
ベクトルデータベースは、セマンティックテキスト検索や画像検索など、多くのAIアプリケーションで重要な役割を果たすベクトルデータの格納と管理を明示的に設計されたものです。伝統的な用語の一致やBM25アルゴリズムはテキスト検索において依然重要ですが、広く採用されているElasticsearchシステムは最近、ベクトル検索の機能を追加しました。特に、オープンソースの高性能SQLベクトルデータベースであるMyScaleDBは、最近全文検索 (opens new window)を導入しました。本記事では、MyScaleDBが全文検索のパフォーマンスでElasticsearchと競合し、より低いレイテンシと40%少ないメモリ使用量を実現することを示します。さらに、ベクトル検索を組み合わせると、MyScaleはコストの12%しか消費せずに最大10倍のパフォーマンスを実現します。高いパフォーマンス、低コスト、ClickHouseに基づく豊富なSQLエコシステムを備えたMyScaleDBは、Elasticsearchに対する効率的で強力なアップグレードと代替として浮上しています。
# Elasticsearchとは
Elasticsearchは、Apache Luceneをベースに構築された分散型のRESTfulな検索エンジンおよび分析エンジンです。大量のデータを迅速に格納、検索、分析することができ、ログ解析、アプリケーション検索、セキュリティ分析、ビジネス分析などの領域で広く使用されています。
Elasticsearchの利点は次のとおりです。
- 強力な検索機能: Elasticsearchは、正確な値、全文、ベクトル検索、複雑なクエリ、フィルタ、集計操作など、強力な全文検索機能を提供し、ユーザーが迅速かつ正確に必要な情報を取得できるようにします。
- 豊富な機能: Elasticsearchは、テキスト分析、集計分析、地理空間検索など、豊富な機能と柔軟な設定オプションを提供し、さまざまな検索と分析のニーズに対応します。
- 豊富なエコシステム: Elasticsearchのエコシステムは非常に広範であり、さまざまなプラグイン、ツール、サードパーティの統合が含まれており、機能とアプリケーションシナリオを拡張し、ユーザーにより多くの選択肢と柔軟性を提供します。
- 分散アーキテクチャ: 分散システムとして、Elasticsearchは簡単に多数のノードにスケールアップし、高可用性と水平スケーラビリティを実現できるため、大規模なデータ処理と分析タスクに適しています。
- リアルタイムデータ処理: Elasticsearchはリアルタイムデータのインデックス作成と検索をサポートしており、大量のリアルタイムデータを迅速に処理し、即座のクエリ結果を提供することができます。
ただし、Elasticsearchには次のようないくつかの欠点もあります。
- 急峻な学習曲線: Elasticsearchは比較的急な学習曲線を持っており、特に初心者にとっては、複雑な概念と使用方法を理解するために時間がかかります。
- 限られたベクトル検索アルゴリズム: バージョン8.13時点では、Elasticsearchはベクトル検索アルゴリズム(ブルートフォースkNNおよびHNSWに基づく近似kNNなど)のサポートが限られています。これは、複雑なベクトル検索シナリオでの応用を制限しています。
- 高いリソース消費: 強力な機能と分散アーキテクチャのため、Elasticsearchは実行時に比較的高いリソース(メモリ、CPU、ストレージスペースなど)を必要とします。
要約すると、Elasticsearchはテキスト検索の分野で強力なツールですが、使いやすさ、ベクトル検索、リソース利用の面でいくつかの欠点があり、複雑なAI検索と分析シナリオでの応用を制限しています。
