
Vector databases offer lightning-fast retrieval on similar objects stored in between billions of records. However, you may also be interested in searching for related objects that match a specific set of conditions, known as filtered vector search. With help from MyScale (opens new window), you can boost your filtered vector searches to a new level.
Most vector indexes or vector stores work as dedicated index services. They support a partial filtered vector search implementation of MongoDB query and projection operators (opens new window), where you can input a dictionary of conditions.
Supported data types and comparators differ between implementations, but most interfaces only support strings, integers on equals, and basic value comparisons. Unlike databases, these vector indexes are not designed to handle complex data types and conditions. As a result, you need an external database solution to store this data, but you cannot use this data to perform filtered vector searches. This solution works, but it is complicated and has limitations.
Actually, there can and should be a better solution. Vector search can be integrated with a database to make it more robust than it is now. MyScale can simultaneously handle filtered vector search with complex conditions and data types using the standard WHERE clause.
# Pre-Filtering and Post-Filtering
Filtered vector search implementations can be categorized into two types:
- Pre-Filtered Vector Search
- Post-Filtered Vector Search
For instance:
Imagine you have a table containing the chat history for users Jack, Jan, and John, and you would like to use a filtered vector search query to retrieve Jack’s chat history similar to the given query vector.
Note:
Each record has a user mark and feature vector—for simplicity, we turn vectors into numbers.
The following image describes both a NoSQL and SQL query retrieving Jack’s chat history:
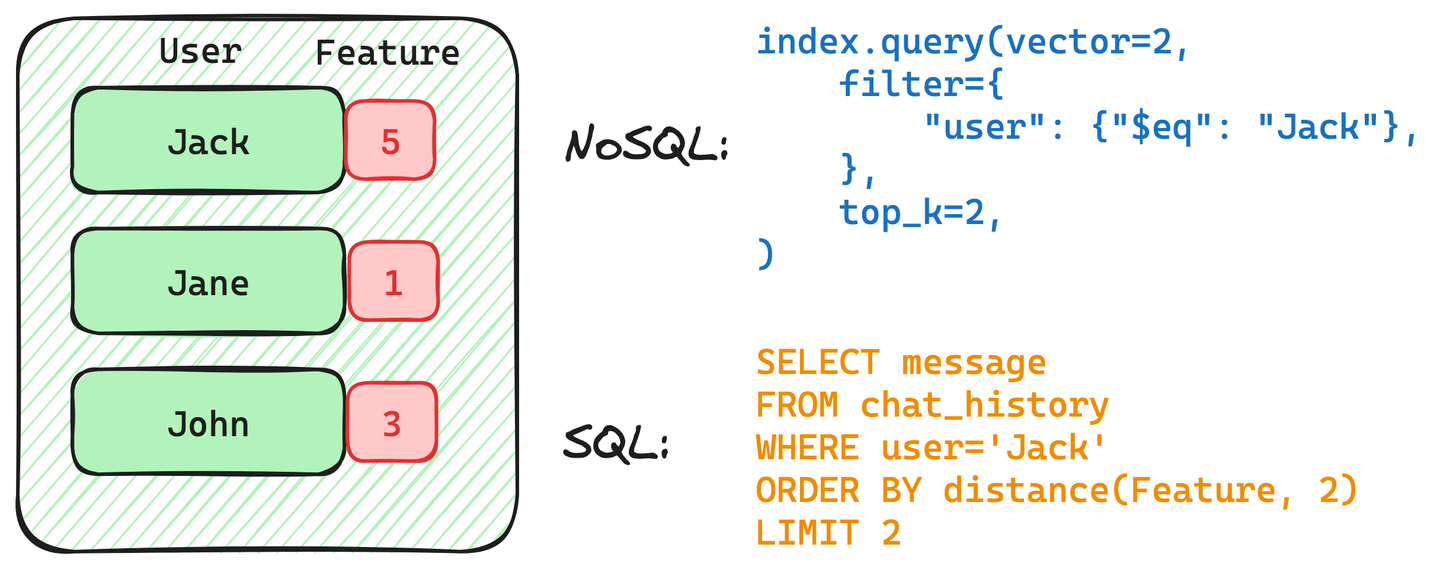
Both of those queries contain a filter on the user Jack. However, this filter can be structured differently, depending on the implementation.
1. Pre-Filtered Vector Search: For the pre-filtered vector search, the engine will first scan the data and only retain records that match the given filter condition. Once this scan is complete, the engine will perform the vector search on the pre-filtered candidates.
2. Post-Filtered Vector Search: On the other hand, the post-filtered vector search will first perform the vector search and then filter these results based on the given filter condition.
