
急速に進化する LLM アプリケーションの分野では、堅牢なオブザーバビリティを実現することが、最適なパフォーマンスと信頼性を確保するために重要です。 しかし、LLM アプリケーションのトレースとランタイムイベントの保存は、その複雑さとスケールのために容易ではありません。これらの課題に対処するために、 MyScale Telemetry (opens new window)をリリースしました。このコールバックは、LangChain Callbacks (opens new window)と統合されています。
このコールバックは、LangChain ベースの LLM アプリケーションからトレースデータをシームレスにキャプチャし、MyScaleDB (opens new window)に保存します。 これにより、問題の診断、パフォーマンスの最適化、モデルの動作の理解が容易になります。MyScale Telemetry は、LangSmith (opens new window)と同様の機能を提供し、LangSmith のオープンソースの代替手段として機能します。また、MyScaleDB は ClickHouse 互換であるため、MyScale Telemetry は直接 ClickHouse と連携して使用することができます。
以下では、MyScale Telemetry の機能と使用方法について詳しく説明します。
# MyScale Telemetry の動作原理
LangChain と MyScale Telemetry を統合することは簡単です。 コールバックハンドラは、LangChain アプリケーションのランタイムイベントごとにネストされたトレースを自動的に作成します。 これらのランタイムイベントには次のものがあります。
on_chain_starton_chain_endon_llm_starton_llm_endon_chat_model_starton_retriever_starton_retriever_endon_tool_starton_tool_endon_tool_erroron_chain_erroron_retriever_erroron_llm_error
収集されたランタイムイベントデータは、OpenTelemetry のトレースデータ (opens new window)と同様にトレースデータに整理され、専用のトレースデータテーブルに MyScale データベースに保存されます。 テーブルの構造は次のようになります。
CREATE TABLE your_database_name.your_table_name
(
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`ParentSpanId` String CODEC(ZSTD(1)),
`StartTime` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`EndTime` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`Duration` Int64 CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanKind` LowCardinality(String) CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`StatusCode` LowCardinality(String) CODEC(ZSTD(1)),
`StatusMessage` String CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_duration Duration TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree()
PARTITION BY toDate(StartTime)
ORDER BY (SpanName, toUnixTimestamp(StartTime), TraceId);
ユーザーは、このトレースデータを分析して、効果的に LLM アプリケーションのデバッグと改善を行うことができます。 MyScale Telemetry は、豊富なオブザーバビリティの洞察を提供しながら、最小限のパフォーマンス影響を保証し、開発者がアプリケーションの動作とパフォーマンスに深い洞察を得ることができます。
# 使用例
MyScale Telemetry の完全な使用例を通じて、効果的に MyScale Telemetry を活用するための手順を説明します。
# MyScaleDB と Grafana のセットアップ
まず、Docker Compose を使用して MyScaleDB と Grafana のインスタンスをセットアップします。 docker-compose.yml ファイルはこちら (opens new window)で見つけることができます。以下のコマンドを実行してコンテナを起動します。
docker-compose up -d
# 必要なパッケージのインストール
次に、pip を使用して MyScale Telemetry パッケージと LangChain、LangChain OpenAI 統合、Ragas をインストールします。
pip install myscale-telemetry langchain_openai ragas
# シンプルなチェーンの構築
次に、シンプルな LangChain チェーンを構築し、トレースデータの収集のためにMyScaleCallbackHandlerと統合します。
import os
from myscale_telemetry.handler import MyScaleCallbackHandler
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import MyScale
from langchain_community.vectorstores.myscale import MyScaleSettings
from langchain_core.runnables import RunnableConfig
# OpenAI と MyScale Cloud/MyScaleDB の環境変数を設定する:
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
os.environ["MYSCALE_HOST"] = "YOUR_MYSCALE_HOST"
os.environ["MYSCALE_PORT"] = "YOUR_MYSCALE_HOST"
os.environ["MYSCALE_USERNAME"] = "YOUR_MYSCALE_USERNAME"
os.environ["MYSCALE_PASSWORD"] = "YOUR_MYSCALE_PASSWORD"
# MyScale と OpenAI の埋め込みを使用して、ベクトルストアとリトリーバを作成する:
texts = [
"Harrison worked at Kensho.",
"Alice is a software engineer.",
"Bob enjoys hiking on weekends.",
"Claire is studying data science.",
"David works at a tech startup.",
"Eva loves playing the piano.",
"Frank is a graphic designer.",
"Grace is an artificial intelligence researcher.",
"Henry is a freelance writer.",
"Isabel is learning machine learning."
