
Las bases de datos vectoriales ofrecen una recuperación ultrarrápida de objetos similares almacenados entre miles de millones de registros. Sin embargo, es posible que también estés interesado en buscar objetos relacionados que cumplan con un conjunto específico de condiciones, conocido como búsqueda vectorial filtrada. Con la ayuda de MyScale (opens new window), puedes llevar tus búsquedas vectoriales filtradas a un nuevo nivel.
La mayoría de los índices vectoriales o almacenes vectoriales funcionan como servicios de índices dedicados. Admiten una implementación parcial de búsqueda vectorial filtrada de operadores de consulta y proyección de MongoDB (opens new window), donde puedes ingresar un diccionario de condiciones.
Los tipos de datos y comparadores admitidos difieren entre las implementaciones, pero la mayoría de las interfaces solo admiten cadenas de texto, enteros en igualdad y comparaciones de valores básicos. A diferencia de las bases de datos, estos índices vectoriales no están diseñados para manejar tipos de datos y condiciones complejas. Como resultado, necesitas una solución de base de datos externa para almacenar estos datos, pero no puedes utilizar estos datos para realizar búsquedas vectoriales filtradas. Esta solución funciona, pero es complicada y tiene limitaciones.
En realidad, puede y debería haber una mejor solución. La búsqueda vectorial se puede integrar con una base de datos para hacerla más robusta de lo que es ahora. MyScale puede manejar simultáneamente la búsqueda vectorial filtrada con condiciones y tipos de datos complejos utilizando la cláusula WHERE estándar.
# Filtrado previo y filtrado posterior
Las implementaciones de búsqueda vectorial filtrada se pueden clasificar en dos tipos:
- Búsqueda vectorial filtrada previa
- Búsqueda vectorial filtrada posterior
Por ejemplo:
Imagina que tienes una tabla que contiene el historial de chat de los usuarios Jack, Jan y John, y te gustaría utilizar una consulta de búsqueda vectorial filtrada para recuperar el historial de chat de Jack similar al vector de consulta dado.
Nota:
Cada registro tiene una marca de usuario y un vector de características. Para simplificar, convertimos los vectores en números.
La siguiente imagen describe tanto una consulta NoSQL como una consulta SQL que recuperan el historial de chat de Jack:
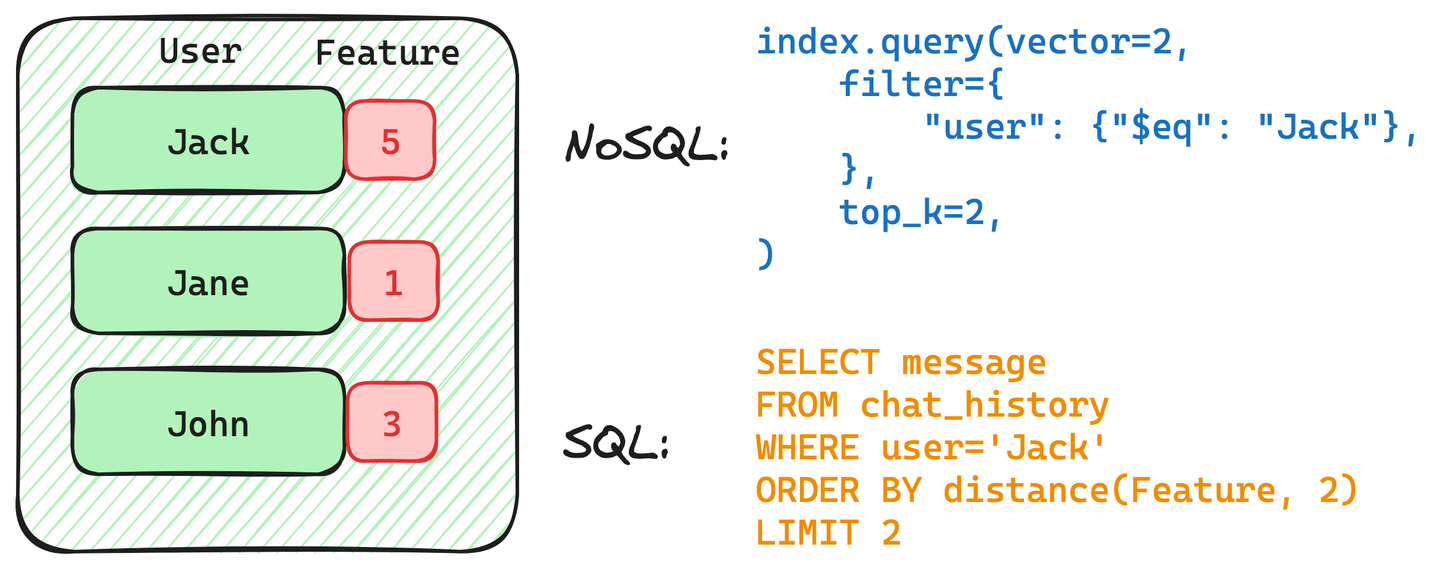
Ambas consultas contienen un filtro en el usuario Jack. Sin embargo, este filtro puede estar estructurado de manera diferente, dependiendo de la implementación.
