
# 电影推荐
![]()
![]()
# 简介
推荐系统是信息过滤系统的一个子类,为特定用户提供最相关的物品建议。为了从一系列可能性中提供最合适的选项,这些系统使用算法。为了实现推荐系统,使用了各种技术和算法,如协同过滤、矩阵分解和深度学习。
本指南将演示如何使用 MyScale 构建一个基本的推荐系统。该过程包括多个阶段,包括基于 NMF 模型构建用户和物品向量、将数据集插入到 MyScale 中、为用户检索前 K 个推荐物品以及使用 SVD 模型预测用户对 MyScale 推荐物品的评分。
如果您更感兴趣于探索 MyScale 的功能,可以跳过 构建数据集 部分,直接进入 向 MyScale 填充数据 部分。
您可以按照 导入数据 部分中提供的说明,在 MyScale 控制台上导入此数据集。导入后,您可以直接进入 查询 MyScale 部分,享受这个示例应用。
# 先决条件
首先,需要安装一些依赖项,包括 clickhouse python client (opens new window)、scikit-learn 和其他相关工具。
pip install -U clickhouse-connect scikit-learn
# 构建数据集
# 下载和处理数据
在此示例中,我们将使用 MovieLens 最新数据集 (opens new window) 中的小型数据集来提供电影推荐。该数据集包含 600 个用户对 9,000 部电影进行的 100,000 次评分。
wget https://files.grouplens.org/datasets/movielens/ml-latest-small.zip
unzip ml-latest-small.zip
让我们将电影数据读入 pandas dataframe。
import pandas as pd
# 获取电影元数据
original_movie_metadata = pd.read_csv('ml-latest-small/movies.csv')
movie_metadata = original_movie_metadata[['movieId', 'title', 'genres']]
movie_metadata['genres'] = movie_metadata['genres'].str.split('|', expand=False)
# 将 tmdbId 添加到电影元数据 dataframe
original_movie_links = pd.read_csv('ml-latest-small/links.csv')
movie_info = pd.merge(movie_metadata, original_movie_links, on=["movieId"])[['movieId', 'title', 'genres', 'tmdbId']]
# 过滤掉无效的 tmdb 电影
movie_info = movie_info[movie_info['tmdbId'].notnull()]
movie_info['tmdbId'] = movie_info['tmdbId'].astype(int).astype(str)
movie_info.head()
读取评分数据。
# 获取电影用户评分信息
movie_user_rating = pd.read_csv('ml-latest-small/ratings.csv')
# 过滤掉没有 tmdbId 的电影评分
movie_user_rating = movie_user_rating[movie_user_rating['movieId'].isin(movie_info['movieId'])]
movie_user_rating = movie_user_rating[["userId", "movieId", "rating"]]
movie_user_rating.head()
读取用户数据。
# 获取电影用户评分信息
movie_user_rating = pd.read_csv('ml-latest-small/ratings.csv')
# 过滤掉没有 tmdbId 的电影评分
movie_user_rating = movie_user_rating[movie_user_rating['movieId'].isin(movie_info['movieId'])]
movie_user_rating = movie_user_rating[["userId", "movieId", "rating"]]
movie_user_rating.head()
# 生成用户和电影向量
非负矩阵分解(NMF)是一种矩阵分解技术,将一个非负矩阵 R 分解为两个非负矩阵 W 和 H,其中 R ≈ WH。NMF 是推荐系统中常用的技术,用于从高维稀疏数据(如用户-物品交互矩阵)中提取潜在特征。
在推荐系统的上下文中,可以利用 NMF 将用户-物品交互矩阵分解为两个低秩非负矩阵:一个矩阵表示用户对潜在特征的偏好,另一个矩阵表示每个物品与这些潜在特征的关系。给定大小为 m x n 的用户-物品交互矩阵 R,我们可以将其分解为两个非负矩阵 W 和 H,使得 R 的近似等于它们的乘积:R ≈ W * H。通过最小化 R 和 W * H 之间的距离,同时满足 W 和 H 的非负约束,实现了矩阵的分解。
W 和 H 矩阵分别对应用户向量矩阵和物品向量矩阵,并可以用作后续查询的向量索引。
首先,我们从电影评分开始创建一个用户-物品矩阵,其中每一行表示一个用户,每一列表示一个电影。矩阵中的每个单元格表示对应用户对该电影的评分。如果用户没有对某个电影进行评分,则单元格的值将设置为 0。
from sklearn.decomposition import NMF
from sklearn.preprocessing import MaxAbsScaler
from scipy.sparse import csr_matrix
user_indices, user_ids = pd.factorize(movie_user_rating['userId'])
item_indices, movie_ids = pd.factorize(movie_user_rating['movieId'])
