
基本的な検索支援生成(RAG) (opens new window)データパイプラインは、通常、ハードコードされたステップに依存し、実行するたびに事前に定義されたパスに従います。これらのシステムでは、リアルタイムの意思決定は行われず、入力データに基づいてアクションを動的に調整することはありません。この制限により、伝統的なRAGシステムの柔軟性と応答性が低下し、複雑または変化する環境での主要な弱点が浮き彫りになります。
LlamaIndexは、エージェントを導入することでこの制限を解決します。エージェントは、静的なデータソースから「読み取る」だけでなく、さまざまなツールからデータを動的に取り込み、変更することができる点で、クエリエンジンを超える存在です。これらのエージェントは、提供されたセットから最適なツールを選択して指定されたタスクを達成するために、一連のアクションを実行するように設計されています。これらのツールは、基本的な関数から包括的なLlamaIndexクエリエンジンまで、単純なものから複雑なものまで様々です。ユーザーの入力やクエリを処理し、これらの入力を処理する方法について内部的に判断し、追加のステップが必要かどうか、または最終結果を提供できるかどうかを決定します。この自動推論と意思決定の能力により、エージェントは複雑なデータ処理タスクに対して非常に適応性があり、効率的に動作します。
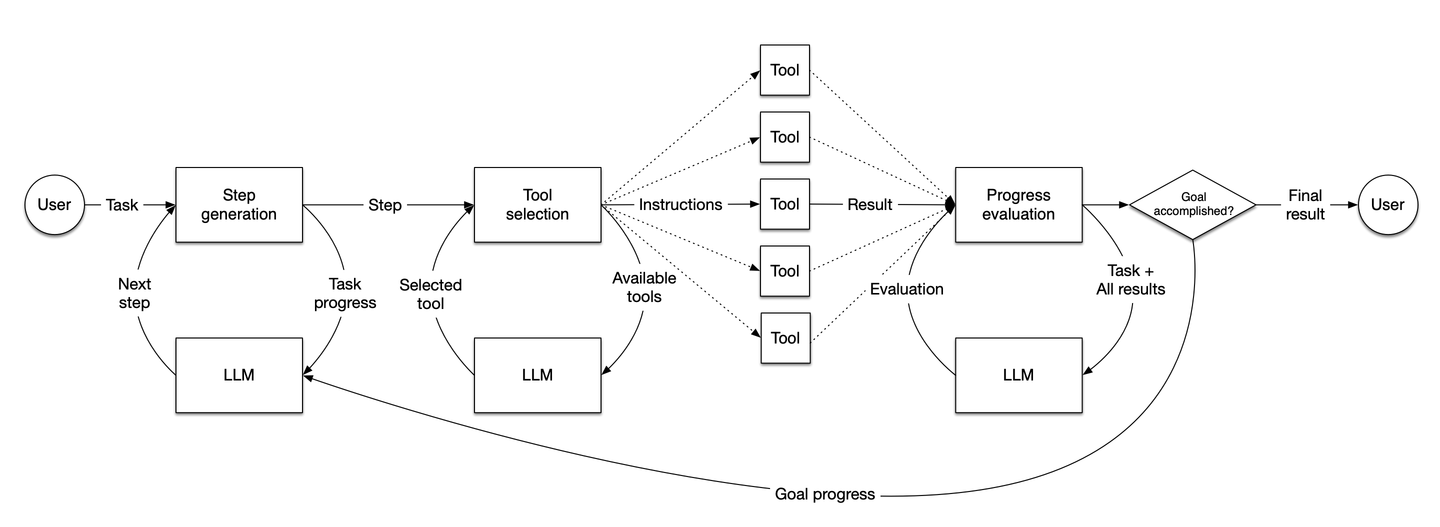
出典:LlamaIndex
この図は、LlamaIndexエージェントのワークフローを示しています。ユーザーの入力に基づいてタスクを動的に実行し、ステップを生成し、意思決定を行い、ツールを選択し、進捗を評価してタスクを達成します。
# LlamaIndexエージェントの主要なコンポーネント
LlamaIndexのエージェントには、エージェントランナーとエージェントワーカーの2つの主要なコンポーネントがあります。
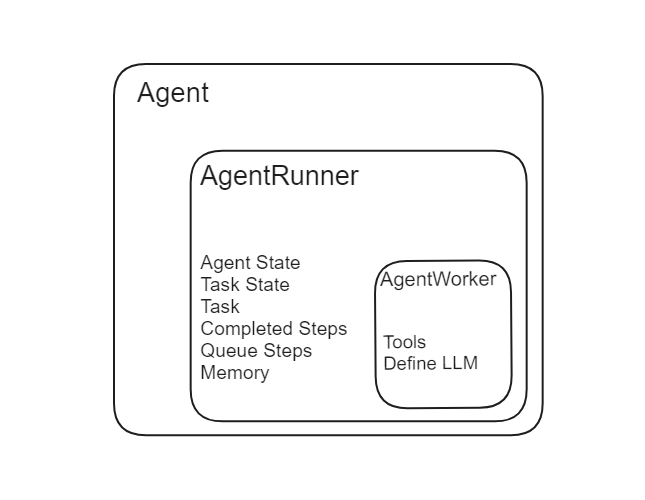
出典:LlamaIndex
# エージェントランナー
エージェントランナーは、LlamaIndex内のオーケストレーターです。エージェントの状態、会話のメモリなどを管理し、ユーザーとのインタラクションのための高レベルなインターフェースを提供します。タスクを作成し、実行する責任を持ちます。以下に、エージェントランナーの機能の詳細な説明を示します。
- タスクの作成:エージェントランナーは、ユーザーのクエリや入力に基づいてタスクを作成します。
