
Large Language Models (opens new window) (LLMs) have revolutionized the field of Natural Language Processing (NLP), introducing a new way to interact with technology. Advanced models such as GPT (opens new window) and BERT (opens new window) have inaugurated a new era in semantic understanding. They enable computers to process and generate human-like text, bridging the gap between human communication and machine interpretation. LLMs are now powering multiple applications, including sentiment analysis, machine translation, question-answering, text summarization, chatbots, virtual assistants, and more.
Despite their practical applications, Large Language Models (LLMs) come with their own set of challenges. They are designed to be generalized, which means they might lack specificity. Additionally, because they are trained on past data, they might not always provide the latest information. This can result in LLMs generating incorrect or outdated responses, leading to a phenomena called “Hallucination (opens new window)”. It arises when the models make errors or generate unpredictable information due to gaps in their training data.
Retrieval-Augmented Generation (opens new window) (RAG) systems are used to address issues like, lack of specificity, and real-time updates, offering potential solutions to enhance the responsible deployment of LLMs.
# What is RAG
In 2020, Meta researchers proposed retrieval-augmented generation (RAG) by combining the Natural Language Generation (opens new window) (NLG) capability of LLMs with the Information Retrieval (IR) component to optimize the output. It refers to a reliable knowledge source outside their training data sources before responding to the query. It extends LLM capabilities without requiring model retraining, which provides a cost-effective way to enhance output relevancy, accuracy, and usability across various contexts.
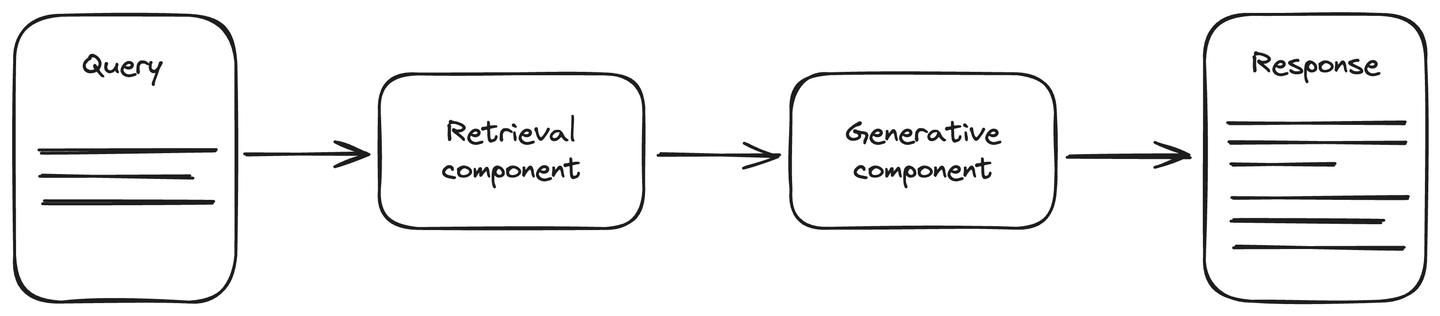
The RAG architecture includes an up-to-date data source to enhance the accuracy during Generative AI tasks. It is divided into two main components: retrieval and generative component. The retrieval component is attached to a data source, mostly a vector database, that retrieves the updated information about the query. This information, along with the query, is provided to the generative component. The generative component is an LLM model that generates the response accordingly. RAG improves the LLM understanding, and the generated response is more accurate and up-to-date.
