
検索増強生成(RAG) (opens new window)は、データとの対話方法を革新し、類似検索において非常に優れたパフォーマンスを提供します。シンプルなクエリに基づいて関連情報を取得することに優れています。しかし、RAGは、時間ベースのクエリや複雑な関係データベースクエリなどのより複雑なタスクを処理する際にはしばしば限界に直面します。これは、RAGが主に外部ソースからの関連情報を持つ拡張テキスト生成に特化しているためであり、正確で条件付きのデータ検索を行うことは主な目的ではありません。これらの制限により、正確で条件付きのデータ検索が必要なシナリオでのRAGの適用が制約されます。
当社の高度なRAGモデルは、SQLベクトルデータベースを基にしており、さまざまなクエリタイプを効率的に処理します。単純な類似検索だけでなく、時間ベースのクエリや複雑な関係クエリにも優れています。
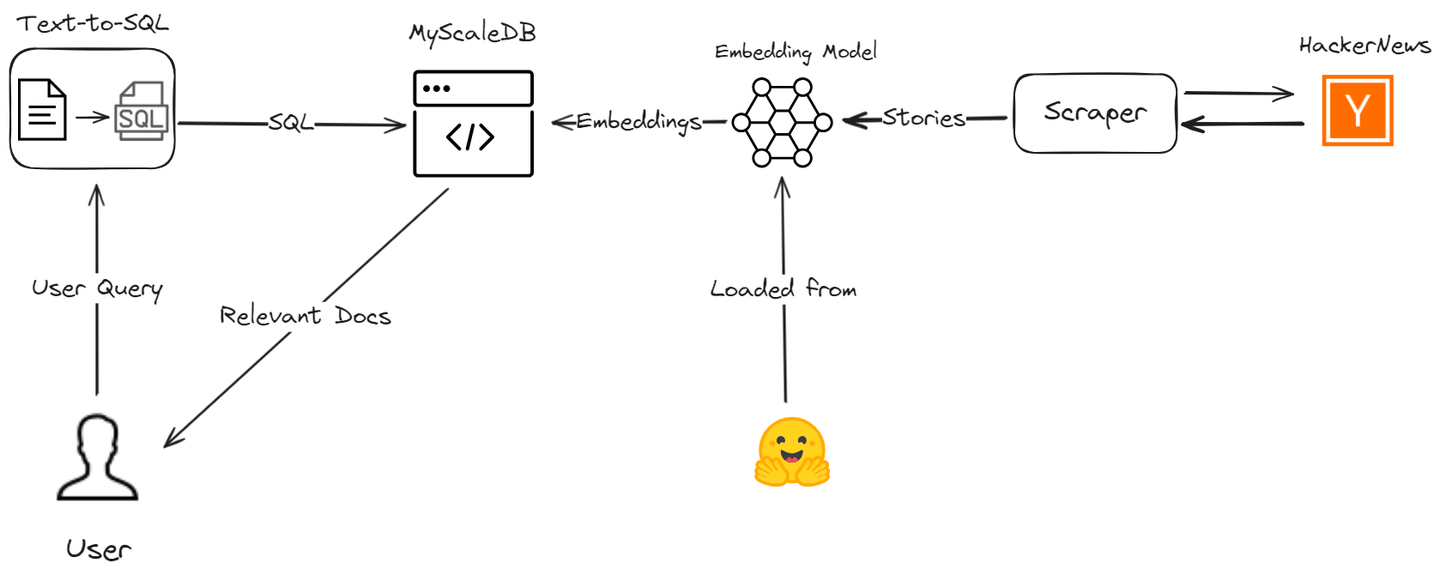
ここでは、MyScaleとLangChainを使用してAIアシスタントを作成し、データの検索プロセスの精度と効率を向上させる方法について説明します。Hacker Newsから最新のストーリーをスクレイピングし、RAGアプリケーションを高度なSQLベクトルクエリで強化するためのプロセスを説明します。
# ツールとテクノロジー
このプロジェクトでは、MyScaleDB、OpenAI、LangChain、Hugging Face、HackerNews APIなど、さまざまなツールを使用します。
- MyScaleDB (opens new window): MyScaleは、構造化および非構造化データを効率的に格納および処理するSQLベクトルデータベースです。
- OpenAI (opens new window): OpenAIのチャットモデルを使用して、テキストからSQLクエリを生成します。
- LangChain: LangChainは、ワークフローの構築とMyScaleおよびOpenAIとのシームレスな統合をサポートします。
- Hugging Face (opens new window): Hugging Faceの埋め込みモデルを使用してテキストの埋め込みを取得し、MyScaleでさらなる分析のために格納します。
- HackerNews (opens new window) API: このAPIは、HackerNewsからリアルタイムのデータを取得して処理および分析します。
# 準備
# 環境のセットアップ
コードを書く前に、必要なライブラリと依存関係がすべてインストールされていることを確認する必要があります。次のコマンドを使用してこれらをインストールできます。
pip install requests clickhouse-connect transformers openai langchain
このpipコマンドにより、このプロジェクトで必要なすべての依存関係がインストールされます。
# ライブラリのインポートとヘルパー関数の定義
まず、必要なライブラリをインポートし、Hacker Newsからデータを取得および処理するために使用されるヘルパー関数を定義します。
import requests
from datetime import datetime, timedelta
import pandas as pd
import numpy as np
# 特定のエンドポイントからストーリーIDを取得する
def fetch_story_ids(endpoint):
url = f'https://hacker-news.firebaseio.com/v0/{endpoint}.json'
response = requests.get(url)
return response.json()
# 特定のIDのアイテムの詳細を取得する
def get_item_details(item_id):
item_url = f'https://hacker-news.firebaseio.com/v0/item/{item_id}.json'
item_response = requests.get(item_url)
return item_response.json()
# ストーリーのコメントを再帰的に取得する
def fetch_comments(comment_ids, depth=0):
comments = []
for comment_id in comment_ids:
comment_details = get_item_details(comment_id)
if comment_details and comment_details.get('type') == 'comment':
comment_text = comment_details.get('text', '[deleted]')
comment_by = comment_details.get('by', 'Anonymous')
indent = ' ' * depth * 2
comments.append(f"{indent}Comment by {comment_by}: {comment_text}")
if 'kids' in comment_details:
comments.extend(fetch_comments(comment_details['kids'], depth + 1))
return comments
# コメントのリストを単一の文字列に変換する
def create_comment_string(comments):
return ' '.join(comments)
# 時間制限を12時間前に設定する
time_limit = datetime.utcnow() - timedelta(hours=12)
unix_time_limit = int(time_limit.timestamp())
これらの関数は、ストーリーIDを取得し、特定のアイテムの詳細を取得し、再帰的にコメントを取得し、コメントを単一の文字列に変換します。
# ストーリーの取得と処理
次に、Hacker Newsから最新のトップストーリーを取得し、関連するデータを抽出するために、最新のストーリーを取得します。