- 状態の管理:会話とタスクの状態を保存し、維持します。
- メモリの管理:会話のメモリを内部で管理し、相互作用ごとにコンテキストが維持されるようにします。
- タスクの実行:エージェントランナーは、エージェントワーカーと協力して各タスクを実行します。
LangChainエージェント (opens new window)とは異なり、開発者がメモリを手動で定義して渡す必要がないため、LlamaIndexエージェントはメモリの管理を内部で行います。
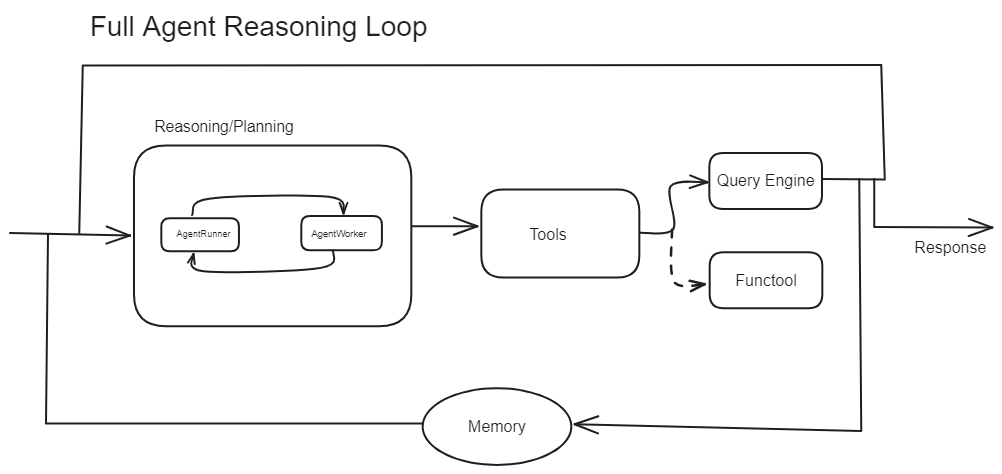
出典:LlamaIndex
# エージェントワーカー
エージェントワーカーは、エージェントランナーによって与えられたタスクのステップごとの実行を制御します。現在の入力に基づいてタスクの次のステップを生成する責任を持ちます。エージェントワーカーは、特定の推論ロジックを含めるようにカスタマイズすることができるため、さまざまなタスクに非常に適応性があります。主な要素は次のとおりです。
- ステップの生成:現在のデータに基づいてタスクの次のステップを決定します。
- カスタマイズ:特定のタイプの推論やデータ処理を処理するためにカスタマイズできます。
エージェントランナーはタスクの作成と状態の管理を担当し、エージェントワーカーはエージェントランナーの指示の下で各タスクのステップを実行する操作ユニットとして機能します。
# LlamaIndexのエージェントの種類
LlamIndexでは、特定のタスクと機能に特化したさまざまな種類のエージェントを提供しています。
# データエージェント
データエージェント (opens new window)は、検索や操作など、さまざまなデータタスクを処理するために特化したエージェントです。読み取りモードと書き込みモードの両方で動作し、さまざまなデータソースとシームレスに連携できます。
データエージェントは、Slack、Shopify、Googleなどのプラットフォームとの連携をサポートし、データベースのクエリ、APIの呼び出し、レコードの更新、データ変換など、複雑なデータ操作を処理できます。その適応性のある設計により、シンプルなデータの取得から複雑なデータ処理パイプラインまで、さまざまなアプリケーションに適しています。
from llama_index.agent import OpenAIAgent, ReActAgent
from llama_index.llms import OpenAI
# ツールのインポートと定義
...