rating_sparse_matrix = csr_matrix((movie_user_rating['rating'], (user_indices, item_indices)))
# 使用 MaxAbsScaler 对矩阵进行归一化
max_abs_scaler = MaxAbsScaler()
rating_sparse_matrix = max_abs_scaler.fit_transform(rating_sparse_matrix)
构建用户-物品矩阵后,我们可以使用该矩阵拟合 NMF 模型。
# 使用设置创建 NMF 模型
dimension = 512
nmf_model = NMF(n_components=dimension, init='nndsvd', max_iter=500)
# 使用 NMF 对评分稀疏矩阵进行分解
user_vectors = nmf_model.fit_transform(rating_sparse_matrix)
item_vectors = nmf_model.components_.T
error = nmf_model.reconstruction_err_
print("Reconstruction error: ", error)
将向量添加到相应的 dataframe 中。
# 生成用户向量矩阵,包含 userId 和用户向量
user_vector_df = pd.DataFrame(zip(user_ids, user_vectors), columns=['userId', 'user_rating_vector']).reset_index(drop=True)
# 生成电影向量矩阵,包含 movieId 和电影向量
movie_rating_vector_df = pd.DataFrame(zip(movie_ids, item_vectors), columns=['movieId', 'movie_rating_vector'])
# 创建数据集
我们现在有四个数据帧:电影元数据、用户电影评分、用户向量和电影向量。我们将把相关的数据帧合并成一个单独的数据帧。
user_rating_df = movie_user_rating.reset_index(drop=True)
# 将电影向量添加到电影元数据中,并删除没有电影向量的电影
movie_info_df = pd.merge(movie_info, movie_rating_vector_df, on=["movieId"]).reset_index(drop=True)
将数据帧持久化为 Parquet 文件。
import pyarrow as pa
import pyarrow.parquet as pq
# 从数据和模式创建表对象
movie_table = pa.Table.from_pandas(movie_info_df)
user_table = pa.Table.from_pandas(user_vector_df)
rating_table = pa.Table.from_pandas(user_rating_df)
# 将表写入 Parquet 文件
pq.write_table(movie_table, 'movie.parquet')
pq.write_table(user_table, 'user.parquet')
pq.write_table(rating_table, 'rating.parquet')
# 向 MyScale 填充数据
# 加载数据
要向 MyScale 填充数据,首先,我们从前一节中创建的 HuggingFace 数据集 myscale/recommendation-examples (opens new window) 加载数据。以下代码片段展示了如何加载数据并将其转换为 panda DataFrames。
from datasets import load_dataset
movie = load_dataset("myscale/recommendation-examples", data_files="movie.parquet", split="train")
user = load_dataset("myscale/recommendation-examples", data_files="user.parquet", split="train")
rating = load_dataset("myscale/recommendation-examples", data_files="rating.parquet", split="train")
# 将数据集转换为 panda Dataframe
movie_info_df = movie.to_pandas()
user_vector_df = user.to_pandas()
user_rating_df = rating.to_pandas()
# 将嵌入向量从 np 数组转换为列表
movie_info_df['movie_rating_vector'] = movie_info_df['movie_rating_vector'].apply(lambda x: x.tolist())
user_vector_df['user_rating_vector'] = user_vector_df['user_rating_vector'].apply(lambda x: x.tolist())
# 创建表
接下来,我们将在 MyScale 中创建表。
在开始之前,您需要从 MyScale 控制台获取集群主机、用户名和密码信息。以下代码片段创建了三个表,分别用于存储电影元数据、用户向量和用户电影评分。
import clickhouse_connect
# 初始化客户端
client = clickhouse_connect.get_client(
host='YOUR_CLUSTER_HOST',
port=443,
username='YOUR_USERNAME',
password='YOUR_CLUSTER_PASSWORD'
)
创建表。
client.command("DROP TABLE IF EXISTS default.myscale_movies")