# 最新のトップストーリーを取得する
latest_stories_ids = fetch_story_ids('newstories')
top_stories_ids = fetch_story_ids('topstories')
# 上位20のストーリーを取得する
top_stories = [get_item_details(story_id) for story_id in top_stories_ids[:20]]
# 過去12時間のすべての最新のストーリーを取得する
latest_stories = [get_item_details(story_id) for story_id in latest_stories_ids if get_item_details(story_id).get('time', 0) >= unix_time_limit]
# DataFrameのためのデータを準備する
data = []
def process_stories(stories):
for story in stories:
if story:
story_time = datetime.utcfromtimestamp(story.get('time', 0))
if story_time >= time_limit:
story_data = {
'Title': story.get('title', 'No Title'),
'URL': story.get('url', 'No URL'),
'Score': story.get('score', 0),
'Time': convert_unix_to_datetime(story.get('time', 0)),
'Writer': story.get('by', 'Anonymous'),
'Comments': story.get('descendants', 0) # コメントの数を正しく処理する
}
# コメントがある場合はコメントを取得する
if 'kids' in story:
comments = fetch_comments(story['kids'])
story_data['Comments_String'] = create_comment_string(comments)
else:
story_data['Comments_String'] = ""
data.append(story_data)
# 最新のストーリーとトップストーリーを処理する
process_stories(latest_stories)
process_stories(top_stories)
# DataFrameを作成する
df = pd.DataFrame(data)
# 正しいデータ型を確保する
df['Score'] = df['Score'].astype(np.uint64)
df['Comments'] = df['Comments'].astype(np.uint64)
df['Time'] = pd.to_datetime(df['Time'])
上記で定義したヘルパー関数を使用して、Hacker Newsから最新のストーリーとトップストーリーを取得します。取得したストーリーを処理して、タイトル、URL、スコア、時間、作成者、コメントなどの関連情報を抽出します。コメントのリストを単一の文字列に変換します。
# 埋め込みの生成のためのHugging Faceモデルの初期化
事前学習済みモデルを使用して、ストーリーのタイトルとコメントの埋め込みを生成します。これは、検索増強生成(RAG)システムの作成には重要なステップです。
import torch
from transformers import AutoTokenizer, AutoModel
# 埋め込みのためのトークナイザーとモデルの初期化
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# DataFrameが作成された後に埋め込みを生成する
empty_embedding = np.zeros(384, dtype=np.float32) # 埋め込みのサイズが384であると仮定
def generate_embeddings(texts):
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().astype(np.float32).flatten()
Hugging Faceのtransformersライブラリを使用して事前学習済みモデルをロードし、ストーリーのタイトルとコメントの埋め込みを生成します。
# 長いコメントの処理
モデルの最大トークン長を超える長いコメントを処理するために、それらを管理可能なパーツに分割します。
# 長いコメントを処理するための関数
def handle_long_comments(comments, max_length):
parts = [' '.join(comments[i:i + max_length]) for i in range(0, len(comments), max_length)]
return parts
この関数は、モデルの最大トークン長に収まるパーツに長いコメントを分割します。
# 埋め込みのためのストーリーの処理
最後に、各ストーリーを処理してタイトルとコメントの埋め込みを生成し、最終的なDataFrameを作成します。
# 埋め込みのために各ストーリーを処理する
final_data = []
for story in data:
title_embedding = generate_embeddings([story['Title']]).tolist()
comments_string = story['Comments_String']
if comments_string and isinstance(comments_string, str):
max_length = tokenizer.model_max_length # モデルの最大トークン長を使用
if len(comments_string.split()) > max_length:
parts = handle_long_comments(comments_string.split(), max_length)
