
検索補完生成(RAG) (opens new window)は、チャットボット (opens new window)、推薦システム (opens new window)、その他のパーソナライズツールを含むカスタマイズされたAIアプリケーションの開発によく使用されます。このシステムは、ベクトルデータベースと大規模言語モデル(LLM)の強みを活用して高品質な結果を提供します。
RAGモデルに適したLLMを選択することは非常に重要であり、コスト、プライバシーの問題、スケーラビリティなどの要素を考慮する必要があります。OpenAIのGPT-4 (opens new window)やGoogleのGemini (opens new window)などの商用LLMは効果的ですが、高額でデータプライバシーの問題を引き起こす可能性があります。一部のユーザーは、柔軟性とコスト削減のためにオープンソースLLM (opens new window)を選択することがありますが、これにはGPUや専用のインフラストラクチャなどのリソースが必要です。また、モデルの更新とスケーラビリティの管理は、ローカル環境でのセットアップでは課題となる場合があります。
より良い解決策は、オープンソースLLMを選択し、クラウド上に展開することです。このアプローチは、高いコンピューティングパワーとスケーラビリティを提供し、ローカルホスティングの高コストと複雑さを排除します。初期のインフラストラクチャコストを節約するだけでなく、メンテナンスの問題も最小限に抑えることができます。
クラウドホステッドのオープンソースLLMとスケーラブルなベクトルデータベースを使用してアプリケーションを開発するために、いくつかのツールが必要です。
- BentoML (opens new window):BentoMLは、機械学習モデルを本番用のAPIに簡単に展開し、スケーラビリティと管理の容易さを確保するオープンソースプラットフォームです。
- LangChain (opens new window):LangChainは、LLMを使用したアプリケーションを構築するためのフレームワークです。簡単な統合とカスタマイズのためのモジュラーコンポーネントを提供します。
- MyScaleDB (opens new window):MyScaleDBは、効率的なデータの取得と保存を最適化した高性能でスケーラブルなデータベースであり、高度なクエリ機能をサポートしています。
このチュートリアルでは、LangChainのWikipediaLoaderモジュールを使用してWikipediaからデータを抽出し、そのデータ上にLLMを構築します。
注意:
MyScaleの例のリポジトリで完全なPythonノートブック (opens new window)を見つけることができます。
# 準備
# 環境のセットアップ
ターミナルを開き、次のコマンドを入力してBentoML、MyScaleDB、LangChainをインストールします。
pip install bentoml langchain clickhouse-connect
これにより、システムに3つのパッケージがインストールされます。これで、コードを書いてRAGアプリケーションを開発する準備が整いました。
# データの読み込み
まず、langchain_community.document_loaders.wikipediaモジュールからWikipediaLoader (opens new window)をインポートします。このローダーを使用して、"アルバート・アインシュタイン"に関連するドキュメント (opens new window)を取得します。
from langchain_community.document_loaders.wikipedia import WikipediaLoader