Related Article: What to expect from RAG (opens new window)
# How to Set up the Retrieval Component of an RAG System
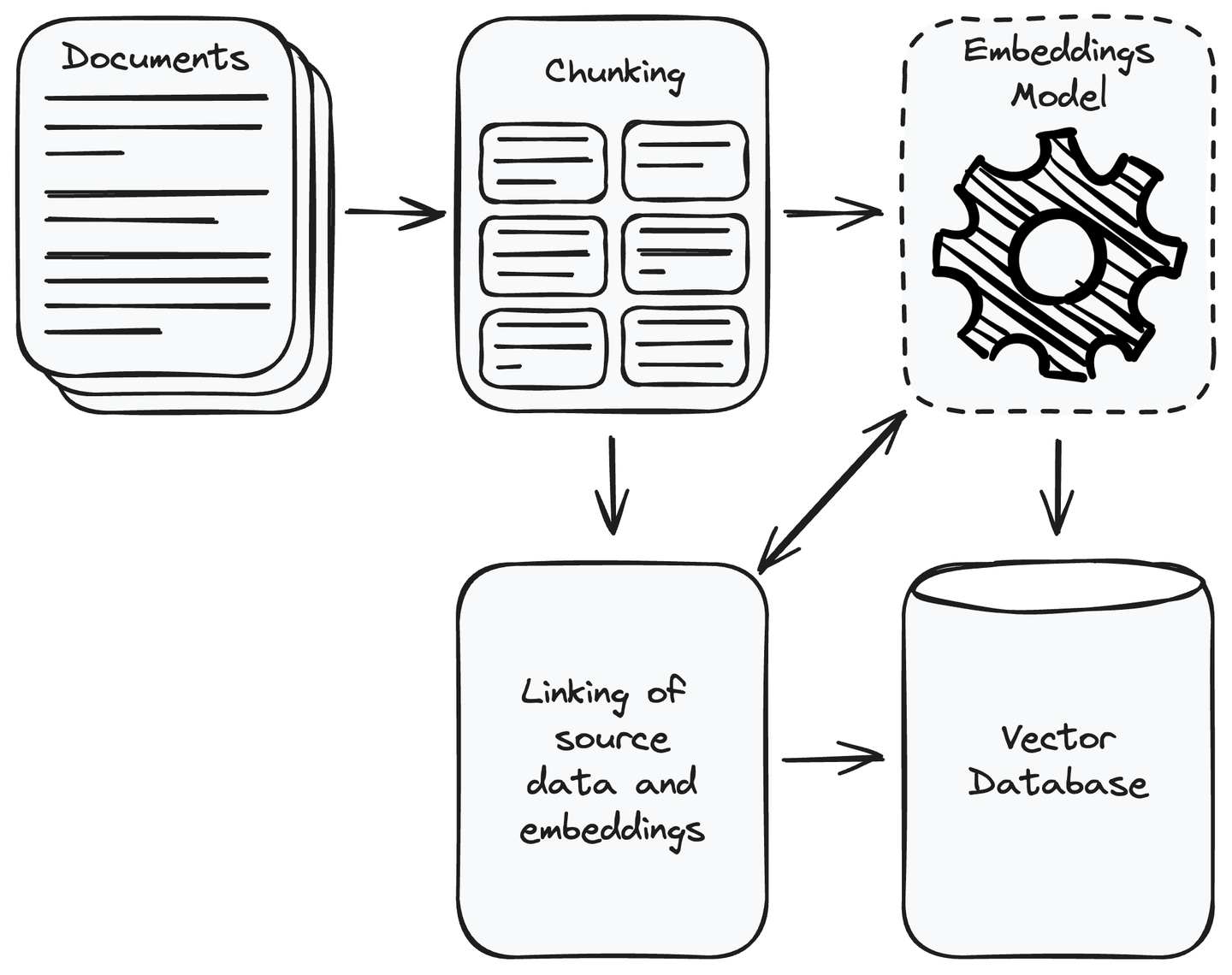
First of all, you must collect all the data required for your application. Once you complete the data collection, remove the irrelevant data. Divide the collected data into manageable smaller chunks and convert these chunks into vector representation using embedding models (opens new window). Vectors are numeric representations where semantically similar content is closer to each other. It allows the system to understand and match the user query with the relevant information in the data source. Store vectors in a vector database and link the chunks of the source data with its embeddings. This will help in retrieving the data chunk of a vector similar to the user query.
MyScale (opens new window) is a cloud-based vector database based on ClickHouse (opens new window) that combines the usual SQL queries with the strength of a vector database. This allows you to save and find high-dimensional data, like image features or text embeddings, using the regular SQL queries of asking for information. MyScale is especially powerful for AI applications where comparing vectors is important. It's designed to be affordable and practical for developers dealing with a lot of vector data in AI and machine learning tasks.
Additionally, MyScale is designed to be more affordable, faster, and more accurate than other options. To encourage users to experience its benefits, MyScale offers 5 million free vector storage on the free tier. This makes it a cost-efficient and user-friendly solution for developers exploring vector databases in their AI and machine learning endeavors.
