
# クイックスタート
![]()
![]()
このガイドでは、クラスタを起動し、データをインポートし、SQLクエリを実行する方法を簡単な手順で説明します。Pythonクライアントなどの他の開発者ツールに関する詳細は、開発者ツールセクションで見つけることができます。
# 最初のクラスタの起動方法
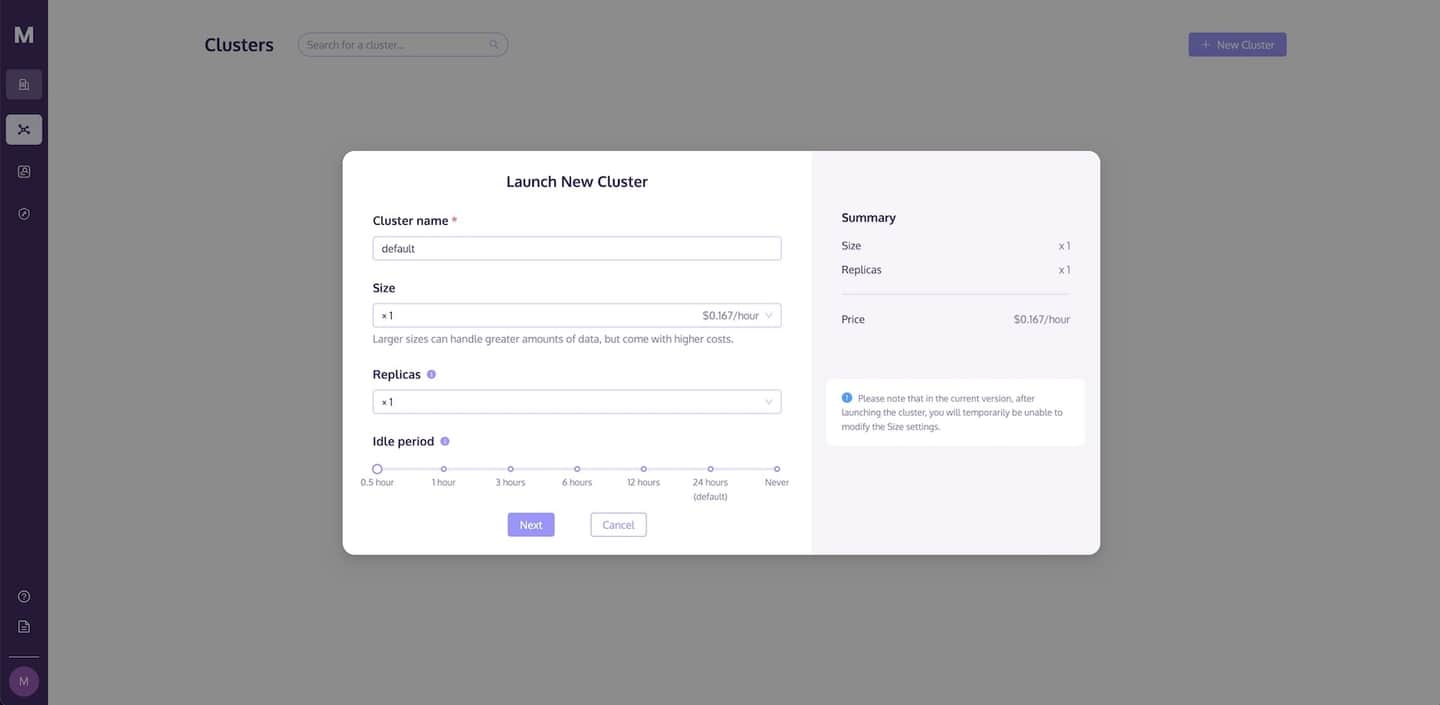
データ操作を行う前に、クラスタを起動する必要があります。クラスタページでは、クラスタを作成し、要件に合わせて計算リソースとストレージリソースを設定することができます。
新しいクラスタを起動するには、次の手順に従ってください。
- クラスタページに移動し、+新しいクラスタボタンをクリックして新しいクラスタを起動します。
- クラスタに名前を付けます。
- クラスタを実行するために起動をクリックします。
TIP
MyScaleの開発ティアはデフォルトの設定に制限されており、複数のレプリカをサポートしていません。より強力な構成にするには、請求プランの変更セクションを参照し、標準プランにアップグレードしてください。
# 環境のセットアップ
以下の開発者ツールのいずれかを使用して、MyScaleデータベースに接続するオプションがあります。
しかし、まずはPythonを使用しましょう。
# Pythonを使用する
Pythonを使用する前に、ClickHouseクライアント (opens new window)をインストールする必要があります。次のシェルスクリプトに記載されているようにインストールしてください。
pip install clickhouse-connect
ClickHouseクライアントが正常にインストールされたら、次のステップは、Pythonアプリ内からMyScaleクラスタに接続するために、次の詳細を提供することです。
- クラスタホスト
- ユーザー名
- パスワード
これらの詳細を見つけるには、MyScaleのクラスタページに移動し、アクションドロップダウンリンクをクリックし、接続の詳細を選択します。
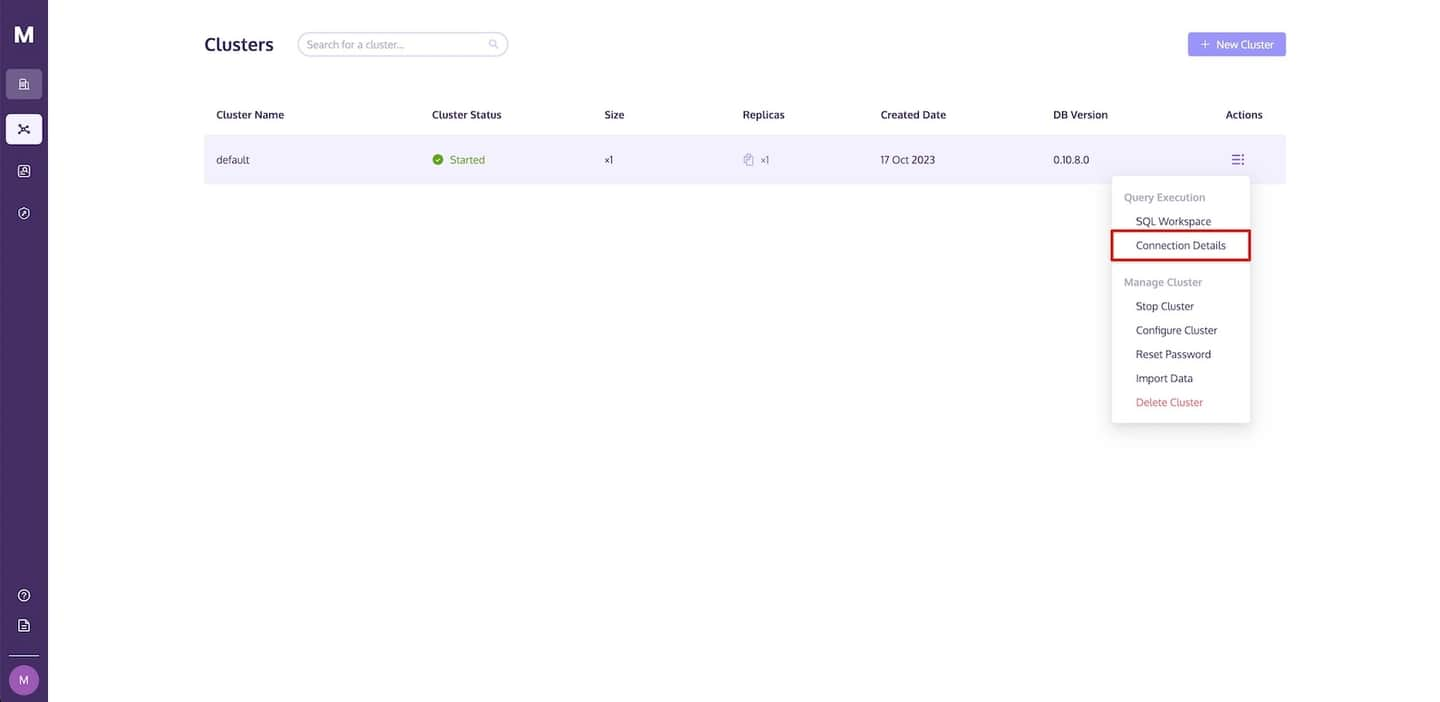
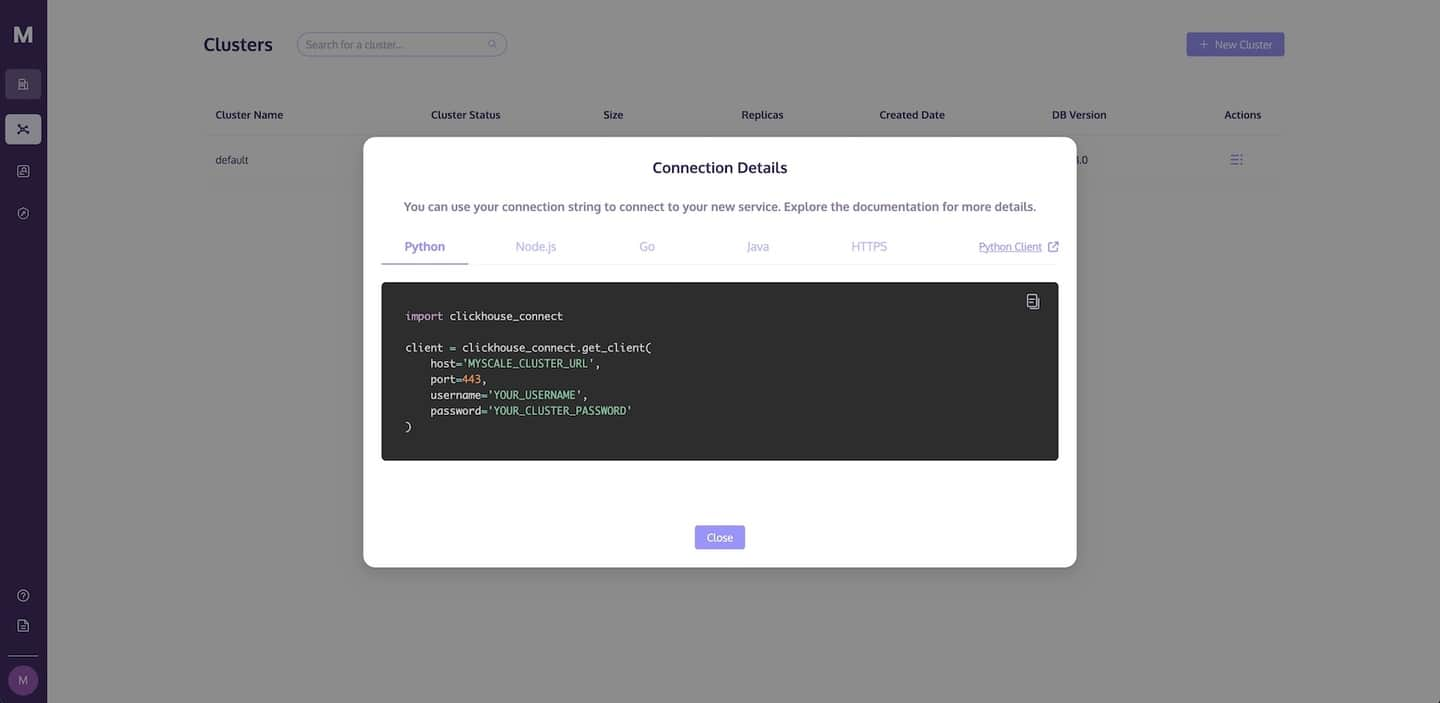
次の画像に示すように、接続の詳細ダイアログが表示され、MyScaleにアクセスするために必要なコードが表示されます。対応するコードをコピーするには、コピーのアイコンをクリックし、Pythonアプリに貼り付けます。
TIP
MyScaleクラスタに接続する詳細については、接続の詳細を参照してください。
# MyScaleコンソールを使用する
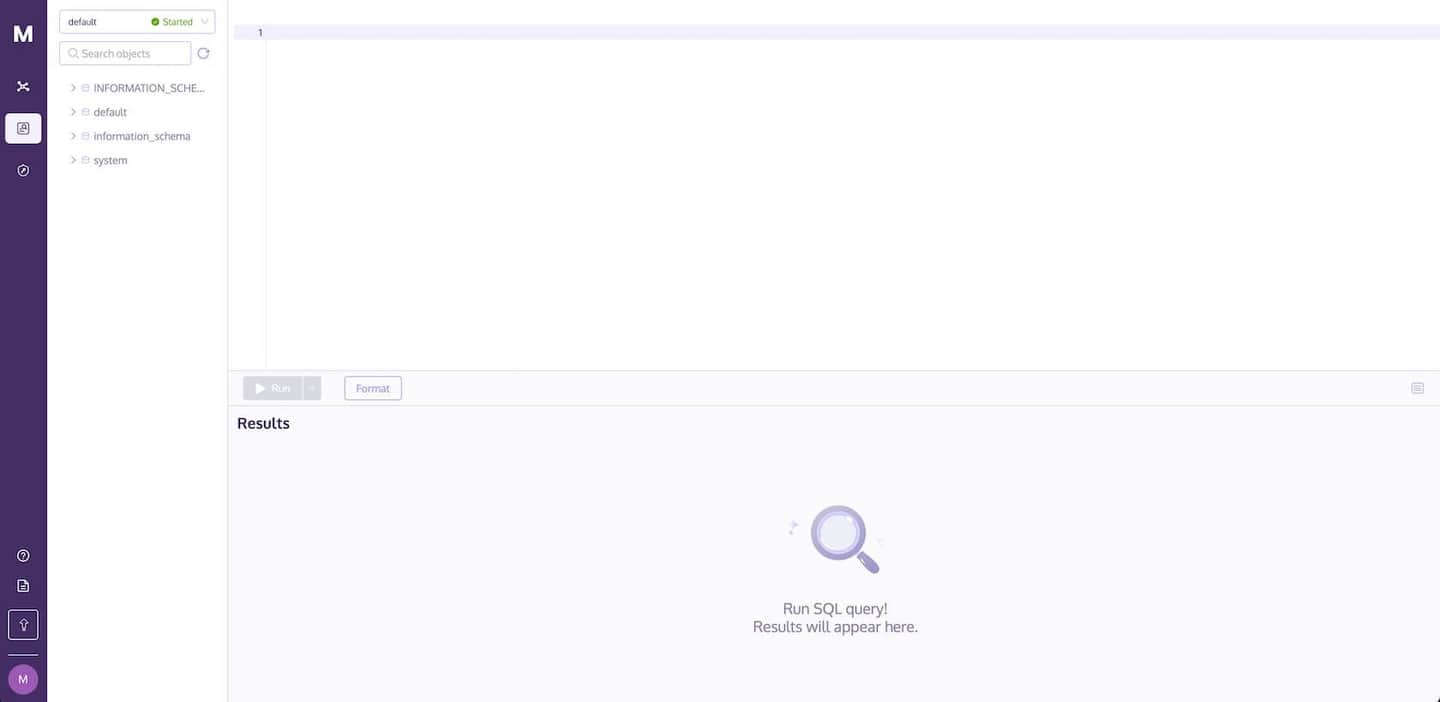
