
MyScale is a high-performance, SQL-enabled vector database fully hosted on AWS. MyScale’s strength lies in its full support for standard SQL syntax and performance levels that match or even surpass those of specialized vector databases.
The function and purpose of this article is to explore how MyScale leverages the AWS infrastructure stack to build a robust, stable, and efficient cloud database.
# Vector Databases & Embeddings
But first, let’s begin by describing vector databases, vector embeddings, and how specialized vector databases store vector embeddings or mathematical representations of objects like documents, capturing their semantic relationships and contextual information.
# Vector Databases
Vector databases can be broadly categorized into two main types:
- Specialist vector databases such as Pinecone, Weaviate, and Qdrant, specifically designed to store vectors
- General-purpose SQL or NoSQL database products, with popular SQL databases like PostgreSQL supporting vector indexing and searching through plugins like
pgvector
Note:
Multiple open-source databases, like ClickHouse, Redis, Elasticsearch, and Cassandra, have recently added native support for vector indexing.
While specialized vector databases are often assumed to provide better search performance, general-purpose databases that support vector search offer more holistic data management and structured data query capabilities. MyScale, based on the open-source OLAP database, ClickHouse, however, merges both vector search and structured data query capabilities into one solution.
The MyScale team developed an advanced vector indexing algorithm known as Multi-Scale Tree Graph (MSTG). This algorithm allows for fast search performance, high data density as well as fast insertion speed. In combination with the columnar storage and fast structured data analytics provided by ClickHouse, MyScale offers significantly greater cost-effectiveness compared to specialized vector databases. These benefits are clearly illustrated in the graph that follows.
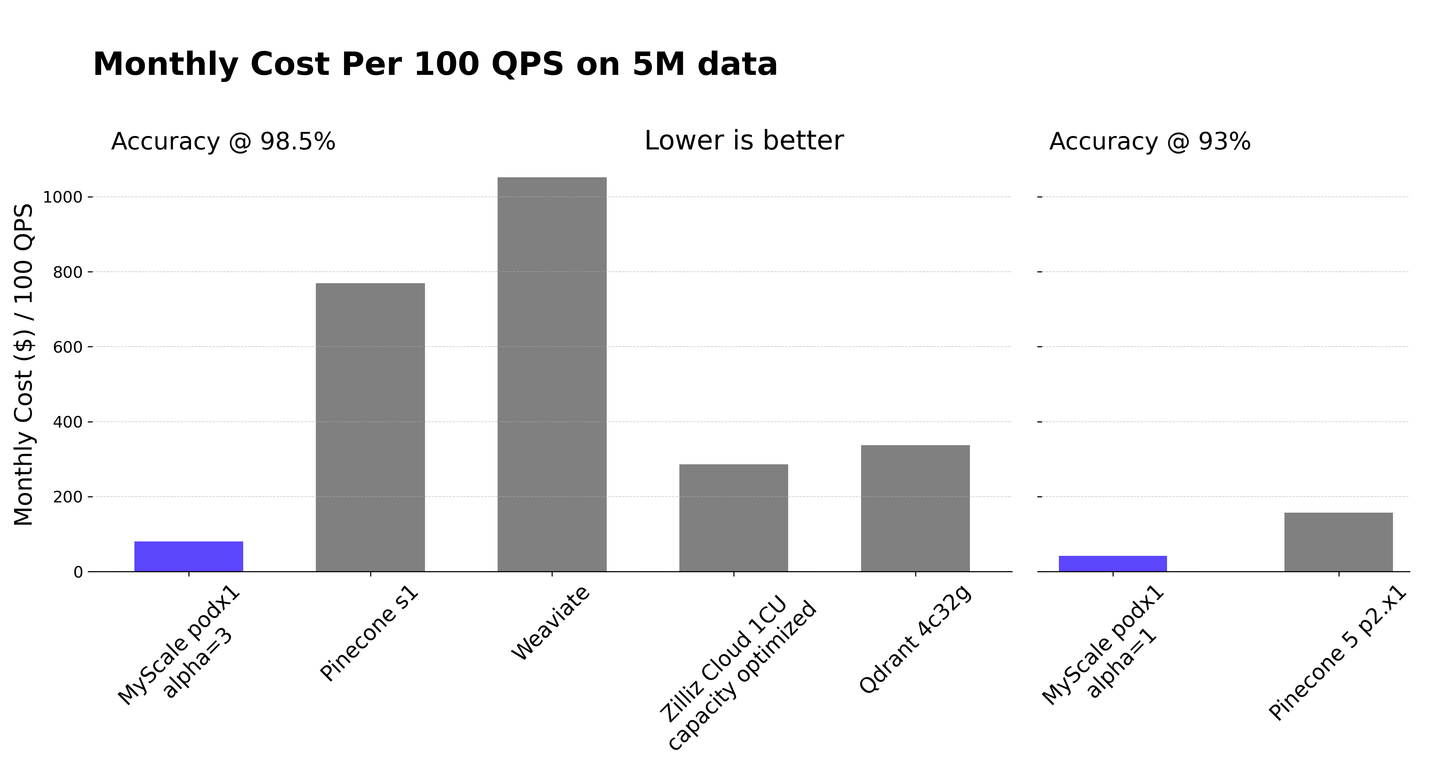
Source: Outperforming Specialized Vector Databases with MyScale
# Vector Embeddings
Vector embeddings are ubiquitous and are the backbone of numerous machine learning and deep learning algorithms, finding their application in a wide range of fields, from search engines to intelligent assistants. Machine learning and deep learning techniques typically transform unstructured data, such as text, images, audio, and video, into vector embeddings. These embeddings can then be searched for semantic relevance using vector similarity search techniques.