client.command("DROP TABLE IF EXISTS default.myscale_users")
client.command("DROP TABLE IF EXISTS default.myscale_ratings")
# 创建电影表
client.command(f"""
CREATE TABLE default.myscale_movies
(
movieId Int64,
title String,
genres Array(String),
tmdbId String,
movie_rating_vector Array(Float32),
CONSTRAINT vector_len CHECK length(movie_rating_vector) = 512
)
ORDER BY movieId
""")
# 创建用户向量表
client.command(f"""
CREATE TABLE default.myscale_users
(
userId Int64,
user_rating_vector Array(Float32),
CONSTRAINT vector_len CHECK length(user_rating_vector) = 512
)
ORDER BY userId
""")
# 创建用户电影评分表
client.command("""
CREATE TABLE default.myscale_ratings
(
userId Int64,
movieId Int64,
rating Float64
)
ORDER BY userId
""")
# 上传数据
创建表格后,我们将从数据集中加载的数据插入到表格中。
client.insert("default.myscale_movies", movie_info_df.to_records(index=False).tolist(), column_names=movie_info_df.columns.tolist())
client.insert("default.myscale_users", user_vector_df.to_records(index=False).tolist(), column_names=user_vector_df.columns.tolist())
client.insert("default.myscale_ratings", user_rating_df.to_records(index=False).tolist(), column_names=user_rating_df.columns.tolist())
# 检查插入数据的数量
print(f"movies count: {client.command('SELECT count(*) FROM default.myscale_movies')}")
print(f"users count: {client.command('SELECT count(*) FROM default.myscale_users')}")
print(f"ratings count: {client.command('SELECT count(*) FROM default.myscale_ratings')}")
# 构建索引
现在,我们的数据集已经上传到 MyScale。我们将创建一个向量索引,以加速在插入数据后的向量搜索。
我们使用 MSTG 作为我们的向量搜索算法。有关配置详细信息,请参阅向量搜索。
这里使用内积作为距离度量。具体来说,查询向量(表示用户的偏好)和项目向量(表示电影特征)之间的内积产生矩阵 R 中的单元格值,该值可以通过矩阵 W 和 H 的乘积来近似表示,如 生成用户和电影向量 部分所述。
# 使用余弦创建向量索引
client.command("""
ALTER TABLE default.myscale_movies
ADD VECTOR INDEX movie_rating_vector_index movie_rating_vector
TYPE MSTG('metric_type=IP')
""")
检查索引状态。
# 检查向量索引的状态,确保向量索引的状态为 'Built'
get_index_status="SELECT status FROM system.vector_indices WHERE name='movie_rating_vector_index'"
print(f"index build status: {client.command(get_index_status)}")
# 查询 MyScale
# 为电影推荐执行查询
随机选择一个用户作为我们推荐电影的目标用户,并获取用户评分直方图,该直方图展示了用户评分的分布。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
random_user = client.query("SELECT * FROM default.myscale_users ORDER BY rand() LIMIT 1")
assert random_user.row_count == 1
target_user_id = random_user.first_item["userId"]
target_user_vector = random_user.first_item["user_rating_vector"]
print("currently selected user id={} for movie recommendation\n".format(target_user_id))
# 用户评分图
target_user_ratings = user_rating_df.loc[user_rating_df['userId'] == target_user_id]['rating'].tolist()
bins = np.arange(1.0, 6, 0.5)
# 计算直方图
hist, _ = np.histogram(target_user_ratings, bins=bins)
