
人工知能の進化する風景の中で、より知的で反応性があり、コンテキストを理解したチャットボットの開発への探求は、私たちを新たな時代の扉の前に連れてきました。RAG(Retrieval-Augmented Generation、検索拡張生成)の世界へようこそ。これは、検索システムの広範な知識と生成モデルの創造力を組み合わせた画期的なアプローチです。RAG技術により、チャットボットは知識ベースにアクセスすることで、効果的にあらゆるタイプのユーザークエリを処理することができます。しかし、このパワーを効果的に活用するためには、その速度と効率に匹敵するストレージソリューションが必要です。ここで、ベクトルデータベースが輝きを放ち、膨大なデータの管理と検索方法に革新をもたらします。
このブログでは、Google GeminiモデルとMyScaleDB (opens new window)を使用して、数分でRAGパワードのチャットボットを構築する方法を紹介します。
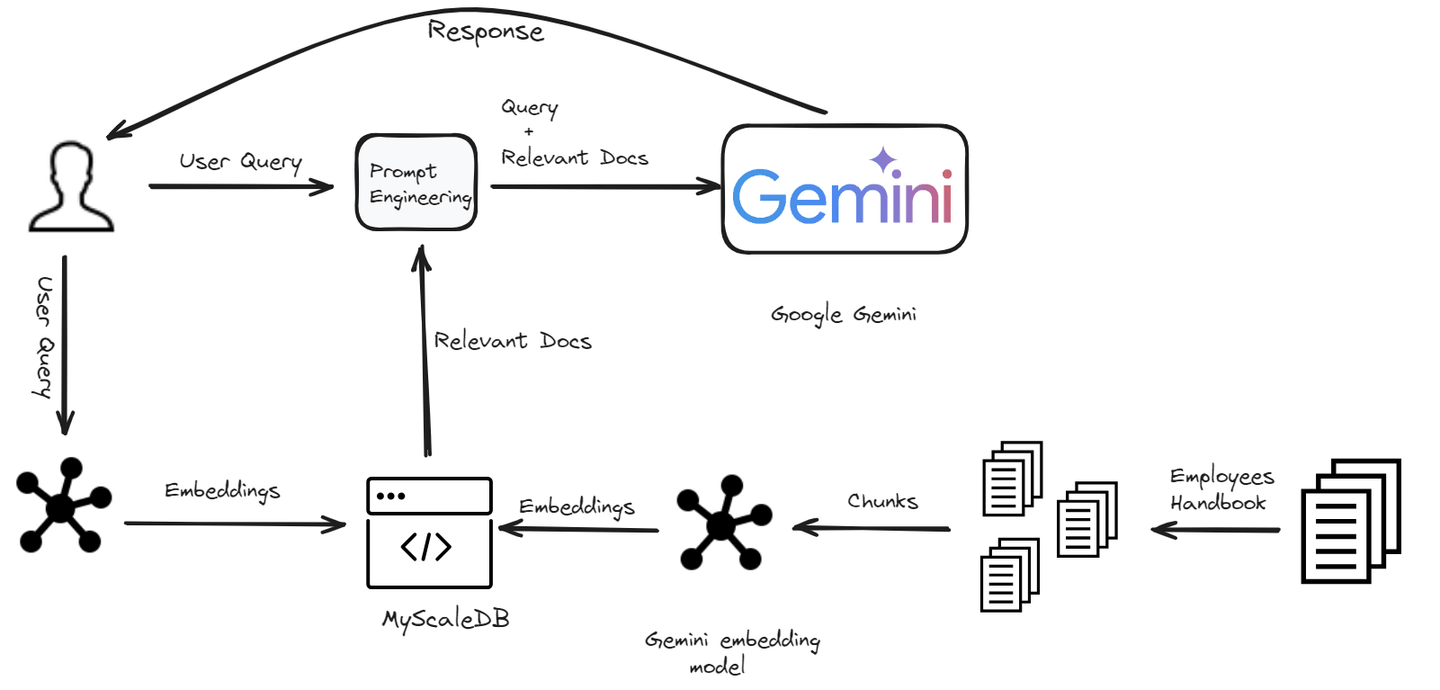
# 環境のセットアップ
# 必要なソフトウェアのインストール
チャットボットの開発の旅を始めるには、必要な依存関係がインストールされていることを確認する必要があります。以下に必要なツールの概要を示します。
Python (opens new window): このチャットボットを構築するためにPythonをプログラミング言語として使用します。
Gemini API (opens new window): Gemini APIを使用して、Gemini LLMにアクセスし、チャットボットで使用します。
LangChain (opens new window): 大規模な言語モデルとベクトルデータベースを統合してスケーラブルなRAGアプリケーションを構築するためのフレームワークです。
MyScaleDB (opens new window): AIアプリケーションを構築するために特別に設計されたSQLベクトルデータベースです。
# Pythonのインストール
すでにPythonがシステムにインストールされている場合は、この手順をスキップできます。そうでない場合は、以下の手順に従ってください。
Pythonのダウンロード: 公式のPythonのウェブサイト (opens new window)にアクセスし、最新バージョンをダウンロードします。
Pythonのインストール: ダウンロードしたインストーラを実行し、画面の指示に従ってインストールを行います。Pythonをシステムパスに追加するオプションにチェックを入れることを忘れないでください。
# Gemini、LangChain、MyScaleDBのインストール
これらの依存関係をすべてインストールするには、ターミナルに以下のコマンドを入力します。
pip install gemini-api langchain clickhouse-client
上記のコマンドは、チャットボットの開発に必要なすべてのパッケージをインストールするはずです。それでは、開発プロセスを始めましょう。
# チャットボットの構築
私たちは、特に会社の従業員向けに設計されたチャットボットを構築しています。このチャットボットは、従業員が会社のポリシーに関連する質問を持つ場合に役立ちます。ドレスコードの理解から休暇ポリシーの明確化まで、チャットボットは迅速かつ正確な回答を提供します。
# ドキュメントの読み込みと分割
最初のステップは、データを読み込み、LangChainのPyPDFLoaderモジュールを使用して分割することです。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Employee_Handbook.pdf")
pages = loader.load_and_split()
pages = pages[4:] # 最初の数ページは不要なのでスキップします
text = "\n".join([doc.page_content for doc in pages])
ドキュメントを読み込み、ページに分割し、最初の数ページをスキップします。すべてのページのテキストは、1つの文字列に連結されます。
注意:
このハンドブックは、kaggleのリポジトリ (opens new window)から使用しています。
次に、このテキストをより扱いやすくするために、小さなチャンクに分割します。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=150,
length_function=len,
is_separator_regex=False,
)
docs = text_splitter.create_documents([text])
for i, d in enumerate(docs):
d.metadata = {"doc_id": i}
ここでは、RecursiveCharacterTextSplitterを使用して、テキストを500文字ずつのチャンクに分割し、連続性を確保するために150文字のオーバーラップを持つようにします。
# 埋め込みの生成
チャットボットが関連する情報を理解し、取得するためには、各テキストのチャンクに対して埋め込みを生成する必要があります。これらの埋め込みは、テキストの意味的な意味を捉えた数値表現です。
import os
