
# 映画のおすすめ
![]()
![]()
# はじめに
レコメンデーションシステムは、特定のユーザーに最も関連性の高いアイテムの提案を行う情報フィルタリングシステムの一種です。これらのシステムは、さまざまなアルゴリズムを使用して、範囲の広い可能性から最適なオプションを提案します。協調フィルタリング、行列分解、ディープラーニングなどのさまざまな技術とアルゴリズムが、レコメンデーションシステムの実装に使用されます。
このガイドでは、MyScaleを使用して基本的なレコメンデーションシステムを構築する方法を説明します。このプロセスには、NMFモデルに基づいたユーザーおよびアイテムベクトルの構築、データセットのMyScaleへの挿入、ユーザーに対する上位K件の推奨アイテムの取得、およびMyScaleの提案されたアイテムのユーザー評価の予測にSVDモデルを使用するなど、いくつかのステージが含まれます。
もしMyScaleの機能を探索することに興味がある場合は、データセットの構築セクションをスキップし、MyScaleへのデータの投入セクションに直接進むことができます。
このデータセットは、Movie Recommendationデータセットのデータのインポートセクションで提供される手順に従って、MyScaleコンソールにインポートすることができます。インポートが完了したら、MyScaleへのクエリセクションに直接進んで、このサンプルアプリケーションをお楽しみください。
# 前提条件
まず、clickhouse python client (opens new window)、scikit-learn、およびその他の関連ツールなど、いくつかの依存関係をインストールする必要があります。
pip install -U clickhouse-connect scikit-learn
# データセットの構築
# データのダウンロードと処理
この例では、MovieLens Latest Datasets (opens new window)の小規模なデータセットを使用して、映画の推奨を提供します。このデータセットには、600人のユーザーが9,000本の映画に対して適用した100,000件の評価が含まれています。
wget https://files.grouplens.org/datasets/movielens/ml-latest-small.zip
unzip ml-latest-small.zip
映画データをpandasのデータフレームに読み込みます。
import pandas as pd
# 映画のメタデータを取得
original_movie_metadata = pd.read_csv('ml-latest-small/movies.csv')
movie_metadata = original_movie_metadata[['movieId', 'title', 'genres']]
movie_metadata['genres'] = movie_metadata['genres'].str.split('|', expand=False)
# 映画のメタデータにtmdbIdを追加
original_movie_links = pd.read_csv('ml-latest-small/links.csv')
movie_info = pd.merge(movie_metadata, original_movie_links, on=["movieId"])[['movieId', 'title', 'genres', 'tmdbId']]
# tmdbの有効な映画をフィルタリング
movie_info = movie_info[movie_info['tmdbId'].notnull()]
movie_info['tmdbId'] = movie_info['tmdbId'].astype(int).astype(str)
movie_info.head()
評価データを読み込みます。
# ユーザーの映画の評価情報を取得
movie_user_rating = pd.read_csv('ml-latest-small/ratings.csv')
# tmdbIdを持たない映画の評価を削除
movie_user_rating = movie_user_rating[movie_user_rating['movieId'].isin(movie_info['movieId'])]
movie_user_rating = movie_user_rating[["userId", "movieId", "rating"]]
movie_user_rating.head()
ユーザーデータを読み込みます。
# ユーザーの映画の評価情報を取得
movie_user_rating = pd.read_csv('ml-latest-small/ratings.csv')
# tmdbIdを持たない映画の評価を削除
movie_user_rating = movie_user_rating[movie_user_rating['movieId'].isin(movie_info['movieId'])]
movie_user_rating = movie_user_rating[["userId", "movieId", "rating"]]
movie_user_rating.head()
# ユーザーと映画のベクトルの生成
非負値行列因子分解(NMF)は、非負値行列Rを2つの非負値行列WとHに分解する行列因子分解の一種です。ここで、R ≈ WHです。NMFは、ユーザー-アイテムの相互作用行列などの高次元疎データから潜在的な特徴を抽出するためのレコメンデーションシステムでよく使用される技術です。
レコメンデーションシステムの文脈では、NMFはユーザー-アイテムの相互作用行列を2つの低ランク非負値行列に因子分解するために使用できます。1つの行列は、潜在的な特徴に対するユーザーの好みを表し、もう1つの行列は各アイテムがこれらの潜在的な特徴と関連している方法を表します。サイズがm x nのユーザー-アイテムの相互作用行列Rが与えられた場合、R ≈ W * Hとなるように、WとHの2つの非負値行列に分解することができます。この因子分解は、RとW * Hの間の距離を最小化することで達成されます。ただし、WとHに非負の制約があります。
WとH行列は、それぞれユーザーベクトル行列とアイテムベクトル行列に対応し、後でクエリのベクトルインデックスとして使用することができます。
まず、映画の評価に対してユーザー-アイテム行列を作成します。ここで、各行はユーザーを表し、各列は映画を表します。行列の各セルは、その映画の対応するユーザーの評価を表します。ユーザーが特定の映画に評価を付けていない場合、セルの値は0に設定されます。