loader = WikipediaLoader(query="Albert Einstein")
# ドキュメントを読み込む
docs = loader.load()
# 最初のドキュメントの内容を表示する
print(docs[0].page_content)
loadメソッドを使用して「アルバート・アインシュタイン"のドキュメントを取得し、printメソッドを使用して最初のドキュメントの内容を表示して、読み込まれたデータを確認します。
# テキストをチャンクに分割する
langchain_text_splittersからCharacterTextSplitter (opens new window)をインポートし、すべてのページの内容を1つの文字列に結合し、テキストを管理可能なチャンクに分割します。
from langchain_text_splitters import CharacterTextSplitter
# テキストをチャンクに分割する
text = ' '.join([page.page_content.replace('\\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
CharacterTextSplitterは、このテキストを400文字のチャンクに分割し、チャンク間で情報が失われないように100文字のオーバーラップを持つように設定されています。page_contentまたはテキストはsplits配列に格納され、テキストの内容のみが含まれます。このsplits配列を使用して埋め込み (opens new window)を取得します。
# BentoMLでモデルをデプロイする
データが準備できたら、次のステップはBentoMLでモデルをデプロイし、それらをRAG (opens new window)アプリケーションで使用することです。まず、無料のBentoMLアカウントが必要です。必要に応じて、BentoCloudでサインアップ (opens new window)してください。次に、デプロイメントセクションに移動し、右上隅の「Create Deployment"ボタンをクリックします。次のような新しいページが開きます。
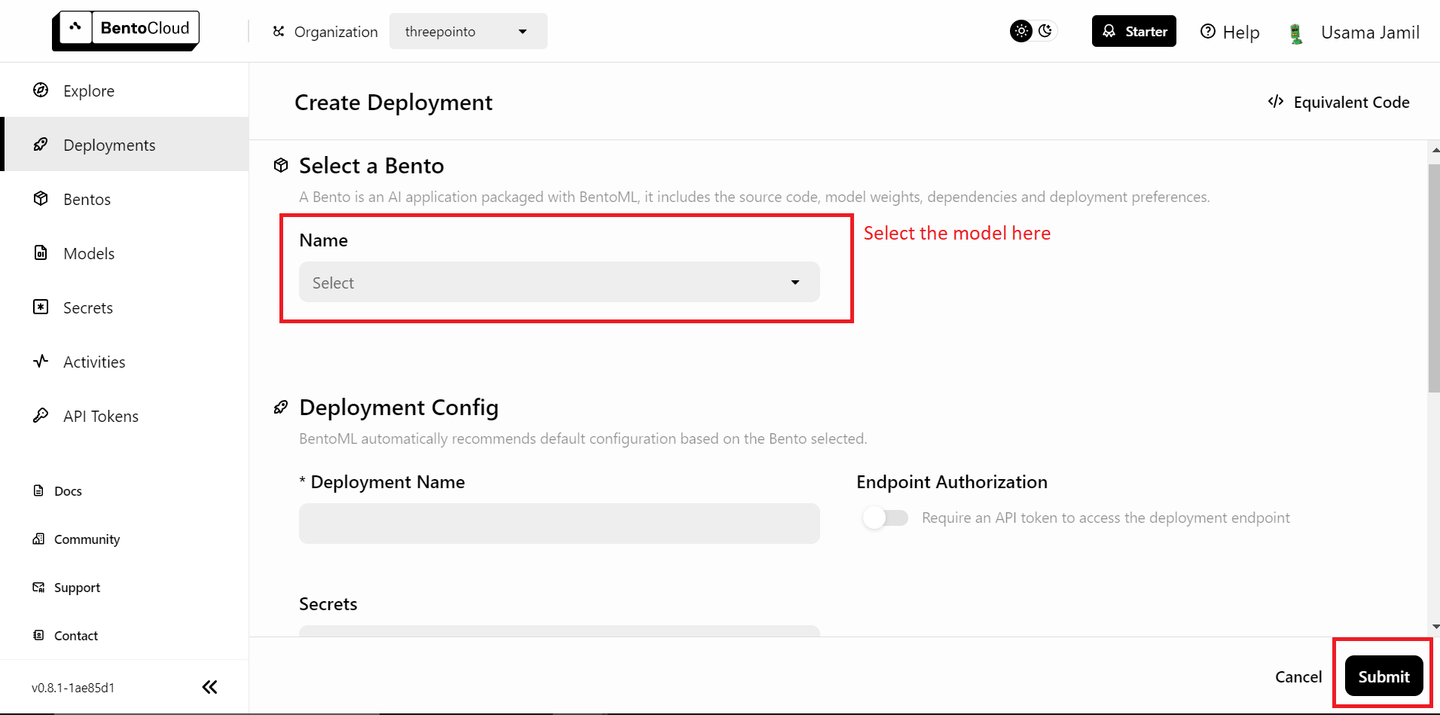
ドロップダウンから「bentoml/bentovllm-llama3-8b-instruct-service (opens new window)"モデルを選択し、「Submit"をクリックします。これにより、モデルのデプロイが開始されます。次のような新しいページが開きます。
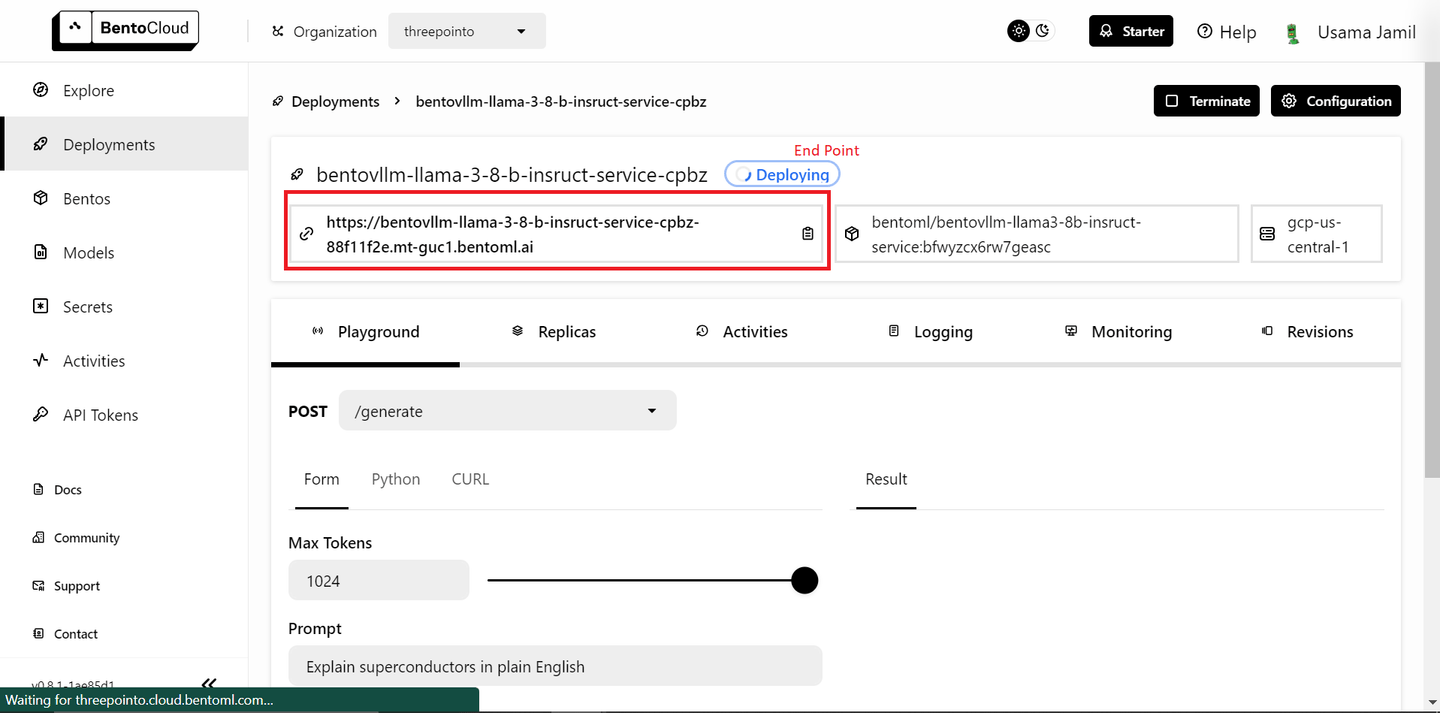
デプロイには時間がかかる場合があります。デプロイが完了したら、エンドポイントをコピーします。
注意:
BentoMLの無料版では、1つのモデルのデプロイのみが許可されています。有料プランを持っていて複数のモデルをデプロイできる場合は、以下の手順に従ってください。そうでない場合は心配しないでください。埋め込みのためにローカルでオープンソースモデルを使用します。
埋め込みモデルをデプロイする手順は、LLMをデプロイする手順と非常に似ています。
- デプロイメントページに移動します。
- 「Create Deployment」ボタンをクリックします。
- リストから
sentence-transformersモデルを選択し、「Submit」をクリックします。 - デプロイが完了したら、エンドポイントをコピーします。
次に、APIトークンページ (opens new window)に移動し、新しいAPIキーを生成します。これで、デプロイされたモデルをRAGアプリケーションで使用する準備が整いました。