import google.generativeai as genai
import pandas as pd
os.environ["GEMINI_API_KEY"] = "your_key_here"
# この関数は文を引数として受け取り、その埋め込みを返します
def get_embeddings(text):
# 埋め込みモデルを定義します
model = 'models/embedding-001'
# 埋め込みを取得します
embedding = genai.embed_content(model=model,
content=text,
task_type="retrieval_document")
return embedding['embedding']
# ドキュメントからpage_contentを取得し、新しいリストを作成します
content_list = [doc.page_content for doc in docs]
# 1つのpage_contentを送信します
embeddings = [get_embeddings(content) for content in content_list]
# データフレームを作成してデータベースにインジェストします
dataframe = pd.DataFrame({
'page_content': content_list,
'embeddings': embeddings
})
Google Geminiを使用して、テキストの各チャンクに対して埋め込みを生成するためのget_embeddings関数を定義します。これらの埋め込みは、さらなる処理のためにDataFrameに格納されます。
注意:
Geminiモデルからembedding-001モデルを使用しており、ここからGemini APIを取得できます (opens new window)。
# MyScaleDBにデータを格納する
テキストのチャンクとそれに対応する埋め込みが準備できたら、次のステップはこのデータをMyScaleDBに格納することです。これにより、後で効率的な検索操作を実行することができます。まず、MyScaleDBとの接続を作成しましょう。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your_host_name',
port="port_number,
username='your_username',
password='yiur_password_hhere'
)
MyScaleDBアカウントの資格情報を取得するには、クイックスタートガイド (opens new window)に従ってください。
# テーブルの作成とデータの挿入
DBとの接続が作成されたら、次のステップはテーブルの作成(MyScaleDBはSQLベクトルDBなので)とデータの挿入です。
# テーブル名を 'handbook' としてテーブルを作成します
client.command("""
CREATE TABLE default.handbook (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 768
) ENGINE = MergeTree()
ORDER BY id
""")
# CONSTRAINTは、各埋め込みベクトルの長さが768であることを確認します
# データをバッチで挿入します
batch_size = 10
num_batches = len(dataframe) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = dataframe[start_idx:end_idx]
# データを挿入します
client.insert("default.handbook", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
# クイックなデータの検索のためにベクトルインデックスを作成します
client.command("""
ALTER TABLE default.handbook
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
データは効率的に挿入するためにバッチで挿入され、ベクトルインデックスが追加され、高速な類似検索が可能になります。
# 関連するドキュメントの取得
データが格納されたら、次のステップは埋め込みを使用して、与えられたユーザークエリに対して最も関連性の高いドキュメントを取得することです。
def get_relevant_docs(user_query):
# get_embeddings関数を再度呼び出して、ユーザークエリをベクトル埋め込みに変換します
query_embeddings = get_embeddings(user_query)
# クエリを実行します
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.handbook ORDER BY dist LIMIT 3
""")
relevant_docs = []
for row in results.named_results():
relevant_docs.append(row['page_content'])
return relevant_docs
