
ベクトルを使用することで、時間とリソースを消費する学習を超えて、より高速かつ効果的なシンプルな検索が可能になります。ベクトルデータベースは、数値、テキスト、画像データなどの高次元ベクトルデータを格納するのに非常に役立ちます。MyScaleのようなSQLベクトルデータベースは、SQLのパワーとMSTGインデックスなどの他のクールな機能を使用して、複雑なデータ処理やその他のバックエンド操作について心配する必要がありません。
Amazon (opens new window)Bedrock (opens new window)は、テキストと画像の両方の基礎モデルを使用してAIアプリケーションを構築するためのマネージドサービスです。AWSのスケーラビリティなどの利点を提供し、モデルのプライベートな微調整などが可能です。これらのサービスは、Scikit-learnやNLTKのような通常のPythonライブラリと同様にシームレスに呼び出すことができます。
この記事では、Amazon BedrockとMyScaleを使用して、E-Bookのセマンティック検索アプリケーションの構築方法を示しています。Acrobat Reader、Kindle、Apple Booksなどの従来のE-リーダーでは、検索を正確なキーワードの一致に制限することがよくあります。Amazon Bedrockの埋め込み生成とMyScaleのベクトルデータベースの機能を活用することで、キーワードの一致を超えて意味理解を行うより知的な検索機能を作成します。BedrockのAIモデルの強みとMyScaleの効率的なストレージと検索機能を活用することで、さまざまなアプリケーションでテキスト検索の効果を向上させることができます。
# ライブラリのインストール
Pythonプロジェクトでは、環境を作成することが良い習慣です。ここでは、プロジェクトのためにCondaを使用して環境を作成します。
conda create --name AWS python=3.12
アクティベートした後、各ライブラリをインストールします。