# 優れたElasticsearchの代替:MyScaleDB
MyScaleDBは、オープンソースのSQLカラムストアデータベースであるClickHouseをベースに構築されています。自社開発の高性能で高データ密度のベクトルインデックスアルゴリズムを特徴としており、SQLとベクトルの結合クエリに対する検索能力とストレージエンジンのリトリーバル能力について、徹底的な研究と最適化を行っています。これにより、MyScaleDBは包括的なパフォーマンスとコスト効率の面で専用のベクトルデータベースを大幅に上回る世界初のSQLベクトルデータベース製品となっています。
# SQLとベクトルのネイティブ互換性
ユーザーはSQLを使用してMyScaleDBと対話し、エントリの障壁を下げ、学習曲線を短縮し、迅速に始めて効率的に進めることができます。MyScaleDBは柔軟なデータモデルとクエリ言語を提供し、ユーザーが特定のニーズに応じてデータ処理と分析戦略をカスタマイズできるようにサポートし、アプリケーションの柔軟性と実行効率を向上させます。SQLとベクトルを複雑なAIアプリケーションシナリオで組み合わせることにより、開発者はより直感的で効率的な開発方法を得ることができ、開発者の効率を大幅に向上させることができます。
Elasticsearchのドメイン固有言語(DSL)はJSONクエリに基づいていますが、MyScaleDBではベクトル検索のdistance()関数をマスターするだけで十分です。この情報と既存のSQLの知識を活用して、複雑なベクトル検索クエリを開発することができます。さらに、データベースレベルで複雑な分析とデータ処理を行うこともできるため、アプリケーションシステム全体の処理効率を高速化することができます。
例えば:
-- ベクトル検索を実行し、上位10件の結果を返す
SELECT
id, title, text
distance(vector, query_vector) as dist
FROM doc_table
ORDER BY
dist ASC
LIMIT 10;
# テキスト検索機能でElasticsearchを置き換える
最新バージョンでは、MyScaleDBはフルテキスト検索やハイブリッド検索などの強力な機能を導入し、複雑なAIの要件とデータの課題を扱うための実用的なソリューションを提供しています。高速なインデックス構築、効率的な検索、マルチスレッドサポートを特徴とするTantivyフルテキスト検索エンジンライブラリを組み込んでいます。さらに、非常に使いやすく、非常に柔軟であり、大規模なテキストデータを迅速に検索するのに非常に適しています。これにより、データベースに格納されたテキストデータを迅速に検索し、BM25スコアに基づいて最も近い一致する結果セットを返すことができます。
たとえば、以下の表は、同じデータセット「wiki」(5億6千万レコード)で実行したテキスト検索機能のテスト結果を示しています。MyScaleDBのP95クエリレイテンシが大幅に低下し、メモリ使用量も目立って減少しています。したがって、全文検索の文脈で、機能面で言えば、MyScaleDBは効果的にElasticsearchを置き換えることができます。
| エンジン | 関数 | QPS | p95レイテンシ | ピークメモリ |
|---|---|---|---|---|
| MyScaleDB | TextSearch | 4099.16 | 4.563ms | 2.35GB |
| ElasticSearch | match | 3907 | 8.863ms | 3.7GB |
| ElasticSearch | wildcard | 4679.16 | 5.583ms | 3.7GB |
# ベクトル検索機能でElasticsearchを凌駕する
MyScaleDBはベクトル検索技術を利用し、MTSG、SCANN、FLAT、HNSWおよびIVFファミリーなど、さまざまなベクトルインデックスアルゴリズムをサポートしています。これにより、さまざまなAIシナリオのリトリーバルニーズに対応し、大規模な高次元データの処理において絶対的な優位性を持っています。
