
# Recomendación de películas
![]()
![]()
# Introducción
Un sistema de recomendación es una subclase de sistema de filtrado de información que proporciona sugerencias de elementos que son más pertinentes para un usuario en particular. Para sugerir la opción más adecuada de una variedad de posibilidades, estos sistemas utilizan algoritmos. Se utilizan diversas técnicas y algoritmos como filtrado colaborativo, factorización de matrices y aprendizaje profundo para implementar un sistema de recomendación.
Esta guía demostrará cómo construir un sistema de recomendación básico utilizando MyScale. El proceso consta de varias etapas, que incluyen la construcción de vectores de usuario y elementos basados en el modelo NMF, la inserción de conjuntos de datos en MyScale, la recuperación de los mejores K elementos recomendados para un usuario y el uso de un modelo SVD para predecir las calificaciones de usuario para los elementos sugeridos por MyScale.
Si estás más interesado en explorar las capacidades de MyScale, puedes omitir la sección Construcción de conjuntos de datos y pasar directamente a la sección Población de datos en MyScale.
Puedes importar este conjunto de datos en la consola de MyScale siguiendo las instrucciones proporcionadas en la sección Importar Datos para el conjunto de datos Recomendación de películas. Una vez importado, puedes pasar directamente a la sección Consultando MyScale para disfrutar de esta aplicación de ejemplo.
# Prerrequisitos
Para comenzar, se deben instalar ciertas dependencias, incluido el cliente Python ClickHouse (opens new window), scikit-learn y otras herramientas relevantes.
pip install -U clickhouse-connect scikit-learn
# Construcción de conjuntos de datos
# Descarga y procesamiento de datos
Para este ejemplo, utilizaremos los conjuntos de datos pequeños de MovieLens Latest Datasets (opens new window) para proporcionar recomendaciones de películas. El conjunto de datos consta de 100,000 calificaciones aplicadas a 9,000 películas por 600 usuarios.
wget https://files.grouplens.org/datasets/movielens/ml-latest-small.zip
unzip ml-latest-small.zip
Leamos los datos de las películas en un dataframe de pandas.
import pandas as pd
# obtener metadatos de las películas
original_movie_metadata = pd.read_csv('ml-latest-small/movies.csv')
movie_metadata = original_movie_metadata[['movieId', 'title', 'genres']]
movie_metadata['genres'] = movie_metadata['genres'].str.split('|', expand=False)
# agregar tmdbId al dataframe de metadatos de las películas
original_movie_links = pd.read_csv('ml-latest-small/links.csv')
movie_info = pd.merge(movie_metadata, original_movie_links, on=["movieId"])[['movieId', 'title', 'genres', 'tmdbId']]
# filtrar películas válidas de tmdb
movie_info = movie_info[movie_info['tmdbId'].notnull()]
movie_info['tmdbId'] = movie_info['tmdbId'].astype(int).astype(str)
movie_info.head()
Leamos los datos de las calificaciones.
# obtener información de calificaciones de las películas por usuario
movie_user_rating = pd.read_csv('ml-latest-small/ratings.csv')
# eliminar calificaciones de películas que no tienen tmdbId
movie_user_rating = movie_user_rating[movie_user_rating['movieId'].isin(movie_info['movieId'])]
movie_user_rating = movie_user_rating[["userId", "movieId", "rating"]]
movie_user_rating.head()
Leamos los datos de los usuarios.
# obtener información de calificaciones de las películas por usuario
movie_user_rating = pd.read_csv('ml-latest-small/ratings.csv')
# eliminar calificaciones de películas que no tienen tmdbId
movie_user_rating = movie_user_rating[movie_user_rating['movieId'].isin(movie_info['movieId'])]
movie_user_rating = movie_user_rating[["userId", "movieId", "rating"]]
movie_user_rating.head()
# Generación de vectores de usuario y película
La Factorización de Matrices No Negativas (NMF, por sus siglas en inglés) es una técnica de factorización de matrices que descompone una matriz no negativa R en dos matrices no negativas W y H, donde R ≈ WH. NMF es una técnica comúnmente utilizada en sistemas de recomendación para extraer características latentes de datos dispersos de alta dimensionalidad, como las matrices de interacción entre usuarios e ítems.
En el contexto de un sistema de recomendación, se puede utilizar NMF para factorizar la matriz de interacción entre usuarios e ítems en dos matrices no negativas de baja dimensionalidad: una matriz representa las preferencias de los usuarios por las características latentes, y la otra matriz representa cómo cada ítem está relacionado con estas características latentes. Dada una matriz de interacción entre usuarios e ítems R de tamaño m x n, podemos factorizarla en dos matrices no negativas W y H, de modo que R se aproxime a su producto: R ≈ W * H. La factorización se logra minimizando la distancia entre R y W * H, sujeta a las restricciones no negativas en W y H.
