
过去,我一直在不同的数据仓库和数据分析项目中使用ClickHouse (opens new window)。但是在生成式AI和向量嵌入技术的兴起之后,我正在寻找一个与尖端技术配合使用的数据库。有很多向量数据库,如Pinecone (opens new window)、Weaviate (opens new window)和Milvus (opens new window),但所有这些向量数据库都只专门用于向量,并且需要很长时间才能彻底理解基础知识并熟悉语法。
MyScale (opens new window)并不像我上面提到的那些向量数据库那样受欢迎,并且列在向量数据库功能矩阵 (opens new window)的末尾。我进一步探索了它,了解到它具备我所需的所有功能,并且有非常简单易懂的文档。它是基于ClickHouse构建的,可以存储用于生成式AI应用的向量和用于普通SQL应用的表格数据。我之前使用ClickHouse和SQL的经验帮助我很快地掌握了基础知识,我已经使用它4个月了。
# MyScale与ClickHouse的比较
我试图以一种非常简单的方式比较这两个数据库,以便您可以清楚地了解它们之间的区别。
| 特性 | ClickHouse | MyScale |
|---|---|---|
| 基础技术 | 开源的面向列的DBMS | 基于ClickHouse构建的云端SQL向量数据库 |
| 主要用途 | 实时SQL查询处理的OLAP | AI应用,将向量相似性搜索与SQL结合起来 |
