
# Filmpfehlung
![]()
![]()
# Einführung
Ein Empfehlungssystem ist eine Unterklasse eines Informationssystems, das Vorschläge für Artikel liefert, die für einen bestimmten Benutzer am relevantesten sind. Um die geeignetste Option aus einer Reihe von Möglichkeiten vorzuschlagen, verwenden diese Systeme Algorithmen. Verschiedene Techniken und Algorithmen wie kollaboratives Filtern, Matrixfaktorisierung und Deep Learning werden verwendet, um ein Empfehlungssystem zu implementieren.
Dieser Leitfaden zeigt, wie man ein grundlegendes Empfehlungssystem mit MyScale erstellt. Der Prozess umfasst mehrere Schritte, darunter den Aufbau von Benutzer- und Artikelvektoren basierend auf dem NMF-Modell, das Einfügen von Datensätzen in MyScale, das Abrufen der Top-K empfohlenen Artikel für einen Benutzer und die Verwendung eines SVD-Modells zur Vorhersage von Benutzerbewertungen für die vorgeschlagenen Artikel von MyScale.
Wenn Sie mehr daran interessiert sind, die Möglichkeiten von MyScale zu erkunden, können Sie den Abschnitt Erstellen von Datensätzen überspringen und direkt zum Abschnitt Daten in MyScale einfügen wechseln.
Sie können diesen Datensatz in der MyScale-Konsole importieren, indem Sie den Anweisungen im Abschnitt Datenimport für den Datensatz Movie Recommendation folgen. Sobald der Datensatz importiert ist, können Sie direkt zum Abschnitt Abfragen von MyScale wechseln, um diese Beispielanwendung zu nutzen.
# Voraussetzungen
Zunächst müssen bestimmte Abhängigkeiten installiert werden, einschließlich des ClickHouse Python-Clients (opens new window), scikit-learn und anderer relevanter Tools.
pip install -U clickhouse-connect scikit-learn
# Erstellen von Datensätzen
# Herunterladen und Verarbeiten von Daten
Für dieses Beispiel verwenden wir die kleinen Datensätze von MovieLens Latest Datasets (opens new window), um Filmpfehlungen zu geben. Der Datensatz umfasst 100.000 Bewertungen für 9.000 Filme von 600 Benutzern.
wget https://files.grouplens.org/datasets/movielens/ml-latest-small.zip
unzip ml-latest-small.zip
Lassen Sie uns die Filmdaten in ein Pandas-Dataframe einlesen.
import pandas as pd
# Filmmetadaten abrufen
original_movie_metadata = pd.read_csv('ml-latest-small/movies.csv')
movie_metadata = original_movie_metadata[['movieId', 'title', 'genres']]
movie_metadata['genres'] = movie_metadata['genres'].str.split('|', expand=False)
# tmdbId zu Filmmetadaten-Dataframe hinzufügen
original_movie_links = pd.read_csv('ml-latest-small/links.csv')
movie_info = pd.merge(movie_metadata, original_movie_links, on=["movieId"])[['movieId', 'title', 'genres', 'tmdbId']]
# Nur gültige Filme mit tmdbId filtern
movie_info = movie_info[movie_info['tmdbId'].notnull()]
movie_info['tmdbId'] = movie_info['tmdbId'].astype(int).astype(str)
movie_info.head()
Bewertungsdaten einlesen.
# Informationen zu Benutzerbewertungen abrufen
movie_user_rating = pd.read_csv('ml-latest-small/ratings.csv')
# Bewertungen von Filmen entfernen, die keine tmdbId haben
movie_user_rating = movie_user_rating[movie_user_rating['movieId'].isin(movie_info['movieId'])]
movie_user_rating = movie_user_rating[["userId", "movieId", "rating"]]
movie_user_rating.head()
Benutzerdaten einlesen.