データをデータベースにインポートし、クエリを実行するためにMyScaleコンソールを使用するには、SQLワークスペースページに移動します。クラスタは自動的に選択されます。
# データをデータベースにインポートする方法
MyScaleにデータをインポートするには、次の手順に従ってください。
# テーブルを作成する
データをインポートする前に、MyScaleでデータベーステーブルを作成する必要があります。
次のコードサンプルを使用して、新しいテーブルdefault.myscale_categorical_searchを作成するためのSQLステートメント(PythonとSQLの両方で)を記述しましょう。
- Python
- SQL
# 128次元ベクトルを持つテーブルを作成します。
client.command("""
CREATE TABLE default.myscale_categorical_search
(
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ORDER BY id""")
# テーブルにデータを挿入する
TIP
MyScaleは、Amazon S3などのクラウドサービスからのデータインポートを、S3互換のAPIを使用してサポートしています。Amazon S3からデータをインポートする方法については、s3テーブル関数を参照してください。
次のコードスニペットに示すように、SQLを使用してdefault.myscale_categorical_searchテーブルにデータをインポートしましょう。
サポートされているファイル形式は次のとおりです。
CSV(opens new window)CSVWithNames(opens new window)JSONEachRow(opens new window)Parquet(opens new window)
TIP
すべてのサポートされている形式の詳細な説明については、入力および出力データの形式 (opens new window)を参照してください。
- Python
- SQL
client.command("""
INSERT INTO default.myscale_categorical_search
SELECT * FROM s3(
'https://d3lhz231q7ogjd.cloudfront.net/sample-datasets/quick-start/categorical-search.csv',
'CSVWithNames',
'id UInt32, data Array(Float32), date Date, label Enum8(''person'' = 1, ''building'' = 2, ''animal'' = 3)'