Las matrices W y H corresponden a la matriz de vectores de usuario y la matriz de vectores de ítem, respectivamente, y se pueden utilizar como índices de vectores para consultas posteriores.
Comencemos creando primero una matriz de usuarios-ítems para las calificaciones de las películas, donde cada fila representa a un usuario y cada columna representa una película. Cada celda de la matriz representa la calificación correspondiente del usuario para esa película. Si un usuario no ha calificado una película en particular, el valor de la celda se establecerá en 0.
from sklearn.decomposition import NMF
from sklearn.preprocessing import MaxAbsScaler
from scipy.sparse import csr_matrix
user_indices, user_ids = pd.factorize(movie_user_rating['userId'])
item_indices, movie_ids = pd.factorize(movie_user_rating['movieId'])
rating_sparse_matrix = csr_matrix((movie_user_rating['rating'], (user_indices, item_indices)))
# normalizar la matriz con MaxAbsScaler
max_abs_scaler = MaxAbsScaler()
rating_sparse_matrix = max_abs_scaler.fit_transform(rating_sparse_matrix)
Después de construir nuestra matriz de usuarios-ítems, podemos ajustar el modelo NMF con la matriz.
# crear modelo NMF con la configuración
dimension = 512
nmf_model = NMF(n_components=dimension, init='nndsvd', max_iter=500)
# descomposición de la matriz dispersa de calificaciones con NMF
user_vectors = nmf_model.fit_transform(rating_sparse_matrix)
item_vectors = nmf_model.components_.T
error = nmf_model.reconstruction_err_
print("Reconstruction error: ", error)
Agreguemos los vectores al dataframe correspondiente.
# generar matriz de vectores de usuario, que contiene userIds y vectores de usuario
user_vector_df = pd.DataFrame(zip(user_ids, user_vectors), columns=['userId', 'user_rating_vector']).reset_index(drop=True)
# generar matriz de vectores de película, que contiene movieIds y vectores de película
movie_rating_vector_df = pd.DataFrame(zip(movie_ids, item_vectors), columns=['movieId', 'movie_rating_vector'])
# Creando conjuntos de datos
Ahora tenemos cuatro dataframes: metadatos de películas, calificaciones de películas por usuarios, vectores de usuarios y vectores de películas. Vamos a fusionar los dataframes relevantes en un solo dataframe.
user_rating_df = movie_user_rating.reset_index(drop=True)
# agregar vectores de películas a los metadatos de películas y eliminar las películas sin vector de película
movie_info_df = pd.merge(movie_info, movie_rating_vector_df, on=["movieId"]).reset_index(drop=True)
Persistir los dataframes en archivos Parquet.
import pyarrow as pa
import pyarrow.parquet as pq
# crear objetos de tabla a partir de los datos y el esquema
movie_table = pa.Table.from_pandas(movie_info_df)
user_table = pa.Table.from_pandas(user_vector_df)
rating_table = pa.Table.from_pandas(user_rating_df)
# escribir la tabla en archivos Parquet
pq.write_table(movie_table, 'movie.parquet')
pq.write_table(user_table, 'user.parquet')
pq.write_table(rating_table, 'rating.parquet')
# Población de datos en MyScale
# Carga de datos
Para poblar datos en MyScale, primero cargamos los datos del conjunto de datos de HuggingFace myscale/recommendation-examples (opens new window) creado en la sección anterior. El siguiente fragmento de código muestra cómo cargar los datos y transformarlos en DataFrames de pandas.
from datasets import load_dataset
movie = load_dataset("myscale/recommendation-examples", data_files="movie.parquet", split="train")
user = load_dataset("myscale/recommendation-examples", data_files="user.parquet", split="train")
rating = load_dataset("myscale/recommendation-examples", data_files="rating.parquet", split="train")
# transformar los conjuntos de datos en DataFrame de pandas
movie_info_df = movie.to_pandas()
user_vector_df = user.to_pandas()
user_rating_df = rating.to_pandas()
# convertir los vectores de incrustación de np array a lista
movie_info_df['movie_rating_vector'] = movie_info_df['movie_rating_vector'].apply(lambda x: x.tolist())
user_vector_df['user_rating_vector'] = user_vector_df['user_rating_vector'].apply(lambda x: x.tolist())
# Creación de tablas
A continuación, crearemos tablas en MyScale.