]
myscale_settings = MyScaleSettings()
myscale_settings.index_type = 'SCANN'
vectorstore = MyScale.from_texts(texts, embedding=OpenAIEmbeddings(), config=myscale_settings)
retriever = vectorstore.as_retriever()
# LLM とプロンプトテンプレートを設定する:
model = ChatOpenAI()
template = """以下のコンテキストに基づいて質問に答えてください:
{context}
質問:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
# チェーンを作成する
chain = (
{
"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
}
| prompt
| model
| StrOutputParser()
)
# MyScaleCallbackHandler を統合して、チェーンの実行中にトレースデータをキャプチャする:
chain.invoke({"question": "where did harrison work"}, config=RunnableConfig(
callbacks=[
MyScaleCallbackHandler()
]
))
正常に実行された後、MyScaleDB のotel.otel_tracesテーブルに対応するトレースデータが見つかるはずです。
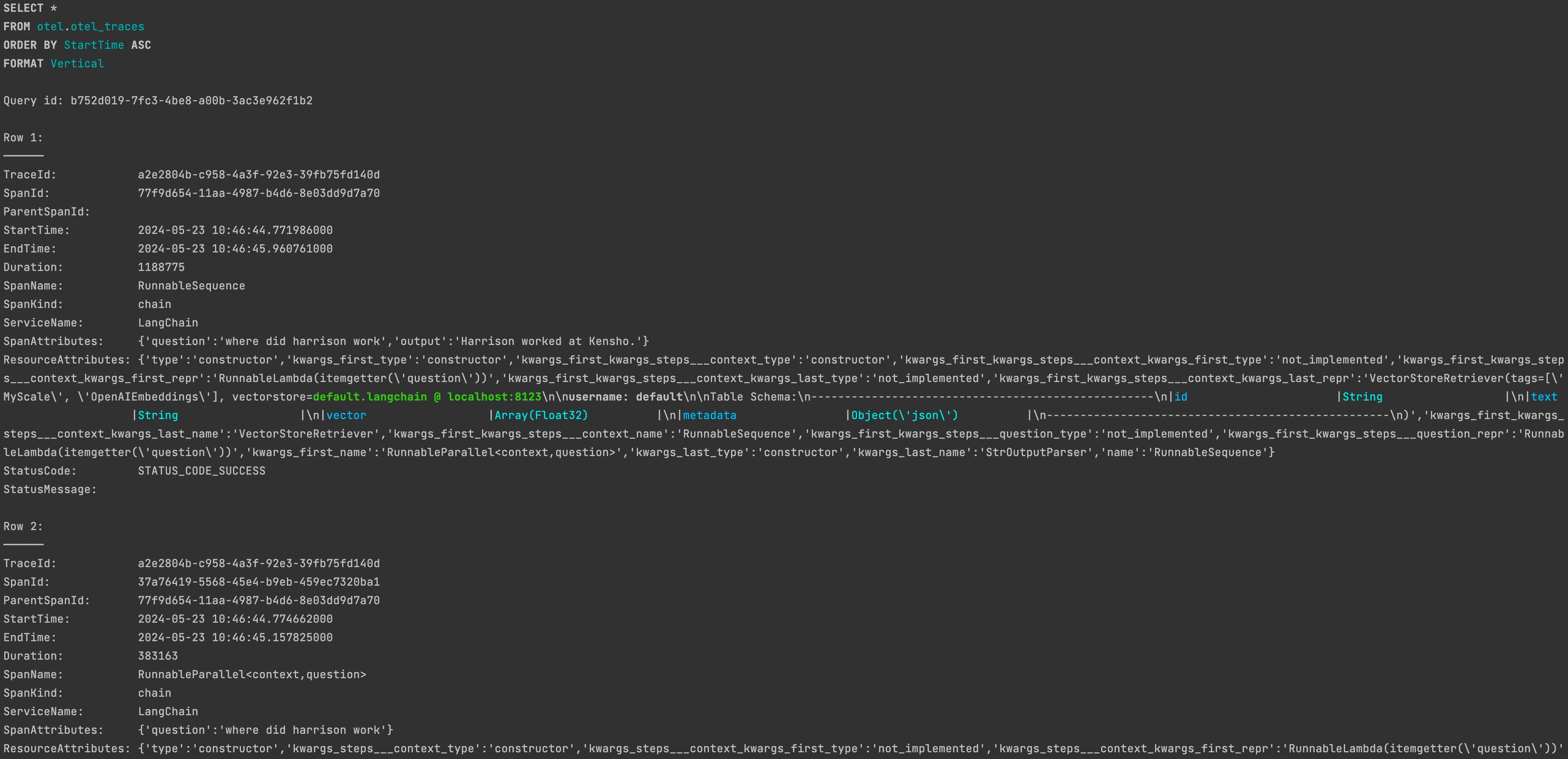
MyScaleCallbackHandlerをカスタマイズする方法については、ドキュメントを参照してください:MyScale Telemetry Custom Parameters (opens new window)。