)""")
# ベクトルインデックスを作成する
構造化データに伝統的なインデックスを作成するだけでなく、MyScaleではベクトル埋め込みのためのベクトルインデックスも作成することができます。次のステップバイステップガイドを参照して、ベクトルインデックスを作成する方法を確認しましょう。
# MSTGベクトルインデックスの作成
以下のコードスニペットに示すように、最初のステップは、MSTGベクトルインデックスを作成することです。これは、当社独自のアルゴリズムであるMSTGを使用したベクトルインデックスです。
- Python
- SQL
client.command("""
ALTER TABLE default.myscale_categorical_search
ADD VECTOR INDEX categorical_vector_idx data
TYPE MSTG
""")
TIP
インデックスのビルド時間は、データのインポートサイズに依存します。
# ベクトルインデックスのビルドステータスを確認する
以下のコードスニペットは、SQLを使用してベクトルインデックスのビルドステータスを確認する方法を説明しています。
- Python
- SQL
# 'vector_indices' システムテーブルをクエリしてインデックス作成のステータスを確認します。
get_index_status="SELECT status FROM system.vector_indices WHERE table='myscale_categorical_search'"
# インデックス作成のステータスを出力します。インデックスが正常に作成された場合、ステータスは 'Built' になります。
print(f"index build status is {client.command(get_index_status)}")
以下の例に示すように、出力結果を確認できます。
- Python
- SQL
index build status is Built
TIP
ベクトルインデックスに関する詳細情報については、ベクトル検索を参照してください。
# SQLクエリの実行
MyScaleテーブルにデータをインポートし、ベクトルインデックスを作成した後、次の検索タイプを使用してデータをクエリできます。
TIP
MSTGベクトルインデックスを作成する最も重要な利点は、高速な検索速度です。
# ベクトル検索
通常、テキストや画像などの「青い車」や青い車の画像などがクエリされます。しかし、MyScaleではすべてのクエリをベクトルとして扱い、クエリとテーブル内の既存データとの類似性(「距離」)に基づいて応答を返します。
