
Retrieval-augmented generation (RAG) is an AI framework designed to augment an LLM by integrating it with information retrieved from an external knowledge base. And based on the increasing focus RAG has garnered lately, it is reasonable to conclude that RAG is now a prominent topic in the AI/NLP (Artificial Intelligence/Natural Language Processing) ecosystem. Therefore, let's jump in and discuss what to expect from RAG systems when paired with self-hosted LLMs.
In the blog post titled: “Discover the Performance Gain with Retrieval Augmented Generation (opens new window),” we investigated how the number of retrieved documents can improve the quality of LLM answers. We also described how the vectorized LLM based on the MMLU dataset, stored in a vector database such as MyScale (opens new window), generates more accurate responses when integrated with contextually relevant knowledge and without fine-tuning the dataset.
Ergo, the salient point being:
RAG fills the knowledge gaps, reducing hallucinations by augmenting prompts with external data.
Using external LLM APIs in your application can pose potential risks to data security, decrease control, and significantly increase costs, especially with a high user volume. Therefore, the question that begs is:
How can you ensure greater data security and maintain control over your system?
The concise answer is to use a self-hosted LLM. This approach not only offers superior control over the data and model but also strengthens data privacy and security, while enhancing cost efficiency.
# Why Self-Hosted LLMs?
Cloud-based Large Language Models-as-a-Service (like OpenAI's ChatGPT) are easy to access and can add value to a wide range of application domains, providing instant and accountable access. However, public LLM providers may violate data security and privacy, as well as concerns around overt control, knowledge leaks, and cost efficiencies.
Note:
If any/all of these concerns resonate with you, then it is worthwhile using a self-hosted LLM.
As we continue with our discussion, let's discuss these four significant concerns in detail:
# 🔒 Privacy
Privacy must be a preeminent concern when integrating LLM APIs with your application.
Why is privacy such an issue?
The answer to this question has several parts, as highlighted in the following points:
- LLM service providers might use your personal information for training or analysis, compromising privacy and security.
- Secondly, LLM providers could incorporate your search queries into their training data.
Self-hosted LLMs solve these issues as they are secure; your data is never exposed to a third-party API.
# 🔧 Control
LLM services, like OpenAI GPT-3.5, generally censor topics such as violence and asking for medical advice. You have no control over what content is censored. However, you might want to develop your own censorship model (and rules).
How do you adopt a censorship model that meets your requirements?
The broad strokes’ theoretical answer is that custom fine-tuning an LLM by building customized filters is preferable to using prompting because a fine-tuned model is more stable. Additionally, self-hosting a finely tuned model provides the freedom to modify and override the default censorship included with public domain LLMs.
# 📖 Knowledge Leaks
As described above, knowledge leaks are a concern when using a third-party LLM server, especially if you run queries that include proprietary business information.
Note:
Possible knowledge leaks flow both ways, from the prompts to the LLM and back to the querying application.
How do you prevent knowledge leaks?
In summary, use a self-hosted LLM, not a public-domain LLM, as your proprietary business knowledge base is one of its most valuable assets.
# 💰 Cost Efficiency
It is arguable whether self-hosted LLMs are cost-efficient compared to cloud-hosted LLMs. The research described in the article: "How continuous batching enables 23x throughput in LLM inference while reducing p50 latency," (opens new window) reports self-hosted LLMs are more cost-effective when latency and throughput are correctly balanced with an advanced continuous batching (opens new window) strategy.
Note:
We expand on this concept further down in this text.
# Maxing out Your RAG with Self-Hosted LLMs
![]()
LLMs devour computational resources. They require vast amounts of resources to infer and serve responses. Adding a RAG will only increase the need for computational resources as they can add over 2,000 tokens to the tokens required to answer questions for improved accuracy. Unfortunately, these extra tokens incur additional costs, especially if you are interfacing with open-source LLM APIs like OpenAI.
These figures might improve by self-hosting an LLM, using matrices and methods like KV Cache (opens new window) and Continuous Batching (opens new window), improving efficiencies as your prompts increase. However, on the other hand, most cloud-based core GPU computing platforms, like RunPod (opens new window), bill your running hours, not your token throughput: good news for self-hosted RAG systems, resulting in a lower cost rate per prompt token.
