
データベースという言葉が出てくると、関係データベース (opens new window)がデータストレージのデフォルト選択肢として長い間使用されてきました。その理由は、シンプルさと使いやすさです。しかし、現代のデータ駆動型の世界では、テキスト、画像、音声などの非構造化データの重要性が増し、ベクトルデータベース (opens new window)が有力な代替手段として登場しました。
従来のデータベースは、整数や文字列などのプリミティブなデータ型に制限されていますが、ベクトルデータベースはデータをベクトルとして格納・管理します。これにより、非構造化データを効率的に処理できるため、非常に人気があります。近年、多くの企業がベクトルデータベースとベクトル検索サービスを提供しています。そのため、このシリーズの記事では、MyScale (opens new window)といくつかの他の人気のあるベクトルデータベースを包括的に比較し、最初の対象としてPineconeを取り上げます。Pinecone (opens new window)は、高次元ベクトルデータを効率的に処理するために設計されたクローズドソースの専門ベクトルデータベースです。ベクトル埋め込みの格納、インデックス付け、クエリ処理に優れており、類似性検索やリアルタイムで高次元ベクトル操作が必要な機械学習アプリケーションに最適なソリューションです。
MyScaleとPineconeの比較の前に、ベクトルデータベースに関連する重要な概念を簡単に紹介します。
# ベクトル検索の重要性
ベクトルは、値の配列、テキストデータ、空間データ、画像などを表すことができます。基本的なベクトル演算やドット積を行うことで、簡単にアラインメント/類似性を見つけることができることは、誰もが知っています。
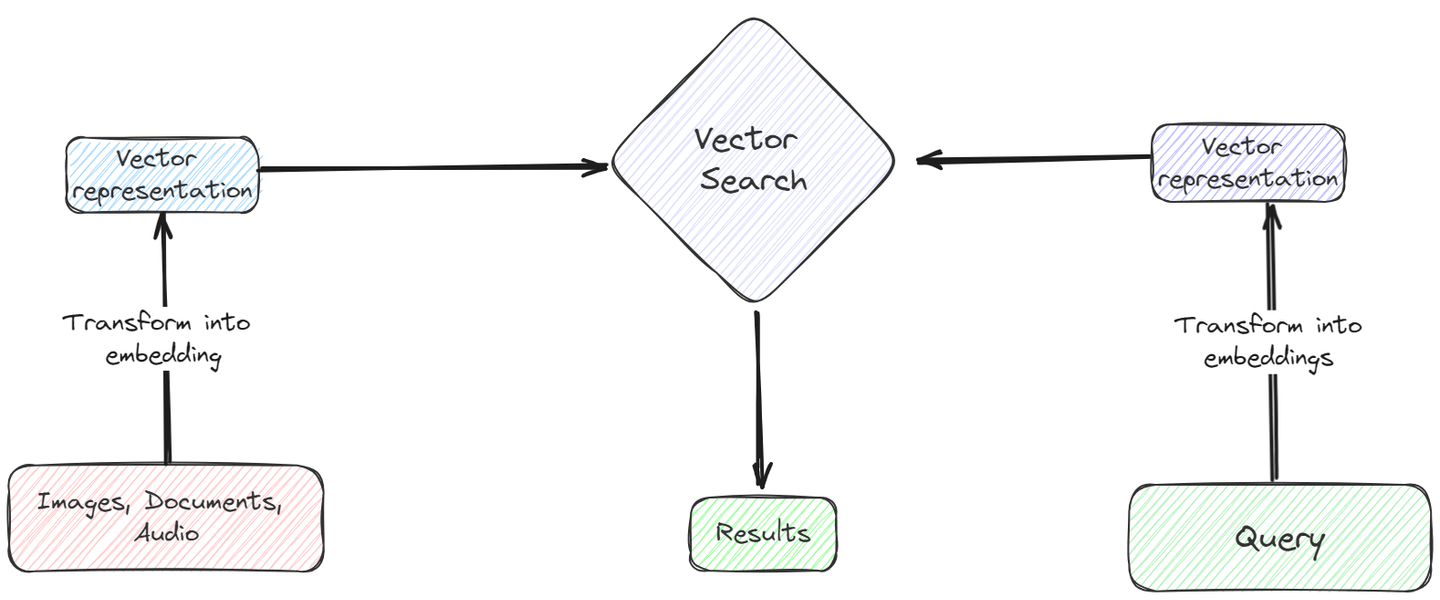
適切な埋め込みを使用することで、非構造化データをベクトルデータベースにベクトルの形式で格納することができます。その後、コサイン類似度やユークリッド距離などの基本的な類似性尺度を使用して、ベクトル上で迅速かつ効率的に類似性検索を実行することができます。このベクトル検索は、従来のデータベースに比べてはるかに高速で費用効果が高く、大量の非構造化データを効果的に処理するのに適しています。
# SQLベクトルデータベースとは
専門のベクトルデータベースに加えて、一部のSQLデータベースはベクトル検索の機能を拡張して提供しています。これらの統合ソリューションは、SQLベクトルデータベース (opens new window)として知られ、構造化データ環境内でベクトルベースの類似性検索機能を提供し、統一されたデータベースフレームワーク内でベクトルデータと構造化データの両方を管理できるようにします。 [Image: testtt (1).png]
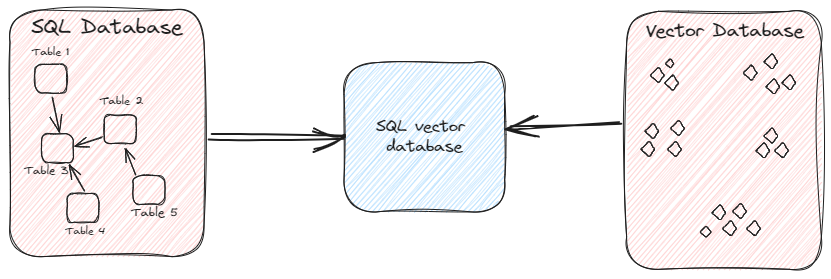
SQLベクトルデータベースの中でも、MyScaleはClickHouseの機能を拡張したオープンソースのオプションです。MyScaleは、速度とパフォーマンスの面で専門のベクトルデータベースさえも凌駕することができる唯一の統合データベース (opens new window)です。
# LLMの領域での重要性
LLMの登場に伴い、その応用はさまざまな領域に広がっています。これらの基本モデルは、LangChain、LlamaIndexなどのさまざまな方法を使用してアプリケーションの特定の要件に適応することができます。
