
This article is based on the keynote speech given by MyScale CEO at The AI Conference 2023 (opens new window).
# Vector Databases + LLMs is a Key Stack to Build GenAI Applications
In a world of rapidly advancing AI technologies, the fusion of Large Language Models (LLMs) like GPT and vector databases has emerged as a critical part of the infrastructure stack used to develop cutting-edge AI applications. This groundbreaking combination enables the process of processing unstructured data, paving the way for more accurate results and real-time access to up-to-date information. Many models, such as OpenAI’s GPT, Bard, Anthropic, and open-source models like LLaMA, have revolutionized how we solve problems.
However, LLMs present severe limitations when employed for real-world use cases. Firstly, they may lack specific or up-to-date information that was not part of their training data, leading to a phenomenon known as hallucination or information limitation, where the model generates incorrect or strange responses.
While fine-tuning adjusts the LLM’s behavior, vector databases are key to solving information limitation (or hallucination) by enhancing the model’s knowledge. That’s why LLM + vector databases have become the key stack for building generative AI applications.
# The Dilemma: Convenience vs. Vector Performance
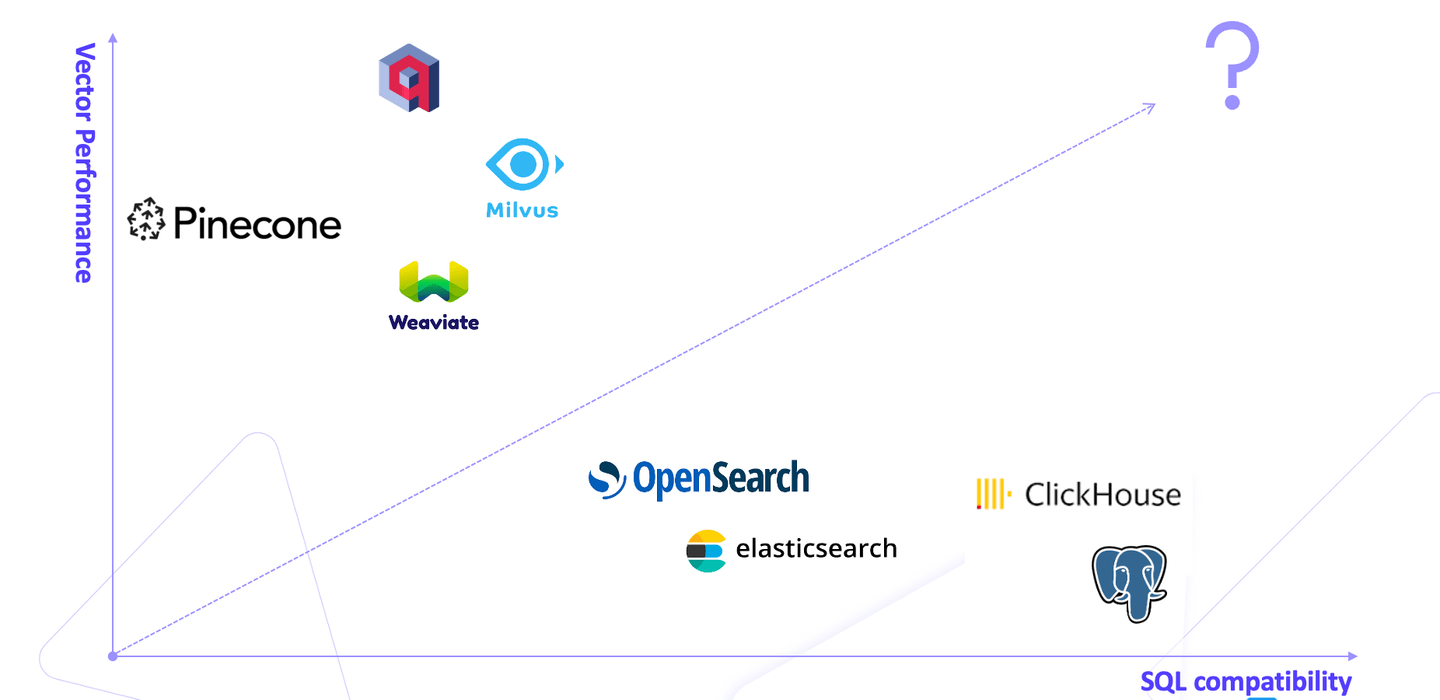
The market is brimming with vector databases, each falling into one of two categories: specialized vector databases like Pinecone, offering high vector performance, and relational databases like PostgreSQL, offering convenience. This plunges users into a dilemma, a battle between the reliability of relational databases and the high-performance vector operations of specialized ones.
Imagine a user is reliant on PostgreSQL for its convenience and reliability but needing to perform vector searches. However, it is inconvenient and cumbersome to interface between PostgreSQL and Pinecone, resulting in increased complexity and potential data consistency issues.