1. Búsqueda vectorial filtrada previa: Para la búsqueda vectorial filtrada previa, el motor primero escaneará los datos y solo retendrá los registros que cumplan con la condición de filtro dada. Una vez que se complete este escaneo, el motor realizará la búsqueda vectorial en los candidatos prefiltrados.
2. Búsqueda vectorial filtrada posterior: Por otro lado, la búsqueda vectorial filtrada posterior primero realizará la búsqueda vectorial y luego filtrará estos resultados en función de la condición de filtro dada.
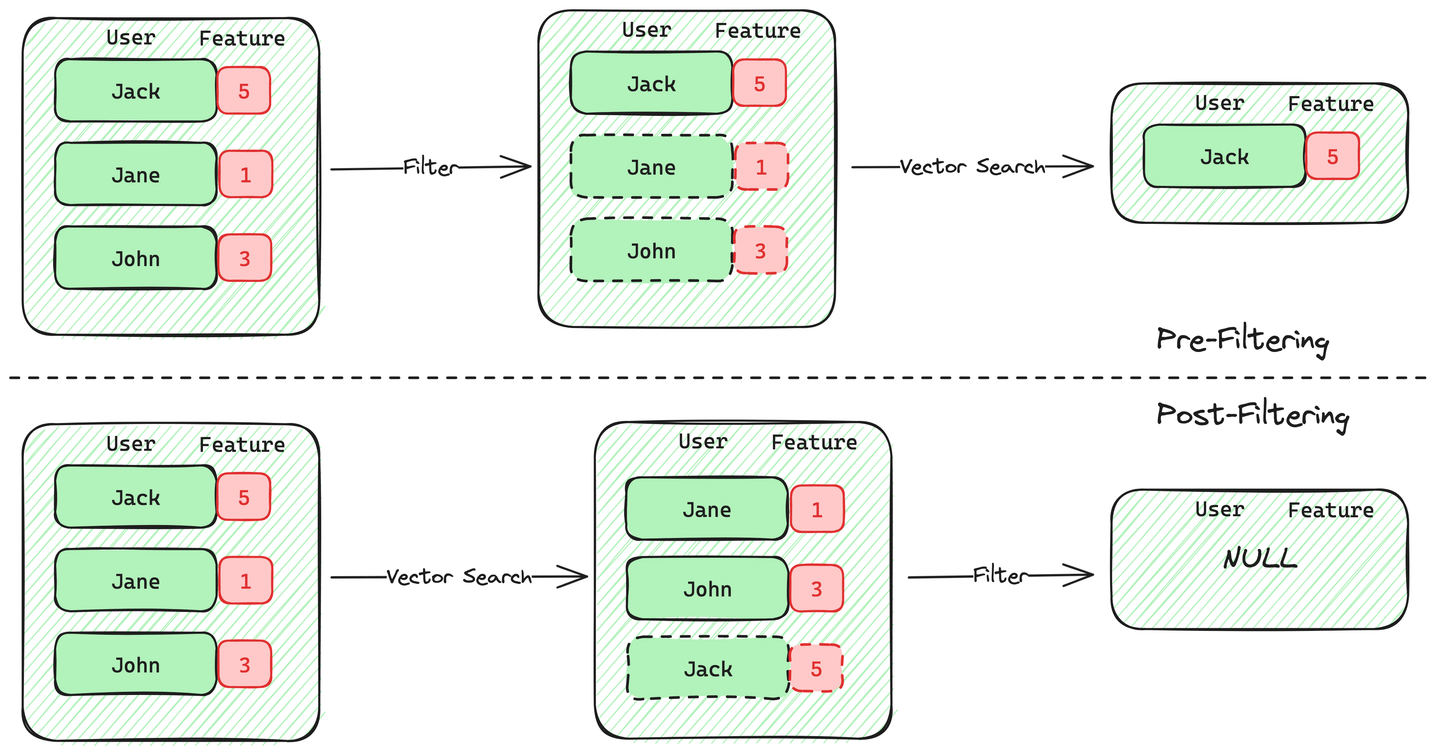
Entre estos dos métodos, el filtrado previo es mejor que el filtrado posterior en términos de precisión y cumple con lo que esperamos de una búsqueda vectorial filtrada. La mayoría de las bases de datos vectoriales admiten el filtrado previo con búsqueda vectorial. Sin embargo, este filtrado previo no es gratuito, ya que aumenta la computación y afecta el rendimiento de la búsqueda vectorial filtrada. La mayoría de las implementaciones sufren de limitaciones de rendimiento o de filtros, como límites de almacenamiento de datos y comparadores admitidos.