print("Distribution of ratings for user {}:".format(target_user_id))
plt.bar(bins[:-1], hist, width=0.4)
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('User Rating Distribution')
for i in range(len(hist)):
plt.text(bins[i], hist[i], str(hist[i]), ha='center', va='bottom')
plt.show()
用户评分的样本分布
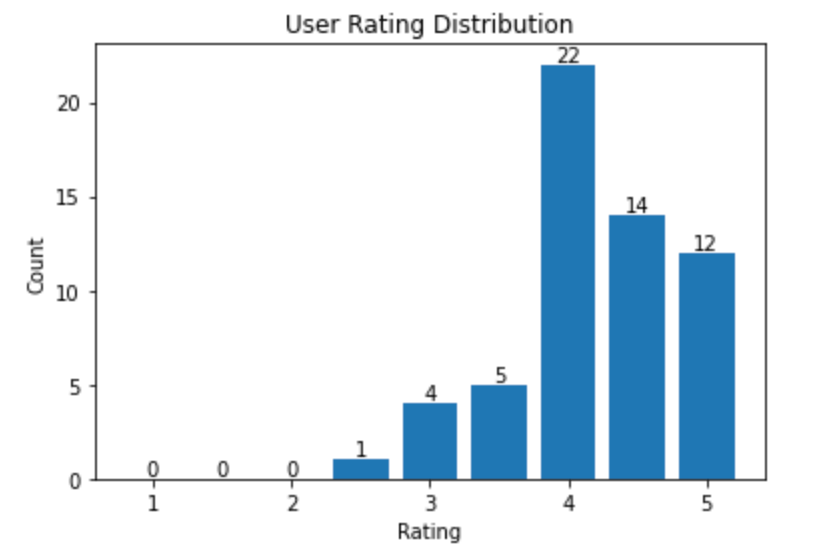
接下来,让我们为用户推荐电影。
如 生成用户和电影向量 和 构建索引 部分所述,我们的用户和电影向量是从 NMF 模型中提取的,并且向量之间的内积用作向量距离度量。两个向量的内积的公式可以简化如下:
更具体地说,我们可以使用用户向量矩阵和电影向量矩阵的内积来获得一个近似的用户评分矩阵。位于 (i, j) 处的单元格的值表示用户 i 对电影 j 的估计评分。因此,用户向量和电影向量之间的距离(由它们的内积表示)可以用于向用户推荐电影。较大的距离对应较高的估计电影评分。
然而,由于我们在之前的部分中对评分矩阵进行了归一化处理,我们仍然需要将距离缩放到新的评分范围 (0, 5)。
top_k = 10
# 查询数据库以找到前K个推荐电影
recommended_results = client.query(f"""
SELECT movieId, title, genres, tmdbId, distance(movie_rating_vector, {target_user_vector}) AS dist
FROM default.myscale_movies
WHERE movieId not in (
SELECT movieId
from default.myscale_ratings
where userId = {target_user_id}
)
ORDER BY dist DESC
LIMIT {top_k}
""")
recommended_movies = pd.DataFrame.from_records(recommended_results.named_results())
rated_score_scale = client.query(f"""
SELECT max(rating) AS max, min(rating) AS min
FROM default.myscale_ratings
WHERE userId = {target_user_id}
""")
max_rated_score = rated_score_scale.first_row[0]
min_rated_score = rated_score_scale.first_row[1]
print("Top 10 movie recommandations with estimated ratings for user {}".format(target_user_id))
max_dist = recommended_results.first_row[4]
recommended_movies['estimated_rating'] = min_rated_score + ((max_rated_score - min_rated_score) / max_dist) * recommended_movies['dist']
recommended_movies[['movieId', 'title', 'estimated_rating', 'genres']]
样例输出
| movieId | title | estimated_rating | genres |
|---|---|---|---|
| 158966 | Captain Fantastic (2016) | 5.000000 | [Drama] |
| 79702 | Scott Pilgrim vs. the World (2010) | 4.930944 | [Action, Comedy, Fantasy, Musical, Romance] |
| 1 | Toy Story (1995) | 4.199992 | [Adventure, Animation, Children, Comedy, Fantasy] |
| 8874 | Shaun of the Dead (2004) | 4.021980 | [Comedy, Horror] |
| 68157 | Inglourious Basterds (2009) | 3.808410 | [Action, Drama, War] |
| 44191 | V for Vendetta (2006) | 3.678385 | [Action, Sci-Fi, Thriller, IMAX] |
| 6539 | Pirates of the Caribbean: The Curse of the Black Pearl (2003) | 3.654729 | [Action, Adventure, Comedy, Fantasy] |
| 8636 | Spider-Man 2 (2004) | 3.571647 | [Action, Adventure, Sci-Fi, IMAX] |
| 6333 | X2: X-Men United (2003) | 3.458405 | [Action, Adventure, Sci-Fi, Thriller] |
| 8360 | Shrek 2 (2004) | 3.417371 | [Adventure, Animation, Children, Comedy, Musical, Romance] |
# 统计已评分电影数量
rated_count = len(user_rating_df[user_rating_df["userId"] == target_user_id])
# 查询数据库以找到用户评分最高的K个已观看电影的推荐电影
rated_results = client.query(f"""