# Informationen zu Benutzerbewertungen abrufen
movie_user_rating = pd.read_csv('ml-latest-small/ratings.csv')
# Bewertungen von Filmen entfernen, die keine tmdbId haben
movie_user_rating = movie_user_rating[movie_user_rating['movieId'].isin(movie_info['movieId'])]
movie_user_rating = movie_user_rating[["userId", "movieId", "rating"]]
movie_user_rating.head()
# Generieren von Benutzer- und Filmbewertungsvektoren
Die nicht-negative Matrixfaktorisierung (NMF) ist eine Matrixfaktorisierungstechnik, die eine nicht-negative Matrix R in zwei nicht-negative Matrizen W und H zerlegt, wobei R ≈ WH. NMF ist eine häufig verwendete Technik in Empfehlungssystemen, um latente Merkmale aus hochdimensionalen dünn besetzten Daten wie Benutzer-Item-Interaktionsmatrizen zu extrahieren.
In einem Empfehlungssystem-Kontext kann NMF verwendet werden, um die Benutzer-Item-Interaktionsmatrix in zwei niedrigdimensionale nicht-negative Matrizen zu faktorisieren: Eine Matrix repräsentiert die Präferenzen der Benutzer für die latenten Merkmale, und die andere Matrix repräsentiert, wie jedes Element mit diesen latenten Merkmalen zusammenhängt. Gegeben eine Benutzer-Item-Interaktionsmatrix R der Größe m x n, können wir sie in zwei nicht-negative Matrizen W und H faktorisieren, so dass R durch ihr Produkt approximiert wird: R ≈ W * H. Die Faktorisierung wird erreicht, indem der Abstand zwischen R und W * H minimiert wird, unter der Bedingung der nicht-negativen Einschränkungen für W und H.
Die Matrizen W und H entsprechen den Benutzervektor- und Filmbewertungsvektormatrizen und können später als Vektorindizes für Abfragen verwendet werden.
Beginnen wir damit, eine Benutzer-Item-Matrix für Filmbewertungen zu erstellen, wobei jede Zeile einen Benutzer und jede Spalte einen Film repräsentiert. Jede Zelle in der Matrix repräsentiert die entsprechende Benutzerbewertung für diesen Film. Wenn ein Benutzer einen bestimmten Film nicht bewertet hat, wird der Zellenwert auf 0 gesetzt.
from sklearn.decomposition import NMF
from sklearn.preprocessing import MaxAbsScaler
from scipy.sparse import csr_matrix
user_indices, user_ids = pd.factorize(movie_user_rating['userId'])
item_indices, movie_ids = pd.factorize(movie_user_rating['movieId'])
rating_sparse_matrix = csr_matrix((movie_user_rating['rating'], (user_indices, item_indices)))
# Matrix mit MaxAbsScaler normalisieren
max_abs_scaler = MaxAbsScaler()
rating_sparse_matrix = max_abs_scaler.fit_transform(rating_sparse_matrix)
Nachdem wir unsere Benutzer-Item-Matrix erstellt haben, können wir das NMF-Modell mit der Matrix anpassen.
# NMF-Modell mit Einstellungen erstellen
dimension = 512
nmf_model = NMF(n_components=dimension, init='nndsvd', max_iter=500)
# Zerlegung der dünn besetzten Matrix mit NMF
user_vectors = nmf_model.fit_transform(rating_sparse_matrix)
item_vectors = nmf_model.components_.T
error = nmf_model.reconstruction_err_
print("Reconstruction error: ", error)
Vektoren dem entsprechenden Dataframe hinzufügen.
# Benutzervektormatrix generieren, die Benutzer-IDs und Benutzervektoren enthält
user_vector_df = pd.DataFrame(zip(user_ids, user_vectors), columns=['userId', 'user_rating_vector']).reset_index(drop=True)
# Filmbewertungsvektormatrix generieren, die Film-IDs und Filmbewertungsvektoren enthält
movie_rating_vector_df = pd.DataFrame(zip(movie_ids, item_vectors), columns=['movieId', 'movie_rating_vector'])
# Erstellen von Datensätzen
Wir haben jetzt vier Dataframes: Metadaten zu Filmen, Benutzer-Film-Bewertungen, Benutzervektoren und Filmvektoren. Wir werden die relevanten Dataframes zu einem einzigen Dataframe zusammenführen.