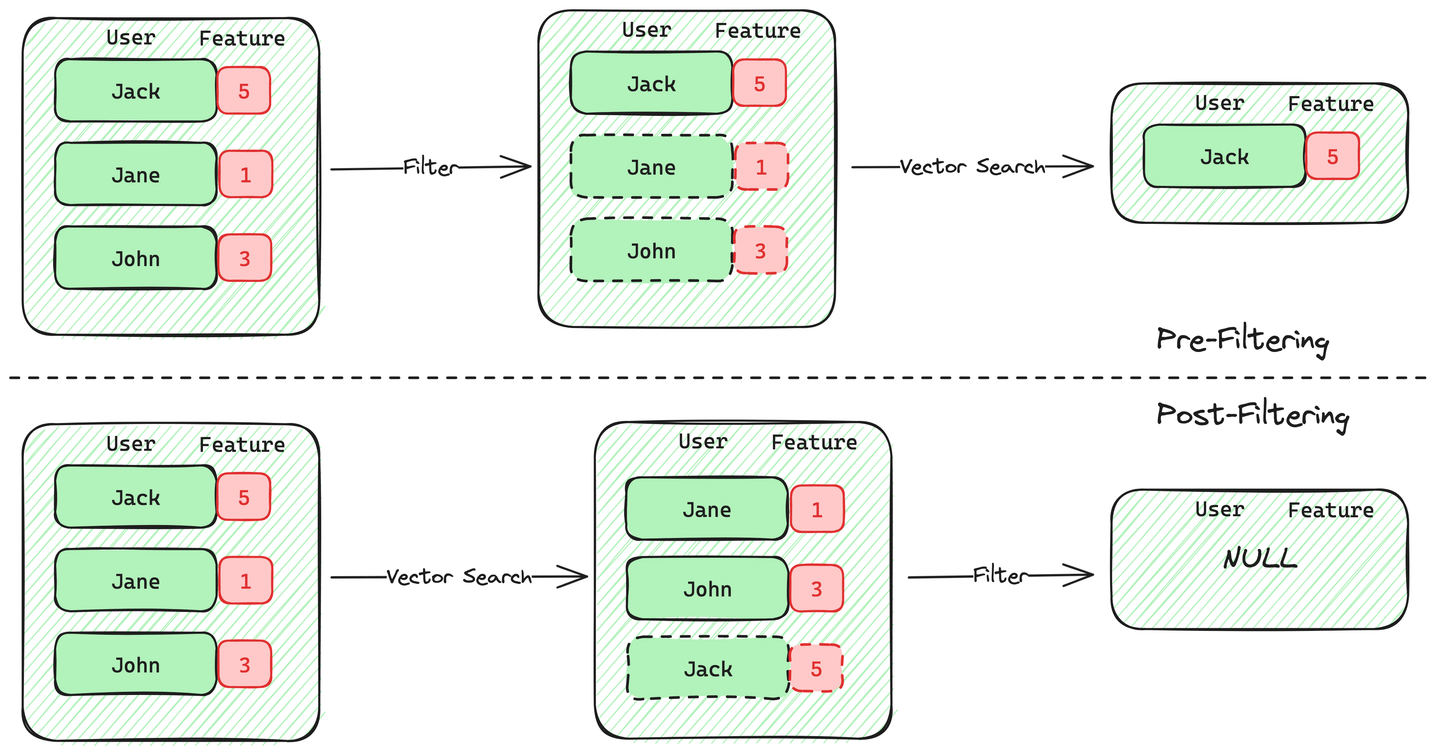
Between these two methods, pre-filtering is better than post-filtering in accuracy and meets what we expect from a filtered vector search. Most vector databases support pre-filtering with vector search. However, this pre-filtering doesn't come for free. However, pre-filtering isn’t free, increasing computation and dragging the filtered vector search’s performance. Most implementations suffer from either performance or filter limitations, such as data storage and supported comparator limits.
MyScale uses a column-based storage engine (opens new window) adapted from the ClickHouse MergeTree engine (opens new window), which is super-fast on conventional filters, significantly boosting first-stage filtering and making the filtered vector search faster than other implementations. Furthermore, you can use a simple SQLWHERE clause to define filters on any column in your table.
# What You Can Do with the WHERE Clause in MyScale
As MyScale is developed on top of ClickHouse (opens new window), it offers precisely the same functionality as ClickHouse.
For instance:
| Method | Others | MyScale |
|---|---|---|
| eq / neq | ✅ | ✅ |
| ge / gt / lt / le | ✅ | ✅ |
| include / exclude | ✅ | ✅ |
with string pattern match LIKE | ❌ | ✅ |
| Timestamps/Geo-Data/JSON | ❌ | ✅ |
| with function | ❌ | ✅ |
| with arrayFunction (opens new window) | ❌ | ✅ |
| with subqueries | ❌ | ✅ |
Let’s look at several examples highlighting what MyScale’s WHERE clause is capable of.