ファインチューニングでは、既存のモデルを使用して新しい/関連するデータにファインチューニングします。学習が関与するため、計算量が非常に多くなります。LoRAなどの技術があるにせよ、ファインチューニングにはまだかなりのGPUが必要です。
一方、RAG (opens new window)は従来の学習プロセスを必要としません。代わりに、ベクトル検索にベクトル埋め込みを使用します。この方法では、基本的な類似性尺度を使用するため、検索プロセスが大幅に高速化されます。
これまで、ほぼすべての基本的な概念をカバーしました。それでは、MyScaleとPineconeの2つのデータベースを比較してみましょう。
# ホスティング
データベースソリューションを選択する際には、ホスティングは重要な要素です。ホスティングオプションは、パフォーマンス、スケーラビリティ、管理に大きな影響を与えます。堅牢なホスティングオプションを選択することで、データベースがさまざまな負荷に対応でき、アクセス可能で簡単にメンテナンスできるようになります。また、ホスティングオプションを理解することで、自分自身のリソースを使用してデータベースをローカルに展開するか、クラウドホステッドサービスを選択するかを判断することができます。
両方のオプションは、クラウドベースのモードでクラウド内にインスタンスを作成することで利用できます。Pineconeは専用のクラウドサービスとしてのみ動作し、MyScaleはクラウド版のMyScale Cloud (opens new window)と、https://github.com/myscale/myscaledbで利用可能なオープンソース版を提供しています。オープンソース版は、次のDockerコマンドを使用して起動できます。
docker run --name MyScale --net=host myscale/MyScale:1.6
さらに、MyScale Cloudでは無料のティアが提供されており、サインアップ (opens new window)してすぐに実験を開始することができます。詳細については、クイックスタートドキュメント (opens new window)をご覧ください。
# コア機能
# クエリ言語とAPIサポート
新しいデータベーステクノロジーを採用する際の重要な考慮事項の1つは、既存の開発ワークフローとの統合の容易さと、クエリ言語の使い慣れ具合です。幸いなことに、MyScaleはリレーショナルデータベースで使用するSQLを使用することで、その手間を省くことができます。
MyScaleはSQLのサポートに加えて、Pythonクライアント (opens new window)、Node.js (opens new window)、Goクライアント (opens new window)、ClientJDBCドライバ (opens new window)、HTTPSインターフェース (opens new window)など、さまざまな開発者ツールを統合しています。
TL;DR:
PineconeとMyScaleの両方がさまざまな言語でSDKを提供していますが、MyScaleは完全なSQLサポートを備えているという特徴があります。
# サポートされるデータ型
Pineconeはベクトルのみを専門に扱っています。一方、MyScaleははるかに多様なデータ型をサポートし、テキストから画像までさまざまなデータ型を格納することができます。
スカラー属性とベクトル属性を持つテーブルを作成することができます。SQLのインターフェースを使用するため、通常のリレーショナルDBテーブルの作成と同じように感じます。このSQLコードは、長さ512のbody_vectorを持つテーブルを作成します。
CREATE TABLE default.wiki_abstract(