for part in parts:
part_comments_string = ' '.join(part)
comments_embeddings = generate_embeddings([part_comments_string]).tolist() if part_comments_string else empty_embedding.tolist()
final_data.append({
'Title': story['Title'],
'URL': story['URL'],
'Score': story['Score'],
'Time': story['Time'],
'Writer': story['Writer'],
'Comments': story['Comments'],
'Comments_String': part_comments_string,
'Title_Embedding': title_embedding,
'Comments_Embedding': comments_embeddings
})
else:
comments_embeddings = generate_embeddings([comments_string]).tolist() if comments_string else empty_embedding.tolist()
final_data.append({
'Title': story['Title'],
'URL': story['URL'],
'Score': story['Score'],
'Time': story['Time'],
'Writer': story['Writer'],
'Comments': story['Comments'],
'Comments_String': comments_string,
'Title_Embedding': title_embedding,
'Comments_Embedding': comments_embeddings
})
else:
story['Title_Embedding'] = title_embedding
story['Comments_Embedding'] = empty_embedding.tolist()
final_data.append(story)
# 最終的なDataFrameを作成する
final_df = pd.DataFrame(final_data)
# 最終的なDataFrameの正しいデータ型を確保する
final_df['Score'] = final_df['Score'].astype(np.uint64)
final_df['Comments'] = final_df['Comments'].astype(np.uint64)
final_df['Time'] = pd.to_datetime(final_df['Time'])
このステップでは、各ストーリーを処理してタイトルとコメントの埋め込みを生成し、必要に応じて長いコメントを処理し、すべての処理済みデータを含む最終的なDataFrameを作成します。
# MyScaleDBへの接続とテーブルの作成
MyScaleDBは、SQLベクトルデータベースにおける複雑なクエリの効率的な処理 (opens new window)や、全文検索 (opens new window)やフィルタリングされたベクトル検索 (opens new window)などの類似検索を最適化することで、RAGモデルを強化します。
提供された認証情報を使用してMyScaleDBに接続し、スクレイピングしたストーリーを格納するためのテーブルを作成します。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host',
port=443,
username='your-username',
password='your-password'
)
client.command("DROP TABLE IF EXISTS default.posts")
client.command("""
CREATE TABLE default.posts (
id UInt64,
Title String,
URL String,
Score UInt64,
Time DateTime64,
Writer String,
Comments UInt64,
Title_Embedding Array(Float32),
Comments_Embedding Array(Float32),
CONSTRAINT check_data_length CHECK length(Title_Embedding) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
このコードは、clickhouse-connectライブラリをインポートし、提供された認証情報を使用してMyScaleDBに接続します。既存のテーブルdefault.postsが存在する場合は削除し、指定されたスキーマで新しいテーブルを作成します。
注意: MyScaleDBは、500万ベクトルのベクトルストレージのための無料のポッドを提供しています。そのため、初期費用なしでMyScaleDBをRAGアプリケーションで使用できます。
# データの挿入とベクトルインデックスの作成
次に、処理済みのデータをMyScaleDBテーブルに挿入し、データの効率的な取得を可能にするためにインデックスを作成します。
batch_size = 20 # 必要に応じて調整
num_batches = len(final_df) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = final_df[start_idx:end_idx]
client.insert("default.posts", batch_data, column_names=['Title', 'URL', 'Score', "Time",'Writer', 'Comments','Title_Embedding','Comments_Embedding'])
print(f"Batch {i+1}/{num_batches} inserted.")