from sklearn.decomposition import NMF
from sklearn.preprocessing import MaxAbsScaler
from scipy.sparse import csr_matrix
user_indices, user_ids = pd.factorize(movie_user_rating['userId'])
item_indices, movie_ids = pd.factorize(movie_user_rating['movieId'])
rating_sparse_matrix = csr_matrix((movie_user_rating['rating'], (user_indices, item_indices)))
# MaxAbsScalerで行列を正規化
max_abs_scaler = MaxAbsScaler()
rating_sparse_matrix = max_abs_scaler.fit_transform(rating_sparse_matrix)
ユーザー-アイテム行列を作成した後、その行列でNMFモデルをフィットさせることができます。
# NMFモデルを設定して作成
dimension = 512
nmf_model = NMF(n_components=dimension, init='nndsvd', max_iter=500)
# NMFで行列を分解
user_vectors = nmf_model.fit_transform(rating_sparse_matrix)
item_vectors = nmf_model.components_.T
error = nmf_model.reconstruction_err_
print("再構築エラー: ", error)
ベクトルを対応するデータフレームに追加します。
# ユーザーベクトル行列を生成し、userIdとユーザーベクトルを含むデータフレームを作成
user_vector_df = pd.DataFrame(zip(user_ids, user_vectors), columns=['userId', 'user_rating_vector']).reset_index(drop=True)
# 映画ベクトル行列を生成し、movieIdと映画ベクトルを含むデータフレームを作成
movie_rating_vector_df = pd.DataFrame(zip(movie_ids, item_vectors), columns=['movieId', 'movie_rating_vector'])
# データセットの作成
現在、4つのデータフレームがあります:映画のメタデータ、ユーザーの映画の評価、ユーザーベクトル、映画ベクトル。関連するデータフレームを1つのデータフレームにマージします。
user_rating_df = movie_user_rating.reset_index(drop=True)
# 映画ベクトルを映画メタデータに追加し、映画ベクトルのない映画を削除します
movie_info_df = pd.merge(movie_info, movie_rating_vector_df, on=["movieId"]).reset_index(drop=True)
データフレームをParquetファイルに永続化します。
import pyarrow as pa
import pyarrow.parquet as pq
# データとスキーマからテーブルオブジェクトを作成します
movie_table = pa.Table.from_pandas(movie_info_df)
user_table = pa.Table.from_pandas(user_vector_df)
rating_table = pa.Table.from_pandas(user_rating_df)
# テーブルをParquetファイルに書き込みます
pq.write_table(movie_table, 'movie.parquet')
pq.write_table(user_table, 'user.parquet')
pq.write_table(rating_table, 'rating.parquet')
# MyScaleへのデータの投入
# データの読み込み
MyScaleにデータを投入するためには、まず、前のセクションで作成したHuggingFace Dataset myscale/recommendation-examples (opens new window)からデータを読み込みます。以下のコードスニペットは、データを読み込んでそれらをpandasのDataFrameに変換する方法を示しています。
from datasets import load_dataset
movie = load_dataset("myscale/recommendation-examples", data_files="movie.parquet", split="train")
user = load_dataset("myscale/recommendation-examples", data_files="user.parquet", split="train")
rating = load_dataset("myscale/recommendation-examples", data_files="rating.parquet", split="train")
# データセットをpandasのDataFrameに変換します
movie_info_df = movie.to_pandas()
user_vector_df = user.to_pandas()
user_rating_df = rating.to_pandas()
# 埋め込みベクトルをnp配列からリストに変換します
movie_info_df['movie_rating_vector'] = movie_info_df['movie_rating_vector'].apply(lambda x: x.tolist())
user_vector_df['user_rating_vector'] = user_vector_df['user_rating_vector'].apply(lambda x: x.tolist())
# テーブルの作成
次に、MyScaleでテーブルを作成します。
始める前に、MyScaleコンソールからクラスターホスト、ユーザー名、パスワードの情報を取得する必要があります。以下のコードスニペットは、映画のメタデータ、ユーザーベクトル、ユーザーの映画の評価の3つのテーブルを作成します。