pip install boto3 langchain-aws clickhouse-connect
# MyScaleとの接続
MyScale (opens new window)でアカウントを作成した後、コンソール (opens new window)からクラスタを実行できます。クラスタの詳細に接続文字列が表示されます。単純にコピー/貼り付けしてクラスタに接続します。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name-here',
port=443,
username='your-user-name-here',
password='your-password-here')
注意:
より詳細なステップバイステップの手順については、クイックスタートガイド (opens new window)に従って接続の詳細を取得できます。
# 接続のテスト
接続とライブラリのインストールをテストするために、小さなテストテーブルを作成すると便利です。
# 128次元の浮動小数点ベクトルを持つテーブルを作成します。
client.command("""
CREATE TABLE default.TestTable (
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ORDER BY id
""")
#['0', 'chi-msc-af209a77-msc-af209a77-0-0', 'OK', '0', '0']
クラスタ内のすべてのテーブルを確認し、接続をテストするために「SHOW TABLES」クエリを使用できます。
# 現在のデータベース内のすべてのテーブルの名前を取得して表示します。
res = client.query("SHOW TABLES").named_results()
print([r['name'] for r in res])
# ['TestTable']
# 埋め込みモデルの選択
次に、適切な埋め込みモデルを選択する必要があります。Amazon Bedrockに接続するためには2つの方法があります。1つは、BedrockのIAMユーザを作成するためにAWS公式ウェブサイトにアクセスする方法です。もう1つの方法は、直接MyScaleのEmbedText関数を利用する方法で、Amazon Bedrockを呼び出すより迅速な方法です。
# Amazon Bedrockへの接続
Amazon BedrockはAWSのいくつかのサービスの1つです。生成型AIアプリケーションを作成するための基礎モデルをいくつかホストしています。RAGはBedrockの特化領域の1つです。Bedrockを選択する理由のいくつかは次のとおりです。
- AWSホスティング: AWSのホスティングは優れています(実際には最高です)。そのため、スケーラビリティ、セキュリティ、稼働時間などの問題を心配する必要はありません。
- シンプルなAPI: この記事で後ほど見るように、APIは非常に使いやすいです。
- 従量制課金: 大きなホスティングプランを購入する必要はありません。従量制課金の機能により、必要に応じて使用をカスタマイズできます。
# アカウントの作成
まず、Bedrockを使用するためにIAMユーザ(この場合はbedrock_test)を作成する必要があります。
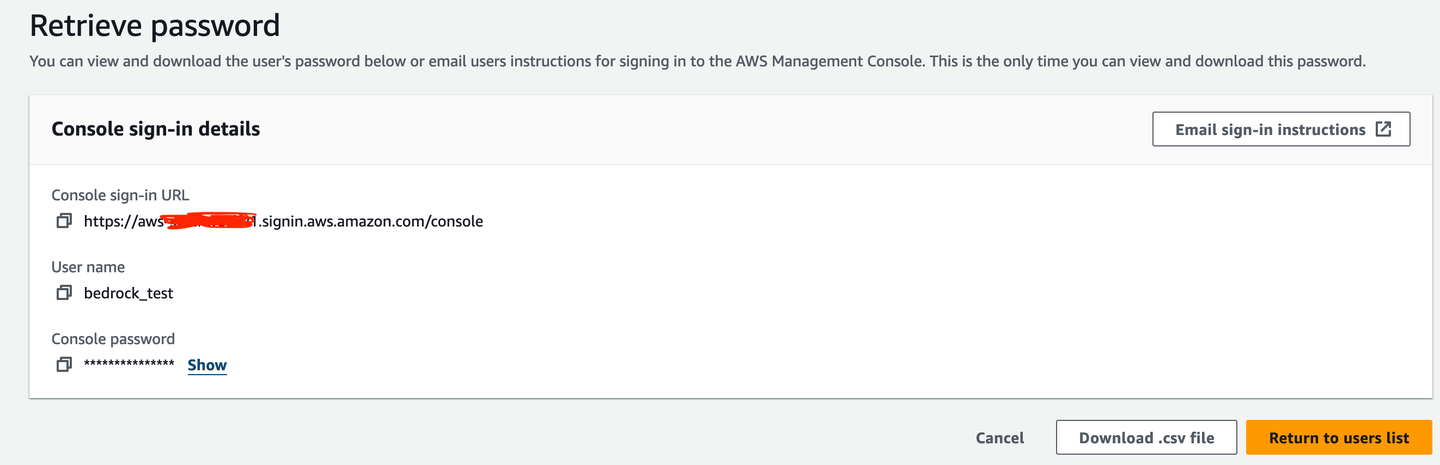
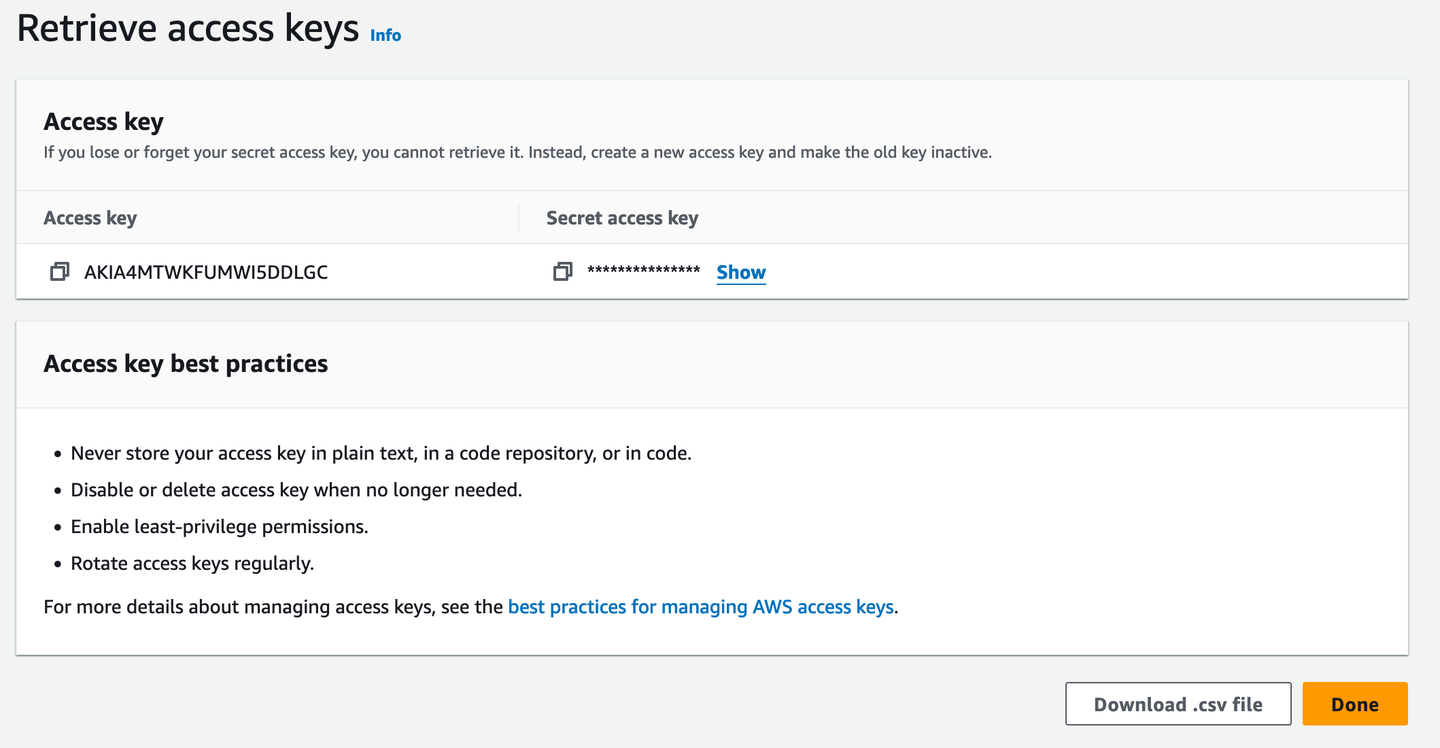
次に、ターミナルアクセス用のアクセスキーが必要です。

アクセスキーを忘れた場合に備えて、.csvファイルとしてダウンロードすると便利です。もちろん、パスワードマネージャーがあれば、必要なときにそこからコピーできるため、それがより良いオプションです。
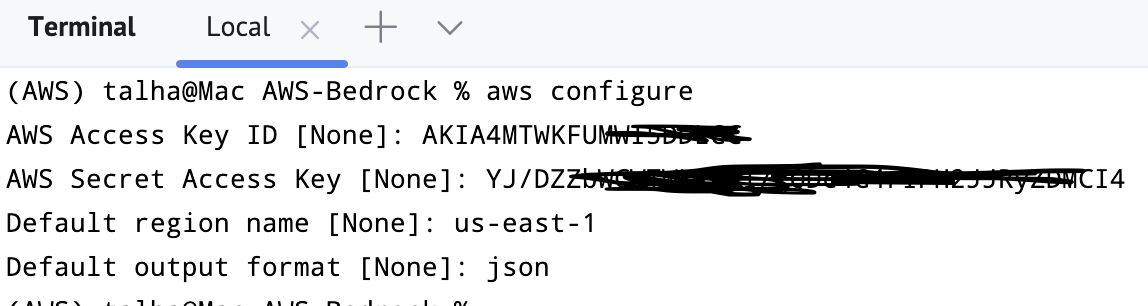
ターミナルに移動してaws configureと入力すると、認証情報、デフォルトの出力形式、リージョンを入力するように求められます。