Antes de comenzar, deberá obtener la información de host, nombre de usuario y contraseña de su clúster de MyScale desde la consola de MyScale. El siguiente fragmento de código crea tres tablas, para metadatos de películas, vectores de usuarios y calificaciones de películas por usuarios.
import clickhouse_connect
# inicializar el cliente
client = clickhouse_connect.get_client(
host='YOUR_CLUSTER_HOST',
port=443,
username='YOUR_USERNAME',
password='YOUR_CLUSTER_PASSWORD'
)
Crear tablas.
client.command("DROP TABLE IF EXISTS default.myscale_movies")
client.command("DROP TABLE IF EXISTS default.myscale_users")
client.command("DROP TABLE IF EXISTS default.myscale_ratings")
# crear tabla para películas
client.command(f"""
CREATE TABLE default.myscale_movies
(
movieId Int64,
title String,
genres Array(String),
tmdbId String,
movie_rating_vector Array(Float32),
CONSTRAINT vector_len CHECK length(movie_rating_vector) = 512
)
ORDER BY movieId
""")
# crear tabla para vectores de usuarios
client.command(f"""
CREATE TABLE default.myscale_users
(
userId Int64,
user_rating_vector Array(Float32),
CONSTRAINT vector_len CHECK length(user_rating_vector) = 512
)
ORDER BY userId
""")
# crear tabla para calificaciones de películas por usuarios
client.command("""
CREATE TABLE default.myscale_ratings
(
userId Int64,
movieId Int64,
rating Float64
)
ORDER BY userId
""")
# Cargando datos
Después de crear las tablas, insertamos los datos cargados desde los conjuntos de datos en las tablas.
client.insert("default.myscale_movies", movie_info_df.to_records(index=False).tolist(), column_names=movie_info_df.columns.tolist())
client.insert("default.myscale_users", user_vector_df.to_records(index=False).tolist(), column_names=user_vector_df.columns.tolist())
client.insert("default.myscale_ratings", user_rating_df.to_records(index=False).tolist(), column_names=user_rating_df.columns.tolist())
# verificar la cantidad de datos insertados
print(f"movies count: {client.command('SELECT count(*) FROM default.myscale_movies')}")
print(f"users count: {client.command('SELECT count(*) FROM default.myscale_users')}")
print(f"ratings count: {client.command('SELECT count(*) FROM default.myscale_ratings')}")
# Construyendo el índice
Ahora, nuestros conjuntos de datos están cargados en MyScale. Crearemos un índice vectorial para acelerar la búsqueda de vectores después de insertar los conjuntos de datos.
Utilizamos MSTG como nuestro algoritmo de búsqueda de vectores. Para obtener detalles de configuración, consulte Búsqueda Vectorial.
El producto interno se utiliza como métrica de distancia aquí. Específicamente, el producto interno entre el vector de consulta (que representa las preferencias de un usuario) y los vectores de elementos (que representan las características de las películas) produce los valores de las celdas en la matriz R, que se puede aproximar mediante el producto de las matrices W y H, como se menciona en la sección Generación de vectores de usuario y película.
# crear índice vectorial con producto interno
client.command("""
ALTER TABLE default.myscale_movies
ADD VECTOR INDEX movie_rating_vector_index movie_rating_vector
TYPE MSTG('metric_type=IP')
""")
Verificar el estado del índice.