| 数据存储方法 | 用于高效查询的列存储 | 处理向量和结构化数据的列存储 |
| 数据类型处理 | 结构化数据 | 结构化数据和向量 |
| 查询语言 | SQL | 完全支持SQL,包括自然语言查询 |
| 主要特点 | 实时分析报告,特定查询的高效性 | AI集成,准确性,性能和成本效益 |
| 使用场景 | 传统的OLAP场景 | 高级AI和机器学习应用 |
希望您已经了解了这些差异以及我为什么选择MyScale。让我们一起探索他们最近添加的一个有趣且有用的功能。
# 探索MyScale游乐场
当我从ClickHouse转到MyScale时,我认为MyScale需要改进的几个方面之一是一个可以编写查询并查看结果而无需注册的游乐场。MyScale逐渐在基础设施方面做出了许多改进,他们已经加入了我大部分期望的功能,但是游乐场仍然缺失。
最近,他们终于在他们的平台上添加了一个游乐场,我非常喜欢它。我之前尝试过其他提供商的游乐场,但我认为这是唯一一个允许执行SQL和向量联合查询 (opens new window)的游乐场,这是一个罕见的功能。
现在让我们一起探索MyScale游乐场 (opens new window)。
# 用户友好的界面
在游乐场中,您会看到已经为不同场景构建了几个示例应用程序,并为每个应用程序上传了不同的数据集。
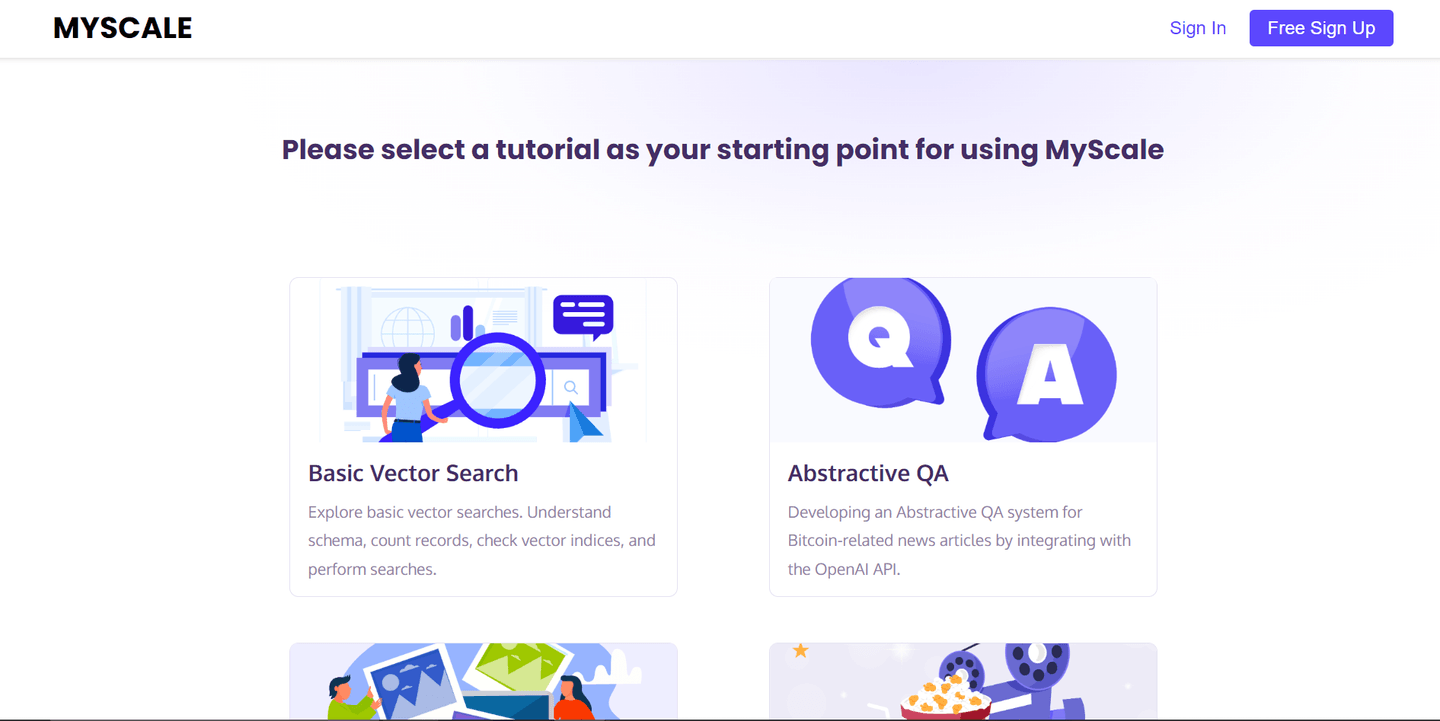