id UInt64,
body String,
title String,
url String,
body_vector Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 512
)
ENGINE = MergeTree
ORDER BY id;
また、タブular形式を使用しているため、行の長さに制限はありません。そのため、ドキュメントのサイズに制限はありません。これは競合他社とは異なります。
# インデックス作成
ベクトルデータベースでは、IVFやKDツリーなどのさまざまなインデックスアルゴリズムが使用されます。PineconeはHierarchical Navigable Small Worlds(HNSW)アルゴリズムとFreshDiskANNアルゴリズムを使用しています。FreshDiskANNは、効率的なリアルタイムの更新をサポートし、大規模なデータセットに対して高い再現性とパフォーマンスを提供するように設計されています。
MyScaleは、階層的なツリークラスタリングとグラフベースの検索を組み合わせたMulti-Scale Tree Graph(MSTG) (opens new window)アルゴリズムを導入しています。MSTGは、より高速な検索とリソース消費の削減を提供することで、現代のアルゴリズムを凌駕しています。もしMyScaleをPineconeよりも選ぶ理由があるとすれば、MSTGが十分に魅力的な理由でしょう。
# フィルタリングされたベクトル検索
Pineconeは、メタデータフィルタリングを提供し、ベクトルごとに最大40KBのメタデータをサポートしています。このメタデータには、文字列、数値、ブール値などが含まれており、詳細な属性ベースの検索が可能です。Pineconeの単一ステージのフィルタリングメカニズムにより、指定された条件を満たすアイテムに限定された検索が行われ、ブルートフォース検索を回避することでプロセスが高速化され、より正確になります。
MyScaleは、MSTGアルゴリズムとClickHouseの高度なインデックスと並列処理の機能を活用して、フィルタリングされたベクトル検索 (opens new window)を最適化しています。さらに、メインのベクトル検索の前にデータセットを狭めるための事前フィルタリング戦略も採用されており、パフォーマンスと精度を向上させています。ClickHouseの列指向ストレージ、ベクトル化されたクエリ実行、高度なインデックス、並列処理により、MyScaleは大規模なデータセットに最適な基盤となり、後処理の欠点なしに速度と精度を維持します。
TL;DR:
Pineconeは豊富なメタデータサポートを備えた詳細な属性ベースの検索に優れています。しかし、MyScaleは事前フィルタリング戦略とSQLベースのアーキテクチャにより、大規模データセットに対するパフォーマンスとスケーラビリティが優れています。
# フルテキスト検索
MyScaleは、Tantivyライブラリを使用した高度なフルテキスト検索 (opens new window)(FTS)機能も提供しており、曖昧検索やワイルドカード検索、BM25アルゴリズムに基づく関連性スコアリングなどが可能です。この設定により、MyScaleは非構造化テキストデータへの直感的で効率的なアクセスを実現し、トピックやキーアイデアに基づいて検索することができます。MyScaleは、複雑なテキスト検索要件に対する堅牢で効率的なソリューションを提供します。基本的なFTSインデックスを作成するには、次の構文に従うことができます。
-- フルテキスト検索インデックスの作成
