
Retrieval augmented generation (RAG) (opens new window)は、AIの大きな飛躍であり、チャットボット (opens new window)がユーザーとの対話を行う方法を変革しました。RAGは、リトリーバルベースの手法と生成AIを組み合わせることで、チャットボットが大規模な外部ソースからリアルタイムのデータを取得し、正確かつ関連性のある応答を生成することを可能にしました。この革新により、チャットボットの開発がより簡単かつ効率的になり、変化するデータに適応できることが保証されました。これは、カスタマーサポート (opens new window)のような分野で、タイムリーかつ正確な情報が重要であるため、非常に重要です。
しかし、従来のRAGシステムは、予約を取ったりリアルタイムのリクエストに対応したりするなど、迅速なシナリオでの迅速な意思決定に苦労しました。ここで、エージェンティックRAGが登場します。これは、自律的にデータを取得、検証、操作できるインテリジェントエージェント (opens new window)を追加することでこの問題に対処します。主にデータを取得して応答を生成する標準的なRAGとは異なり、エージェンティックRAGはAIがその場で積極的に意思決定を行うことを可能にし、迅速かつ正確な意思決定が不可欠な医療診断やカスタマーサービスなどの複雑な状況に最適です。
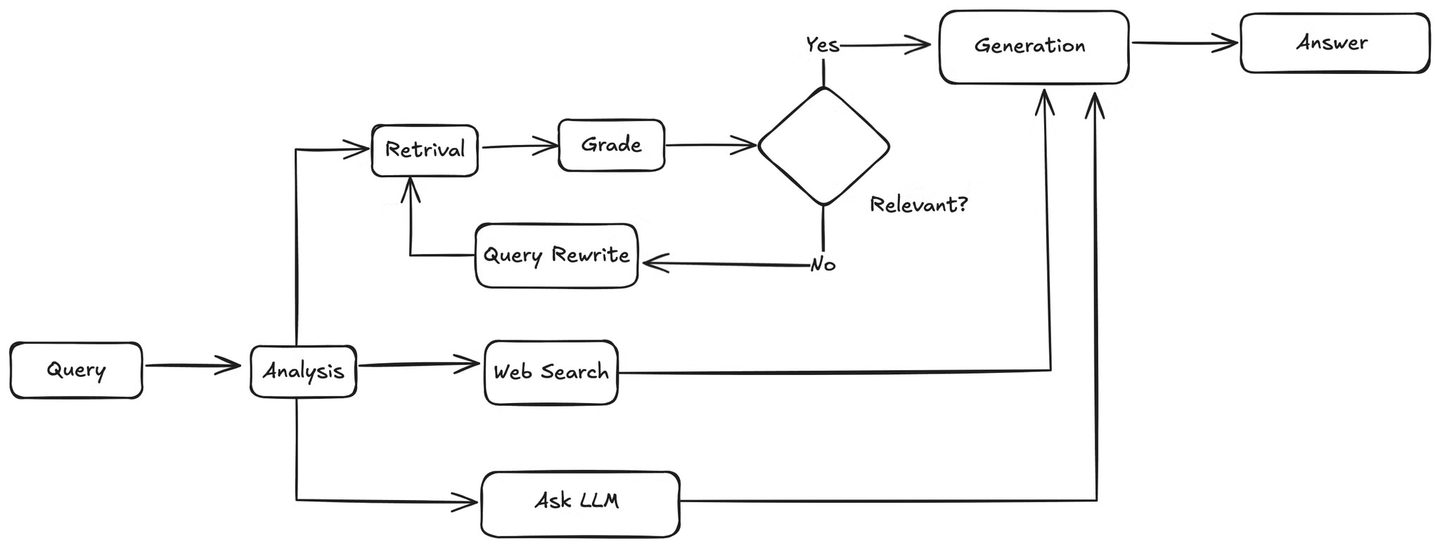
これは、今回のチュートリアルで実装する内容そのものであり、ユーザーのクエリに基づいてナレッジベース (opens new window)を使用するか、インターネット検索を実行するかを動的に判断するインテリジェントなエージェント型Q&Aシステムです。これを実現するために、いくつかのツールを統合する必要があります。
- LangChain (opens new window): このツールは、システムが言語モデルと他のツールとのやり取りを管理します。クエリに基づいて、システムが知識ベースを検索するかインターネットを検索するかを決定するのに役立ちます。
- MyScaleDB (opens new window): MyScaleDBは、知識ベースを表す埋め込みを格納するベクトルデータベースとして機能します。知識ベースに関連するクエリの場合に効率的にデータを検索するために使用されます。
- VoyageAI (opens new window): テキストから埋め込みを生成するためのさまざまな埋め込みモデルを提供し、検索とマッチングのための知識のエンコードに使用されます。
- Tavily (opens new window): ユーザーの質問に最新の情報や外部データが必要な場合にインターネットからリアルタイムの情報を取得し、システムが常に正確な回答を提供するようにします。
# 環境のセットアップ
まず、次のコマンドを実行して、必要なライブラリをインストールし、このAIアプリケーションの開発に必要なパッケージを取得します。
pip install -U langchain-google-genai langchain-voyageai langchain-core langchain-community
次に、Gemini (opens new window)(Google Generative AI)とTavily search (opens new window)を使用するために必要なAPIキーを設定します。MyScaleの場合は、クイックスタート (opens new window)ガイドに従ってください。
import os
# MyScale API credentials
os.environ["MYSCALE_HOST"] = "msc-24862074.us-east-1.aws.myscale.com"
os.environ["MYSCALE_PORT"] = "443"
os.environ["MYSCALE_USERNAME"] = "your_myscale_username"
os.environ["MYSCALE_PASSWORD"] = "your_myscale_password"
# Tavily API key
os.environ["TAVILY_API_KEY"] = "your_tavily_api_key"
# Google API key for Gemini
os.environ["GOOGLE_API_KEY"] = "your_google_api_key"
上記のコードのプレースホルダを実際のAPIキーで置き換えてください。
注意: これらのツールはすべて、機能をテストするための無料版を提供しています。したがって、各プラットフォームでアカウントを作成し、APIキーを取得してください。
# テキストの読み込みと分割
次のステップは、知識ベースのデータを準備することです。このチュートリアルでは、MyScaleDBに関する基本情報を含むデータセットを使用します。データは管理可能なチャンクに分割されており、システムが効率的に処理し、関連する情報を効率的に取得できるようになっています。
from langchain_text_splitters import CharacterTextSplitter