Related Article: Build a RAG-Enabled Chatbot (opens new window)
# How Does an RAG System Work
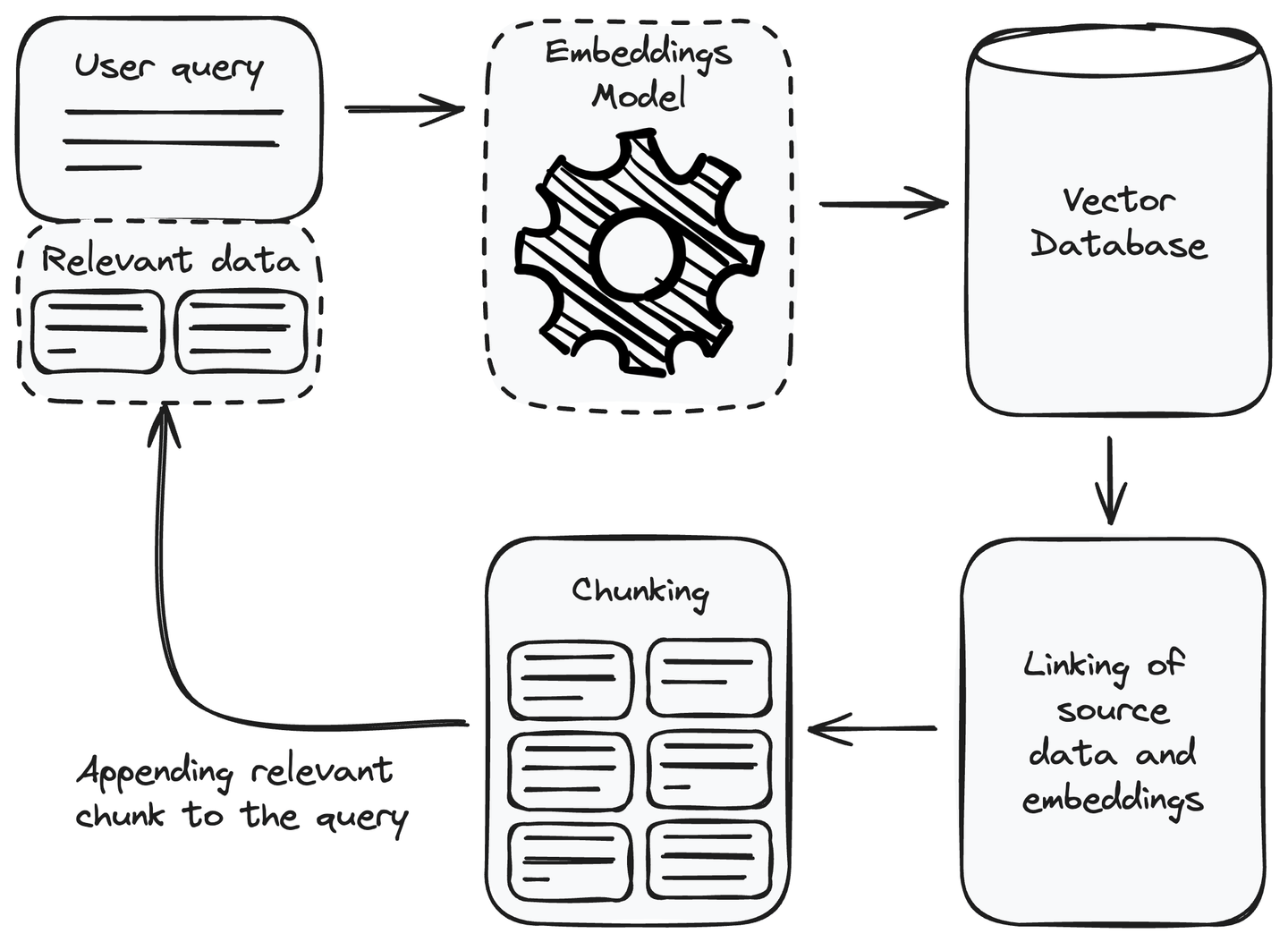
After setting up the retrieval component, we can now utilize it in our RAG system. To respond to a user query, we can use it to retrieve the relevant information and append it to the user query as a context before passing it to the language model for response generation. Let’s understand how to use the retrieval component to get the relevant information.
# Adding Relevant Information to the Query
Whenever we receive a user query, the first step we need to perform is to convert the user query into an embedding or vector representation. Use the same embedding model we used to convert the data source into embeddings while setting up the retrieval component. After the conversion of the user query into a vector representation, find the similar
# Generating Response Using LLM
Now, we have the query and the related chunks of information. Feed the user query along with the retrieved data to the LLM (the generative component). The LLM is capable of understanding the user query and processing the provided data. It will generate the response to the user’s query according to the information received from the retrieval component.