Note:
You can find the code for these examples in our Colab or GitHub spaces.
![]()
![]()
Note:
Refer to the ClickHouse’s Official Documentation (opens new window) for more information on data types and functions.
# Common Value Comparison: =, !=, >, <, >=, <=
Most vector index solutions support these operations on strings or numbers. In MyScale, you can write value comparisons with:
WHERE column = value
Where the column can be any column name in the table, and the operation can be any of =, !=, >, <, >=, <=.
Note:
The column type and value must be the same.
If you have multiple conditions to add to the WHERE clause, use logical operators like AND to connect them:
WHERE column_1 = value_1 AND column_2 >= value_2
# Common Set Operators: Include, Exclude
MyScale also supports set operations like IN and NOT IN:
WHERE column IN (value_1, value_2, ...)
This is useful when you want to select a set of rows. Similarly, you can use logical operators to connect these set operators with other conditions.
# Operators for Arrays
You can check if an element is in an array with the has function:
WHERE has(column, value_1)
# String Pattern Matching
You can match string patterns in MyScale with the keyword LIKE:
WHERE column_1 LIKE '%value%'
This condition matches values that contain value in column_1. This string pattern matching operator is one of of many operators offered by MySQL. Others include: NOT LIKE, match with regular expressions, and ngramSearch.
Note:
See ClickHouse's official documentation (opens new window) for more information on the LIKE operator.
# Date-Time Comparison
MyScale also includes a date-time comparison function:
WHERE dateDiff('hour', column_datetime, toDateTime('2018-01-02 23:00:00')) >= 25;
This WHERE clause refers to any rows whose column_datetime is later than the given date time for more than 25 hours. This function also supports seconds, minutes, days and months.
Note:
See here (opens new window) for more information.
# Geo-data Comparison
MyScale can handle the H3 Index (opens new window) and S2 Geometry (opens new window), powerful tools for route planning and geometry analysis.
For example, with the H3 Index, you can use the area of a hexagon to filter out geograhical data in a given area:
WHERE h3CellAreaM2(column_h3) > 1000
You can also add the distance to a specific H3 Index:
WHERE h3Distance(column_h3, value_h3) > 10
# Arbitrary Object with JSON Columns
MyScale allows you to store JSON as an object and filter on its attributes.
You can use the JSON data type to import a JSON string into a table and use the WHERE clause below to filter out results:
WHERE column_json.attr_1 = value_1
You can also filter on nested attributes as follows:
WHERE column_json.attr_1.attr_2 = value_1
Though this is an experimental feature (opens new window), it is powerful to use. We have used these objects in our LangChain (opens new window) and LlamaIndex (opens new window) vector store implementations.
# Value Functions
MyScale includes lots of column data processing functions that you can utilize in WHERE clauses, such as:
WHERE abs(column_1) > 5
You can include multiple columns in your WHERE clause:
WHERE column_1 + column_2 + column_3 > 10
# Array Functions
Array functions are really powerful, especially with our vector search. In our documentation (opens new window), we introduced array functions in MyScale for the final logit computations and gradient computations for our few-shot classifier.
ClickHouse has great documentation on array functions (opens new window).
Note:
If you still need help with array functions in MyScale, please join our discord (opens new window) and ask.
# Subquery Support
Subqueries are queries within queries. You can also write a WHERE clause with another SELECT query as follows:
WHERE column_1 IN (SELECT ... FROM another_table WHERE ...)