The following table tells its own story: Self-hosted LLMs combined with RAG can provide cost-efficiency and accuracy. To summarize:
- The cost drops to only 10% of
gpt-3.5-turbowhen maxed out. - The
llama-2-13b-chatRAG pipeline with ten contexts only cost $0.04 for 1840 tokens, one-third of the cost ofgpt-3.5-turbowithout any context.
Note:
See our first RAG blog post (opens new window) for further details on performance gain with RAG.
Table: Total Cost Comparison in US Cents
| # Contexts | Avg Tokens | LLaMA-2-13B Accuarcy Gain | llama-2-13b-chat @ 1 thread | llama-2-13b-chat @ 8 threads | llama-2-13b-chat @ 32 threads | gpt-3.5-turbo |
|---|---|---|---|---|---|---|
| 0 | 417 | +0.00% | 0.3090 | 0.0423 | 0.0143 | 0.1225 |
| 1 | 554 | +4.83% | 0.3151 | 0.0450 | 0.0166 | 0.1431 |
| 3 | 737 | +6.80% | 0.3366 | 0.0514 | 0.0201 | 0.1705 |
| 5 | 1159 | +9.07% | 0.3627 | 0.0575 | 0.0271 | 0.2339 |
| 10 | 1840 | +8.77% | 0.4207 | 0.0717 | 0.0400 | 0.3360 |