user_rating_df = movie_user_rating.reset_index(drop=True)
# Füge Filmvektoren zu den Metadaten hinzu und entferne Filme ohne Filmvektor
movie_info_df = pd.merge(movie_info, movie_rating_vector_df, on=["movieId"]).reset_index(drop=True)
Speichern Sie die Dataframes als Parquet-Dateien.
import pyarrow as pa
import pyarrow.parquet as pq
# Erstellen Sie Tabellenobjekte aus den Daten und dem Schema
movie_table = pa.Table.from_pandas(movie_info_df)
user_table = pa.Table.from_pandas(user_vector_df)
rating_table = pa.Table.from_pandas(user_rating_df)
# Schreiben Sie die Tabelle in Parquet-Dateien
pq.write_table(movie_table, 'movie.parquet')
pq.write_table(user_table, 'user.parquet')
pq.write_table(rating_table, 'rating.parquet')
# Daten in MyScale einfügen
# Daten laden
Um Daten in MyScale einzufügen, laden wir zunächst Daten aus dem HuggingFace-Dataset myscale/recommendation-examples (opens new window), das im vorherigen Abschnitt erstellt wurde. Der folgende Codeausschnitt zeigt, wie Daten geladen und in Panda DataFrames transformiert werden.
from datasets import load_dataset
movie = load_dataset("myscale/recommendation-examples", data_files="movie.parquet", split="train")
user = load_dataset("myscale/recommendation-examples", data_files="user.parquet", split="train")
rating = load_dataset("myscale/recommendation-examples", data_files="rating.parquet", split="train")
# Datasets in Panda DataFrame transformieren
movie_info_df = movie.to_pandas()
user_vector_df = user.to_pandas()
user_rating_df = rating.to_pandas()
# Einbettungsvektoren von np-Array in Liste konvertieren
movie_info_df['movie_rating_vector'] = movie_info_df['movie_rating_vector'].apply(lambda x: x.tolist())
user_vector_df['user_rating_vector'] = user_vector_df['user_rating_vector'].apply(lambda x: x.tolist())
# Tabelle erstellen
Als nächstes erstellen wir Tabellen in MyScale.
Bevor Sie beginnen, müssen Sie Ihre Cluster-Host-, Benutzername- und Passwortinformationen aus der MyScale-Konsole abrufen. Der folgende Codeausschnitt erstellt drei Tabellen für Metadaten zu Filmen, Benutzervektoren und Benutzer-Film-Bewertungen.
import clickhouse_connect
# Client initialisieren
client = clickhouse_connect.get_client(
host='YOUR_CLUSTER_HOST',
port=443,
username='YOUR_USERNAME',
password='YOUR_CLUSTER_PASSWORD'
)
Tabellen erstellen.
client.command("DROP TABLE IF EXISTS default.myscale_movies")
client.command("DROP TABLE IF EXISTS default.myscale_users")
client.command("DROP TABLE IF EXISTS default.myscale_ratings")
# Tabelle für Filme erstellen
client.command(f"""
CREATE TABLE default.myscale_movies
(
movieId Int64,
title String,
genres Array(String),
tmdbId String,
movie_rating_vector Array(Float32),
CONSTRAINT vector_len CHECK length(movie_rating_vector) = 512
)
ORDER BY movieId
""")
# Tabelle für Benutzervektoren erstellen
client.command(f"""
CREATE TABLE default.myscale_users
(
userId Int64,
user_rating_vector Array(Float32),
CONSTRAINT vector_len CHECK length(user_rating_vector) = 512
)
ORDER BY userId
""")
# Tabelle für Benutzer-Film-Bewertungen erstellen
client.command("""
CREATE TABLE default.myscale_ratings
(
userId Int64,
movieId Int64,
rating Float64
)
ORDER BY userId
""")
# Hochladen von Daten
Nachdem die Tabellen erstellt wurden, fügen wir Daten aus den Datensätzen in die Tabellen ein.
