaca en escalabilidad, lo que te permite gestionar múltiples usuarios de manera simultánea fácilmente. Para obtener más información, puedes consultar nuestra documentación sobre QA abstractivo (opens new window). Además, puedes utilizar autoconsultas con algoritmos avanzados para mejorar la precisión y velocidad de tus resultados de búsqueda.
- Chatbot de inteligencia artificial a gran escala: Desarrollar un chatbot a gran escala es una tarea desafiante, especialmente cuando debes gestionar numerosos usuarios de manera simultánea y garantizar que sean tratados de forma separada. Además, el chatbot debe proporcionar respuestas precisas. MyScale ha simplificado la creación de chatbots (opens new window) a través de su control de acceso basado en roles compatible con SQL y su multiarrendamiento a gran escala (opens new window) a través de particionamiento de datos y búsqueda filtrada, lo que te permite gestionar múltiples usuarios.
- Búsqueda de imágenes: Si estás creando un sistema que realiza búsquedas semánticas o similares de imágenes, MyScale puede acomodar fácilmente tus crecientes datos de imágenes manteniendo un rendimiento y eficiencia de recursos. También puedes escribir consultas SQL más complejas y consultas de unión de vectores para emparejar imágenes por metadatos o contenido visual. Para obtener información más detallada, consulta nuestra documentación sobre búsqueda de imágenes (opens new window).
Además de estas aplicaciones prácticas, al incorporar las capacidades SQL y vectoriales de MyScale, puedes desarrollar sistemas de recomendación avanzados (opens new window), aplicaciones de detección de objetos (opens new window) y muchas más.
# Conclusión
La búsqueda vectorial supera la coincidencia tradicional de términos al interpretar la semántica dentro de las incrustaciones vectoriales. Este enfoque no solo es efectivo para el texto, sino que también se extiende a imágenes, audio y diversos datos no estructurados multimodales, como se demuestra en modelos como ImageBind (opens new window). Sin embargo, esta tecnología enfrenta desafíos como las demandas computacionales y de almacenamiento, así como la ambigüedad semántica de los vectores de alta dimensionalidad. MyScale resuelve estos problemas al fusionar de manera innovadora SQL y búsqueda vectorial en un sistema unificado de alto rendimiento y rentabilidad. Esta fusión permite una amplia variedad de aplicaciones, desde sistemas de QA hasta chatbots de IA y búsquedas de imágenes, lo que demuestra su versatilidad y eficiencia.
Por último, te invitamos a conectarte con nosotros en Twitter (opens new window) y Discord (opens new window). Nos encanta escuchar y discutir tus ideas.