# オブザーバビリティ
LLM アプリケーションのランタイムから MyScale Telemetry によって収集されたトレースデータを簡単かつ明確に表示するために、Grafana Trace Dashboard (opens new window)も提供しています。 このダッシュボードを使用すると、LangSmith と同様に、LLM アプリケーションの状態をモニタリングし、デバッグとパフォーマンスの改善を容易にすることができます。
Docker Compose の例では、http://localhost:3000 (opens new window)で Grafana インスタンスを起動する。ユーザー名 admin とパスワード admin でログインする。
# トレースダッシュボードのセットアップ
MyScale Telemetry Handler を使用して収集したトレースデータを MyScale Trace Dashboard で表示するには、次の手順に従ってください。
Grafana-clickhouse-datasource Plugin (opens new window)をインストール:
Grafana に新しい ClickHouse データソースを追加:
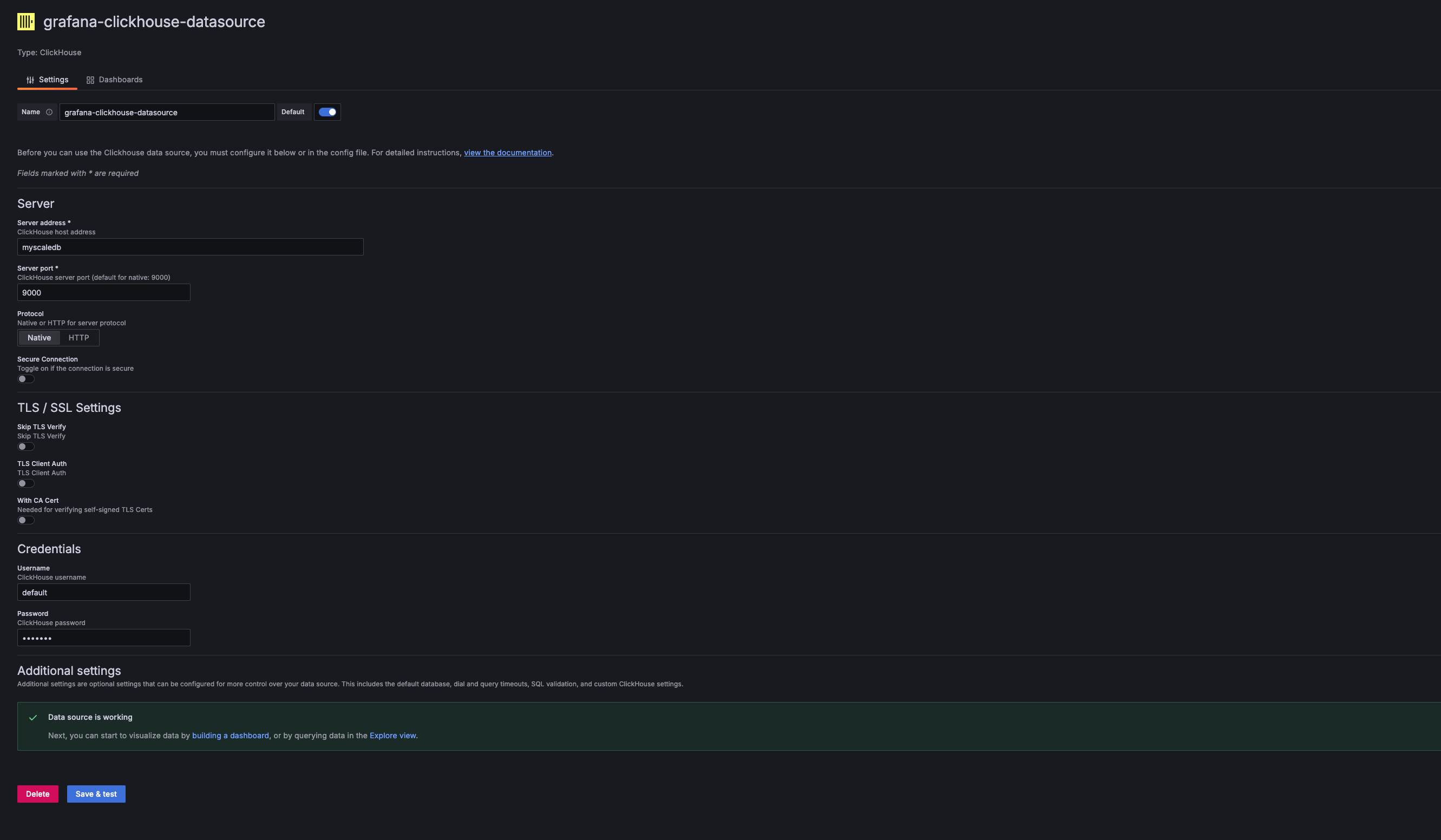
Grafana のデータソース設定で、新しい ClickHouse データソースを追加します。サーバーアドレス、サーバーポート、ユーザー名、パスワードは、使用する MyScaleDB のホスト、ポート、ユーザー名、パスワードに対応する必要があります。 提供された Docker Compose の例では、これらの値は次のとおりです:
- Address:
myscaledb - Port:
9000 - Username:
default - Password:
default
- Address:
MyScale Trace Dashboard をインポート:
ClickHouse データソースが追加されたら、MyScale Trace Dashboard (opens new window)をインポートできます。
ダッシュボードを設定:
インポート後、MyScale クラスタ(Clickhouse データソース名)、データベース名、テーブル名、および分析したいトレースの TraceID を選択します。ダッシュボードには、選択したトレースのトレーステーブルとトレースの詳細パネルが表示されます。