以下のコードスニペットを使用して、ベクトルをクエリとして使用してデータを取得します。
- Python
- SQL
# テーブルからランダムな行を選択してターゲットとします
random_row = client.query("SELECT * FROM default.myscale_categorical_search ORDER BY rand() LIMIT 1")
assert random_row.row_count == 1
target_row_id = random_row.first_item["id"]
target_row_label = random_row.first_item["label"]
target_row_date = random_row.first_item["date"]
target_row_data = random_row.first_item["data"]
print("currently selected item id={}, label={}, date={}".format(target_row_id, target_row_label, target_row_date))
# クエリの結果を取得します。
result = client.query(f"""
SELECT id, date, label,
distance(data, {target_row_data}) as dist FROM default.myscale_categorical_search ORDER BY dist LIMIT 10
""")
# クエリ結果の行を反復処理し、各行の 'id'、'date'、'label'、および距離を出力します。
print("Top 10 candidates:")
for row in result.named_results():
print(row["id"], row["date"], row["label"], row["dist"])
最も類似した結果を含む結果セットは次のようになります。
| id | date | label | dist |
|---|---|---|---|
| 0 | 2030-09-26 | person | 0 |
| 2 | 1975-10-07 | animal | 60,088 |
| 395,686 | 1975-05-04 | animal | 70,682 |
| 203,483 | 1982-11-28 | building | 72,585 |
| 597,767 | 2020-09-10 | building | 72,743 |
| 794,777 | 2015-04-03 | person | 74,797 |
| 591,738 | 2008-07-15 | person | 75,256 |