# 埋め込みメソッドを定義する
提供されたテキストの埋め込みを生成するためのget_embeddingsという関数を定義します。この関数は3つの引数を受け取ります。BentoMLのエンドポイントとAPIトークンが指定されている場合、関数はBentoMLの埋め込みサービスを使用します。それ以外の場合は、ローカルのtransformersとtorchライブラリを使用して、sentence-transformers/all-MiniLM-L6-v2モデルをロードし、埋め込みを生成します。
# ライブラリをインポートする
import subprocess
import sys
import numpy as np
# APIキーが指定されていない場合はパッケージをインストールする
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
# 埋め込みメソッドを定義する
def get_embeddings(texts: list, BENTO_EMBEDDING_MODEL_END_POINT=None, BENTO_API_TOKEN=None) -> list:
# BentoMLのキーが指定されている場合、メソッドはBENTOMLモデルを使用して埋め込みを取得します
if BENTO_EMBEDDING_MODEL_END_POINT and BENTO_API_TOKEN:
import bentoml
embedding_client = bentoml.SyncHTTPClient(BENTO_EMBEDDING_MODEL_END_POINT, token=BENTO_API_TOKEN)
return embedding_client.encode(sentences=texts).tolist()
# それ以外の場合はtransformersライブラリを使用します
else:
# transformersとtorchがインストールされていない場合はインストールします
try:
import transformers
except ImportError:
install("transformers")
try:
import torch
except ImportError:
install("torch")
from transformers import AutoTokenizer, AutoModel
# 埋め込みのためのトークナイザとモデルを初期化する
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
このセットアップにより、無料のBentoMLユーザーは1度に1つのモデルのみをデプロイできるため、柔軟性があります。BentoMLの有料バージョンを使用して2つのモデルをデプロイできる場合は、デプロイされた埋め込みモデルを使用するためにBentoMLエンドポイントとBento APIトークンを渡すことができます。
# 埋め込みを取得する
get_embeddings関数を使用して、splitsのテキストチャンクを25個ずつのバッチで反復処理し、埋め込みを生成します。
all_embeddings = []
# splitsを25個ずつのバッチで渡す
for i in range(0, len(splits), 25):
batch = splits[i:i+25]
# バッチをget_embeddingsメソッドに渡す
embeddings_batch = get_embeddings(batch)
# バッチの埋め込みをall_embeddingsリストに追加する
all_embeddings.extend(embeddings_batch)