# Our Methodology
We used text-generation-inference (opens new window) to run an unquantized llama-2-13b-chat model for all evaluations in this article. We also rented a cloud pod with 1x NVIDIA A100 80GB, costing $1.99 per hour. A pod of this size can deploy llama-2-13b-chat. Notably, every figure uses the first 4th-quantile as its lower bound and the third 4th-quantile as its upper bound, visually representing the spread of data using box plots.
Note:
Deploying models with 70B requires more available GPU memory.
# Pushing LLM-Throughput to Its Limit
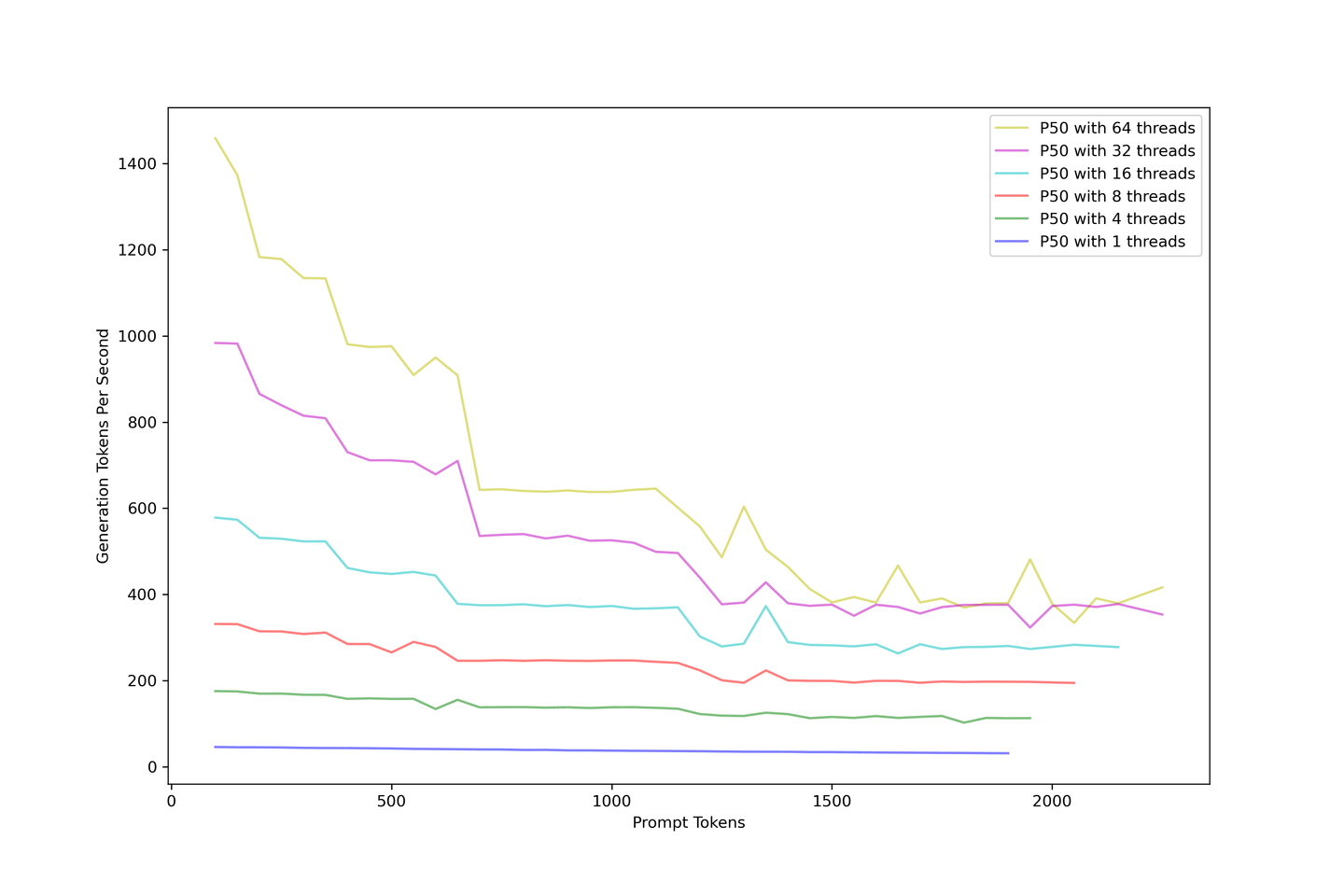
The overall throughput should be the first thing to consider. We overloaded the LLM from 1 to 64 threads to simulate many simultaneous incoming queries. The image below describes how the generation throughput drops with larger prompts. The generation throughput converged around 400 tokens per second, no matter how you increase the concurrency.
Adding prompts reduces the throughput. As a solution, we recommend using an RAG with less than 10 contexts to balance accuracy and throughput.
# Measuring Boot Time for Longer Prompts
Model responsiveness is critical to us. We also know that the generation process for casual language modeling is iterative. To