大規模なデータセット(LAION 5Mベクトル、768次元)を使用して、MyScaleDBとElasticsearchのベクトル検索のパフォーマンスを異なる同時クエリスレッドでテストしました。精度とスループットのテスト結果は以下の図に示されています。
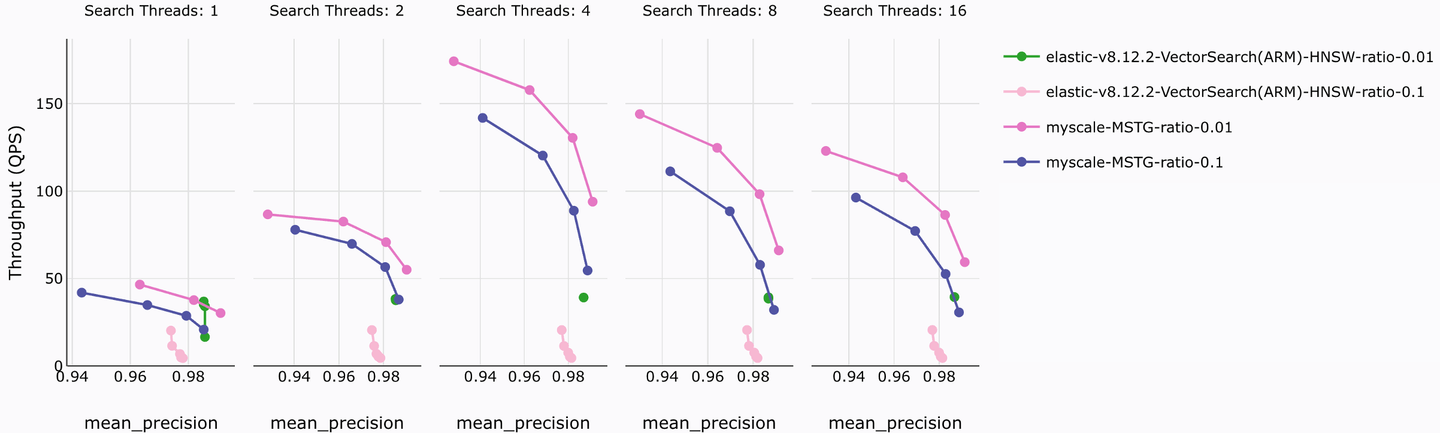
このテストでは、フィルタリング比率0.1と0.01の2つの一般的な比率をテストしました。結果の分析から、同様の精度の場合、MyScaleDBのMSTGインデックスは最大10倍のQPSパフォーマンス向上を示しています。MyScaleDBは、インデックスリソースの消費、作成時間、クエリレイテンシ、クエリコストの面でも同様の利点を持っています。
さらに、MyScaleDB SaaSは5百万ベクトルを提供するために月額120ドルしかかかりませんが、ElasticCloudは982ドルと8倍以上の費用がかかります。さらに、MyScaleDBは複数のタイプのベクトルインデックスをサポートしており、強力なリトリーバルパフォーマンスとコスト効率の使用コストと組み合わせることで、Elasticsearchよりもベクトルのリトリーバルと分析クエリシナリオに適しています。
パフォーマンステスト結果については、MyScaleDBベクトルデータベースベンチマーク (opens new window)を参照してください。
# リソースの効果的な使用
前述のように、MyScaleDBは高性能なカラムストアデータベースであるClickHouseをベースに構築されており、現在、リアルタイムアプリケーションと分析のための最も高速でリソース効率の良いオープンソースデータベースです。ClickHouseの高度な機能のいくつかが選択されました。効率的なインデックスメカニズム、データ圧縮技術、カラムストア構造、ベクトル化されたクエリ実行、および分散処理の機能などが含まれます。
さらに、MyScaleDBのクエリエンジンは、モダンなCPUとメモリに最適化されています。ベクトル化されたクエリ処理とデータ並列処理の技術を使用して、マルチコアプロセッサのパフォーマンスを最大限に活用し、データの計算を高速化します。ClickHouseのカラムストアモデルを継承しているため、MyScaleDBは効率的なデータ圧縮と高速な列レベルの操作を実現しています。クエリで指定された列のみを読み取るため、データの読み取り量を減らし、データの圧縮率を向上させ、ストレージコストを削減することができます。これにより、大量のデータの分析と処理に特に適しています。
まとめると、ベクトル検索技術、フルテキスト検索エンジンであるTantivy、ClickHouseの高性能機能、分散アーキテクチャ、最適化されたクエリエンジンを組み合わせることで、MyScaleDBは大規模なデータセットの効率的な処理と分析を実現します。複雑なデータ分析、ハイブリッド検索、全文検索、ベクトル検索のシナリオに特に適しています。
# ElasticsearchをMyScaleDBで置き換える方法
このプロセスには、データモデリング、データ移行、クエリロジックの変換などのタスクが含まれます。データのクラスタへのクイックスピンアップ、データのインポート、SQLクエリの実行に関する詳細な情報については、クイックスタート (opens new window)ガイドを参照してください。
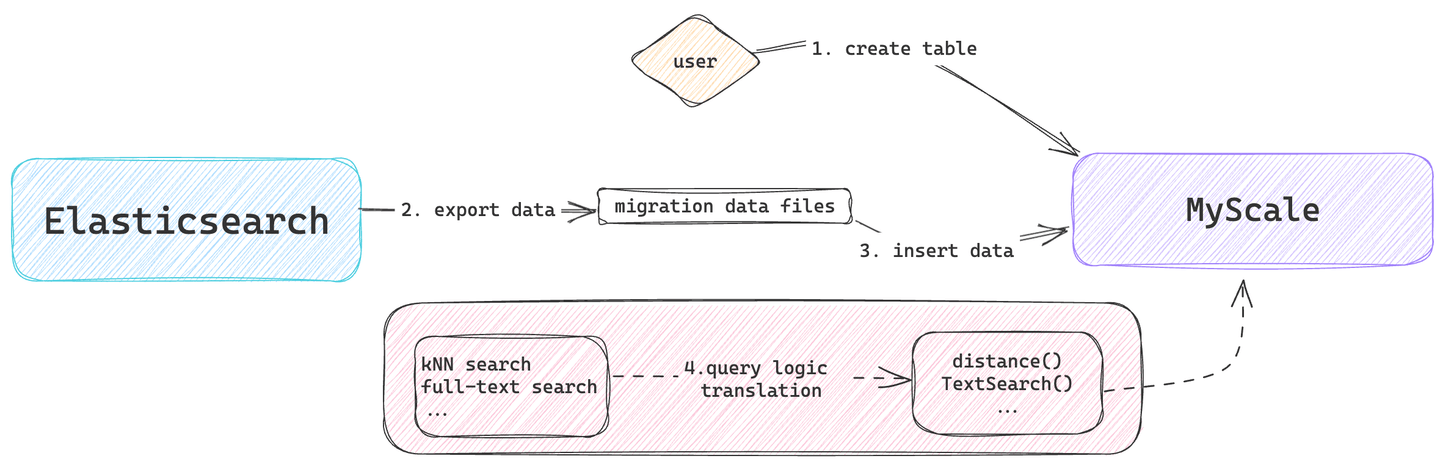
# データモデルの設計
データモデルの設計フェーズでは、ElasticsearchのドキュメントモデルをMyScaleDBのテーブル構造にマッピングする方法を決定します。主に、MyScaleDBに移行するデータテーブルの列、データ型、およびインデックスタイプを定義します。