# Filtered Vector Search Performance
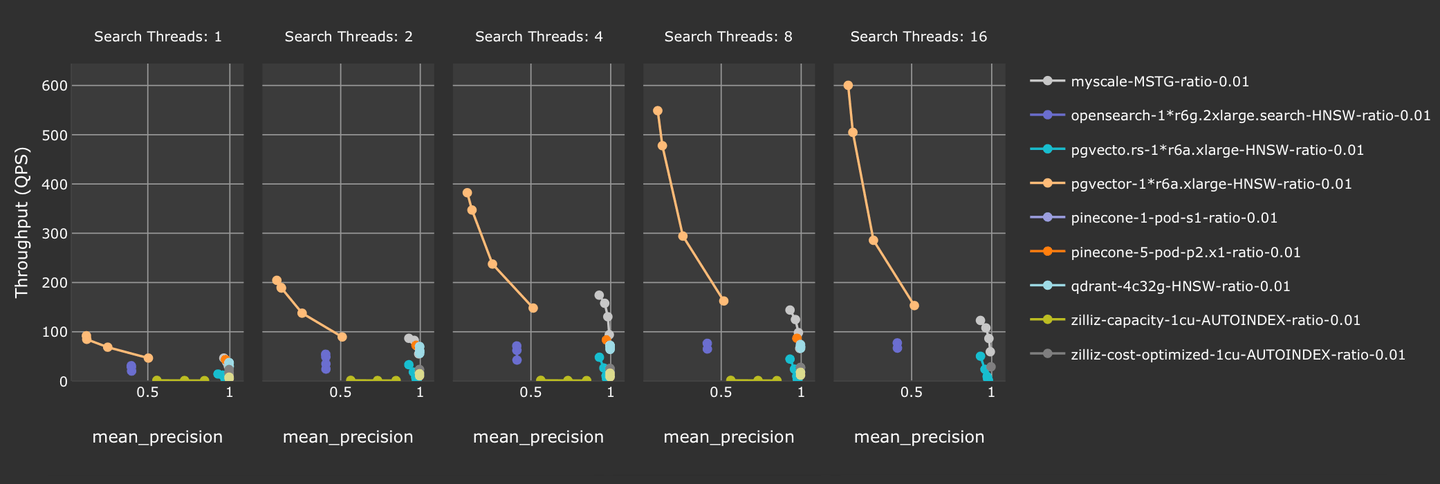
We investigated filtered vector search performance in vector-db-benchmark (opens new window). We used laion-768-5m-ip-probability where a random float is added as its filter mark during the query. We also tested popular vector database solutions against MyScale. As the following chart describes, MyScale surpasses most other vector database solutions in that we provide better accuracy with higher throughput.
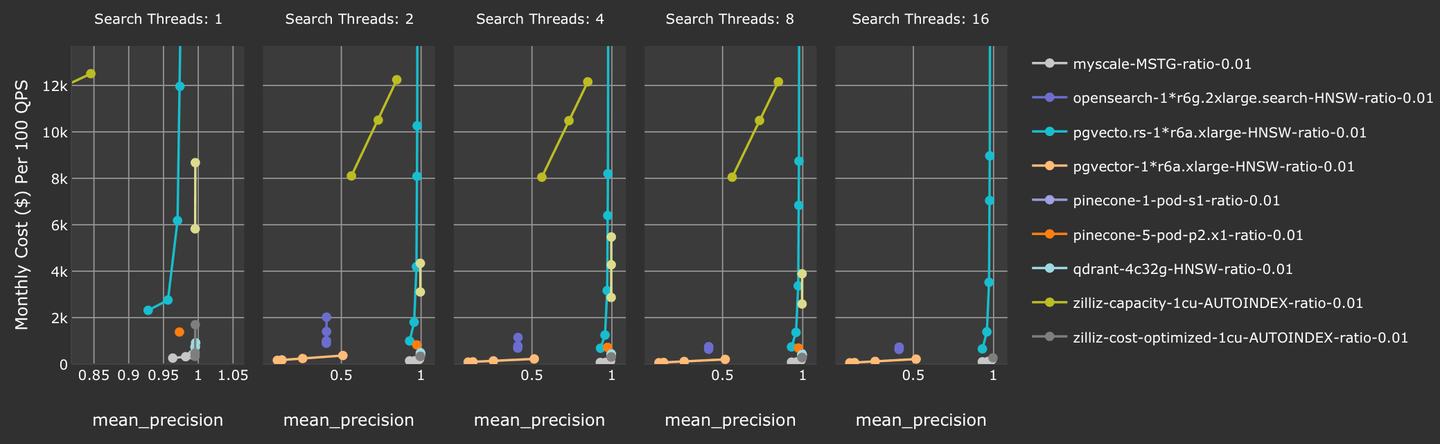
Furthermore, MyScale achieves the best cost-efficiency of all vector databases tested when accuracy >= 90%. When compared to other SQL-integrated vector databases—such as pgvector and pgvector.rs—MyScale stands out as the only SQL and vector-integrated database that achieves production-ready accuracy and throughput for filtered search.
Note:
See the following blog comparing pgvector and MyScale (opens new window) for more information.
In summary, MyScale offers better accuracy with higher throughput at a lower cost. We also support 5 million vectors with more data types and functions within our s1 pod in the product line, which is free for all registered users.
# Conclusion
Filtered search is a common type of query in vector databases that allows you to search for similar vectors or data points based on specific criteria or filters, especially when dealing with data that can be represented as vectors, such as text and image embeddings or other structured data.
MyScale embeds SQL power into AI technology; filtered search is a case in point, enabling more sophisticated and flexible querying capabilities for vector databases. By combining AI and SQL, you can perform complex data operations and searches, making extracting valuable insights, discovering patterns, and performing different analytical tasks easier.
If you are interested in how SQL can boost your AI apps, join us today on discord (opens new window) or X (opens new window).



