
大規模言語モデル(LLM)を使用したスケーラブルで最適化されたAIアプリケーションの開発は、まだ成長段階にあります。LLMに基づいたアプリケーションの構築は、プロンプトの作成などの手作業が必要なため、複雑で時間のかかる作業です。プロンプトの作成は、モデルから最良の結果を引き出すために非常に重要な部分です。しかし、最適化されたプロンプトを作成するには、開発者が試行錯誤の方法に頼る必要があり、望ましい結果が得られるまでかなりの時間がかかります。
手動でプロンプトを作成する従来の方法は、時間がかかり、エラーが発生しやすいです。開発者は、望ましい出力を得るためにプロンプトを微調整するために多くの手作業を行い、次のような問題に直面します。
- 脆弱性: プロンプトは、わずかな変更で壊れたり一貫性のないパフォーマンスを発揮したりすることがあります。
- 手動の調整: プロンプトを洗練させるためには、広範な手作業が必要です。
- 一貫性のない処理: 類似のタスクに対して異なるプロンプトを使用すると、一貫性のない結果が生じます。
# DSPyとは?
DSPy(Declarative Self-improving Language Programs)は、Omer Khattab氏と彼のチームがStanford NLで開発したフレームワークです。DSPyは、プログラミングを手動のプロンプト作成よりも優先することで、プロンプト作成の一貫性と信頼性の問題を解決することを目指しています。DSPyは、低レベルの詳細にフォーカスせずに高レベルのワークフローを作成するためのより宣言的で体系的なアプローチを提供し、データパイプラインの構築を自動化することで効率を向上させます。
DSPyロゴ
達成すべき目標を定義するだけでなく、それを達成する方法を定義します。そのため、DSPyは次のような進歩を遂げました。
- プロンプトに対する抽象化: DSPyはシグネチャの概念を導入しました。シグネチャは、テンプレートのような構造で手動のプロンプト表現を置き換えることを目指しています。この構造では、任意のタスクに対して入力と出力を定義するだけで済みます。これにより、パイプラインがモデルやデータの変更に柔軟に対応できるようになり、耐障害性が向上します。
- モジュラーなビルディングブロック: DSPyは、Chain of ThoughtやReActなどの一般的なプロンプト技術をカプセル化したモジュールを提供します。これにより、これらの技術のために複雑なプロンプトを手動で構築する必要がなくなります。
- 自動最適化: DSPyは組み込みの最適化機能("テレプロンプター"とも呼ばれる)をサポートしており、特定のタスクとモデルに最適なプロンプトを自動的に選択します。この機能により、手動のプロンプト調整が不要になり、プロセスがよりシンプルで効率的になります。
- コンパイラによる適応: DSPyコンパイラは、データと検証ロジックに基づいてプロンプトやモデルを調整し、パイプラインが変更されても効果的なままであることを保証するため、パイプライン全体を最適化します。
# DSPyプログラムの構築ブロック
DSPyプログラムの基礎を形成する重要なコンポーネントを探って、それらがどのように相互作用して強力で効率的なNLPパイプラインを作成するかを理解しましょう。
# シグネチャ
シグネチャは、LLMが行うべきことを定義するための設計図として機能します。正確なプロンプトを書く代わりに、タスクを入力と出力の観点で記述します。
例えば、テキストの要約のためのシグネチャは次のようになります: text -> summary。これにより、DSPyに対してテキストを入力し、簡潔な要約を出力するように指示します。より複雑なタスクでは、質問応答のシグネチャのように複数の入力が関与する場合もあります: context, question -> answer。シグネチャは柔軟で、入力と出力フィールドの説明などの追加情報でカスタマイズすることができます。
class GenerateAnswer(dspy.Signature):
"""短い事実ベースの回答で質問に答えます。"""
context = dspy.InputField(desc="関連する事実を含む場合があります")
question = dspy.InputField()
answer = dspy.OutputField(desc="通常は1〜5語程度")
# モジュール: LLMの動作のビルディングブロック
モジュールは、特定のLLMの動作や技術をカプセル化した事前に構築されたコンポーネントです。これらは、LLMアプリケーションを組み立てるために使用するビルディングブロックです。例えば、ChainOfThoughtモジュールは、LLMがステップバイステップで考えることを促すことで、複雑な推論タスクでのパフォーマンスを向上させます。ReActモジュールは、計算機やデータベースなどの外部ツールとの連携を可能にします。複数のモジュールを連鎖させることで、洗練されたパイプラインを作成することができます。
# 方法1: ChainOfThoughtモジュールにクラスを渡す
chain_of_thought = ChainOfThought(TranslateText)
各モジュールはシグネチャを受け取り、ChainOfThoughtのようなdefinedメソッドを使用して、定義された入力と出力に基づいて必要なプロンプトを構築します。このメソッドにより、プロンプトが体系的に生成され、一貫性が保たれ、手動のプロンプト作成の必要性が減ります。
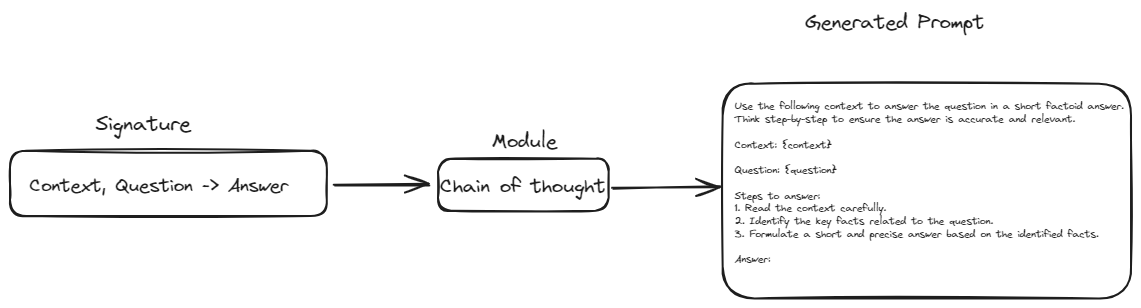