# verificar el estado del índice vectorial, asegurarse de que el índice vectorial esté listo con el estado 'Built'
get_index_status="SELECT status FROM system.vector_indices WHERE name='movie_rating_vector_index'"
print(f"index build status: {client.command(get_index_status)}")
# Consultando MyScale
# Realizando una consulta para recomendación de películas
Seleccionamos aleatoriamente a un usuario como usuario objetivo para recomendarle películas y obtenemos el histograma de calificaciones del usuario, que muestra la distribución de las calificaciones del usuario.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
random_user = client.query("SELECT * FROM default.myscale_users ORDER BY rand() LIMIT 1")
assert random_user.row_count == 1
target_user_id = random_user.first_item["userId"]
target_user_vector = random_user.first_item["user_rating_vector"]
print("currently selected user id={} for movie recommendation\n".format(target_user_id))
# gráfico de calificaciones del usuario
target_user_ratings = user_rating_df.loc[user_rating_df['userId'] == target_user_id]['rating'].tolist()
bins = np.arange(1.0, 6, 0.5)
# Calcular el histograma
hist, _ = np.histogram(target_user_ratings, bins=bins)
print("Distribution of ratings for user {}:".format(target_user_id))
plt.bar(bins[:-1], hist, width=0.4)
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('User Rating Distribution')
for i in range(len(hist)):
plt.text(bins[i], hist[i], str(hist[i]), ha='center', va='bottom')
plt.show()
Una muestra de la distribución de calificaciones para un usuario
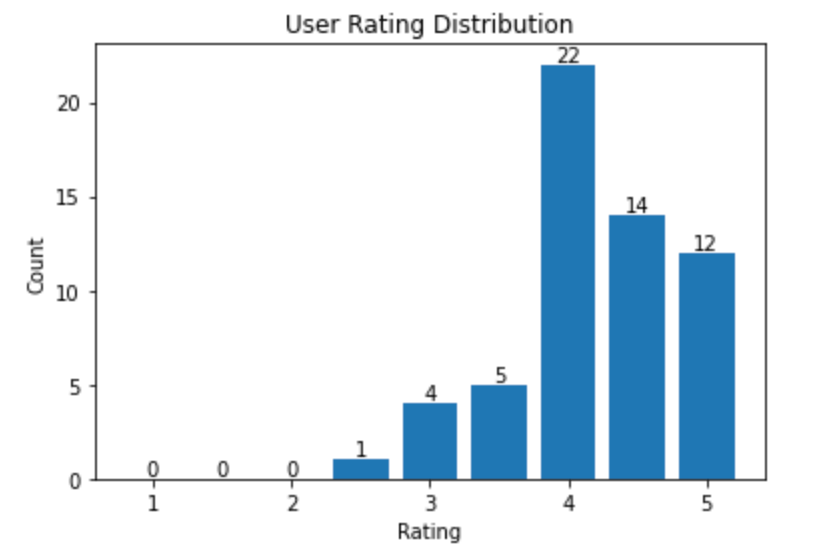
A continuación, recomendemos películas al usuario.
Como se describe en las secciones Generación de vectores de usuario y película y Construyendo el índice, nuestros vectores de usuario y película se extraen del modelo NMF, y los productos internos de los vectores sirven como nuestras métricas de distancia vectorial. La fórmula del producto interno de dos vectores se puede simplificar de la siguiente manera:
Más específicamente, podemos obtener una matriz de calificaciones de usuario aproximada utilizando el producto interno de la matriz de vectores de usuario y la matriz de vectores de película basada en el modelo NMF. El valor de la celda ubicada en (i, j) representa la calificación estimada del usuario i para la película j. Por lo tanto, las distancias entre los vectores de usuario y los vectores de película, representadas por sus productos internos, se pueden utilizar para recomendar películas a los usuarios. Distancias más altas corresponden a calificaciones de películas estimadas más altas.
Sin embargo, dado que normalizamos la matriz de calificaciones en las secciones anteriores, todavía necesitamos escalar las distancias a la nueva escala de calificaciones (0, 5).
top_k = 10
# consultar la base de datos para encontrar las K películas recomendadas principales
recommended_results = client.query(f"""
SELECT movieId, title, genres, tmdbId, distance(movie_rating_vector, {target_user_vector}) AS dist
FROM default.myscale_movies
WHERE movieId not in (
SELECT movieId
from default.myscale_ratings
where userId = {target_user_id}
)
ORDER BY dist DESC
LIMIT {top_k}
""")
recommended_movies = pd.DataFrame.from_records(recommended_results.named_results())
rated_score_scale = client.query(f"""
SELECT max(rating) AS max, min(rating) AS min
FROM default.myscale_ratings
WHERE userId = {target_user_id}
""")
max_rated_score = rated_score_scale.first_row[0]
min_rated_score = rated_score_scale.first_row[1]
print("Top 10 movie recommandations with estimated ratings for user {}".format(target_user_id))
max_dist = recommended_results.first_row[4]
recommended_movies['estimated_rating'] = min_rated_score + ((max_rated_score - min_rated_score) / max_dist) * recommended_movies['dist']
recommended_movies[['movieId', 'title', 'estimated_rating', 'genres']]
Resultado de ejemplo
| movieId | title | estimated_rating | genres |
|---|---|---|---|