client.insert("default.myscale_movies", movie_info_df.to_records(index=False).tolist(), column_names=movie_info_df.columns.tolist())
client.insert("default.myscale_users", user_vector_df.to_records(index=False).tolist(), column_names=user_vector_df.columns.tolist())
client.insert("default.myscale_ratings", user_rating_df.to_records(index=False).tolist(), column_names=user_rating_df.columns.tolist())
# Überprüfen Sie die Anzahl der eingefügten Daten
print(f"movies count: {client.command('SELECT count(*) FROM default.myscale_movies')}")
print(f"users count: {client.command('SELECT count(*) FROM default.myscale_users')}")
print(f"ratings count: {client.command('SELECT count(*) FROM default.myscale_ratings')}")
# Erstellen des Index
Nun sind unsere Datensätze in MyScale hochgeladen. Wir werden einen Vektorindex erstellen, um die Vektorsuche nach dem Einfügen der Datensätze zu beschleunigen.
Wir haben MSTG als unseren Vektorsuchalgorithmus verwendet. Für Konfigurationsdetails siehe Vektorsuche.
Das Skalarprodukt wird hier als Distanzmetrik verwendet. Speziell ergibt das Skalarprodukt zwischen dem Abfragevektor (der die Vorlieben eines Benutzers darstellt) und den Elementvektoren (die die Merkmale des Films darstellen) die Zellenwerte in der Matrix R, die durch das Produkt der Matrizen W und H approximiert werden können, wie im Abschnitt Generieren von Benutzer- und Filmbewertungsvektoren erwähnt.
# Vektorindex mit Kosinus erstellen
client.command("""
ALTER TABLE default.myscale_movies
ADD VECTOR INDEX movie_rating_vector_index movie_rating_vector
TYPE MSTG('metric_type=IP')
""")
Indexstatus überprüfen.
# Den Status des Vektorindex überprüfen, stellen Sie sicher, dass der Vektorindex mit dem Status 'Built' bereit ist
get_index_status="SELECT status FROM system.vector_indices WHERE name='movie_rating_vector_index'"
print(f"index build status: {client.command(get_index_status)}")
# Abfragen von MyScale
# Durchführen einer Abfrage für Filmpempfehlungen
Wählen Sie zufällig einen Benutzer als Zielbenutzer aus, für den wir Filme empfehlen, und erhalten Sie das Histogramm der Benutzerbewertungen, das die Verteilung der Benutzerbewertungen zeigt.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
random_user = client.query("SELECT * FROM default.myscale_users ORDER BY rand() LIMIT 1")
assert random_user.row_count == 1
target_user_id = random_user.first_item["userId"]
target_user_vector = random_user.first_item["user_rating_vector"]
print("currently selected user id={} for movie recommendation\n".format(target_user_id))
# Diagramm der Benutzerbewertungen
target_user_ratings = user_rating_df.loc[user_rating_df['userId'] == target_user_id]['rating'].tolist()
bins = np.arange(1.0, 6, 0.5)
# Histogramm berechnen
hist, _ = np.histogram(target_user_ratings, bins=bins)
print("Distribution of ratings for user {}:".format(target_user_id))
plt.bar(bins[:-1], hist, width=0.4)
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('User Rating Distribution')
for i in range(len(hist)):
plt.text(bins[i], hist[i], str(hist[i]), ha='center', va='bottom')
plt.show()
Eine Beispielaufteilung der Bewertungen für einen Benutzer
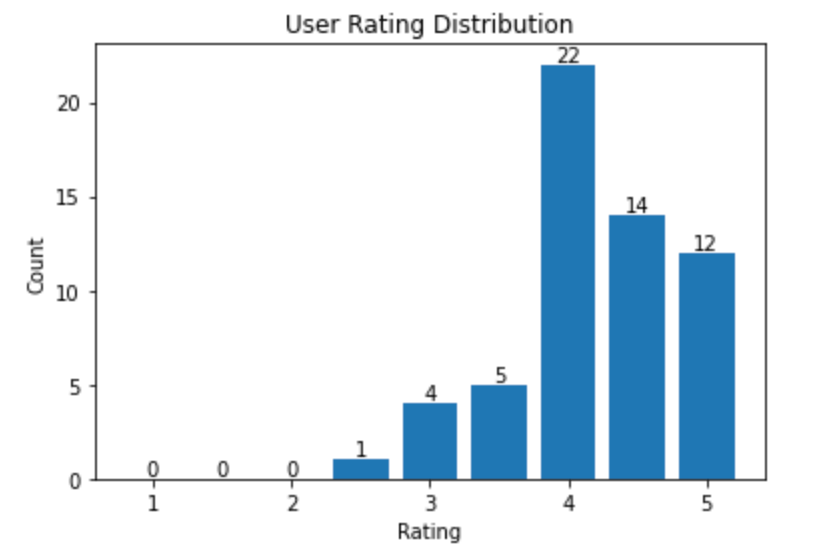
Als nächstes empfehlen wir Filme für den Benutzer.