このように、モジュールはシグネチャを受け取り、特定の動作や技術を適用し、タスクの要件に合致するプロンプトを生成します。シグネチャとモジュールの統合により、手動の介入を最小限に抑えながら、複雑で柔軟なLLMアプリケーションを構築することができます。
# テレプロンプター(最適化ツール): プロンプトのアドバイザー
テレプロンプターは、LLMのコーチのような存在です。特定のタスクとモデルに対して最適なプロンプトを見つけるために、高度な技術を使用します。これは、異なるバリエーションのプロンプトを自動的に試し、定義したメトリックに基づいてパフォーマンスを評価することで行います。例えば、テレプロンプターは、質問応答タスクの場合には正確さのメトリック、テキスト要約の場合にはROUGEスコアなどのメトリックを使用するかもしれません。
from dspy.teleprompt import BootstrapFewShot
# シンプルなテレプロンプターの例
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# DSPyコンパイラ: マスターオーケストレーター
DSPyコンパイラは、この操作の中核です。コンパイラは、シグネチャ、モジュール、トレーニングデータ、検証ロジックなど、プログラム全体を受け取り、最適なパフォーマンスを実現するために最適化します。コンパイラは、アプリケーションの変更を自動的に処理する能力により、DSPyを非常に堅牢で適応性のあるものにしています。
from dspy.teleprompt import BootstrapFewShot
# 質問と回答のペアを含む小さなトレーニングセット
trainset = [dspy.Example(question="アルバート・アインシュタインは何で最もよく知られていますか?",
answer="相対性理論").with_inputs('question'),
dspy.Example(question="アルバート・アインシュタインの相対性理論はどの有名な方程式を生み出しましたか?",
answer="E = mc²").with_inputs('question'),
dspy.Example(question="アルバート・アインシュタインは1921年にどのような名誉ある賞を受賞しましたか?",
answer="ノーベル物理学賞").with_inputs('question'),
dspy.Example(question="アルバート・アインシュタインは何年にアメリカ合衆国に移住しましたか?",
answer="1933").with_inputs('question'),
dspy.Example(question="アインシュタインは1905年にどのような重要な科学的業績を発表しましたか?この年は彼のアヌス・ミラビリス(奇跡の年)とも呼ばれます。",
answer="光電効果、ブラウン運動、特殊相対性理論、質量-エネルギーの等価性などを含む画期的な4つの論文").with_inputs('question'),]
# RAGプログラムをコンパイルするための基本的なテレプロンプターを設定します。
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
DSPyコンパイラは、基本的なプロンプト、トレーニング例、およびDSPyプログラムを受け取り、最適化されたパフォーマンスを持つプロンプトを生成します。このプロセスでは、プログラムのさまざまなバージョンを入力上でシミュレートし、各モジュールの例トレースをブートストラップして、タスクに最適化されたパイプラインを最適化します。
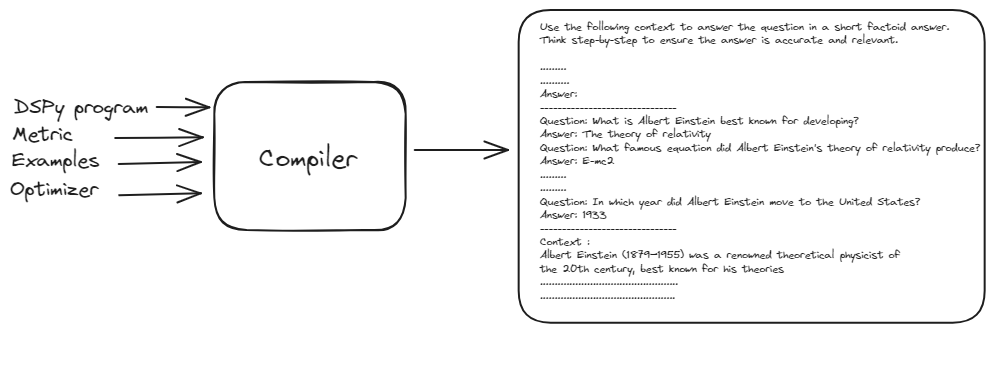
この自動最適化プロセスにより、手動のプロンプト調整が不要になり、DSPyは変更に適応できる堅牢さと適応性を備え、非常に効果的で効率的なNLPパイプラインを提供します。
# DSPyとMyScaleDBを使用したRAGモデルの実践例
DSPyの基礎を理解したところで、実践的なアプリケーションを作成してみましょう。質問応答のRAGパイプラインを構築し、ベクトルデータベースとしてMyScaleDBを使用します。
# 1. Wikipediaからドキュメントを読み込む
まず、Wikipediaから「アルバート・アインシュタイン」に関連するドキュメントを読み込みます。これは、langchain_community.document_loadersモジュールのWikipediaLoaderを使用して行います。
from langchain_community.document_loaders.wikipedia import WikipediaLoader
loader = WikipediaLoader(query="アルバート・アインシュタイン")
# ドキュメントを読み込む
docs = loader.load()
# 2. ドキュメントをプレーンテキストに変換する
次に、読み込んだドキュメントをHtml2TextTransformerを使用してプレーンテキストに変換します。
from langchain_community.document_transformers import Html2TextTransformer
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)
# クリーンなテキストを取得する
cleaned_text = docs_transformed[0].page_content
text = ' '.join([page.page_content.replace('\\t', ' ') for page in docs_transformed])