improve the model’s response time, we cached the results from the previous generation to reduce the computation time with KV Cache. We call this process “booting” when generating an LLM using KV Cache.
Note:
You will always need to compute keys and values for all input prompts at the very beginning of the process.

As we increased the prompt length, we continued to evaluate the model's boot time. The following chart uses a log scale to illustrate the boot time.
The following points pertain to this chart:
- Boot times with under 32 threads are acceptable;
- The boot time of most samples is below 1000 ms.
- The boot time drastically rises when we push the concurrency up.
- The examples using 64 threads start above 1000ms and end at around 10 seconds.
- That is way too long for users to wait.
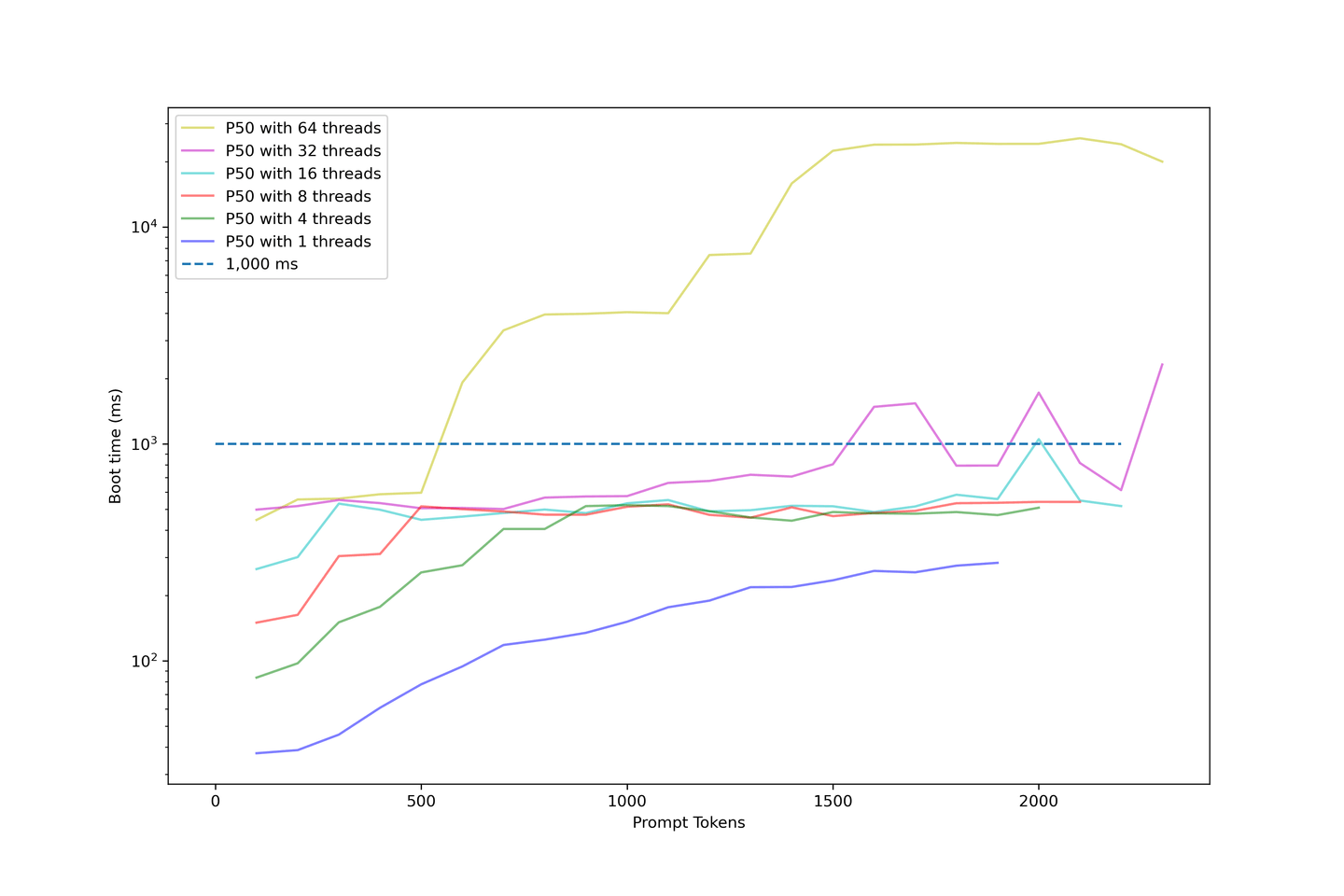
Our setup shows an average boot time of around 1000ms when the concurrency is under 32 threads. Therefore, we do not recommend overloading the LLM too much, as the boot time will become ridiculously long.
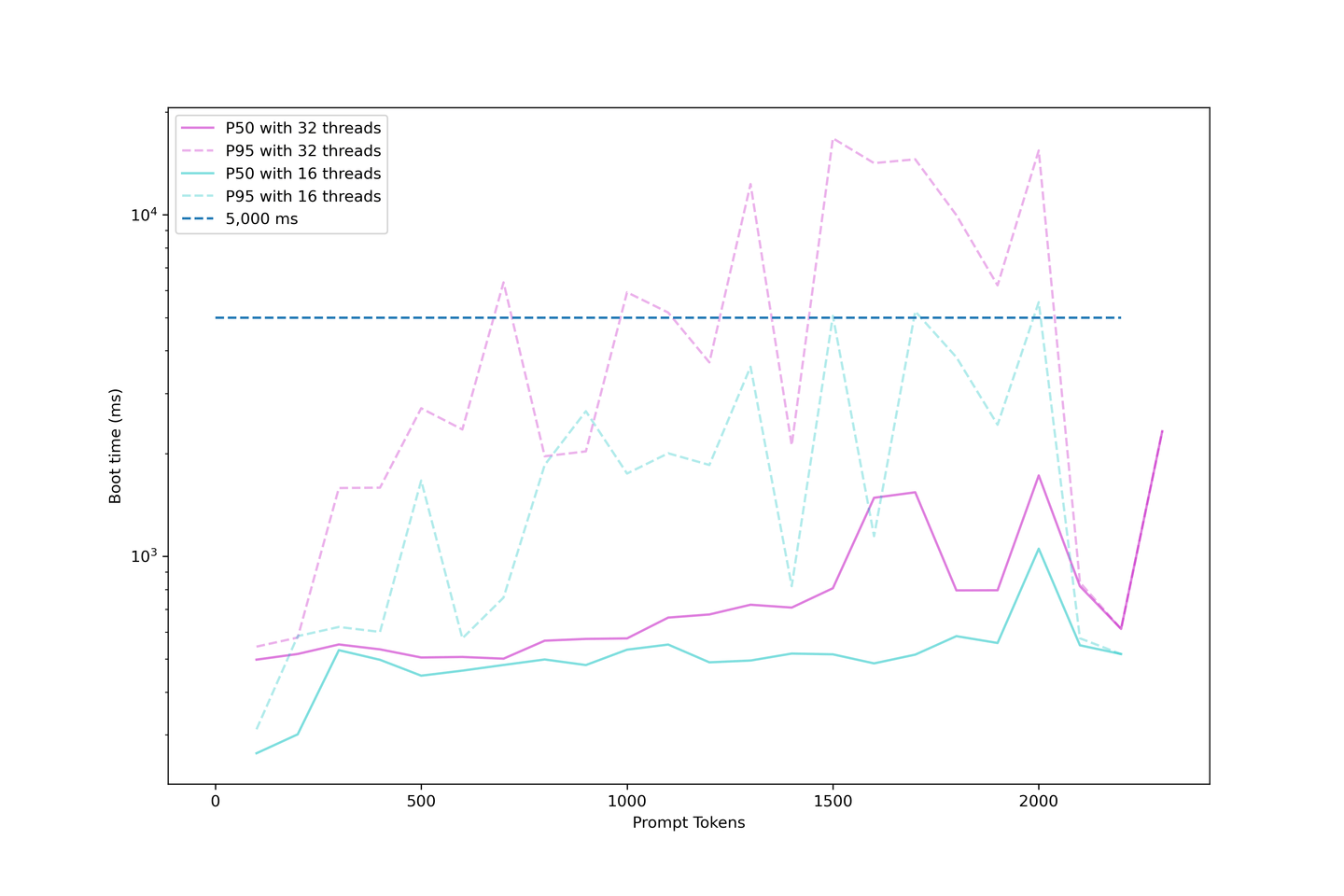