# The Ideal Solution: MyScale - a Relational Vector Database
This is where MyScale (opens new window) comes into play as a solution that bridges the gap between traditional relational databases and high-performance vector databases. Unlike proprietary vector databases such as Milvus, Qdrant, and Weaviate, MyScale is built on the open-source SQL-compatible ClickHouse database, allowing users to run vector searches with SQL, thus eliminating the inconvenience of moving between different types of databases.
It is widely assumed that relational databases cannot provide performance that matches that of vector databases. MyScale breaks this myth. It offers a balanced, optimized, and streamlined solution for users facing such a dilemma. It outperforms specialized vector databases while retaining all the benefits of relational databases.

This is just the beginning!
Under the hood, MyScale integrates structured data and vectors seamlessly with a series of algorithmic and systems engineering innovations. Unlike other vector databases that rely on IVF or HNSW as their core algorithm, we developed our own algorithms. We help users vectorize and search both structured data and vector embeddings with very high performance.
# Use Cases: Unlocking MyScale's Potential
Let's now consider the following two use cases describing the benefits of SQL+vector:
# 1. BitCap — MyScale Allows Users to Run Complex Queries
The first use case is from BitCap, a prominent digital assets management company. They needed to conduct vector searches, filtering on specific data types, for example, timestamps, over a substantial amount of data.
In this scenario, the scale of data was immense, and BitCap needed the ability to use SQL syntax for their precise filter searches. It's worth noting that, not just vector search, filter search performance is absolutely critical for many real-world applications. Additionally, BitCap needed support for multiple data types, including dates and strings, to meet their requirements effectively.

Moreover, BitCap had additional requirements:
- Integrate our solution with Langchain
- Provide for self-queries and other demanding applications
MyScale enabled them to meet all their requirements in a single query. So, compared to the other alternatives, MyScale is the best choice for BitCap because it's very easy to use with high performance.
# 2. MyScale Helps Academic Users Achieves Best Cost-Effectiveness
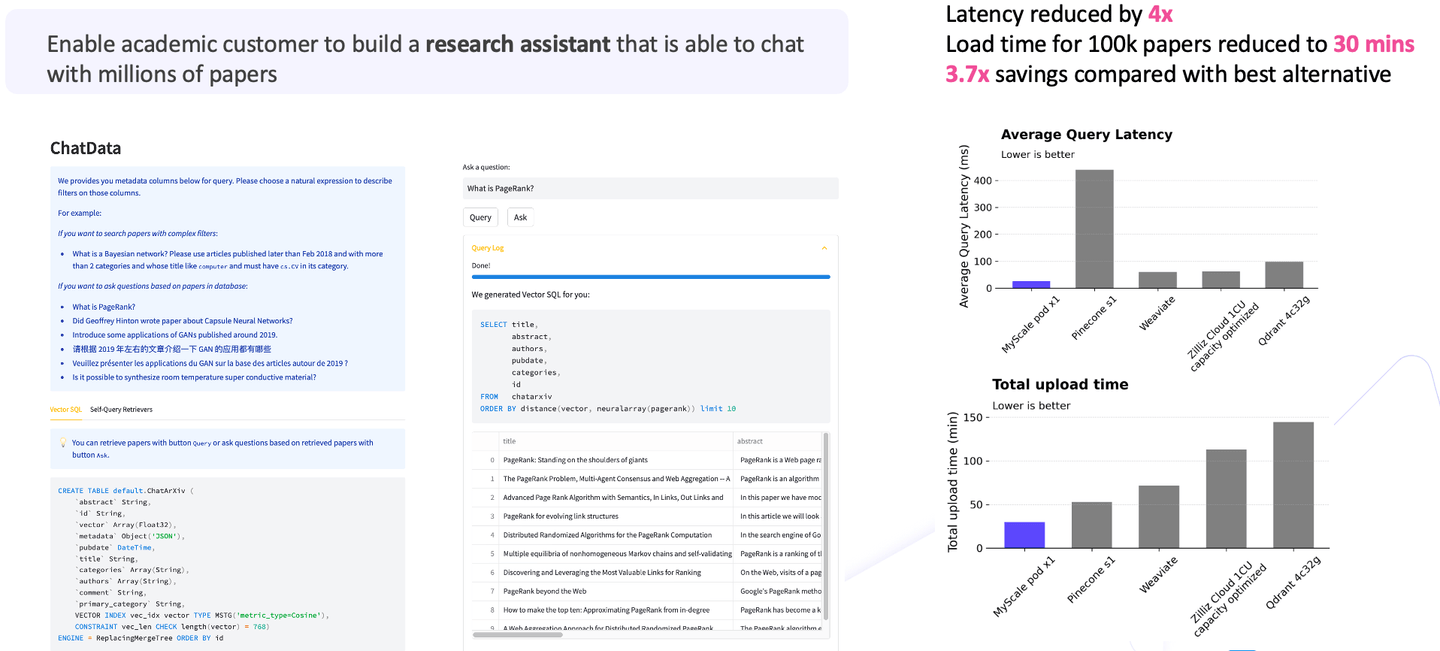
In the second use case, we helped academic users create a research assistant to chat with millions of papers. The scenario involved ingesting one million research papers and enabling question-answering capabilities using these papers.