# LLMの初期化
llm = OpenAI(model="gpt-3.5-turbo")
# OpenAIエージェントの初期化
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
# ReActエージェントの初期化
agent = ReActAgent.from_tools(tools, llm=llm, verbose=True)
# エージェントの使用
response = agent.chat("What is (121 * 3) + 42?")
# カスタムエージェント
カスタムエージェントは、柔軟性とカスタマイズオプションに優れています。CustomSimpleAgentWorkerをサブクラス化することで、エージェントの特定のロジックと動作を定義できます。これには、複雑なクエリの処理、複数のツールの統合、エラーハンドリングメカニズムの実装などが含まれます。
ステップバイステップのロジック、リトライメカニズム、さまざまなツールの統合などを定義することで、カスタムエージェントを特定のニーズに合わせることができます。このカスタマイズにより、複雑なデータ操作やユニークなサービスとの統合など、さまざまなシナリオに対応できるエージェントを作成できます。
# ツールとツールの仕様
ツールは、エージェントの最も重要なコンポーネントです。ツールを使用することで、エージェントはさまざまなタスクを実行し、機能を拡張することができます。さまざまなタイプのツールを使用することで、エージェントは必要に応じて特定の操作を実行できます。これにより、エージェントは非常に適応性があり、効率的に動作します。
# 関数ツール
関数ツールを使用すると、任意のPython関数をエージェントが使用できるツールに変換できます。この機能は、カスタム操作を作成し、エージェントがさまざまなタスクを実行できる能力を向上させるのに役立ちます。
シンプルな関数を、エージェントがワークフローに組み込むことができるツールに変換できます。これには、数学的な操作、データ処理関数、その他のカスタムロジックなどが含まれます。
次のように、Pythonの関数をツールに変換できます。
from llama_index.core.tools import FunctionTool
def multiply(a: int, b: int) -> int:
"""2つの整数を掛け合わせ、結果の整数を返します。"""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
LlamaIndexのFunctionToolメソッドを使用すると、Pythonの関数をエージェントが使用できるツールに変換できます。関数の名前はツールの名前になり、関数のドキュメント文字列はツールの説明になります。
# クエリエンジンツール
クエリエンジンツールは、既存のクエリエンジンをラップし、エージェントがデータソース上で複雑なクエリを実行できるようにします。これらのツールは、さまざまなデータベースやAPIと連携し、エージェントがデータを効率的に取得して操作できるようにします。
これらのツールにより、エージェントは特定のデータソースと対話し、複雑なクエリを実行し、関連する情報を取得できます。この統合により、エージェントはデータを効果的に使用して意思決定プロセスを行うことができます。
クエリエンジンをクエリエンジンツールに変換するには、次のコードを使用できます。
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tools = QueryEngineTool(
query_engine="ここにクエリエンジンとしてのインデックスを指定",
metadata=ToolMetadata(
name="ツールの名前を指定",
description="説明を記入",
),
)
QueryEngineToolメソッドを使用すると、クエリエンジンをエージェントが使用できるツールに変換できます。ToolMetadataクラスを使用して、このツールの名前と説明を定義できます。ツールの名前はname属性で設定し、説明はdescription属性で設定します。
注意:ツールの説明は非常に重要です。これにより、LLMがそのツールを使用するタイミングを判断できます。

# MyScaleDBとLlamaIndexを使用したAIエージェントの構築
ここでは、クエリエンジンツールと関数ツールの両方を使用してAIエージェントを構築し、これらのツールを効果的に統合して利用する方法を示します。
# 必要なライブラリのインストール
まず、ターミナルで次のコマンドを実行して必要なライブラリをインストールします。
pip install myscale-client llama-index
ベクトル検索エンジンとしてMyScaleDB (opens new window)を使用して、クエリエンジンを開発します。MyScaleDBは、スケーラブルなアプリケーションに特化した高度なSQLベクトルデータベースです。
# クエリエンジンのデータの取得
この例では、Nikeカタログデータセット (opens new window)を使用します。次のコードを使用して、データをダウンロードして準備します。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import requests
url = 'https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
reader = SimpleDirectoryReader(input_files=["Nike_Catalog.pdf"])
documents = reader.load_data()
このコードは、NikeカタログPDFをダウンロードし、クエリエンジンで使用するためにデータをロードします。