Wie in den Abschnitten Generieren von Benutzer- und Filmbewertungsvektoren und Erstellen des Index beschrieben, werden unsere Benutzer- und Filmvektoren aus dem NMF-Modell extrahiert, und die Skalarprodukte der Vektoren dienen als unsere Vektordistanzmetriken. Die Formel des Skalarprodukts von zwei Vektoren kann wie folgt vereinfacht werden:
Genauer gesagt können wir eine approximierte Benutzer-Bewertungsmatrix erhalten, indem wir das Skalarprodukt der Benutzervektormatrix und der Filmvektormatrix basierend auf dem NMF-Modell verwenden. Der Wert der Zelle an der Position (i, j) repräsentiert die geschätzte Bewertung des Benutzers i für den Film j. Daher können die Abstände zwischen Benutzervektoren und Filmvektoren, die durch ihre Skalarprodukte dargestellt werden, verwendet werden, um Filme für Benutzer zu empfehlen. Größere Abstände entsprechen höheren geschätzten Filmbewertungen.
Da wir jedoch die Bewertungsmatrix in den vorherigen Abschnitten normalisiert haben, müssen wir die Abstände noch auf die neue Bewertungsskala (0, 5) skalieren.
top_k = 10
# Datenbankabfrage, um die top K empfohlenen Filme zu finden
recommended_results = client.query(f"""
SELECT movieId, title, genres, tmdbId, distance(movie_rating_vector, {target_user_vector}) AS dist
FROM default.myscale_movies
WHERE movieId not in (
SELECT movieId
from default.myscale_ratings
where userId = {target_user_id}
)
ORDER BY dist DESC
LIMIT {top_k}
""")
recommended_movies = pd.DataFrame.from_records(recommended_results.named_results())
rated_score_scale = client.query(f"""
SELECT max(rating) AS max, min(rating) AS min
FROM default.myscale_ratings
WHERE userId = {target_user_id}
""")
max_rated_score = rated_score_scale.first_row[0]
min_rated_score = rated_score_scale.first_row[1]
print("Top 10 movie recommandations with estimated ratings for user {}".format(target_user_id))
max_dist = recommended_results.first_row[4]
recommended_movies['estimated_rating'] = min_rated_score + ((max_rated_score - min_rated_score) / max_dist) * recommended_movies['dist']
recommended_movies[['movieId', 'title', 'estimated_rating', 'genres']]
Beispiel-Ausgabe
| movieId | title | estimated_rating | genres |
|---|---|---|---|
| 158966 | Captain Fantastic (2016) | 5.000000 | [Drama] |
| 79702 | Scott Pilgrim vs. the World (2010) | 4.930944 | [Action, Comedy, Fantasy, Musical, Romance] |
| 1 | Toy Story (1995) | 4.199992 | [Adventure, Animation, Children, Comedy, Fantasy] |
| 8874 | Shaun of the Dead (2004) | 4.021980 | [Comedy, Horror] |
| 68157 | Inglourious Basterds (2009) | 3.808410 | [Action, Drama, War] |
| 44191 | V for Vendetta (2006) | 3.678385 | [Action, Sci-Fi, Thriller, IMAX] |
| 6539 | Pirates of the Caribbean: The Curse of the Black Pearl (2003) | 3.654729 | [Action, Adventure, Comedy, Fantasy] |
| 8636 | Spider-Man 2 (2004) | 3.571647 | [Action, Adventure, Sci-Fi, IMAX] |
| 6333 | X2: X-Men United (2003) | 3.458405 | [Action, Adventure, Sci-Fi, Thriller] |
| 8360 | Shrek 2 (2004) | 3.417371 | [Adventure, Animation, Children, Comedy, Musical, Romance] |