client.command("""
ALTER TABLE default.posts
ADD VECTOR INDEX photo_embed_index Title_Embedding
TYPE MSTG
('metric_type=Cosine')
""")
このコードは、データをdefault.postsテーブルにバッチごとに挿入して大量のデータを効率的に処理します。ベクトルインデックスはTitle_Embedding列に作成されます。
# クエリ生成のためのプロンプトテンプレートの設定
ユーザーの入力をMyScaleDBのSQLクエリに変換するためのプロンプトテンプレートを設定します。
prompt_template = """
あなたはMyScaleDBのエキスパートです。入力された質問に対して、まず実行する構文的に正しいMyScaleDBクエリを作成し、クエリの結果を確認して入力された質問の回答を返します。
MyScaleDBクエリには、ベクトル距離関数である`DISTANCE(column, array)`があります。この関数は、ユーザーの質問に対する関連性を計算し、関連性に基づいて特徴配列の列をソートして返します。`DISTANCE(column, array)`関数は、最初の引数に配列列を、第二引数に`Embeddings(entity)`を受け入れます。また、エンティティの配列を取得するためのユーザー定義関数`Embeddings(entity)`が必要です。
クエリが特定のキーワード(例:"AIフィールド"や"批判")に基づいて最も近い行を求める場合は、この距離関数を使用してベクトル列内のエンティティの距離を計算し、距離に基づいて関連する行を取得するためにソートします。質問に時間制約(例:"過去7時間")が含まれる場合は、現在の日付と時刻を取得するために`today()`関数を使用します。
クエリで取得する例の数が指定されている場合は、その数を使用します。それ以外の場合は、MyScaleのLIMIT句を使用して最大{top_k}の結果をクエリします。必要な場合にのみ距離関数に基づいてソートします。テーブルからすべての列をクエリしないでください。質問に回答するために必要な列のみをクエリし、各列名を二重引用符(")で囲んで区別された識別子として指定します。
クエリを構築する際には、次の手順に注意してください:
1. 入力された質問からキーワード(例:"最も投票された記事"、"過去7時間"、"AIフィールド")を特定します。
2. キーワードを特定のクエリコンポーネントにマッピングします(例:"最も投票された"は"Score DESC"にマッピングされます)。
3. 質問がキーワードの関連性を必要とする場合(例:"批判")、距離関数を使用します。それ以外の場合は、標準のSQL句を使用します。
4. タイトルまたはコメントが明示的に指定されている場合は、それに応じて距離を計算します。デフォルトでは、タイトルで距離を計算します。
5. `Embeddings(keyword)`を使用してキーワードの埋め込みを取得し、クエリがキーワードの関連性検索を含む場合にのみ`DISTANCE`関数で使用します。
6. 質問でコメントの列が明示的に言及されている場合は、コメントの列も考慮して距離を計算します。
7. 距離が計算されているクエリでは、距離が見つかっていないクエリではdistを使用せず、距離が計算されている他の列でもdistと一緒にorder by distを使用するように注意してください。
質問の例とその処理方法:
1. "過去7時間のAIフィールドで最も投票された記事は何ですか?"