これにより、一度に大量のデータを埋め込みモデルに過負荷にすることがなくなり、メモリと計算リソースの管理に役立ちます。
# DataFrameの作成
次に、テキストチャンクとそれに対応する埋め込みを格納するためのpandas (opens new window) DataFrameを作成します。
import pandas as pd
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})
この構造化された形式は、データの操作とMyScaleDBへの格納を容易にします。
# MyScaleDBに接続する
ナレッジベースが完成し、データをベクトルデータベースに保存する準備が整いました。このデモでは、ベクトルストレージにMyScaleDBを使用します。クイックスタートガイド (opens new window)に従ってクラウド環境でMyScaleDBクラスタを起動し、clickhouse_connectライブラリを使用してMyScaleDBデータベースに接続します。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name',
port=443,
username='your-user-name',
password='your-password'
)
ここで作成されたclientオブジェクトは、SQLコマンドの実行とデータベースとの対話に使用されます。
# テーブルの作成とデータの挿入
MyScaleDBにテキストチャンクと埋め込みを格納するためのテーブルを作成します。テーブルのスキーマにはid、page_content、embeddingsが含まれます。
# RAGという名前のテーブルを作成する
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
# データをテーブルに挿入する
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
これにより、埋め込みの長さが固定された384になります。DataFrameのデータは、大量のデータを効率的に管理するためにバッチでテーブルに挿入されます。
# ベクトルインデックスの作成
次のステップは、RAGテーブルのembeddings列にベクトルインデックスを追加することです。ベクトルインデックスにより、検索補完生成タスクにおける効率的な類似度検索が可能になります。
client.command("""
ALTER TABLE default.RAG
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# 関連するベクトルの取得
ユーザーのクエリに基づいて関連するドキュメントを取得するための関数を定義します。クエリの埋め込みはget_embeddings関数を使用して生成され、データベース内で最も近いマッチを見つけるために高度なSQLベクトルクエリが実行されます。
def get_relevant_docs(user_query, top_k):
query_embeddings = get_embeddings(user_query)[0]
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.RAG ORDER BY dist LIMIT {top_k}
""")
relevant_docs = " "
for row in results.named_results():
relevant_docs=relevant_docs + row["page_content"]
return relevant_docs
# クエリの例
message="アルバート・アインシュタインは誰ですか?"