| 158966 | Captain Fantastic (2016) | 5.000000 | [Drama] |
| 79702 | Scott Pilgrim vs. the World (2010) | 4.930944 | [Action, Comedy, Fantasy, Musical, Romance] |
| 1 | Toy Story (1995) | 4.199992 | [Adventure, Animation, Children, Comedy, Fantasy] |
| 8874 | Shaun of the Dead (2004) | 4.021980 | [Comedy, Horror] |
| 68157 | Inglourious Basterds (2009) | 3.808410 | [Action, Drama, War] |
| 44191 | V for Vendetta (2006) | 3.678385 | [Action, Sci-Fi, Thriller, IMAX] |
| 6539 | Pirates of the Caribbean: The Curse of the Black Pearl (2003) | 3.654729 | [Action, Adventure, Comedy, Fantasy] |
| 8636 | Spider-Man 2 (2004) | 3.571647 | [Action, Adventure, Sci-Fi, IMAX] |
| 6333 | X2: X-Men United (2003) | 3.458405 | [Action, Adventure, Sci-Fi, Thriller] |
| 8360 | Shrek 2 (2004) | 3.417371 | [Adventure, Animation, Children, Comedy, Musical, Romance] |
# contar las películas calificadas
rated_count = len(user_rating_df[user_rating_df["userId"] == target_user_id])
# consultar la base de datos para encontrar las K películas recomendadas más vistas para el usuario
rated_results = client.query(f"""
SELECT movieId, genres, tmdbId, dist, rating
FROM (SELECT * FROM default.myscale_ratings WHERE userId = {target_user_id}) AS ratings
INNER JOIN (
SELECT movieId, genres, tmdbId, distance(movie_rating_vector, {target_user_vector}) AS dist
FROM default.myscale_movies
WHERE movieId in ( SELECT movieId FROM default.myscale_ratings WHERE userId = {target_user_id} )
ORDER BY dist DESC
LIMIT {rated_count}
) AS movie_info
ON ratings.movieId = movie_info.movieId
WHERE rating >= (
SELECT MIN(rating) FROM (
SELECT least(rating) AS rating FROM default.myscale_ratings WHERE userId = {target_user_id} ORDER BY rating DESC LIMIT {top_k})
)
ORDER BY dist DESC
LIMIT {top_k}
""")
print("Genres of top 10 highest-rated and recommended movies for user {}:".format(target_user_id))
rated_genres = {}
for r in rated_results.named_results():
for tag in r['genres']:
rated_genres[tag] = rated_genres.get(tag, 0) + 1
rated_tags = pd.DataFrame(rated_genres.items(), columns=['category', 'occurrence_in_rated_movie'])
recommended_genres = {}
for r in recommended_results.named_results():
for tag in r['genres']:
recommended_genres[tag] = recommended_genres.get(tag, 0) + 1
recommended_tags = pd.DataFrame(recommended_genres.items(), columns=['category', 'occurrence_in_recommended_movie'])
inner_join_tags = pd.merge(rated_tags, recommended_tags, on='category', how='inner')
inner_join_tags = inner_join_tags.sort_values('occurrence_in_rated_movie', ascending=False)
inner_join_tags
Resultado de ejemplo
| category | occurrence_in_rated_movie | occurrence_in_recommended_movie |
|---|---|---|
| Drama | 8 | 2 |
| Comedy | 5 | 5 |
| Romance | 3 | 2 |
| War | 2 | 1 |
| Adventure | 1 | 5 |
Además, podemos obtener las 10 películas mejor calificadas con sus puntajes reales y puntajes estimados, para observar la similitud entre las calificaciones del usuario y nuestras calificaciones estimadas.
rated_movies = pd.DataFrame.from_records(rated_results.named_results())
print("Top 10 highest-rated movies along with their respective user scores and predicted ratings for the user {}".format(target_user_id))
max_dist = rated_results.first_row[3]
rated_movies['estimated_rating'] = min_rated_score + ((max_rated_score - min_rated_score) / max_dist) * rated_movies['dist']
rated_movies[['movieId', 'rating', 'estimated_rating', 'genres']]
Resultado de ejemplo
| movieId | rating | estimated_rating | genres |
|---|---|---|---|
| 2324 | 5.0 | 4.999934 | [Comedy, Drama, Romance, War] |
| 90430 | 5.0 | 4.925842 | [Comedy, Drama] |
| 128620 | 5.0 | 4.925816 | [Crime, Drama, Romance] |
| 63876 | 5.0 | 4.925714 | [Drama] |
| 6807 | 5.0 | 4.925266 | [Comedy] |
| 3967 | 5.0 | 4.924646 | [Drama] |
| 3448 | 5.0 | 4.923244 | [Comedy, Drama, War] |
| 4027 | 5.0 | 4.922347 | [Adventure, Comedy, Crime] |
| 215 | 5.0 | 4.922092 | [Drama, Romance] |
| 112290 | 5.0 | 4.918183 | [Drama] |