# MyScaleDBとの接続
MyScaleDBを使用する前に、接続を確立する必要があります。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='ここにホストを入力',
port=443,
username='ここにユーザー名を入力',
password='ここにパスワードを入力'
)
クラスタの詳細を取得し、MyScaleについて詳しくは、MyScaleDBクイックスタート (opens new window)ガイドを参照してください。
# クエリエンジンツールの作成
まず、エージェントの最初のツールであるクエリエンジンツールを構築しましょう。そのために、MyScaleDBを使用してクエリエンジンを開発し、Nikeカタログデータをベクトルストアに追加します。
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
query_engine = index.as_query_engine()
データがベクトルストアに取り込まれ、インデックスが作成されたら、次のステップはクエリエンジンをツールに変換することです。そのために、LlamaIndexのQueryEngineToolメソッドを使用します。
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tool = QueryEngineTool(
query_engine=index,
metadata=ToolMetadata(
name="nike_data",
description="Nikeの製品に関する情報を提供します。詳細なプレーンテキストの質問をツールの入力として使用してください。"
),
)
QueryEngineToolは、query_engineとmeta_dataを引数に取ります。メタデータでは、ツールの名前と説明を定義します。
# 関数ツールの作成
次のツールは、2つの数値を掛け合わせるだけのシンプルなPython関数です。このメソッドをLlamaIndexのFunctionToolを使用してツールに変換します。
from llama_index.core.tools import FunctionTool
# シンプルなPython関数を定義します
def multiply(a: int, b: int) -> int:
"""2つの整数を掛け合わせ、結果を返します。"""
return a * b
# 関数をツールに変換します
multiply_tool = FunctionTool.from_defaults(fn=multiply)
これで、ツールの作業は完了です。LlamaIndexのエージェントは、ツールをPythonのリストとして受け取ります。したがって、ツールをリストに追加しましょう。
tools = [multiply_tool, query_engine_tool]
# LLMの定義
LlamaIndexエージェントの中心であるLLMを定義しましょう。LLMの選択は重要です。なぜなら、LLMの理解とパフォーマンスが良ければ良いほど、より効果的に意思決定を行い、複雑な問題を処理できるからです。ここでは、OpenAIのgpt-3.5-turboモデルを使用します。
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
# エージェントの初期化
先に述べたように、エージェントはエージェントランナーとエージェントワーカーの2つの構成要素で構成されます。これらはエージェントの構築ブロックです。次に、実際の動作方法を説明します。以下のコードは2つの方法で実装されています。
- カスタムエージェント:最初の方法は、エージェントワーカーを最初にツールとllmと共に初期化し、エージェントランナーにエージェントワーカーを渡してエージェント全体を処理する方法です。必要なモジュールをインポートし、独自のエージェントを構築します。
from llama_index.core.agent import AgentRunner
from llama_index.agent.openai import OpenAIAgentWorker
# 方法2:OpenAIAgentWorkerでAgentRunnerを初期化
openai_step_engine = OpenAIAgentWorker.from_tools(tools, llm=llm, verbose=True)
agent1 = AgentRunner(openai_step_engine)
- 事前定義されたエージェントの使用:2番目の方法は、エージェントが
AgentRunnerのサブクラスであり、バックエンドでOpenAIAgentWorkerが実装されているため、AgentRunnerやAgentWorkerを自分で定義する必要がないため、エージェントを使用する方法です。
from llama_index.agent.openai import OpenAIAgent
# OpenAIAgentの初期化
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
注意:LLMでverbose=trueを設定すると、モデルの思考プロセスを理解し、詳細な説明と推論を提供することで、回答に至るまでのモデルの考え方を把握することができます。
初期化方法に関係なく、同じ方法でエージェントをテストできます。最初のものをテストしてみましょう。
# カスタムエージェントを呼び出す
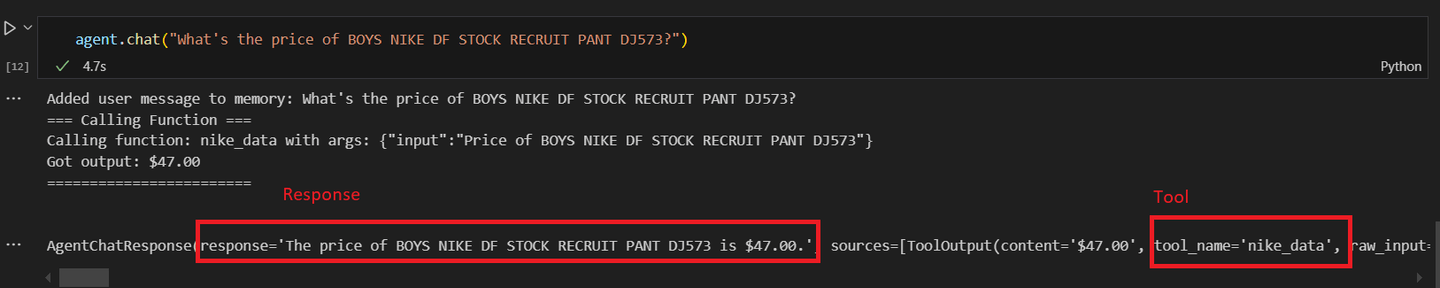
agent = agent.chat("BOYS NIKE DF STOCK RECRUIT PANT DJ573の価格はいくらですか?")