# Anzahl der bewerteten Filme zählen
rated_count = len(user_rating_df[user_rating_df["userId"] == target_user_id])
# Datenbankabfrage, um die top K empfohlenen gesehenen Filme für den Benutzer zu finden
rated_results = client.query(f"""
SELECT movieId, genres, tmdbId, dist, rating
FROM (SELECT * FROM default.myscale_ratings WHERE userId = {target_user_id}) AS ratings
INNER JOIN (
SELECT movieId, genres, tmdbId, distance(movie_rating_vector, {target_user_vector}) AS dist
FROM default.myscale_movies
WHERE movieId in ( SELECT movieId FROM default.myscale_ratings WHERE userId = {target_user_id} )
ORDER BY dist DESC
LIMIT {rated_count}
) AS movie_info
ON ratings.movieId = movie_info.movieId
WHERE rating >= (
SELECT MIN(rating) FROM (
SELECT least(rating) AS rating FROM default.myscale_ratings WHERE userId = {target_user_id} ORDER BY rating DESC LIMIT {top_k})
)
ORDER BY dist DESC
LIMIT {top_k}
""")
print("Genres of top 10 highest-rated and recommended movies for user {}:".format(target_user_id))
rated_genres = {}
for r in rated_results.named_results():
for tag in r['genres']:
rated_genres[tag] = rated_genres.get(tag, 0) + 1
rated_tags = pd.DataFrame(rated_genres.items(), columns=['category', 'occurrence_in_rated_movie'])
recommended_genres = {}
for r in recommended_results.named_results():
for tag in r['genres']:
recommended_genres[tag] = recommended_genres.get(tag, 0) + 1
recommended_tags = pd.DataFrame(recommended_genres.items(), columns=['category', 'occurrence_in_recommended_movie'])
inner_join_tags = pd.merge(rated_tags, recommended_tags, on='category', how='inner')
inner_join_tags = inner_join_tags.sort_values('occurrence_in_rated_movie', ascending=False)
inner_join_tags
Beispiel-Ausgabe
| Kategorie | Häufigkeit_in_bewerteten_Filmen | Häufigkeit_in_empfohlenen_Filmen |
|---|---|---|
| Drama | 8 | 2 |
| Comedy | 5 | 5 |
| Romance | 3 | 2 |
| War | 2 | 1 |
| Adventure | 1 | 5 |
Zusätzlich können wir die top 10 bewerteten Filme mit ihren tatsächlichen Bewertungen und vorhergesagten Bewertungen abrufen, um die Ähnlichkeit zwischen den Benutzerbewertungen und unseren geschätzten Bewertungen zu beobachten.
rated_movies = pd.DataFrame.from_records(rated_results.named_results())
print("Top 10 highest-rated movies along with their respective user scores and predicted ratings for the user {}".format(target_user_id))
max_dist = rated_results.first_row[3]
rated_movies['estimated_rating'] = min_rated_score + ((max_rated_score - min_rated_score) / max_dist) * rated_movies['dist']
rated_movies[['movieId', 'rating', 'estimated_rating', 'genres']]
Beispiel-Ausgabe
| movieId | rating | geschätzte_bewertung | genres |
|---|---|---|---|
| 2324 | 5.0 | 4.999934 | [Comedy, Drama, Romance, War] |
| 90430 | 5.0 | 4.925842 | [Comedy, Drama] |
| 128620 | 5.0 | 4.925816 | [Crime, Drama, Romance] |
| 63876 | 5.0 | 4.925714 | [Drama] |
| 6807 | 5.0 | 4.925266 | [Comedy] |
| 3967 | 5.0 | 4.924646 | [Drama] |
| 3448 | 5.0 | 4.923244 | [Comedy, Drama, War] |
| 4027 | 5.0 | 4.922347 | [Adventure, Comedy, Crime] |
| 215 | 5.0 | 4.922092 | [Drama, Romance] |
| 112290 | 5.0 | 4.918183 | [Drama] |