import clickhouse_connect
# クライアントを初期化します
client = clickhouse_connect.get_client(
host='YOUR_CLUSTER_HOST',
port=443,
username='YOUR_USERNAME',
password='YOUR_CLUSTER_PASSWORD'
)
テーブルを作成します。
client.command("DROP TABLE IF EXISTS default.myscale_movies")
client.command("DROP TABLE IF EXISTS default.myscale_users")
client.command("DROP TABLE IF EXISTS default.myscale_ratings")
# 映画のテーブルを作成します
client.command(f"""
CREATE TABLE default.myscale_movies
(
movieId Int64,
title String,
genres Array(String),
tmdbId String,
movie_rating_vector Array(Float32),
CONSTRAINT vector_len CHECK length(movie_rating_vector) = 512
)
ORDER BY movieId
""")
# ユーザーベクトルのテーブルを作成します
client.command(f"""
CREATE TABLE default.myscale_users
(
userId Int64,
user_rating_vector Array(Float32),
CONSTRAINT vector_len CHECK length(user_rating_vector) = 512
)
ORDER BY userId
""")
# ユーザーの映画の評価のテーブルを作成します
client.command("""
CREATE TABLE default.myscale_ratings
(
userId Int64,
movieId Int64,
rating Float64
)
ORDER BY userId
""")
# データのアップロード
テーブルを作成した後、データセットから読み込んだデータをテーブルに挿入します。
client.insert("default.myscale_movies", movie_info_df.to_records(index=False).tolist(), column_names=movie_info_df.columns.tolist())
client.insert("default.myscale_users", user_vector_df.to_records(index=False).tolist(), column_names=user_vector_df.columns.tolist())
client.insert("default.myscale_ratings", user_rating_df.to_records(index=False).tolist(), column_names=user_rating_df.columns.tolist())
# 挿入されたデータの数を確認する
print(f"movies count: {client.command('SELECT count(*) FROM default.myscale_movies')}")
print(f"users count: {client.command('SELECT count(*) FROM default.myscale_users')}")
print(f"ratings count: {client.command('SELECT count(*) FROM default.myscale_ratings')}")
# インデックスの作成
データセットがMyScaleにアップロードされました。データセットの挿入後、ベクトル検索を高速化するためにベクトルインデックスを作成します。
ベクトル検索アルゴリズムとしてMSTGを使用しました。詳細な設定については、ベクトル検索を参照してください。
ここでは内積を距離尺度として使用しています。具体的には、クエリベクトル(ユーザーの好みを表す)とアイテムベクトル(映画の特徴を表す)の内積は、行列Rのセルの値を生成し、セクションユーザーと映画のベクトルの生成で説明されているように、行列WとHの積で近似することができます。
# コサインを使用してベクトルインデックスを作成する
client.command("""
ALTER TABLE default.myscale_movies
ADD VECTOR INDEX movie_rating_vector_index movie_rating_vector
TYPE MSTG('metric_type=IP')
""")
インデックスのステータスを確認します。
# ベクトルインデックスのステータスを確認し、ベクトルインデックスが 'Built' ステータスであることを確認する
get_index_status="SELECT status FROM system.vector_indices WHERE name='movie_rating_vector_index'"
print(f"index build status: {client.command(get_index_status)}")
# MyScaleへのクエリ
# 映画の推薦のためのクエリの実行
映画の推薦の対象ユーザーとしてランダムにユーザーを選択し、ユーザーの評価ヒストグラムを取得します。評価ヒストグラムは、ユーザーの評価の分布を示します。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
random_user = client.query("SELECT * FROM default.myscale_users ORDER BY rand() LIMIT 1")
assert random_user.row_count == 1
target_user_id = random_user.first_item["userId"]
target_user_vector = random_user.first_item["user_rating_vector"]