with open("myscaledb_summary.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(
separator="\\n\\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([state_of_the_union])
**CharacterTextSplitter**は、文字数に基づいてテキストをより小さな管理可能なチャンクに分割します。
注意: このブログのためにMyScaleに関するtxtファイルが使用されています。お好みのデータを使用してください。
# 知識ベースへのデータの追加
データをチャンクに分割した後、埋め込みを取得し、それらの埋め込みを知識ベースに保存します。このために、VoyageAIEmbeddingsを使用してテキストのチャンクの埋め込みを生成し、MyScaleDBに保存します。
from langchain_voyageai import VoyageAIEmbeddings
from langchain_community.vectorstores import MyScale
embeddings = VoyageAIEmbeddings(
voyage_api_key="your_voyageai_api_key",
model="voyage-law-2"
)
vectorstore = MyScale.from_documents(
texts,
embeddings,
)
retriever = vectorstore.as_retriever()
.from_documents (opens new window)メソッドは通常、ドキュメントのリストとモデルを取り、これらのドキュメントをベクトル埋め込みに変換します。このメソッドは、これらの埋め込みを自動的に知識ベースに保存します。
# モデルのためのツールの作成
LangChainでは、ツール (opens new window)は、エージェントがテキスト生成以外の特定のタスクを実行するために利用できる機能です。モデルにツールを装備することで、外部データソースとのやり取り、リアルタイム情報の取得、ユーザークエリに対してより正確で関連性のある回答を提供することができます。
このアプリケーションでは、エージェントがユーザーのクエリに基づいてどのツールを使用するかを決定するために、2つの異なるツールを開発します。
- クエリがMyScaleDBまたはMyScaleに関連する場合、エージェントはリトリーバーツールを使用してカスタム知識ベースから情報を取得します。
- 最新の情報が必要な他のクエリの場合、エージェントはTavily検索ツールを使用してライブインターネット検索を実行します。
# MyScaleコンテンツのためのリトリーバーツール
上記で作成したMyScaleDBリトリーバーを使用し、create_retriever_toolメソッドを使用してリトリーバーをツールに変換します。
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"retrieve_myscale_content",
"MyScaleDBに関する情報を返すために使用します。",
)
# ライブインターネットデータのためのTavily検索ツール
LangChainは、コミュニティパッケージを介してTavily検索ツール (opens new window)の使用をサポートしています。
from langchain_community.tools import TavilySearchResults
tool = TavilySearchResults(
max_results=5,
search_depth="advanced",
include_answer=True,
name="live_search",
description="インターネットから最新のニュースを検索するために使用します。",
)
tools = [retriever_tool, tool]
TavilySearchResultsツールは、最大5件の結果と高度な検索深度、直接の回答を含む最新のニュースを検索するように設定されています。最後に、両方のツールをリストに追加します。
注意: 各ツールの説明は非常に重要です。これにより、エージェントがどのツールを使用するか、どの目的で使用するかを判断するのに役立ちます。
# アプリケーションのワークフローの定義
必要なツールが定義されたので、次のステップは、ユーザーのクエリを分析し、知識ベースを使用するかウェブ検索を実行するかを決定するエージェントの完全なワークフローをレイアウトすることです。Geminiモデルを使用して、クエリに基づいて適切なツールを選択し、取得した情報に基づいてユーザーのクエリに応じた回答を生成します。
クエリが知識ベースに関連する場合、エージェントは関連するチャンクを知識ベースから取得し、これらのドキュメントをユーザーのクエリと照合する関数に渡して関連性をチェックします。ドキュメントが関連している場合、エージェントはそれらをLLMに送信して回答を生成します。関連していない場合、ユーザーのクエリを書き換えるためのメソッドを呼び出します。書き換えられたクエリは、リトリーバーに再送信され、関連する情報が見つかるまでプロセスが繰り返されます。