ALTER TABLE [table_name] ADD INDEX [index_name] [column_name]
TYPE fts;
-- クエリの実行
SELECT
id,
title,
body,
TextSearch(body, 'non-profit institute in Washington') AS score
FROM default.en_wiki_abstract
ORDER BY score DESC
LIMIT 5;
一方、Pineconeはベクトル検索専用であり、組み込みのフルテキスト検索機能は含まれていません。
TL;DR:
MyScaleのこのフルテキスト検索機能により、包括的なデータクエリと分析が必要なアプリケーションに対して、より多機能な選択肢となります。
# LLM APIの統合
ここでは、LangChain、LlamaIndexなどの一般的なAPIをサポートしているため、それぞれの違いはほとんどありません。 具体的なイメージを持つために、以下にMyScaleでLangChainを使用する基本的なコードを示します。
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
output = docsearch.similarity_search("How LLMs operate?", 3)
# 価格設定
PineconeとMyScaleの両方には無料のティアが提供されています。新しいツールを実装する前に、ユーザーはしばしばそれを試してみることを望むため、これは非常に役立ちます。Pineconeの無料ティアでは、約300,000個の1,536次元のベクトルを含む約2GBのストレージを扱うことができます。
一方、MyScaleは、最大5百万個の768次元のベクトルに対する無料ストレージを提供しており、約2百万個の1,536次元のベクトルを格納することができます。これはPineconeの無料ティアよりもはるかに高い容量ですので、初期費用なしでより大規模なデータセットを管理する必要があるユーザーにとって、MyScaleはより魅力的な選択肢となります。
PineconeとMyScaleは、パフォーマンスとストレージの最適化されたポッドをユーザーに提供しています。この柔軟性により、ユーザーは特定のニーズに基づいて最適なソリューションを選択することができます。価格に関しては、MyScaleはPineconeに比べて格段に安価です。
# 容量最適化ポッドの価格設定
以下の表は、アプリケーションにより高いストレージ容量が必要なユーザー向けの理想的なものです。MyScaleとPineconeの容量最適化カテゴリーの価格と容量オプションを示しています。
| ポッドタイプ(MyScale) | ポッドサイズ | MyScale基本価格($/時間) | MyScale推定容量 | ポッドタイプ(Pinecone) | Pinecone基本価格($/時間) | Pinecone推定容量 |
|---|---|---|---|---|---|---|
| 容量最適化ポッド | x 1 | $0.094/時間 | 1,000万個のベクトル | s1 | $0.11 | 500万個のベクトル |
| 容量最適化ポッド | x 2 | $0.189/時間 | 2,000万個のベクトル | s1 | $0.22 | 1,000万個のベクトル |
| 容量最適化ポッド | x 4 | $0.378/時間 | 4,000万個のベクトル | s1 | $0.44 | 2,000万個のベクトル |
| 容量最適化ポッド | x 8 | $0.756/時間 | 8,000万個のベクトル | s1 | $0.89 | 4,000万個のベクトル |