# 3. テキストをチャンクに分割する
テキストをCharacterTextSplitterを使用して管理可能なチャンクに分割します。これにより、大きなドキュメントの処理が容易になり、モデルが効率的に処理できるようになります。
import os
from langchain_text_splitters import CharacterTextSplitter
# APIキーを環境変数として設定する
os.environ["OPENAI_API_KEY"] = "your_openai_api_key"
# テキストをチャンクに分割する
text = ' '.join([page.page_content.replace('\\\\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\\n",
chunk_size=300,
chunk_overlap=50,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
# 8. 埋め込みモデルの定義
transformersライブラリを使用して埋め込みモデルを定義します。テキストをベクトル埋め込みに変換するためにall-MiniLM-L6-v2モデルを使用します。
import torch
from transformers import AutoTokenizer, AutoModel
# 埋め込みのためのトークナイザーとモデルを初期化する
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
def get_embeddings(texts: list) -> list:
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
# 7. 埋め込みの取得
上記の埋め込みモデルを使用して、テキストのチャンクに対して埋め込みを生成します。
import pandas as pd
all_embeddings = []
for i in range(0, len(splits), 25):
batch = splits[i:i+25]
embeddings_batch = get_embeddings(batch)
all_embeddings.extend(embeddings_batch)
# テキストのチャンクとその埋め込みを持つDataFrameを作成する
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})
# 8. ベクトルデータベースへの接続
このサンプルアプリケーションの開発には、MyScaleDB (opens new window)をベクトルデータベースとして使用します。MyScaleDBで無料アカウントを作成するには、MyScaleのサインアップページ (opens new window)を訪れてください。その後、クイックスタートチュートリアル (opens new window)に従って新しいクラスターを開始し、接続の詳細を取得できます。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-cloud-host',
port=443,
username='your-user-name',
password='your-password'
)
接続の詳細をPythonノートブックにコピーして貼り付け、コードブロックを実行します。これにより、クラウド上のMyScaleDBクラスターに接続されます。
# 9. テーブルの作成とデータのプッシュ
MyScaleDBクラスター上にテーブルを作成するプロセスを分解してみましょう。まず、RAGという名前のテーブルを作成します。このテーブルには、id、page_content、embeddingsの3つの列があります。id列には各行の一意のidが格納され、page_content列にはテキストの内容が保存され、embeddings列には対応するページコンテンツの埋め込みが保存されます。
# テーブルを作成する
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
# データをテーブルに挿入する
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
テーブルを作成した後、データを新しく作成したRAGテーブルにバッチ形式で保存します。
# 10. MyScaleDBとのDSPyの設定
DSPyとMyScaleDBを接続し、DSPyがデフォルトで言語モデルと検索モデルを使用するように設定します。
import dspy
import openai
from dspy.retrieve.MyScaleRM import MyScaleRM
# OpenAI APIキーを設定する
openai.api_key = "your_openai_api_key"
# LLMを設定する
lm = dspy.OpenAI(model="gpt-3.5-turbo")
# 検索モデルを設定する
rm = MyScaleRM(client=client,
table="RAG",
local_embed_model="sentence-transformers/all-MiniLM-L6-v2",
vector_column="embeddings",
metadata_columns=["page_content"],
k=6)
# DSPyをデフォルトで以下の言語モデルと検索モデルを使用するように設定する
dspy.settings.configure(lm=lm, rm=rm)