# Python API
Bedrockをインポートしてサービスと接続することができます。通常、us-east-1リージョンに接続することをお勧めします。
import boto3
bedrockInterface = boto3.client(service_name="bedrock-runtime", region_name='us-east-1')
正常に実行されているため、Bedrockのクライアント/インターフェースがインストールおよび設定されました。これまでの準備が整いました。
- MyScaleのセットアップと接続
- Bedrockのセットアップと接続
# モデルの選択
埋め込みモデルを実装する前に、適切なモデルの選択が必要です。通常のデータリクエストとは異なり、時間がかかり、通常はすぐに許可されるデータリクエストとは異なり、モデルへのアクセスにはサイドバーの下部に移動し、該当するオプションを見つける必要があります。
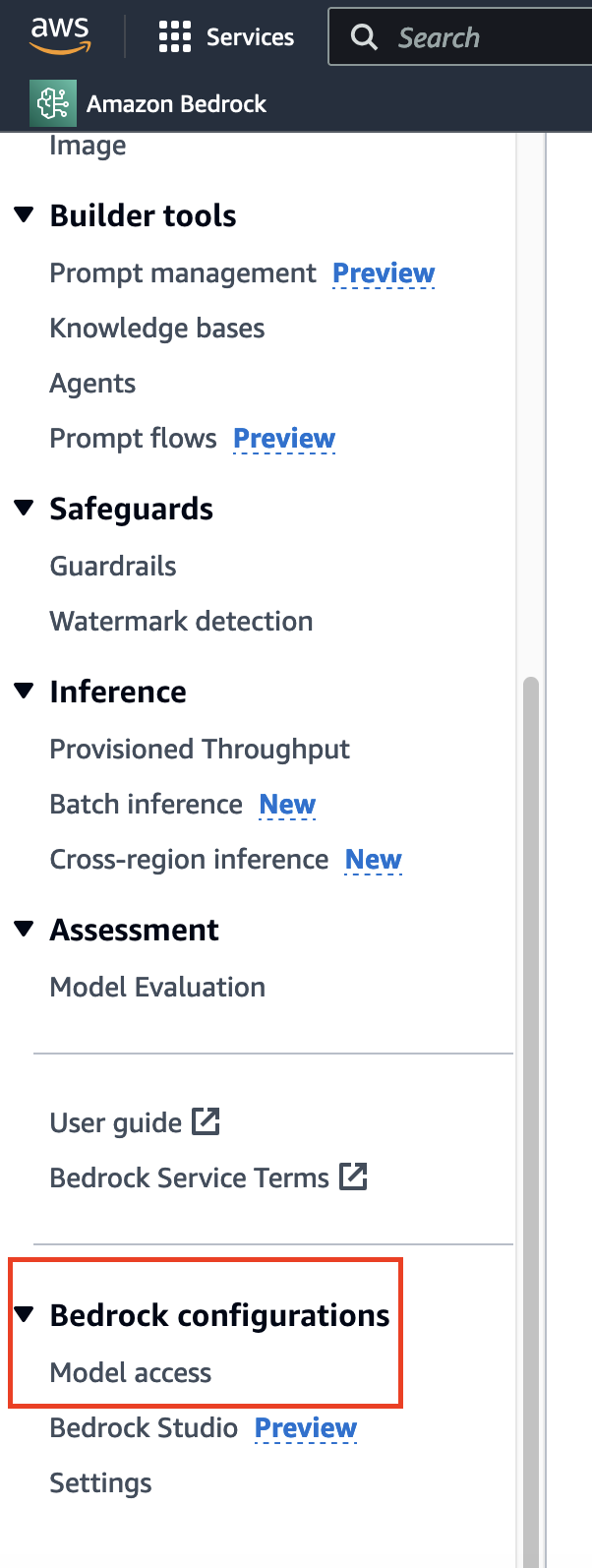
ここでは、すでにアクセス権限を取得しているため、ほとんどのモデルに対して「Access Granted」と表示されます。初めて使用する場合は、「Modify model access」をクリックして、該当するモデルへのアクセスを有効にすることができます。

注意:
一部のモデルの利用可能性は、選択したリージョン (opens new window)に依存します。
# Titan Embeddings
このチュートリアルでは、Titan Embeddingsモデル (opens new window)を使用します。まず、先ほど作成したクライアント/インターフェースにinvoke_model()メソッドを適用してモデルを使用します。JSONをモードオペランディとして指定したため、入力と出力の両方がこの形式であることを確認する必要があります。
import json
query = "Why number 42 is so significant in the literature?"