# Evaluating the Generation Latency
We know that LLM generation with KV Cache can be categorized as boot time and generation time; we can evaluate the actual generation latency or the time it takes for the user to wait to see the next token in the application.
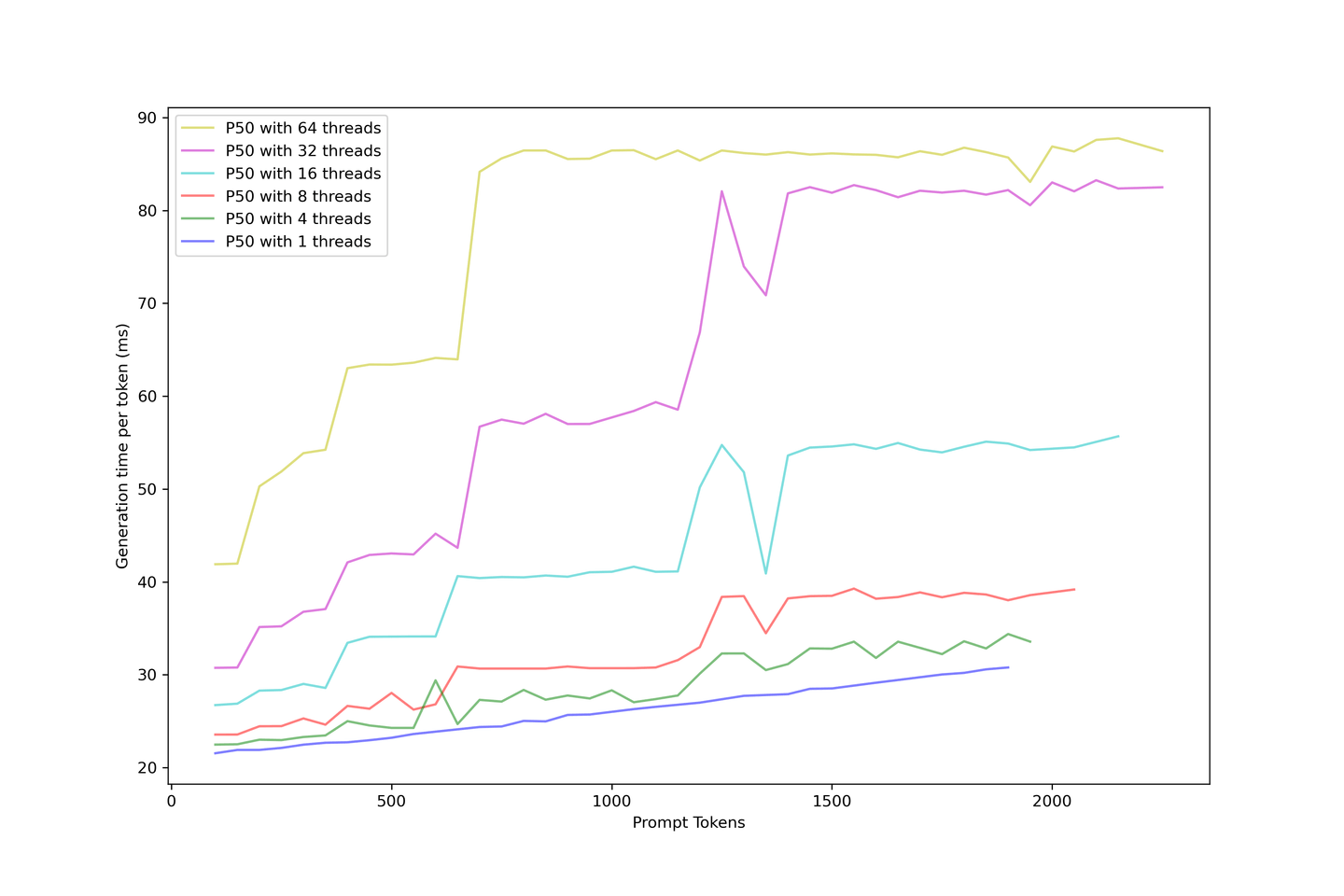
Generation latency is more stable than the boot time because larger prompts in the boot process are hard to place in a continuous batching strategy. So, when you have more requests simultaneously, you must wait until the previous prompts are cached before the next token is displayed.
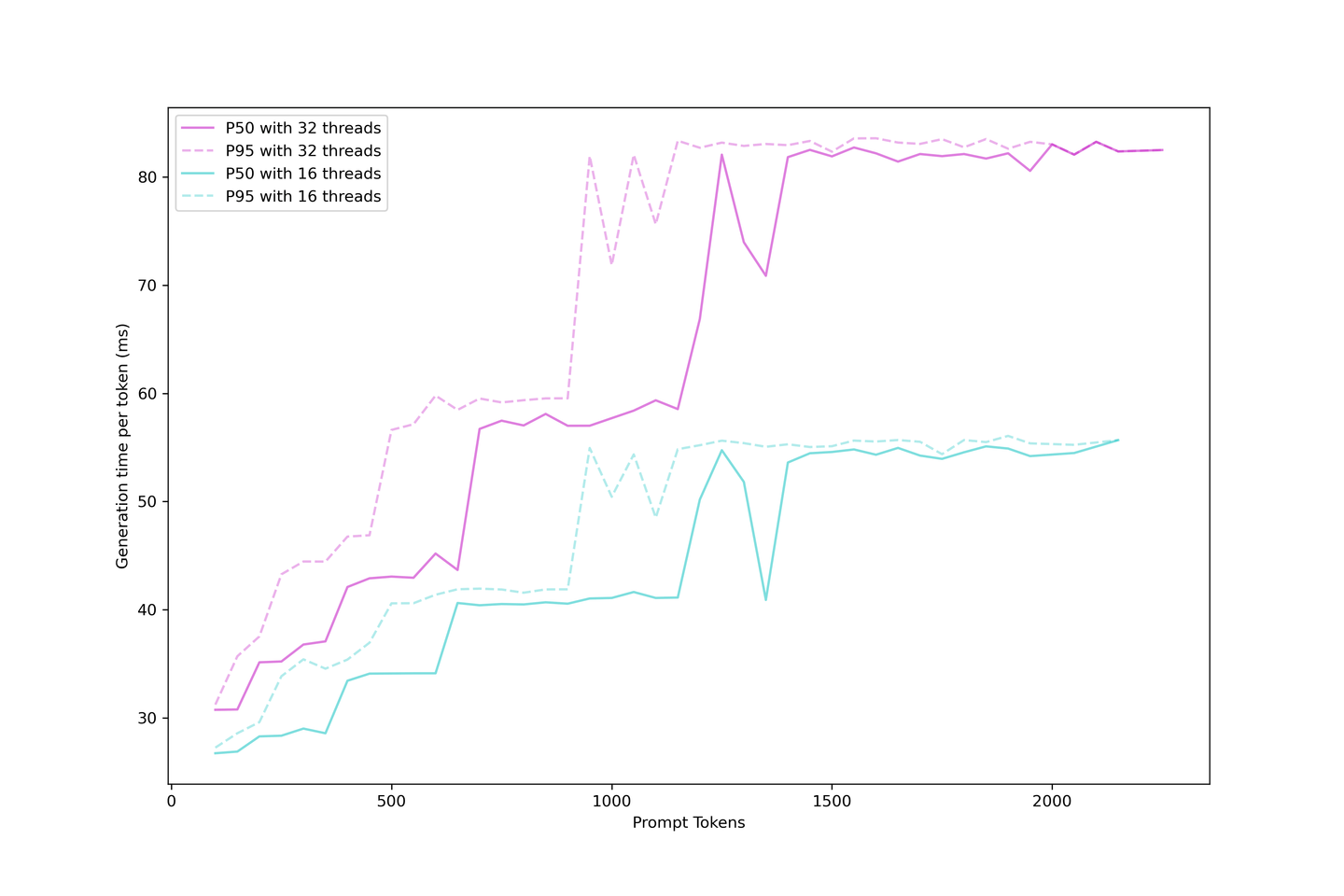
On the other hand, generation is much simpler once the cache is built as the KV cache shrinks the number of iterations, and generation is scheduled once a place is available in the batch. Latency rises at different steps, with these steps arriving earlier with bigger prompts, and the batch is saturated. More requests will soon exhaust the LLM, increasing the limit while serving more requests.