print("currently selected user id={} for movie recommendation\n".format(target_user_id))
# ユーザーの評価プロット
target_user_ratings = user_rating_df.loc[user_rating_df['userId'] == target_user_id]['rating'].tolist()
bins = np.arange(1.0, 6, 0.5)
# ヒストグラムを計算する
hist, _ = np.histogram(target_user_ratings, bins=bins)
print("Distribution of ratings for user {}:".format(target_user_id))
plt.bar(bins[:-1], hist, width=0.4)
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('User Rating Distribution')
for i in range(len(hist)):
plt.text(bins[i], hist[i], str(hist[i]), ha='center', va='bottom')
plt.show()
ユーザーの評価のサンプル分布
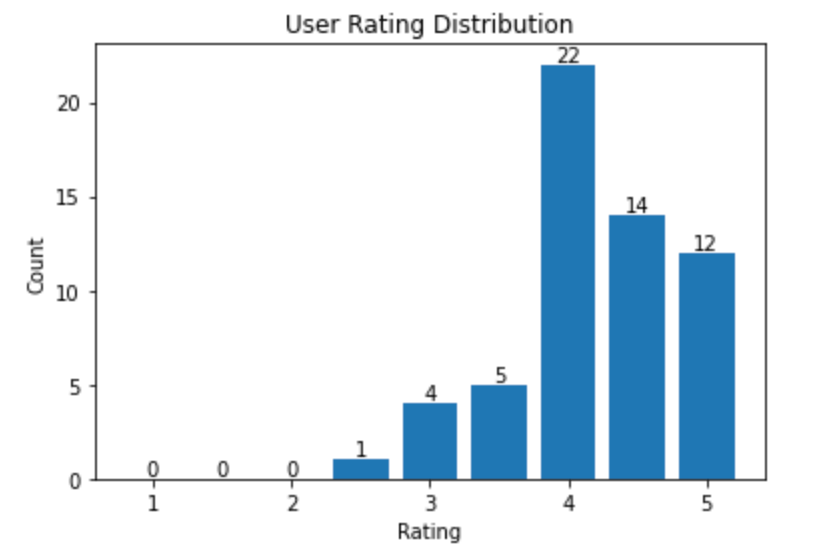
次に、ユーザーに映画を推薦します。
ユーザーと映画のベクトルの生成およびインデックスの作成のセクションで説明したように、ユーザーベクトルと映画ベクトルはNMFモデルから抽出され、ベクトルの内積がベクトルの距離尺度として使用されます。2つのベクトルの内積の式は次のように簡略化できます。
具体的には、NMFモデルに基づいてユーザーベクトル行列と映画ベクトル行列の内積を使用して、近似されたユーザー評価行列を取得できます。セルの値は、ユーザーiが映画jに対して推定される評価を表します。したがって、ユーザーベクトルと映画ベクトルの距離(内積によって表される)は、ユーザーに映画を推薦するために使用できます。距離が大きいほど、推定される映画の評価が高くなります。
ただし、前のセクションで評価行列を正規化したため、距離を新しい評価尺度(0, 5)にスケーリングする必要があります。
top_k = 10
# データベースにクエリを送信して上位K件のおすすめ映画を検索する
recommended_results = client.query(f"""
SELECT movieId, title, genres, tmdbId, distance(movie_rating_vector, {target_user_vector}) AS dist
FROM default.myscale_movies
WHERE movieId not in (
SELECT movieId
from default.myscale_ratings
where userId = {target_user_id}
)
ORDER BY dist DESC
LIMIT {top_k}
""")
recommended_movies = pd.DataFrame.from_records(recommended_results.named_results())
rated_score_scale = client.query(f"""
SELECT max(rating) AS max, min(rating) AS min
FROM default.myscale_ratings
WHERE userId = {target_user_id}
""")
max_rated_score = rated_score_scale.first_row[0]
min_rated_score = rated_score_scale.first_row[1]
print("Top 10 movie recommandations with estimated ratings for user {}".format(target_user_id))
max_dist = recommended_results.first_row[4]
recommended_movies['estimated_rating'] = min_rated_score + ((max_rated_score - min_rated_score) / max_dist) * recommended_movies['dist']
recommended_movies[['movieId', 'title', 'estimated_rating', 'genres']]
サンプル出力
| movieId | title | estimated_rating | genres |
|---|---|---|---|
| 158966 | Captain Fantastic (2016) | 5.000000 | [Drama] |
| 79702 | Scott Pilgrim vs. the World (2010) | 4.930944 | [Action, Comedy, Fantasy, Musical, Romance] |
| 1 | Toy Story (1995) | 4.199992 | [Adventure, Animation, Children, Comedy, Fantasy] |
| 8874 | Shaun of the Dead (2004) | 4.021980 | [Comedy, Horror] |
| 68157 | Inglourious Basterds (2009) | 3.808410 | [Action, Drama, War] |
| 44191 | V for Vendetta (2006) | 3.678385 | [Action, Sci-Fi, Thriller, IMAX] |
| 6539 | Pirates of the Caribbean: The Curse of the Black Pearl (2003) | 3.654729 | [Action, Adventure, Comedy, Fantasy] |
| 8636 | Spider-Man 2 (2004) | 3.571647 | [Action, Adventure, Sci-Fi, IMAX] |
| 6333 | X2: X-Men United (2003) | 3.458405 | [Action, Adventure, Sci-Fi, Thriller] |