query_json = json.dumps({
"inputText": query,
})
次に、invoke_model()を呼び出します。出力は辞書形式です。
output = bedrockInterface.invoke_model(modelId="amazon.titan-embed-text-v1", body=query_json)
#Output
{'ResponseMetadata': {'RequestId': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'HTTPStatusCode': 200,
'HTTPHeaders': {'date': 'Wed, 18 Sep 2024 03:05:53 GMT',
'content-type': 'application/json',
'content-length': '17180',
'connection': 'keep-alive',
'x-amzn-requestid': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'x-amzn-bedrock-invocation-latency': '68',
'x-amzn-bedrock-input-token-count': '12'},
'RetryAttempts': 0},
'contentType': 'application/json',
'body': <botocore.response.StreamingBody at 0x151b1c880>}
bodyをデコードするために、再びJSONローダーを使用します。
response_body = json.loads(output.get('body').read())
#Output
{'embedding': [-0.35351562,
-0.3203125,
-0.083496094,
0.04711914,
0.0034332275,
0.24902344,
-0.13183594,
-4.798174e-06,
-0.28320312,
.
.
.
0.7890625,
...],
'inputTextTokenCount': 12}
これは良いですが、LangChainにはもっとシンプルなBedrockEmbeddingsクラスがあります。すでに上記で宣言したbedrockInterfaceを使用します。
from langchain_aws import BedrockEmbeddings
embeddingOutput = BedrockEmbeddings(client=bedrockInterface)
BedrockEmbeddingsにはいくつかのメソッドが含まれています。その1つがembed_query()で、テキスト文字列を受け取り、埋め込みを返します。Titanモデルを使用しているため、長さが1536の埋め込みベクトルが返されるはずです。
x = embeddingGenerator.embed_query("How is it going?")
len(x)
# 1536
# MyScaleに埋め込みを保存する
これで、対応するモデルから埋め込みを取得することができるため、ベクトルデータベースを利用する準備が整いました。まず、テキストとそれに対応する埋め込みを格納するためのテーブルを作成し、推論にさらに使用します。
client.command("""
CREATE TABLE IF NOT EXISTS BookEmbeddings (
id UInt64,
sentences String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id;
""")
# MyScale埋め込み関数
MyScaleは、MLモデルへのアクセスを含むさまざまな目的のために組み込み関数を提供しています。その1つがEmbedText()で、次のようないくつかの理由から非常に価値があります。
- テキスト入力の埋め込みを計算するための直接インターフェース。
- Bedrock、Hugging Face、Open AIなど、さまざまなAPIを呼び出す能力。
EmbedText() (opens new window)は、いくつかの引数を受け取ります。特にBedrockについて話すと、必要なのは次のとおりです。
- Input text: 埋め込みを取得したいテキスト。
- Provider: この場合は「Bedrock」になります。
- API URL: 一部のAPIではURLを使用する場合がありますが、この場合は必要ありませんので、空の文字列のままにしておきます。
api_key: 先ほど話した(AWSの)シークレットアクセスキー。access_key_id: 対応するキーID。model: モデルID(Bedrockのモデルの1つ)。region_name: AWSリージョン名。
例えば、次のようにこの関数を使用します。
SELECT EmbedText('Call me Ishmael. Some years ago—never mind how long precisely—having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world.', 'Bedrock', '', 'xxxxxxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxxx"}')
スカラー関数であるため、直接的な出力が得られます。

この関数を呼び出すたびに、入力テキスト以外のすべての引数は同じです。したがって、次のようにカスタマイズできます。
CREATE FUNCTION EmbedTest AS (x) -> EmbedText(x, 'Bedrock', '', 'xxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxx"}')
SELECT EmbedTest('Call me Ishmael. Some years ago—never mind how long precisely—having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world.')