在所有这些示例应用程序中,我最喜欢的是Working with Texts (opens new window)应用程序。它有预加载的ArXiv数据集,其中包含超过220万篇带有元数据信息的论文。
打开应用程序,您会看到如下界面:
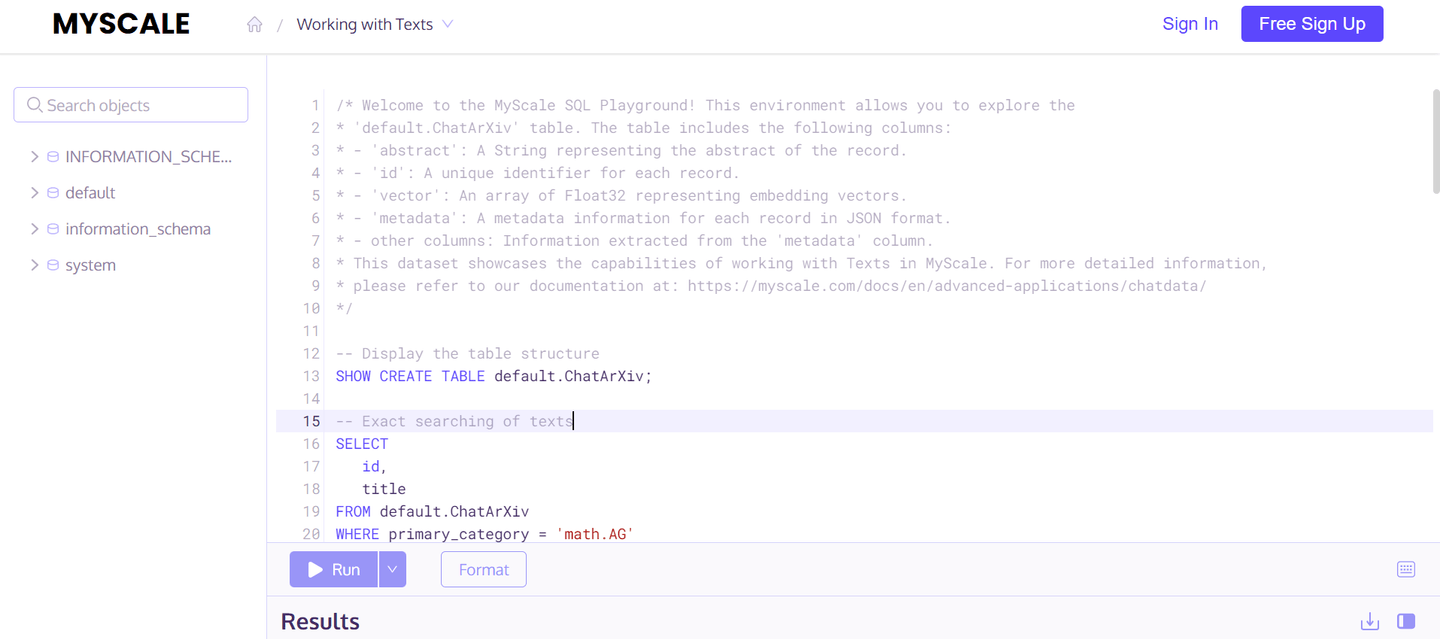
当您打开任何应用程序时,您可能会注意到的第一件事是其描述和用于此应用程序的表格的详细信息。通过阅读描述,您可以轻松了解应用程序的用途以及如何操作数据集。所有可用的数据库都显示在左侧,供您探索预先存在的表格。
然后,添加了不同的示例命令,您可以使用这些命令来探索应用程序并进行实验。让我们看一些示例查询:
# 简单查询
执行第一个查询后,您将看到用于创建此应用程序表格的命令。
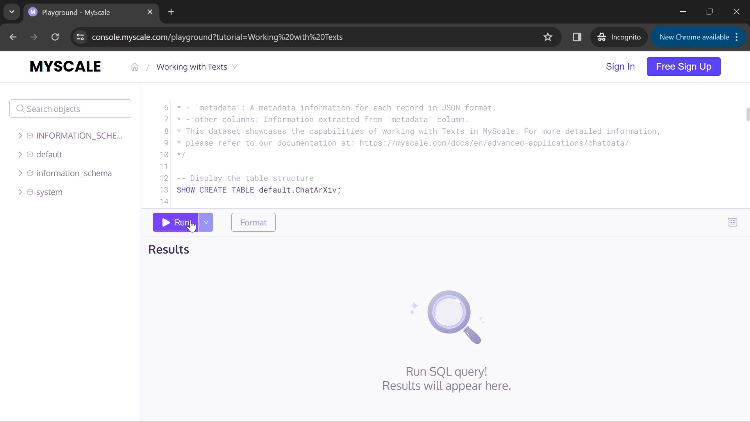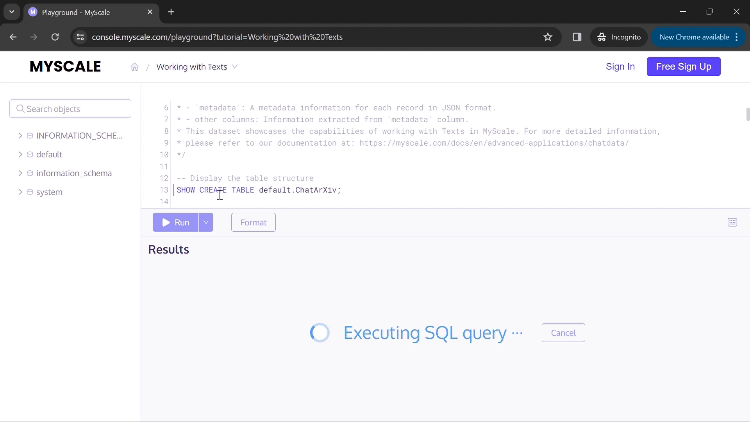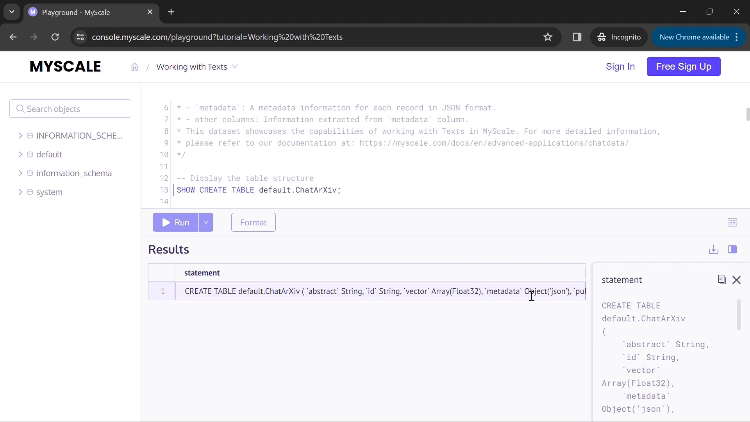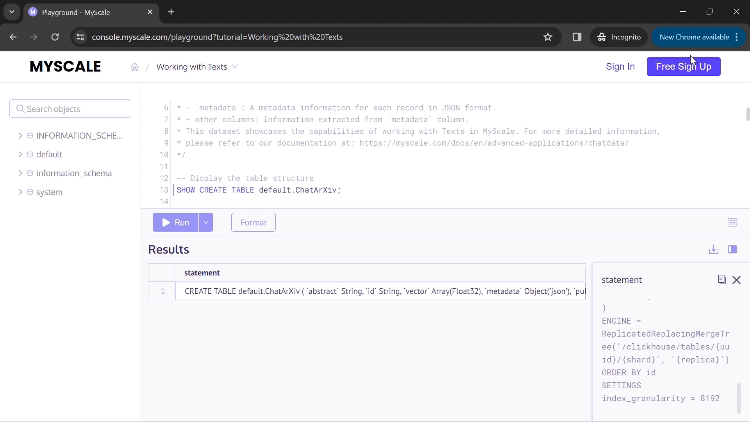
您可以点击“运行”来执行您的命令并显示结果。如果结果中的值过大而无法完全显示在列中,您可以点击该列,将打开一个新的对话框,显示完整的结果(如上面的GIF所示)。
它还添加了一些带有预构建函数 (opens new window)的示例查询。然而,我将跳过这些查询,直接进行最后一个查询,执行向量SQL查询。