# データ型の変換
MyScaleDBはClickHouseのすべてのデータ型と互換性があります。したがって、Elasticsearchのフィールドデータ型はすべて、MyScaleDBのデータ型に対応しています。
注意:
ベクトル検索に使用されるElasticsearchのdense_vector型は、element_typeに基づいてMyScaleDBではArray(Float32)またはFixedStringにマッピングする必要があります。さらに、対応する長さの制約を列に追加する必要があります。
# ベクトルインデックスの定義
MyScaleDBは複数のタイプのベクトルインデックスをサポートしていますが、最適なパフォーマンスのためにはMSTGインデックスの使用を強くお勧めします。
高速なベクトル検索のためのベクトルインデックスの作成と操作については、ベクトルクエリチュートリアル (opens new window)を参照してください。
以下は、Elasticsearchのimage-indexをMyScaleDBのes_data_migrationテーブルに変換する例です。
{
"image-index": {
"mappings": {
"properties": {
"file-type": {
"type": "keyword"
},
"image-vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "l2_norm"
},
"title": {
"type": "text"
},
"title-vector": {
"type": "dense_vector",
"dims": 5,
"index": true,
"similarity": "l2_norm"
}
}
}
}
}
CREATE TABLE default.es_data_migration
(
`id` UInt32,
`file_type` String,
`image_vector` Array(Float32),
`title` String,
`title_vector` Array(Float32),
VECTOR INDEX vec_ind_image image_vector TYPE MSTG('metric_type=L2'),
VECTOR INDEX vec_ind_title title_vector TYPE MSTG('metric_type=L2'),
CONSTRAINT check_length_image CHECK length(image_vector) = 3,
CONSTRAINT check_length_title CHECK length(title_vector) = 5
)
ENGINE = MergeTree
PRIMARY KEY id;
# データ移行
このフェーズでは、Elasticsearchからデータをエクスポートし、それをMyScaleDBにインポートすることが主なタスクです。
- Elasticsearchからデータをエクスポートする: Elasticsearch API、Logstash、KibanaのCSVレポート機能、Pythonのes2csvツールなど、さまざまな方法を使用して、一般的な形式(JSONやCSVなど)でデータをエクスポートできます。
- MyScaleDBにデータをインポートする: MyScaleDBは、Pythonクライアント、HTTPSインターフェースなど、さまざまなデータインポート方法をサポートしています。
たとえば、ElasticsearchからエクスポートされたデータファイルをMyScaleDBに移行するためのPythonクライアントを使用する例です。
import clickhouse_connect
import pandas as pd