Given the vast data volumes, if you compare the costs, you will find that the large language models constitute about eighty to ninety percent of the overall cost. At the same time, vector search forms a vital part of the initial requirements. So, when vector search is added into the equation, compared with alternatives (opens new window), MyScale reduces the latency by 4x and the load time to 30 minutes; overall, the total cost savings are more than 3x than that of the other options.
As you can see from the diagram, MyScale boasts high performance, low latency, and outstanding cost-effectiveness. These achievements are particularly remarkable when dealing with large-scale applications.
From these use cases, it becomes clear that a relational database is required to address this challenge effectively. And equipping it with the best vector functionality unlocks a world of possibilities.

# The Potential for Performance, Cost, and Quality Optimization is Enormous
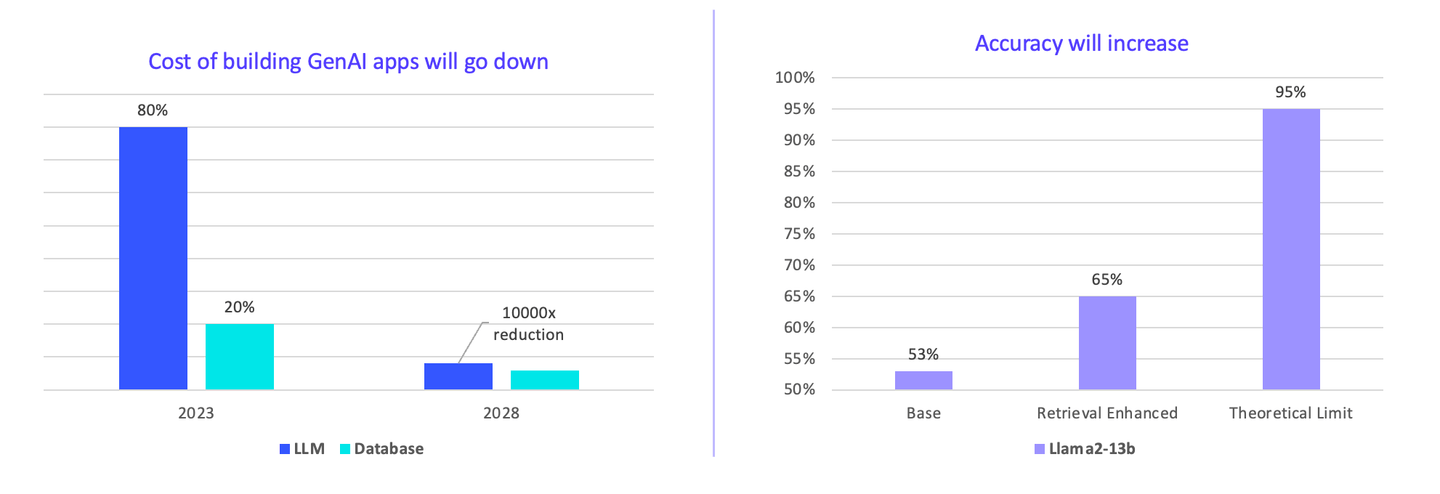
I think enterprises currently overpay for AI. LLMs constitute 80-90% percent of the total cost. However, in the future, the cost of building applications will go down. We can drive the price down faster by consensus. It can be seen that there is 10000x room for a reduction in costs.
How is this possible?
- Hosting your own models instead of using commercialized APIs reduces the costs 10x,
- Advanced caching systems contribute another 10x,
- Other techniques jointly contribute 100x.
Not everyone knows about these techniques.
Furthermore, vector search accuracy may increase. Currently, the base model is Llama2, and with a vector database plugin, the accuracy significantly increases from 53% to 65%.
Note:
The database is already in the training set, but using a vector database dramatically increases performance.
The theoretical limit is much higher if we use bigger vector databases. The cost is much lower compared with using GPUs to serve LLMs alone. We think this is a future direction to go.
# The Future
Let's look forward to the future:
SQL+vector relational databases represent a groundbreaking approach to empowering GenAI applications. MyScale bridges the gap between relational and vector databases, offering both convenience and high-performance capabilities, and demonstrates that relational databases can outperform specialized databases in terms of vector performance while retaining all the benefits of SQL. By redefining possibilities and reducing costs, MyScale paves the way for a future where AI applications are more accessible and powerful than ever before. And there is vast room for cost reduction and accuracy improvement, which is the direction for us to go. If you have more questions or are interested in our offering, don't hesitate to contact us Discord (opens new window) or follow MyScale on Twitter (opens new window).
Thanks!