It is reasonable always to expect a generation latency under 90ms and even around 60ms if you don't push too hard on contexts and concurrency. Consequently, we recommend five contexts with 32 concurrency in this setup.
# Comparing the Cost of gpt-3.5-turbo
We are very interested in what this solution costs. So, we estimated the cost using the data collected above and created the following cost model for our pipeline:
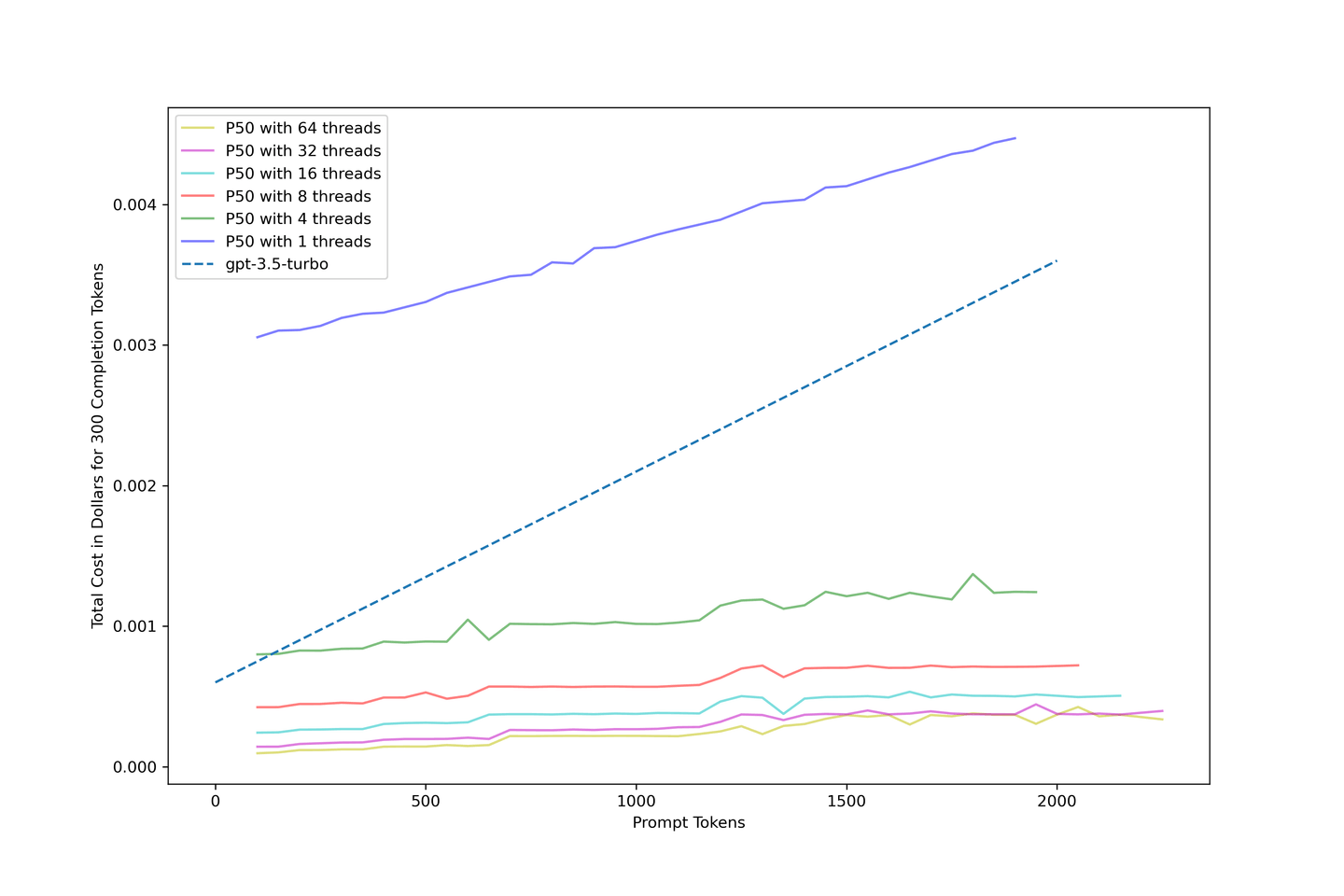
Using KV cache and continuous batching enhances system cost-efficiency, potentially reducing costs to a tenth of gpt-3.5-turbo with the right setup. A concurrency of 32 threads is advised for optimal results.
# What's Next?
The last question that we ask is:
What can we learn from these charts and where to go from here?
# Balance Between Latency and Throughput
There is always a trade-off between latency and throughput. Estimating your daily usage and your user's tolerance for latency is a good starting point. To maximize your performance per dollar, we recommend you expect 32 concurrency on 1x NVIDIA A100 80GB with llama-2-13b or similar models. It gives you the best throughput, relatively low latency, and a reasonable budget. You can always change your decision; remember always to estimate your use case first.