SELECT movieId, genres, tmdbId, dist, rating
FROM (SELECT * FROM default.myscale_ratings WHERE userId = {target_user_id}) AS ratings
INNER JOIN (
SELECT movieId, genres, tmdbId, distance(movie_rating_vector, {target_user_vector}) AS dist
FROM default.myscale_movies
WHERE movieId in ( SELECT movieId FROM default.myscale_ratings WHERE userId = {target_user_id} )
ORDER BY dist DESC
LIMIT {rated_count}
) AS movie_info
ON ratings.movieId = movie_info.movieId
WHERE rating >= (
SELECT MIN(rating) FROM (
SELECT least(rating) AS rating FROM default.myscale_ratings WHERE userId = {target_user_id} ORDER BY rating DESC LIMIT {top_k})
)
ORDER BY dist DESC
LIMIT {top_k}
""")
print("Genres of top 10 highest-rated and recommended movies for user {}:".format(target_user_id))
rated_genres = {}
for r in rated_results.named_results():
for tag in r['genres']:
rated_genres[tag] = rated_genres.get(tag, 0) + 1
rated_tags = pd.DataFrame(rated_genres.items(), columns=['category', 'occurrence_in_rated_movie'])
recommended_genres = {}
for r in recommended_results.named_results():
for tag in r['genres']:
recommended_genres[tag] = recommended_genres.get(tag, 0) + 1
recommended_tags = pd.DataFrame(recommended_genres.items(), columns=['category', 'occurrence_in_recommended_movie'])
inner_join_tags = pd.merge(rated_tags, recommended_tags, on='category', how='inner')
inner_join_tags = inner_join_tags.sort_values('occurrence_in_rated_movie', ascending=False)
inner_join_tags
样例输出
| category | occurrence_in_rated_movie | occurrence_in_recommended_movie |
|---|---|---|
| Drama | 8 | 2 |
| Comedy | 5 | 5 |
| Romance | 3 | 2 |
| War | 2 | 1 |
| Adventure | 1 | 5 |
此外,我们还可以检索用户实际评分和预测评分的前10部电影,以观察用户评分和我们的预估评分之间的相似性。
rated_movies = pd.DataFrame.from_records(rated_results.named_results())
print("Top 10 highest-rated movies along with their respective user scores and predicted ratings for the user {}".format(target_user_id))
max_dist = rated_results.first_row[3]
rated_movies['estimated_rating'] = min_rated_score + ((max_rated_score - min_rated_score) / max_dist) * rated_movies['dist']
rated_movies[['movieId', 'rating', 'estimated_rating', 'genres']]
样例输出
| movieId | rating | estimated_rating | genres |
|---|---|---|---|
| 2324 | 5.0 | 4.999934 | [Comedy, Drama, Romance, War] |
| 90430 | 5.0 | 4.925842 | [Comedy, Drama] |
| 128620 | 5.0 | 4.925816 | [Crime, Drama, Romance] |
| 63876 | 5.0 | 4.925714 | [Drama] |
| 6807 | 5.0 | 4.925266 | [Comedy] |
| 3967 | 5.0 | 4.924646 | [Drama] |
| 3448 | 5.0 | 4.923244 | [Comedy, Drama, War] |
| 4027 | 5.0 | 4.922347 | [Adventure, Comedy, Crime] |
| 215 | 5.0 | 4.922092 | [Drama, Romance] |
| 112290 | 5.0 | 4.918183 | [Drama] |
 京公网安备 11010802042981号
京公网安备 11010802042981号