# クライアントの初期化
# SaaSユーザーの場合は、MyScaleDBクラスタページに移動し、アクションのドロップダウンリンクをクリックし、接続の詳細を選択します。
client = clickhouse_connect.get_client(
host='127.0.0.1',
port=8123,
username='default',
password=''
)
def convert_vector(vector_str):
return list(map(float, vector_str.split(', ')))
# 移行データファイルの読み込み
data = pd.read_csv('test.csv', usecols=['_id', 'image-vector', 'title', 'title-vector'], converters={'image-vector': convert_vector, 'title-vector': convert_vector})
# データを移行テーブルに挿入する
client.insert('default.es_data_migration', data.values.tolist(), ['id', 'image_vector', 'title', 'title_vector'])
# クエリロジックの変換
元のアプリケーションのクエリリトリーバルロジック(元々Elasticsearchで処理されていた)は、MyScaleDBの検索に変更され、それに応じてデータ処理ロジックも更新されます。
{
"knn": {
"field": "image-vector",
"query_vector": [-5, 9, -12],
"k": 10,
"num_candidates": 100
},
"fields": [ "title", "file-type" ]
}
SELECT
id,
title,
file_type,
distance(image_vector, [-5.0, 9.0, -12.0]) AS l2_dist
FROM default.es_data_migration
ORDER BY l2_dist ASC
LIMIT 10

# 結論
MyScaleDBとElasticsearchの機能とパフォーマンスを比較分析することで、MyScaleDBはElasticsearchの効率的な代替品であり、アップグレードであるだけでなく、将来のデータニーズと技術トレンドに適応できる先進的なデータソリューションであることがわかります。ベクトル検索とリソースコストの面で特に優れています。
さらに、ClickHouseの強力な分散ストレージと処理アーキテクチャに基づいて、MyScaleDBはスケーラビリティに非常に柔軟であり、成長するデータ要件に簡単に対応できます。
さらに、MyScaleDBはClickHouseのエコシステムコンポーネントと互換性があり、豊富なドキュメントリソースと広範なコミュニティサポートを提供しています。また、Pythonクライアント (opens new window)、Node.js (opens new window)、LLMフレームワーク(OpenAI (opens new window)、LangChain (opens new window)、LangChain JS/TS (opens new window)、LlamaIndex (opens new window))など、世界中の人気のある開発者ツールとも統合されており、より良いユーザーエクスペリエンスとサポートを提供しています。
最後に、MyScaleDBはさまざまなデータ要件とクエリシナリオに適応できる広範なデータ型とクエリ構文をサポートしており、包括的なSQLデータ管理機能、堅牢なデータストレージ、クエリ機能を備えているため、将来のデータストレージと処理においてますます重要な役割を果たし、ユーザーにより豊かで効率的なサービスを提供します。