- キーワードを抽出します:"最も投票された記事"、"過去7時間"、"AIフィールド"。
- "最も投票された"を"Score DESC"にマッピングします。
- 過去7時間で最も投票された記事のためのクエリを作成します:
- `SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings('AIフィールド')) FROM posts1 WHERE Time >= today() - INTERVAL 7 HOUR ORDER BY Score DESC LIMIT {top_k}`
2. "コンテンツを批判しているコメントをいくつか教えてください。"
- キーワードを抽出します:"コメント"、"批判"。
- "批判"をDISTANCE関数にマッピングします。
- 関連するコメントのためのクエリを作成します:
- `SELECT DISTINCT "Comments", "Score", DISTANCE("Comments_Embedding", Embeddings('批判')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
3. "過去6時間で最も投票されたストーリーは何ですか?"
- キーワードを抽出します:"最も投票されたストーリー"、"過去6時間"。
- "最も投票された"を"Score DESC"にマッピングします。
- 過去6時間で最も投票されたストーリーのためのシンプルなクエリを作成します:
- `SELECT DISTINCT "Title", "URL", "Score" FROM posts1 WHERE Time >= today() - INTERVAL 6 HOUR ORDER BY Score DESC LIMIT {top_k}`
4. "AIフィールドでトレンドのあるストーリーは何ですか?"
- キーワードを抽出します:"トレンドのあるストーリー"、"AIフィールド"。
- "トレンド"を"Score DESC"にマッピングします。
- AIフィールドでトレンドのあるストーリーのためのクエリを作成します:
- `SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings('AIフィールド')) as dist FROM posts1 ORDER BY dist,Score DESC LIMIT {top_k}`
5. "LLMの最新のトレンドについて議論しているコメントを教えてください。"
- キーワードを抽出します:"コメント"、"LLMの最新のトレンド"。
- "LLMの最新のトレンド"をDISTANCE関数にマッピングします。
- LLMの最新のトレンドについて議論しているコメントのためのクエリを作成します:
- `SELECT DISTINCT "Comments", "Score", DISTANCE("Comments_Embedding", Embeddings('LLMの最新のトレンド')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
これで、モデルによって返されたクエリを取得します。
```sql
'SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings(\'AIフィールド\')) as dist FROM posts1 ORDER BY dist, Score DESC LIMIT 5'
ただし、MyScaleDBのDISTANCEはDISTANCE(column, array)を期待しています。そのため、クエリ文字列内のEmbeddings(\'AIフィールド\')の部分をベクトル埋め込みに変換する必要があります。
# クエリ文字列内の埋め込みの処理と置換
このメソッドは、クエリ文字列内のEmbeddings("抽出されたキーワード")をfloat32の配列に置き換えるために使用されます。
import re
def process_query(query):
pattern = re.compile(r'Embeddings\(([^)]+)\)')
matches = pattern.findall(query)
for match in matches:
processed_embedding = str(list(generate_embeddings(match)))
query = query.replace(f'Embeddings({match})', processed_embedding)
return query
query=process_query1(f"""{response}""")
このメソッドは、クエリをinputとして受け取り、クエリ文字列内にEmbeddingsメソッドが存在する場合は更新されたクエリを返します。

# クエリの実行
最後に、クエリを実行してベクトルデータベースから関連するストーリーを取得します。
query=query.replace("\n","")
results = client.query(f"""{query}""")
for row in results.named_results():
print("Title ", row["Title"])
さらに、モデルによって返されたクエリを取得し、指定された列を抽出して使用して列を取得することもできます。上記のように結果を取得し、それをチャットモデルに渡すことで、完全なAIチャットアシスタントを作成できます。これにより、アシスタントは結果から直接抽出された関連データを使用してユーザーのクエリに動的に応答し、シームレスでインタラクティブな体験を提供できます。
# 結論
シンプルなRAGは、シンプルな類似検索に焦点を当てているため、使用範囲が限られています。しかし、MyScaleDB、LangChainなどの高度なツールと組み合わせることで、RAGアプリケーションは大規模なビッグデータ管理の要件を満たすだけでなく、時間ベースのクエリや複雑な関係クエリなど、さまざまなクエリを処理できるようになります。これにより、現在のシステムのパフォーマンスと効率が大幅に向上します。
ご意見がありましたら、Twitter (opens new window)またはDiscord (opens new window)までお気軽にお問い合わせください。