MyScale utiliza un motor de almacenamiento basado en columnas (opens new window) adaptado del motor MergeTree de ClickHouse (opens new window), que es muy rápido en filtros convencionales, mejorando significativamente el filtrado de la primera etapa y haciendo que la búsqueda vectorial filtrada sea más rápida que otras implementaciones. Además, puedes utilizar una simple cláusula WHERE en SQL para definir filtros en cualquier columna de tu tabla.
# Lo que puedes hacer con la cláusula WHERE en MyScale
Como MyScale se desarrolla sobre ClickHouse (opens new window), ofrece exactamente la misma funcionalidad que ClickHouse.
Por ejemplo:
| Método | Otros | MyScale |
|---|---|---|
| eq / neq | ✅ | ✅ |
| ge / gt / lt / le | ✅ | ✅ |
| include / exclude | ✅ | ✅ |
con coincidencia de patrones de cadena LIKE | ❌ | ✅ |
| Marcas de tiempo/Datos geográficos/JSON | ❌ | ✅ |
| con función | ❌ | ✅ |
| con arrayFunction (opens new window) | ❌ | ✅ |
| con subconsultas | ❌ | ✅ |
Veamos varios ejemplos que destacan lo que la cláusula WHERE de MyScale es capaz de hacer.
Nota:
Puedes encontrar el código de estos ejemplos en nuestros espacios de Colab o GitHub.
![]()
![]()
Nota:
Consulta la documentación oficial de ClickHouse (opens new window) para obtener más información sobre los tipos de datos y las funciones.
# Comparación de valores comunes: =, !=, >, <, >=, <=
La mayoría de las soluciones de índices vectoriales admiten estas operaciones en cadenas de texto o números. En MyScale, puedes escribir comparaciones de valores con:
WHERE columna = valor
Donde la columna puede ser cualquier nombre de columna en la tabla y la operación puede ser cualquiera de =, !=, >, <, >=, <=.
Nota:
El tipo de columna y el valor deben ser iguales.
Si tienes múltiples condiciones para agregar a la cláusula WHERE, utiliza operadores lógicos como AND para conectarlos:
WHERE columna_1 = valor_1 AND columna_2 >= valor_2
# Operadores de conjunto comunes: Include, Exclude
MyScale también admite operaciones de conjunto como IN y NOT IN:
WHERE columna IN (valor_1, valor_2, ...)
Esto es útil cuando deseas seleccionar un conjunto de filas. De manera similar, puedes utilizar operadores lógicos para conectar estos operadores de conjunto con otras condiciones.
# Operadores para matrices
Puedes verificar si un elemento está en una matriz con la función has:
WHERE has(columna, valor_1)
# Coincidencia de patrones de cadena
Puedes realizar coincidencias de patrones de cadena en MyScale con la palabra clave LIKE:
WHERE columna_1 LIKE '%valor%'
Esta condición coincide con los valores que contienen valor en la columna_1. Este operador de coincidencia de patrones de cadena es uno de los muchos operadores ofrecidos por MySQL. Otros incluyen: NOT LIKE, match con expresiones regulares y ngramSearch.
Nota:
Consulta la documentación oficial de ClickHouse (opens new window) para obtener más información sobre el operador LIKE.
# Comparación de fecha y hora
MyScale también incluye una función de comparación de fecha y hora:
WHERE dateDiff('hour', columna_fecha_hora, toDateTime('2018-01-02 23:00:00')) >= 25;
Esta cláusula WHERE se refiere a cualquier fila cuya columna_fecha_hora sea posterior a la fecha y hora dadas durante más de 25 horas. Esta función también admite segundos, minutos, días y meses.