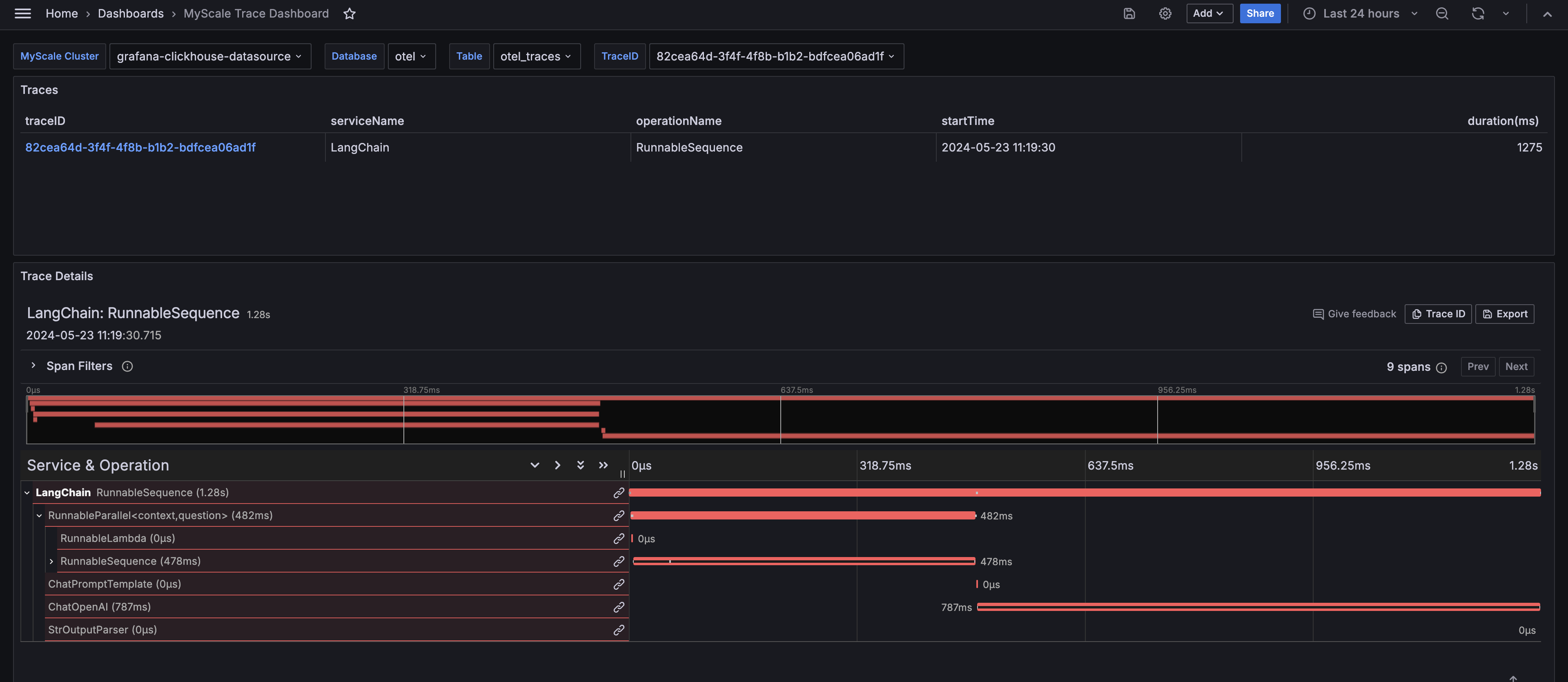
# MyScale Trace Dashboard からの洞察
MyScale Trace Dashboard は、LangSmith と同様に、LLM アプリケーションのランタイム動作に関する包括的な洞察を提供します。パフォーマンスのボトルネックを特定するのに役立つ各関数の実行時間、データのフローを追跡するのに役立つ入力と出力の詳細な表示、データベースリトリーバによって返される具体的なデータ、プロンプト情報、ChatOpenAI によって生成される出力などが表示されます。 さらに、API コールに関連するコストを監視および最適化するためのトークン使用の詳細も表示されます。
# 関数の実行時間
ダッシュボードは、LangChain アプリケーションの各関数の実行時間を表示し、パフォーマンスのボトルネックを特定するのに役立ちます。

# 入力と出力
ダッシュボードは、チェーン全体の入力と出力の詳細な表示を提供し、データのフローを追跡するのに役立ちます。

# DB リトリーバの返り値
データベースリトリーバによって返される具体的なデータが表示され、正しいデータがプロンプトでフェッチされて使用されていることを確認できます。

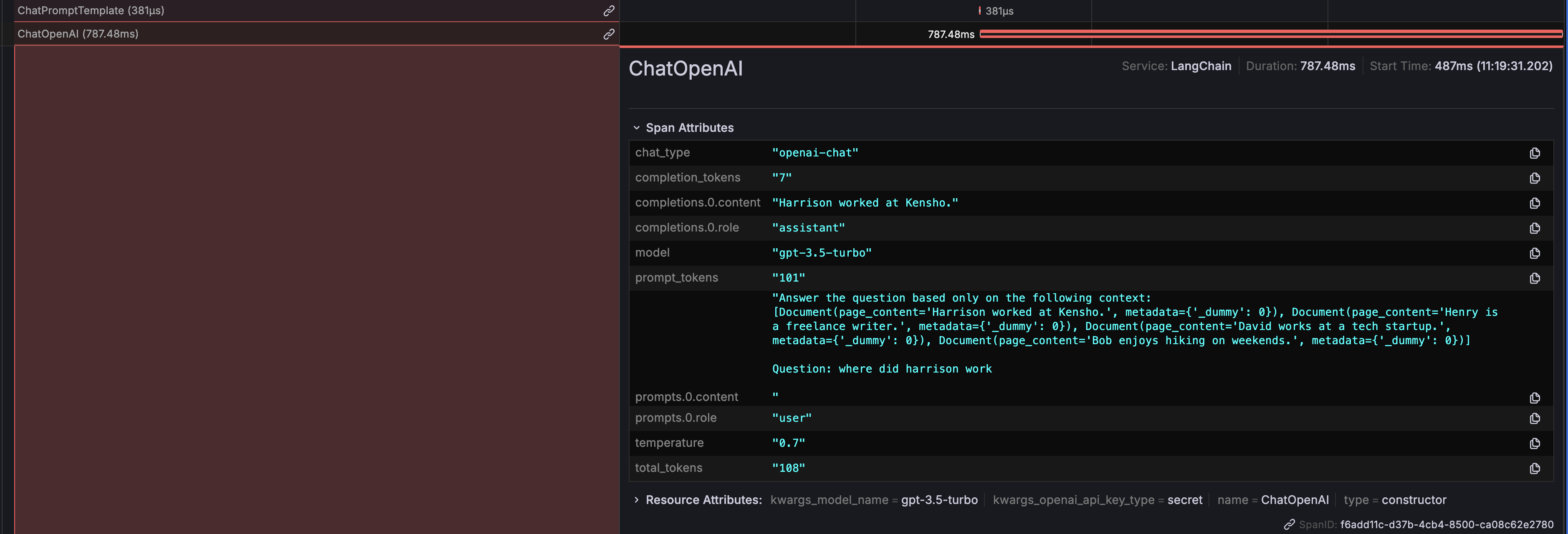
# プロンプト情報
LLM に送信される具体的なプロンプトが表示され、質問の正確性と関連性を確保するために重要です。

# ChatOpenAI の出力
ChatOpenAI によって生成される出力が表示され、LLM がプロンプトに対してどのように応答しているかが明確になります。
さらに、API コールに関連するコストを監視および最適化するために、トークンの使用状況の詳細も表示されます。
# Ragas による評価
MyScaleDB に格納されたスパンデータを使用して、人気のあるオープンソースの RAG 評価フレームワークであるRagas (opens new window)を使用して、RAG パイプラインを分析および評価することができます。