次のような結果が得られるはずです。
次に、数学の操作を行うために2番目のカスタムエージェントを呼び出してみましょう。
# 2番目のエージェントを呼び出す
response = agent1.chat("2+2は何ですか?")
2番目のエージェントを呼び出すと、数学の操作を要求すると、次のような応答が得られます。
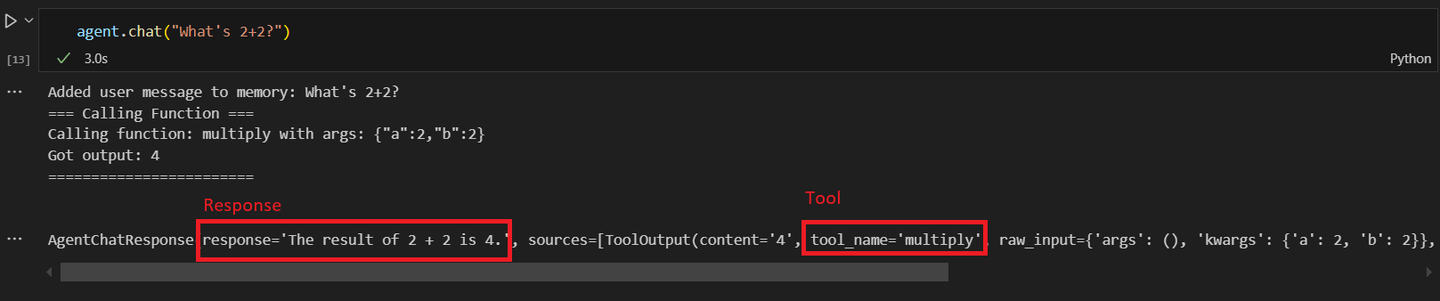
AIエージェントが複雑なタスクを自律的に処理する能力は拡大しており、定型的なタスクを管理し、人間の労働者を高付加価値の活動に割り当てることで、ビジネス環境で貴重な存在となっています。今後、AIエージェントの採用はさらに拡大し、技術との相互作用方法を革新し、ワークフローを最適化することが期待されています。
# 結論
LlamaIndexエージェントは、伝統的なRAGシステムを超えたデータの管理と処理のスマートな方法を提供します。静的なデータパイプラインとは異なり、これらのエージェントはリアルタイムの意思決定を行い、入力データに基づいてアクションを調整します。この自動推論により、複雑なタスクに対して非常に適応性があり、効率的に動作するエージェントが実現されます。基本的な関数から高度なクエリエンジンまで、さまざまなツールを統合して、入力を効果的に処理し、最適な結果を提供します。
MyScaleDBは、大規模なAIアプリケーションに特化したトップクラスのベクトルデータベースです。そのMSTGアルゴリズム (opens new window)は、スケーラビリティと効率性の面で他のデータベースを凌駕しており、高需要の環境に最適です。大規模なデータセットと複雑なクエリ (opens new window)を迅速に処理するために設計されたMyScaleDBは、高速かつ正確なデータの取得を保証します。これにより、他のベクトルデータベースと比較して、シームレスな統合と優れたパフォーマンスが実現されます。
MyScaleDBを使用したAIエージェントの構築について詳しく話し合いたい場合は、Twitter (opens new window)でフォローするか、Discord (opens new window)コミュニティに参加してください。一緒にデータとAIの未来を築きましょう!