| 209,719 | 1978-06-13 | building | 76,462 |
| 608,767 | 1970-12-19 | building | 79,107 |
| 591,816 | 1995-03-20 | building | 79,390 |
TIP
これらの結果はベクトル埋め込みであり、結果の id を参照して元のデータを取得することができます。
# フィルタリング検索
ベクトル検索(ベクトル埋め込みを使用した)だけでなく、構造化データとベクトルデータの組み合わせを使用してSQLクエリを実行することもできます。以下のコードスニペットを参照してください。
- Python
- SQL
# クエリの結果を取得します。
result = client.query(f"""
SELECT id, date, label,
distance(data, {target_row_data}) as dist
FROM default.myscale_categorical_search WHERE toYear(date) >= 2000 AND label = 'animal'
ORDER BY dist LIMIT 10
""")
# クエリ結果の行を反復処理し、各行の 'id'、'date'、'label'、および距離を出力します。
for row in result.named_results():
print(row["id"], row["date"], row["label"], row["dist"])
最も類似した結果を含む結果セットは次のようになります。
| id | date | label | dist |
|---|---|---|---|
| 601,326 | 2001-05-09 | animal | 83,481 |
| 406,181 | 2004-12-18 | animal | 93,655 |
| 13,369 | 2003-01-31 | animal | 95,158 |
| 209,834 | 2031-01-24 | animal | 97,258 |
| 10,216 | 2011-08-02 | animal | 103,297 |
| 605,180 | 2009-04-20 | animal | 103,839 |
| 21,768 | 2021-01-27 | animal | 105,764 |
| 1,988 | 2000-03-02 | animal | 107,305 |
| 598,464 | 2003-01-06 | animal | 109,670 |
| 200,525 | 2024-11-06 | animal | 110,029 |