Nota:
Consulta aquí (opens new window) para obtener más información.
# Comparación de datos geográficos
MyScale puede manejar el Índice H3 (opens new window) y la Geometría S2 (opens new window), herramientas poderosas para la planificación de rutas y el análisis de geometría.
Por ejemplo, con el Índice H3, puedes utilizar el área de un hexágono para filtrar datos geográficos en un área determinada:
WHERE h3CellAreaM2(columna_h3) > 1000
También puedes agregar la distancia a un Índice H3 específico:
WHERE h3Distance(columna_h3, valor_h3) > 10
# Objeto arbitrario con columnas JSON
MyScale te permite almacenar JSON como un objeto y filtrar según sus atributos.
Puedes utilizar el tipo de datos JSON para importar una cadena JSON en una tabla y utilizar la siguiente cláusula WHERE para filtrar los resultados:
WHERE columna_json.attr_1 = valor_1
También puedes filtrar según atributos anidados de la siguiente manera:
WHERE columna_json.attr_1.attr_2 = valor_1
Aunque esta es una característica experimental (opens new window), es potente de utilizar. Hemos utilizado estos objetos en nuestras implementaciones de almacenamiento vectorial LangChain (opens new window) y LlamaIndex (opens new window).
# Funciones de valor
MyScale incluye muchas funciones de procesamiento de datos de columna que puedes utilizar en cláusulas WHERE, como:
WHERE abs(columna_1) > 5
Puedes incluir varias columnas en tu cláusula WHERE:
WHERE columna_1 + columna_2 + columna_3 > 10
# Funciones de matriz
Las funciones de matriz son realmente poderosas, especialmente con nuestra búsqueda vectorial. En nuestra documentación (opens new window), presentamos funciones de matriz en MyScale para los cálculos de logit finales y los cálculos de gradiente para nuestro clasificador de pocos disparos.
ClickHouse tiene una gran documentación sobre funciones de matriz (opens new window).
Nota:
Si aún necesitas ayuda con las funciones de matriz en MyScale, únete a nuestro discord (opens new window) y pregunta.
# Soporte de subconsultas
Las subconsultas son consultas dentro de consultas. También puedes escribir una cláusula WHERE con otra consulta SELECT de la siguiente manera:
WHERE columna_1 IN (SELECT ... FROM otra_tabla WHERE ...)

# Rendimiento de la búsqueda vectorial filtrada
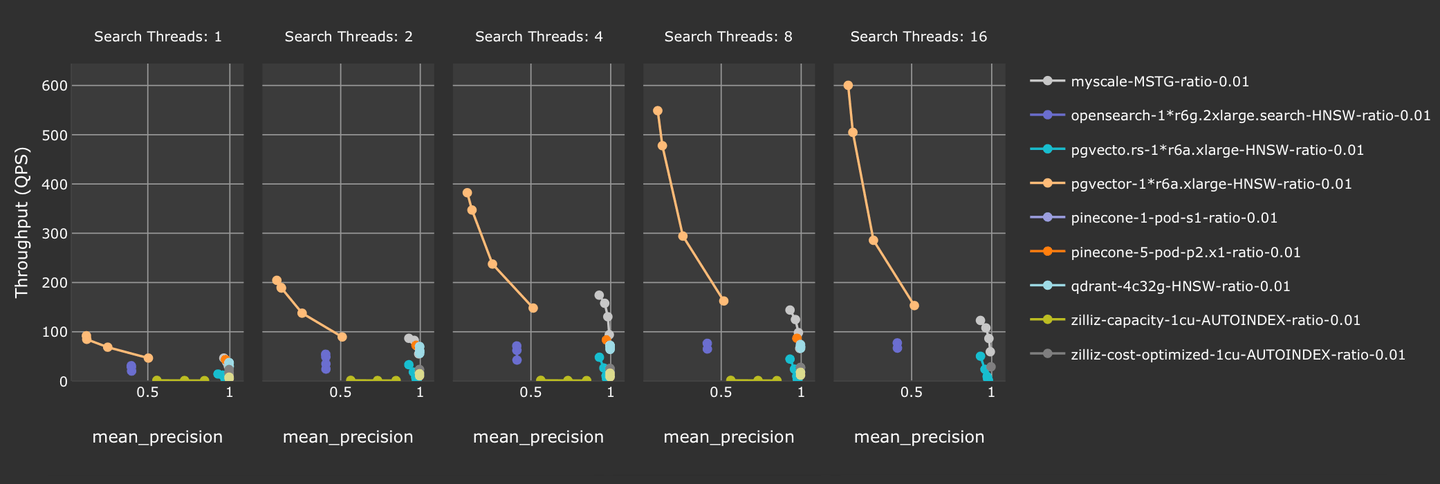
Investigamos el rendimiento de la búsqueda vectorial filtrada en vector-db-benchmark (opens new window). Utilizamos laion-768-5m-ip-probability, donde se agrega un número aleatorio como su marca de filtro durante la consulta. También probamos soluciones populares de bases de datos vectoriales frente a MyScale. Como se describe en el siguiente gráfico, MyScale supera a la mayoría de las otras soluciones de bases de datos vectoriales al proporcionar una mejor precisión con un mayor rendimiento.