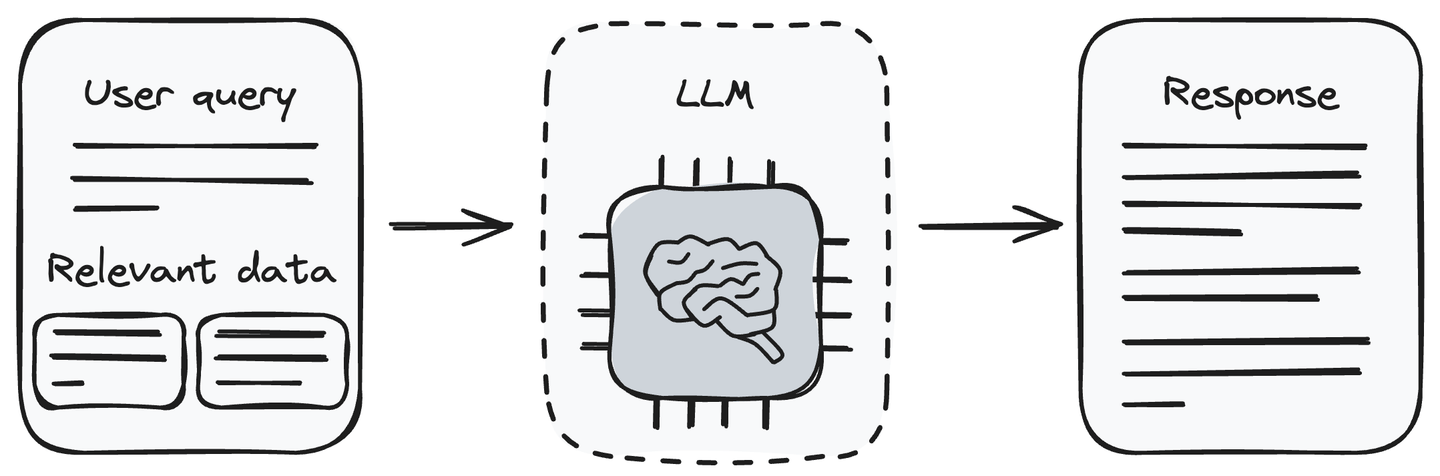
Passing the relevant information along with the user query to the LLM is a method that removes the hallucination issue of LLM. Now, the LLM can generate responses to the user query using the information we pass it with the user query.
Note: Remember to update the database regularly with the latest information to ensure the accuracy of the model.
# Some RAG Application Scenarios
RAG systems (opens new window) can be used in different applications that need precise and contextually relevant information retrieval. This helps improve the accuracy, timeliness, and reliability of the generated responses. Let’s discuss some applications of a RAG system.
- Domain-specific questioning: When a RAG system faces questions in a specific domain, it utilizes the retrieval component to dynamically access external knowledge sources, databases, or domain-specific documents. This allows RAG systems to generate responses that are contextually relevant by reflecting the most recent and accurate information within the specified domain. This could be helpful in various domains, such as healthcare, legal interpretation, historical research, technical troubleshooting, etc.
- Factual accuracy: Factual accuracy is crucial in ensuring that the generated content or responses align with accurate and verified data. In situations where inaccuracies may arise, RAG prioritizes factual accuracy to provide information that is consistent with the reality of the subject matter. This is essential for various applications, including news reporting, educational content, and any scenario where the reliability and trustworthiness of information are paramount.
- Research queries: RAG systems are valuable in addressing research queries by dynamically retrieving relevant and up-to-date information from their knowledge sources. For example, suppose a researcher puts a query related to the latest advancements in a specific scientific field. In that case, a RAG system can leverage its retrieval component to access recent research papers, publications, and relevant data to ensure that the researcher receives contextually accurate and current insights.
Related Article: How to build a recommendation system (opens new window)

# Challenges to Build an RAG System
Although the RAG systems have various use cases and advantages, they also face a few unique limitations. Let’s pen down them below:
- Integration: Integrating a retrieval component with an LLM-based generative component could be difficult. The complexity is increased when working with multiple data sources in different formats. Make sure the consistency over all data sources using separate modules before integrating the retrieval component with the generative component.
- Data Quality: RAG systems are dependent on the attached data source. The quality of a RAG system could be poor for multiple reasons, such as using low-quality content, using different embedding in case of multiple data sources, or using inconsistent data formats. Make sure to maintain the data quality.
- Scalability: The performance of a RAG system is compromised as the amount of external data increases. The tasks of converting data into embedding, comparing the meaning of similar chunks of data, and retrieving in real time may become computationally intensive. This may slow down the RAG system. To address this issue, you can use MyScale that has resolved the issue by providing a 390 QPS(Query Per Second) on the LAION 5M dataset with a 95% recall rate and 17ms of average query latency witt the x1 pod.
# Conclusion
RAG is one of the techniques to improve the capabilities of LLM by attaching a knowledge base to it. You can understand it as a search engine with language generation abilities. These systems mitigate the hallucination issue of LLMs without any re-training or fine-tuning cost. Using an external data source while responding to the user query provides a more accurate and up-to-date response, especially when working with factual, latest, or regularly updated data.Despite these advantages of RAG systems, it also comes with their limitations.
MyScale offers a powerful solution for large-scale and complex RAG applications by combining the strengths of ClickHouse, advanced vector search algorithms and joint SQL vector optimizations. It is specifically designed for AI applications, considering all factors including cost and scalability. Additionally, it provides integrations with well-known AI frameworks like LangChain (opens new window) and LlamaIndex (opens new window). These qualities and features make MyScale the best fit for your next AI application.
If you have any suggestions and feedbacks, please reach out to us through Twitter (opens new window) or Discord (opens new window).