# 向量SQL搜索查询
正如我之前讨论的,MyScale是一个非常动态的数据库,您可以在其中执行带有高级向量搜索查询的SQL。这种组合使得MyScale能够以更有效和更具成本效益的方式处理复杂的数据集。提供了一些示例查询,仅用于更好地理解数据集,但是MyScale的潜在应用超出了这些示例。例如,您可以利用熟悉的SQL语法对数据集进行深入分析,从而获得有价值的见解。以下是一个查询示例,它提供了量子计算研究的演变和当前趋势的见解:
WITH recent_quantum_papers AS (
SELECT id, vector, title, abstract, pubdate
FROM default.ChatArXiv
WHERE abstract LIKE '%quantum computing%' AND pubdate > '2019-01-01'
),
reference_vector AS (
SELECT vector
FROM recent_quantum_papers
ORDER BY pubdate DESC
LIMIT 1
)
SELECT
id,
title,
abstract,
EXTRACT(YEAR FROM pubdate) AS year,
distance(vector, (SELECT vector FROM reference_vector)) AS similarity
FROM recent_quantum_papers
ORDER BY year DESC, similarity ASC
LIMIT 10;
此查询筛选了2019年之后发表的关于量子计算的学术论文,使用最新论文的向量来衡量它们之间的上下文相似性。这种方法不仅按时间顺序排序论文,还按照它们与最新研究趋势的相关性排序。下图显示了包含文档元数据和相似性距离的搜索结果:
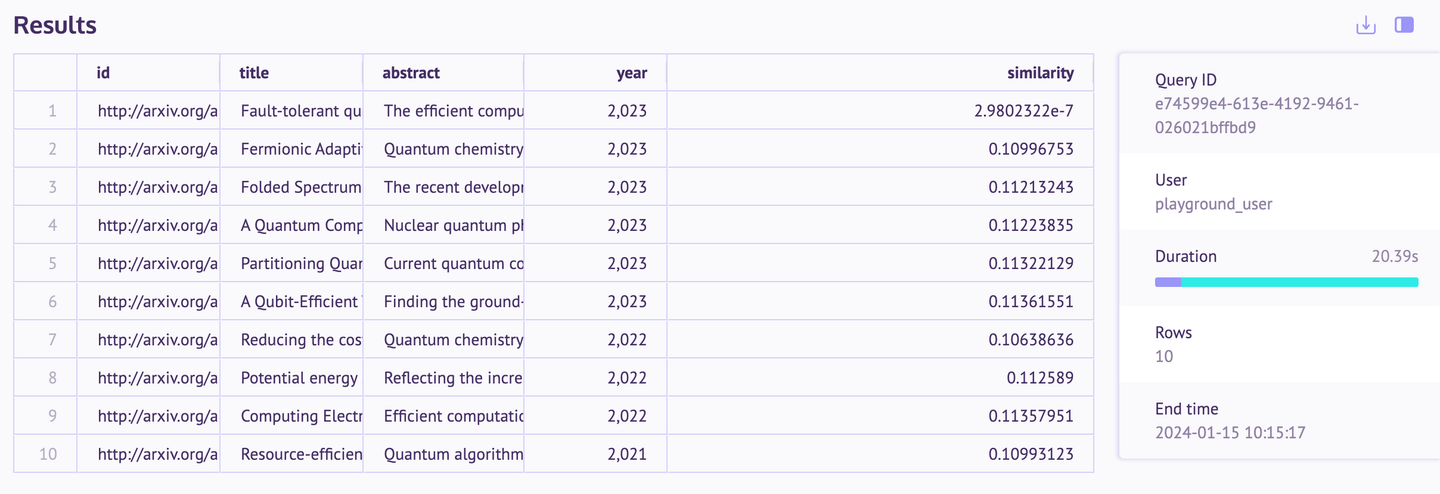
您还可以使用MyScale编写更复杂的查询,因为它具有完全的SQL和向量支持。其他示例应用程序也非常令人印象深刻。如果有兴趣,可以进一步探索它们。
注意:MyScale游乐场不支持直接上传数据。要使用您的数据,请先登录或注册MyScale,然后按照快速入门指南 (opens new window)中提供的逐步说明进行操作。
# 结论
总之,我在MyScale游乐场有着很好的体验,它提供了一个用户友好的环境,可以无缝地集成SQL和向量查询。行业标准的示例应用程序的包含对于从传统数据库过渡和学习非常有价值。
MyScale建立在坚实的ClickHouse基础上,继承了所有功能,并满足现代AI应用的需求。它支持与OpenAI (opens new window)、LangChain (opens new window)和LlamaIndex (opens new window)的集成,进一步展示了其多功能性。
如果您对MyScale感兴趣,不妨探索一下MyScale游乐场,特别是考虑到游乐场的界面非常简单易上手。这就是我对MyScale游乐场的探索。欢迎在评论中分享您的想法或参与讨论。