relevant_docs = get_relevant_docs(message, 8)
print(relevant_docs)
結果は距離によって並べ替えられ、上位k個のマッチが返されます。このセットアップにより、特定のクエリに対して最も関連性の高いドキュメントを見つけることができます。
注意:
distanceメソッドは、埋め込み列とユーザークエリの埋め込みベクトルを取り、コサイン類似度を適用して類似するドキュメントを見つけるために使用されます。
# BentoML LLMに接続する
ホストされているBentoML LLMに接続します。llm_clientオブジェクトは、取得したドキュメントに基づいて応答を生成するためにLLMと対話するために使用されます。
import bentoml
BENTO_LLM_END_POINT = "ここにエンドポイントを追加"
llm_client = bentoml.SyncHTTPClient(BENTO_LLM_END_POINT, token="ここにトークンを追加")
BENTO_LLM_END_POINTとtokenを、LLMデプロイ時にコピーした値に置き換えます。
# RAGを実行する
RAGを実行するための関数を定義します。この関数はユーザーの質問と取得したコンテキストを入力として受け取ります。それはLLMに対してプロンプトを構築し、提供されたコンテキストに基づいて質問に答えるように指示します。LLMからの応答が回答として返されます。
def dorag(question: str, context: str):
# プロンプトテンプレートを定義する
prompt = (f"You are a helpful assistant. The user has a question. Answer the user question based only on the context: {context}. \\n"
f"The user question is {question}")
# 上記で定義したプロンプトでLLMエンドポイントを呼び出す
results = llm_client.generate(
max_tokens=1024,
prompt=prompt,
)
res = ""
for result in results:
res += result
return res

# クエリを実行する
最後に、RAGアプリケーションにクエリを実行してテストすることができます。質問「アルバート・アインシュタインは誰ですか?」を尋ね、先に取得した関連ドキュメントに基づいて回答を取得するためにdorag関数を使用します。
query = "アルバート・アインシュタインは誰ですか?"
dorag(question=query, context=relevant_docs)
出力は、RAGのセットアップの効果を示す質問に対する詳細な回答を提供します。

アルバート・アインシュタインの死についてRAGモデルに尋ねると、次のような応答が表示されます。

# 結論
BentoMLは、リソースの管理の手間を省いて機械学習モデル(LLMを含む)を展開するための優れたプラットフォームです。BentoMLを使用すると、クラウド上でAIアプリケーションを迅速に展開してスケーラブルにすることができます。シンプルさと柔軟性により、開発者はイノベーションにより集中し、展開の複雑さにより少なく集中することができます。
一方、MyScaleDBは、RAGアプリケーションに特化した高性能なSQLベクトルデータベースであり、効率的でスケーラブルなAIソリューションを実装するために開発されています。MyScaleDBのMulti-Scale Tree Graph(MSTG) (opens new window)アルゴリズムは、速度と精度の面で他のベクトルデータベースを大幅に上回ります。また、新規ユーザー向けに、MyScaleDBには500万個の768Dベクトルのストレージへのアクセス権が含まれており、効率的でスケーラブルなAIソリューションを実装する開発者にとって魅力的なオプションです。
このプロジェクトについてどう思いますか?Twitter (opens new window)とDiscord (opens new window)でご意見をお聞かせください。