このカスタマイズされた関数は、どこからでも簡単に呼び出すことができます。この直感的な埋め込み関数(他のAPIとも組み合わせて拡張できます)を見た後、フロントエンドに戻って、ブログの残りの部分で使用するテキストをスクラップしましょう。
# Book Embeddingsの生成
では、本を選んでその埋め込みを生成しましょう。例えば、Gutenberg (opens new window)を使用してTolstoyの名作 (opens new window)を取得します。
import requests
url = "<https://www.gutenberg.org/files/1399/1399-0.txt>"
response = requests.get(url)
if response.status_code == 200:
bookText = response.content.decode('utf-8-sig')
start = bookText.find("CHAPTER I")
end = bookText.find("End of the Project Gutenberg EBook")
bookText = bookText[start:end]
chapters = re.split(r'(Chapter \\d+)', book_text)
splitChapters = ["".join(x) for x in zip(chapters[1::2], chapters[2::2])]
これで、Anna Kareninaが章ごとの形式で取得できました。これらをすべてTitanモデルに渡して埋め込みを取得できます。
embeddingsMatrix = [embeddingGenerator.embed_query(chapter) for chapter in splitChapters]
さらに、データフレームに変換してテーブルに挿入します。
import pandas as pd
df = pd.DataFrame({
'Text': splitChapters,
'Embedding': embeddingsMatrix
})
df_records = df.to_records(index=True)
client.insert("BookEmbeddings", df_records.tolist(), column_names=["id", "sentences", "embeddings"])
データが正常に挿入されたことを、SQLワークスペース (opens new window)(MyScaleコンソール上)で確認できます。
# インデックスの作成
インデックスを作成すると、埋め込み間の距離を素早く計算するのに役立ちます。
client.command("""
ALTER TABLE BookEmbeddings
ADD VECTOR INDEX dist_idx embeddings
TYPE MSTG
""")
このインデックスが適用されるまでには、数分かかる場合があります(データによって異なります)。
# MyScaleを使用してAnna Kareninaの小説を検索する
小説全体がデータベースに格納され、インデックスが作成されたら、ベクトルデータベースに戻っていくつかのクエリを実行しましょう。例えば、最も関連性の高い章(つまり、ドキュメントの検索)を見つけましょう。
query = "What happened to Levin's brother?"
queryEmbeddings = embeddingGenerator.embed_query(query)
results = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {queryEmbeddings}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
以下の結果では、これらの3つの章がクエリに関連するものとして最も関連性が高いことがわかります。

query = "When Dolly went to meet Anna at her home?"
query_embeddings = embeddingGenerator.embed_query(query)
results = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {query_embeddings}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
再び、出力は素晴らしいです。ベクトル検索は非常にうまく機能していることがわかります。

異なる測定方法(コサイン類似度)を試してみましたが、距離は異なりますが、上記と同じ回答が得られました。試してみたい場合は、既存のインデックスを削除し、コサイン類似度インデックスを追加してください。
client.command("""
ALTER TABLE BookEmbeddings
ADD VECTOR INDEX cosine_idx embeddings
TYPE MSTG
('metric_type=Cosine')
""")

# 結論
Amazon BedrockとMyScaleを使用したベクトル検索は、ほとんどのE-リーダーで見られる従来のキーワードベースの検索に比べて明らかな改善を提供します。セマンティック検索を使用することで、ユーザーは正確な用語を覚えていなくても関連するコンテンツを見つけることができ、読書体験がスムーズになります。この例では、単一の小説に焦点を当てていますが、このアプローチは他の書籍から法的文書や公式文書まで、さまざまなテキストに適用することができます。
このプロセスは非常にアクセス可能です。ここで示したすべての操作は、MyScaleの無料ティアを使用して行われました。テストや結果の再現に十分なリソースが提供されています。BedrockのAIモデルの強みとMyScaleの効率的なストレージと検索機能を組み合わせることで、さまざまなアプリケーションでテキスト検索をより効果的に処理することができます。