# エージェントとステートの定義
まず、レスポンスの状態を追跡するために使用される「AgentState」クラスを定義します。
# Standard Library Imports
from typing import Literal, Annotated, Sequence, TypedDict
# Langchain Core Imports
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
# Langchain and External Tools
from langchain import hub
from langchain_google_genai import ChatGoogleGenerativeAI
# LangGraph Imports
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
次に、ユーザーのクエリを分析し、知識ベースを使用するかウェブ検索を実行するかを決定するエージェントを定義します。Geminiモデルを使用して、クエリに基づいて適切なツールを選択し、取得した情報に基づいてユーザーのクエリに応じた回答を生成します。
def agent(state):
messages = state["messages"]
model = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
model = model.bind_tools(tools)
response = model.invoke(messages)
return {"messages": [response]}
# 取得したドキュメントの評価
エージェントは、取得したドキュメントがユーザーのクエリに関連しているかどうかを確認し、関連性をチェックします。grade_documents関数は、取得したドキュメントを分析して関連性をチェックするために使用されます。取得したドキュメントが関連している場合、エージェントは回答を生成することを決定します。関連していない場合、ユーザーのクエリを書き換えるためのメソッドを呼び出します。
def grade_documents(state) -> Literal["generate", "rewrite"]:
# Data model for grading
class Grade(BaseModel):
"""Binary score for relevance check."""
binary_score: str = Field(description="Relevance score 'yes' or 'no'")
# LLM
model = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
llm_with_tool = model.with_structured_output(Grade)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question.
Here is the retrieved document:
{context}
Here is the user question: {question}
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant.
Give a binary score 'yes' or 'no' to indicate whether the document is relevant to the question.""",
input_variables=["context", "question"],
)
# Chain
chain = prompt | llm_with_tool
messages = state["messages"]
last_message = messages[-1]
question = messages[0].content
docs = last_message.content
scored_result = chain.invoke({"question": question, "context": docs})
score = scored_result.binary_score
if score == "yes":
return "generate"
else:
return "rewrite"
# ユーザーのクエリの書き換え
取得したドキュメントが関連していない場合、エージェントはユーザーのクエリを書き換えて、知識ベースからの取得結果を改善します。
def rewrite(state):
messages = state["messages"]
question = messages[0].content
msg = [
HumanMessage(
content=f"""
Look at the input and try to reason about the underlying semantic intent / meaning.