以下の Python コードは、Ragas を使用してトレースをスコアリングする方法を示しています。スコアリングでは、取得したコンテキストと生成された回答を評価します。
import os
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_utilization
from clickhouse_connect import get_client
def score_with_ragas(query, chunks, answer):
test_dataset = Dataset.from_dict({"question": [query], "contexts": [chunks], "answer": [answer]})
result = evaluate(test_dataset, metrics=[faithfulness, answer_relevancy, context_utilization])
return result
def evaluate_trace(question, topk, client, database_name, table_name):
trace_id, answer = client.query(
f"SELECT TraceId, SpanAttributes['output'] as Answer FROM {database_name}.{table_name} WHERE SpanAttributes['question'] = '{question}' AND ParentSpanId = ''"
).result_rows[0]
span_dict = client.query(
f"SELECT SpanAttributes FROM {database_name}.{table_name} WHERE TraceId = '{trace_id}' AND SpanKind = 'retriever'"
).result_rows[0][0]
contexts = [span_dict.get(f"documents.{i}.content") for i in range(topk)]
print(score_with_ragas(question, contexts, answer))
test_question = "where did harrison work"
client = get_client(
host=os.getenv("MYSCALE_HOST"),
port=int(os.getenv("MYSCALE_PORT")),
username=os.getenv("MYSCALE_USERNAME"),
password=os.getenv("MYSCALE_PASSWORD"),
)
evaluate_trace(test_question, 4, client, "otel", "otel_traces")
この例を実行すると、Ragas が提供するスコアを使用して RAG パイプラインのパフォーマンスを評価することができます。


# 結論
MyScale Telemetry は、LLM アプリケーションのオブザーバビリティと評価を向上させるための堅牢なオープンソースのソリューションを提供します。LangChain Callbacks とシームレスに統合することで、詳細なトレースデータをキャプチャし、MyScaleDB に保存することができます。これにより、問題の診断、パフォーマンスの最適化、アプリケーションの動作の理解が容易になります。
Grafana の MyScale Trace Dashboard は、トレースデータを明確に可視化し、LLM アプリケーションを効果的にモニタリングおよびデバッグするのに役立ちます。主な洞察には、関数の実行時間、入力と出力の追跡、DB リトリーバの返り値、プロンプト情報、ChatOpenAI の出力、トークンの使用状況などが含まれます。
さらに、MyScale Telemetry と Ragas を統合することで、RAG パイプラインを包括的に評価することができます。MyScaleDB に格納されたトレースデータを使用して、Ragas は信頼性、回答の関連性、コンテキストの利用などのメトリックを評価し、高品質な結果と継続的な改善を確保します。
MyScale Telemetry と Grafana Dashboard をぜひお試しください。ご質問やさらなるサポートが必要な場合は、サポートチームまでお気軽にお問い合わせください。