| 8360 | Shrek 2 (2004) | 3.417371 | [Adventure, Animation, Children, Comedy, Musical, Romance] |
# 評価された映画の数をカウントする
rated_count = len(user_rating_df[user_rating_df["userId"] == target_user_id])
# データベースにクエリを送信してユーザーの上位K件の視聴済みおすすめ映画を検索する
rated_results = client.query(f"""
SELECT movieId, genres, tmdbId, dist, rating
FROM (SELECT * FROM default.myscale_ratings WHERE userId = {target_user_id}) AS ratings
INNER JOIN (
SELECT movieId, genres, tmdbId, distance(movie_rating_vector, {target_user_vector}) AS dist
FROM default.myscale_movies
WHERE movieId in ( SELECT movieId FROM default.myscale_ratings WHERE userId = {target_user_id} )
ORDER BY dist DESC
LIMIT {rated_count}
) AS movie_info
ON ratings.movieId = movie_info.movieId
WHERE rating >= (
SELECT MIN(rating) FROM (
SELECT least(rating) AS rating FROM default.myscale_ratings WHERE userId = {target_user_id} ORDER BY rating DESC LIMIT {top_k})
)
ORDER BY dist DESC
LIMIT {top_k}
""")
print("Genres of top 10 highest-rated and recommended movies for user {}:".format(target_user_id))
rated_genres = {}
for r in rated_results.named_results():
for tag in r['genres']:
rated_genres[tag] = rated_genres.get(tag, 0) + 1
rated_tags = pd.DataFrame(rated_genres.items(), columns=['category', 'occurrence_in_rated_movie'])
recommended_genres = {}
for r in recommended_results.named_results():
for tag in r['genres']:
recommended_genres[tag] = recommended_genres.get(tag, 0) + 1
recommended_tags = pd.DataFrame(recommended_genres.items(), columns=['category', 'occurrence_in_recommended_movie'])
inner_join_tags = pd.merge(rated_tags, recommended_tags, on='category', how='inner')
inner_join_tags = inner_join_tags.sort_values('occurrence_in_rated_movie', ascending=False)
inner_join_tags
サンプル出力
| category | occurrence_in_rated_movie | occurrence_in_recommended_movie |
|---|---|---|
| Drama | 8 | 2 |
| Comedy | 5 | 5 |
| Romance | 3 | 2 |
| War | 2 | 1 |
| Adventure | 1 | 5 |
さらに、実際の評価スコアと予測スコアを持つ上位10件の評価された映画を取得し、ユーザーの評価と予測評価の類似性を観察することもできます。
rated_movies = pd.DataFrame.from_records(rated_results.named_results())
print("Top 10 highest-rated movies along with their respective user scores and predicted ratings for the user {}".format(target_user_id))
max_dist = rated_results.first_row[3]
rated_movies['estimated_rating'] = min_rated_score + ((max_rated_score - min_rated_score) / max_dist) * rated_movies['dist']
rated_movies[['movieId', 'rating', 'estimated_rating', 'genres']]
サンプル出力
| movieId | rating | estimated_rating | genres |
|---|---|---|---|
| 2324 | 5.0 | 4.999934 | [Comedy, Drama, Romance, War] |
| 90430 | 5.0 | 4.925842 | [Comedy, Drama] |
| 128620 | 5.0 | 4.925816 | [Crime, Drama, Romance] |
| 63876 | 5.0 | 4.925714 | [Drama] |
| 6807 | 5.0 | 4.925266 | [Comedy] |
| 3967 | 5.0 | 4.924646 | [Drama] |
| 3448 | 5.0 | 4.923244 | [Comedy, Drama, War] |
| 4027 | 5.0 | 4.922347 | [Adventure, Comedy, Crime] |
| 215 | 5.0 | 4.922092 | [Drama, Romance] |
| 112290 | 5.0 | 4.918183 | [Drama] |