Here is the initial question:
-------
{question}
-------
Formulate an improved question:""",
)
]
# LLM
model = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
response = model.invoke(msg)
return {"messages": [response]}
# 最終的な回答の生成
取得したドキュメントが関連していることが確認されたら、エージェントは取得したドキュメントを最終的な回答の生成に使用します。
def generate(state):
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}
# LangGraphにすべてを配置する
ワークフローのタスクをノードとして組織化し、それらの間に明確なパスを定義することで、LangGraphは、エージェントが知識ベースを使用するかウェブ検索を実行するか、関連情報を取得し、回答を生成するなどの複雑な決定を簡素化し、アプリケーションを構造化して維持しやすくします。
グラフを作成するために、ノード(アクション)とそれらの接続方法を指定します。
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import ToolNode
# Define a new graph
workflow = StateGraph(AgentState)
# Define the nodes we will cycle between
workflow.add_node("agent", agent) # Agent node
retrieve = ToolNode([retriever_tool])
workflow.add_node("retrieve", retrieve) # Retrieval node
search = ToolNode([tool])
workflow.add_node("search", search) # Search node
workflow.add_node("rewrite", rewrite) # Rewrite node
workflow.add_node("generate", generate) # Generate node
add_node関数は、ノードをグラフに追加します。最初の引数はノードの名前であり、2番目の引数はそれを表す関数です。
# エッジの定義
エッジは、特定の条件に基づいてノード間の遷移を定義します。エッジはアプリケーションの完全なフローを制御します。
# ツールの条件付きエッジの定義
まず、ユーザーのクエリに基づいてリトリーバーを使用するか検索ツールを使用するかを決定する条件を定義します。クエリに「myscaledb」または「myscale」が含まれている場合、エージェントはリトリーバーを使用します。それ以外の場合は、検索ツールを使用します。
def tools_condition(state) -> Literal["retrieve", "search"]:
messages = state["messages"]
question = messages[0].content.lower()
if "myscaledb" in question or "myscale" in question:
return "retrieve"
else:
return "search"
# エッジの追加
次に、ワークフローグラフにエッジを追加します。
workflow.add_edge(START, "agent")
workflow.add_conditional_edges(
"agent",
tools_condition,
{
"search": "search",
"retrieve": "retrieve",
},
)
workflow.add_conditional_edges(
"retrieve",
grade_documents,
)
workflow.add_edge("retrieve", "generate")
workflow.add_edge("search", "generate")
workflow.add_edge("generate", END)
workflow.add_edge("rewrite", "agent")
# Compile the graph
graph = workflow.compile()
add_edge関数は、ノードから別のノードへの直接の遷移を定義します。add_conditional_edges関数を使用すると、条件に基づいて遷移を指定できます。最初の引数はソースノードであり、2番目の引数は条件関数であり、3番目は条件の結果に対応するターゲットノードをマッピングする辞書です。
# 最終グラフの可視化
ノードとエッジがどのように接続されているかを確認するために、最終グラフを可視化してみましょう。
from IPython.display import Image, display
try:
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass
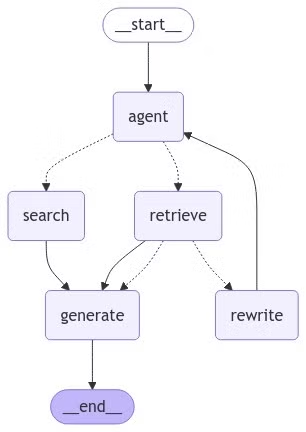
# グラフの実行
最後に、グラフを実行して、Q&Aシステムを実際に動作させましょう。
inputs = {
"messages": [
("user", "Which model was released by OpenAI recently?"),
]
}
for output in graph.stream(inputs):
for value in output.items():
print(value["messages"][0], indent=2, width=80, depth=None)
以下のような出力が生成されます。
OpenAI recently released a new generative AI model called OpenAI o1. '
'This model excels in "reasoning" abilities, allowing it to fact-check itself '
'and tackle complex problems like coding and math. It was released on '
'September 12, 2024, and is available for ChatGPT Plus and Team users.
MyScaleDBに関するクエリを次のように行った場合:
inputs = {
"messages": [
("user", "What is MyScaleDB?"),
]
}
for output in graph.stream(inputs):
for key, value in output.items():
print(value["messages"][0], indent=2, width=80, depth=None)
出力は次のようになります:
"MyScaleDB is a high-performance, cloud-based database built on top of the
open-source ClickHouse, designed specifically for AI and machine learning
applications. It supports both structured and unstructured data, making
it ideal for managing vast volumes of data and performing complex analytical
tasks."

# 結論
このチュートリアルを完了することで、ユーザーのクエリに基づいて知識ベースを使用するかウェブ検索を実行するかを動的に選択する質問応答(Q&A)システムを構築することができました。LangChain、MyScaleDB、VoyageAI、およびTavilyなどのツールを統合することで、複雑な質問を効率的に処理できる適応型AIエージェントを作成しました。これらのツールをさらに探索して、AIアプリケーションをさらに高度化していきましょう!