この関数は、まずユーザークエリの埋め込みを生成し、その埋め込みの類似性に基づいてデータベースから上位3つの関連するテキストチャンクを取得します。
# 応答の生成
最後に、取得したドキュメントを使用して、ユーザーのクエリに対する応答を生成します。
def make_rag_prompt(query, relevant_passage):
relevant_passage = ' '.join(relevant_passage)
prompt = (
f"You are a helpful and informative chatbot that answers questions using text from the reference passage included below. "
f"Respond in a complete sentence and make sure that your response is easy to understand for everyone. "
f"Maintain a friendly and conversational tone. If the passage is irrelevant, feel free to ignore it.\n\n"
f"QUESTION: '{query}'\n"
f"PASSAGE: '{relevant_passage}'\n\n"
f"ANSWER:"
)
return prompt
import google.generativeai as genai
def generate_response(user_prompt):
model = genai.GenerativeModel('gemini-pro')
answer = model.generate_content(user_prompt)
return answer.text
def generate_answer(query):
relevant_text = get_relevant_docs(query)
text = " ".join(relevant_text)
prompt = make_rag_prompt(query, relevant_passage=relevant_text)
answer = generate_response(prompt)
return answer
answer = generate_answer(query="What is the Work Dress Code?")
print(answer)
make_rag_prompt関数は、関連するドキュメントを使用してチャットボットのためのプロンプトを作成します。generate_response関数は、プロンプトとGoogle Geminiを使用して応答を生成し、generate_answer関数は、関連するドキュメントを取得し、ユーザーのクエリに対する応答を生成するためにすべてを結びつけます。
注意: このブログでは、Gemini Pro 1.0 (opens new window)を使用しています。なぜなら、無料版ではより多くのリクエストが可能だからです。GeminiにはGemini 1.5 Pro (opens new window)やGemini 1.5 Flash (opens new window)などの高度なモデルもありますが、これらのモデルはより制限のある無料版であり、広範な使用には高いコストがかかります。
チャットボットの出力の一部は次のようになります。

チャットボットにオフィスのランチタイムについて尋ねた場合:

これらの手順をチャットボットの開発プロセスに統合することで、Google GeminiとMyScaleDBのパワーを最大限に活用して、洗練されたAIパワードのチャットボットを構築することができます。実験が重要です。チャットボットを継続的にパフォーマンスを向上させるために微調整してください。好奇心を持ち、革新的であり続け、チャットボットが会話の驚異に進化するのを見守ってください!

# 結論
RAGの登場により、GeminiやGPTなどの大規模な言語モデルを統合することで、チャットボットの開発プロセスが革新されました。これらの高度なLLMは、ベクトルデータベースから関連情報を取得し、より正確で事実に基づき、文脈に適した応答を生成することで、チャットボットのパフォーマンスを向上させます。この変化により、開発時間とコストが削減されるだけでなく、より知的で反応性の高いチャットボットによりユーザーエクスペリエンスが大幅に向上します。
RAGモデルのパフォーマンスは、ベクトルデータベースの効率性に大きく依存しています。ベクトルデータベースが迅速に関連するドキュメントを取得できる能力は、ユーザーに迅速な応答を提供するために重要です。RAGシステムをスケーリングする際には、この高いパフォーマンスを維持することがさらに重要になります。MyScaleDBは、ClickHouseから継承した高いスケーラビリティと最小のレイテンシで迅速なクエリ応答を提供するため、この目的には最適な選択肢です。また、新規ユーザーには500万件の無料ベクトルストレージも提供されており、小規模なアプリケーションの開発に簡単に使用することができます。
もしもっと詳しく話し合いたい場合は、MyScaleのDiscord (opens new window)に参加して、ご意見やフィードバックを共有してください。