# Architectural Overview of MyScale
MyScale is a database service that fully leverages the AWS cloud platform, including the following AWS products, among others:
- EC2 - cloud virtual servers
- EKS - container orchestration
- S3 - object storage
- NLB - load balancing
By capitalizing on the robust underlying infrastructure provided by AWS, we have rapidly developed MyScale’s cloud service offerings.
MyScale’s cloud service architecture is designed in three layers, each a Kubernetes cluster:
- The global control plane
- The regional control plane
- The regional data plane
As the following diagram describes, the global control plan houses the cloud service’s business systems responsible for organization, user management, and overall usage statistics.
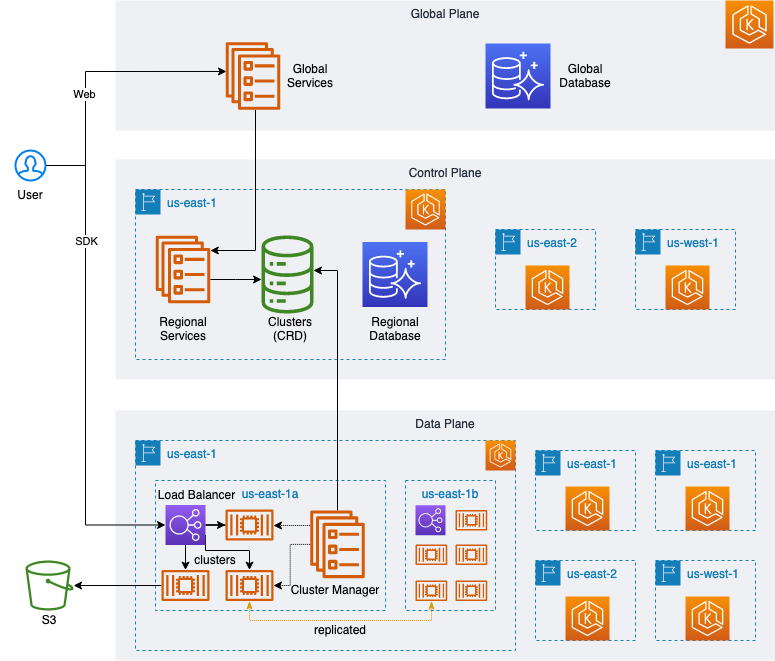
All MyScale’s servers are deployed on AWS’s managed Kubernetes service, EKS, providing a secure, highly available, and scalable Kubernetes environment. As a result, MyScale can fully utilize Kubernetes’ features, like service discovery, load balancing, auto-scaling, and security isolation.
Moreover, MyScale leverages Kubernetes’ namespace features in the data plane to ensure user cluster isolation. Each MyScale database cluster corresponds to a unique Kubernetes namespace, minimizing the impact of clusters on each other and making sure each cluster has its own dedicated namespace containing database nodes, load balancing services, and metadata storage services.
# Leveraging AWS Services
We use an EC2 instance with local NVMe-based SSD disks to deploy the MyScale database. Unlike most vector databases that opt for a purely in-memory HNSW vector indexing algorithm, MyScale’s MSTG algorithm allows vector data to be cached on local NVMe SSD disks, providing users with high-performance vector searches while significantly saving on memory usage.
Furthermore, we utilize Crossplane to deploy and manage MyScale cloud services hosted on AWS EC2 and EKS. Our cloud resources are configured in a declarative, unified, and automated way with Crossplane, significantly improving accuracy and productivity.

# Data Security with Teleport
MyScale uses Teleport, an advanced remote access management system for data security. Teleport provides a secure connection to our Kubernetes cluster, facilitating system security and operational ease. It also offers comprehensive auditing capabilities with detailed logging of all sessions and events, useful for security analysis and compliance requirements.
# In Conclusion
MyScale, a vector database hosted on AWS, is a powerful tool for handling structured and unstructured data. Based on ClickHouse and integrating the proprietary Multi-Scale Tree Graph (MSTG) vector indexing algorithm, MyScale offers robust data management and structured data querying capabilities. It is cost-effective and highly suited for AI-driven scenarios such as image retrieval, video analysis, and natural language understanding.