# Model Fine-Tuning: Longer and Stronger
You can now fine-tune your model with RAG systems. This will help the model to get used to long contexts. There are open-sourced repositories that tune LLMs for a longer input length, such as Long-LLaMA (opens new window). Models fine-tuned with longer contexts are good in-context learners and perform better than models stretched by RoPE rescaling (opens new window).
# Pairing MyScale With a RAG System: Inference vs. Database Cost Analysis
By pairing MyScale and RunPod's 10 A100 GPUs with MyScale (vector database), you can easily configure a Llama2-13B + Wikipedia knowledge base RAG system, seamlessly catering to the needs of up to 100 concurrent users.
Before we conclude this discussion, let's consider a simple cost analysis of running such a system:
| Recommended Product | Suggested Specs | Approx Cost/Month (USD) |
|---|---|---|
| RunPod | 10 A100 GPUs | $14,000 |
| MyScale | 40 million vectors (records) x 2 replicas | $2,000 |
| Total | $16,000 |
Note:
- These costs are an approximation based on the cost calculations highlighted above.
- Large-scale RAG systems significantly improve LLM performance with less than 15% additional cost in vector database service.
- The amortized cost for vetor database will be even lower as the number of users increases.

# In Conclusion...
It is intuitive to conclude that extra prompts in RAG cost more and are slower. However, our evaluations show this is a feasible solution for real-world applications. This evaluation also examined what you can expect from self-hosted LLMs, evaluating this solution's cost and overall performance and helping you build your cost model when deploying an LLM with the external knowledge base.
Finally, we can see that MyScale's cost-efficiency makes RAG systems much more scalable!
Therefore, if you are interested in evaluating the QA performance of RAG pipelines, join us on discord (opens new window) or Twitter (opens new window). And you can also evaluate your own RAG pipelines with RQABenchmark (opens new window)!
We will keep you posted with our newest findings with regard to LLMs and vector databases!