注意: ここで使用する埋め込みモデルは、上記で定義したものと同じものである必要があります。
# 11. シグネチャの定義
質問応答のタスクに対して入力と出力を指定するために、GenerateAnswerシグネチャを定義します。
class GenerateAnswer(dspy.Signature):
"""短い事実ベースの回答で質問に答えます。"""
context = dspy.InputField(desc="関連する事実を含む場合があります")
question = dspy.InputField()
answer = dspy.OutputField(desc="通常は1〜5語程度")
# 12. RAGモジュールの定義
RAGモジュールは、検索と生成のステップを統合します。統合されたデータベースから関連するパッセージを検索し、コンテキストに基づいて回答を生成します。
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
forwardメソッドは質問を入力として受け取り、リトリーバーを使用して統合されたデータベースから関連するチャンクを見つけます。これらの取得されたチャンクは、ChainOfThoughtモジュールに渡され、基礎となるプロンプトが生成されます。
# 13. テレプロンプターの設定
次に、BootstrapFewShotテレプロンプター/最適化ツールを使用して、基本的なプロンプトをコンパイルして最適化します。
from dspy.teleprompt import BootstrapFewShot
# 質問と回答のペアを含む小さなトレーニングセット
trainset = [dspy.Example(question="アルバート・アインシュタインは何で最もよく知られていますか?",
answer="相対性理論").with_inputs('question'),
dspy.Example(question="アルバート・アインシュタインの相対性理論はどの有名な方程式を生み出しましたか?",
answer="E = mc²").with_inputs('question'),
dspy.Example(question="アルバート・アインシュタインは1921年にどのような名誉ある賞を受賞しましたか?",
answer="ノーベル物理学賞").with_inputs('question'),
dspy.Example(question="アルバート・アインシュタインは何年にアメリカ合衆国に移住しましたか?",
answer="1933").with_inputs('question'),
dspy.Example(question="アインシュタインは1905年にどのような重要な科学的業績を発表しましたか?この年は彼のアヌス・ミラビリス(奇跡の年)とも呼ばれます。",
answer="光電効果、ブラウン運動、特殊相対性理論、質量-エネルギーの等価性などを含む画期的な4つの論文").with_inputs('question'),]
# 基本的なテレプロンプターを設定し、RAGプログラムをコンパイルする
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
このコードは、上記で定義したRAGクラスを使用し、最適化ツールと一緒に例を使用してLLMに最適なプロンプトを生成します。
# 14. パイプラインの実行
最後に、コンパイルされたRAGパイプラインを実行し、MyScaleDBに保存されたコンテキストに基づいて質問に回答します。
# 関連するドキュメントを取得する
retrieve_relevant_docs = dspy.Retrieve(k=5)
context = retrieve_relevant_docs("アルバート・アインシュタインとは誰ですか?").passages
# クエリを実行する
pred = compiled_rag(question="アルバート・アインシュタインは誰でしたか?")
これにより、次のような出力が生成されます。
['アルバート・アインシュタイン(1879年-1955年)は、20世紀の著名な理論物理学者であり、特殊相対性理論の理論などで最もよく知られています ........
.......
独創性により、"アインシュタイン"という言葉は"天才"と同義語となりました。']

# 結論
DSPyフレームワークは、ハードコーディングされたプロンプトをプログラム可能なインターフェースに置き換えることで、LLMとの対話を革新し、開発プロセスを大幅に効率化しています。手動のプロンプト作成からより構造化されたプログラミング指向の方法への移行により、AIアプリケーションの効率性、一貫性、スケーラビリティが向上しました。プロンプトエンジニアリングの複雑さを抽象化することで、DSPyは開発者が高レベルのロジックとワークフローを定義することに集中できるようにし、洗練されたAI駆動型ソリューションの展開を加速します。
AIアプリケーションのパフォーマンスを向上させるために特別に開発されたベクトルデータベースであるMyScaleDBは、このようなシステムの性能を向上させる重要な役割を果たしています。MyScaleDBの高度な独自のアルゴリズムにより、AIアプリケーションの速度と精度が向上します。さらに、MyScaleDBは、新規ユーザーに対して最大500万ベクトルまでの無料ストレージを提供するなど、初期投資なしで堅牢なデータベースソリューションを利用できるため、スタートアップや研究者にとって魅力的な選択肢となっています。