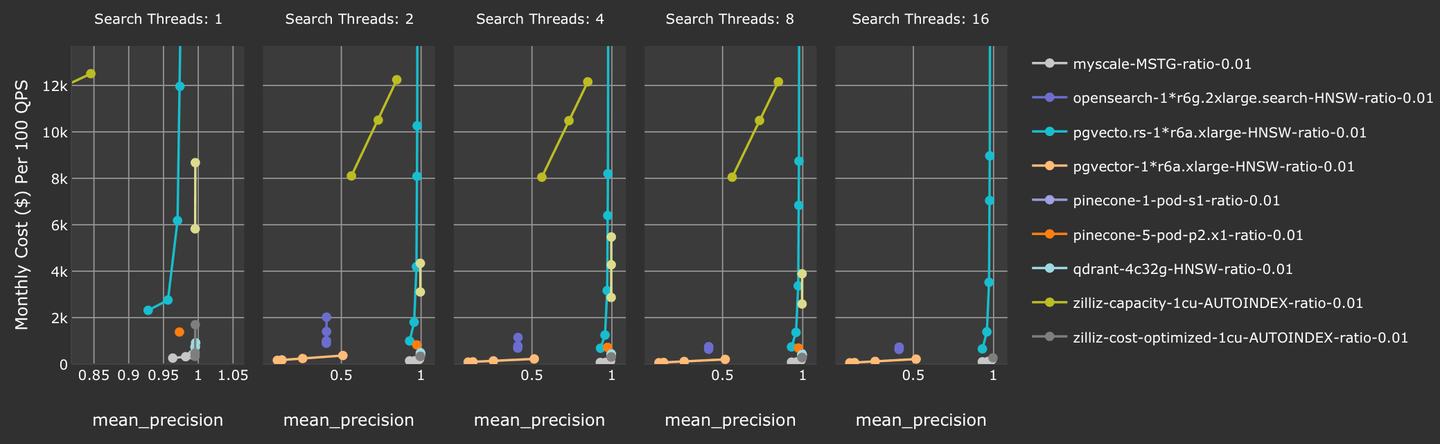
Además, MyScale logra la mejor eficiencia de costos de todas las bases de datos vectoriales probadas cuando la precisión es >= 90%. En comparación con otras bases de datos vectoriales integradas con SQL, como pgvector y pgvector.rs, MyScale se destaca como la única base de datos integrada con SQL y vectorial que logra una precisión y un rendimiento listos para producción en la búsqueda filtrada.
Nota:
Consulta el siguiente blog comparando pgvector y MyScale (opens new window) para obtener más información.
En resumen, MyScale ofrece una mejor precisión con un mayor rendimiento a un menor costo. También admitimos 5 millones de vectores con más tipos de datos y funciones dentro de nuestra s1 pod en la línea de productos, que es gratuita para todos los usuarios registrados.
# Conclusión
La búsqueda filtrada es un tipo común de consulta en bases de datos vectoriales que te permite buscar vectores o puntos de datos similares en función de criterios o filtros específicos, especialmente cuando se trata de datos que se pueden representar como vectores, como incrustaciones de texto e imágenes u otros datos estructurados.
MyScale incorpora el poder de SQL en la tecnología de IA; la búsqueda filtrada es un ejemplo de ello, lo que permite capacidades de consulta más sofisticadas y flexibles para las bases de datos vectoriales. Al combinar IA y SQL, puedes realizar operaciones y búsquedas de datos complejas, lo que facilita la extracción de información valiosa, el descubrimiento de patrones y la realización de diferentes tareas analíticas.
Si estás interesado en cómo SQL puede potenciar tus aplicaciones de IA, únete hoy a nosotros en discord (opens new window) o X (opens new window).