| 容量最適化ポッド | x 16 | $1.511/時間 | 1億6,000万個のベクトル | - | - | - |
| 容量最適化ポッド | x 32 | $3.022/時間 | 3億2,000万個のベクトル | - | - | - |
MyScaleの容量最適化ポッドは、リーズナブルな価格で高い容量を提供しています。Pineconeに比べて、MyScaleはより低い時間当たりのコストでより多くのベクトルを格納することができます。
# パフォーマンス最適化ポッドの価格設定
以下の表は、容量よりもパフォーマンスを優先するユーザー向けの理想的なものです。MyScaleとPineconeのパフォーマンス最適化カテゴリーの価格と容量オプションを示しています。
| ポッドタイプ(MyScale) | ポッドサイズ | MyScale基本価格($/時間) | MyScale推定容量 | ポッドタイプ(Pinecone) | Pinecone基本価格($/時間) | Pinecone推定容量 |
|---|---|---|---|---|---|---|
| 標準ポッド | x 1 | $0.167/時間 | 500万個のベクトル | P2 | $0.17 | 100万個のベクトル |
| 標準ポッド | x 2 | $0.333/時間 | 1,000万個のベクトル | P2 | $0.33 | 200万個のベクトル |
| 標準ポッド | x 4 | $0.667/時間 | 2,000万個のベクトル | P2 | $0.67 | 400万個のベクトル |
| 標準ポッド | x 8 | $1.333/時間 | 4,000万個のベクトル | P2 | $1.33 | 800万個のベクトル |
| 標準ポッド | x 16 | $2.667/時間 | 8,000万個のベクトル | - | - | - |
| 標準ポッド | x 32 | $5.333/時間 | 1億6,000万個のベクトル | - | - | - |
ストレージ最適化ポッドに関しては、MyScaleはPineconeのs1ポッドと比較して、より多くのベクトルを格納する能力を持つ、より費用効果の高いソリューションを提供しています。
TL;DR:
ストレージ最適化ポッドに関しては、MyScaleはPineconeのs1ポッドと比較して、より多くのベクトルを格納する能力を持つ、より費用効果の高いソリューションを提供しています。

# ベンチマーク
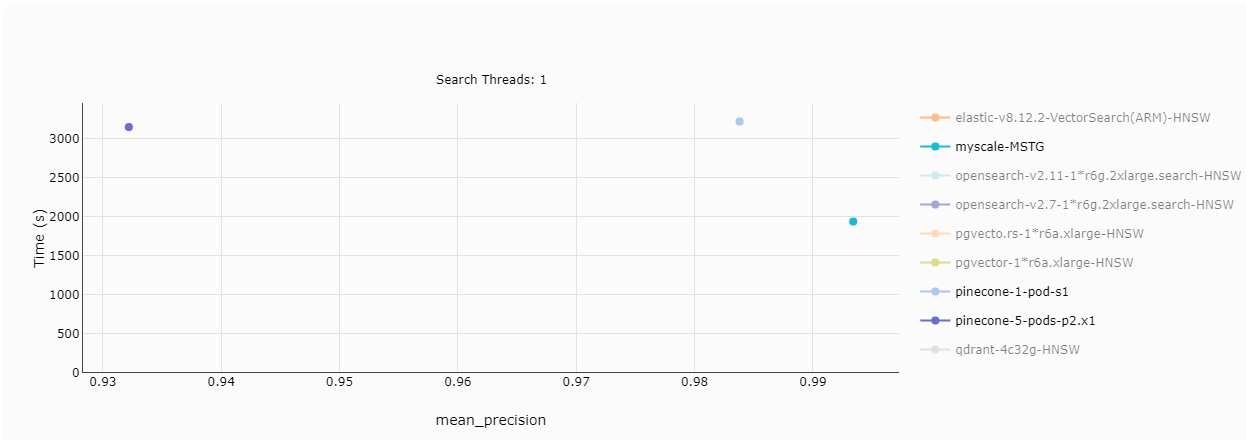
さて、MyScaleとPineconeのパフォーマンスをいくつかの主要なメトリクスでベンチマークを行い、比較してみましょう。比較では、MyScaleはMSTGを使用し、Pineconeは2つのバリアント(1つのノードと5つのポッド)を使用します。
# スループット(クエリ数/秒)
スループットはシステムのパフォーマンスの基本的な指標であり、顧客は自然と1秒あたりのクエリ数に興味を持ちます。シングルスレッドの検索では、Pineconeのs1ポッドはMyScaleに比べて大幅に遅れています。しかし、Pineconeの5つのp2ポッドは、同等のクエリ数を処理することができます。スレッド数が2に増えると、パフォーマンスの差が広がり、8つのスレッドでは、5つのp2ポッドさえも遅れ始めます。
注: グラフでは、黄色がMyScaleを表し、4つの異なるポイントは異なる精度レベルを示しています。より高い精度では、より多くの計算が必要です。Pineconeの制約として、MyScaleのように精度を調整することができないため、リコールが最大でも94%にしかなりません。
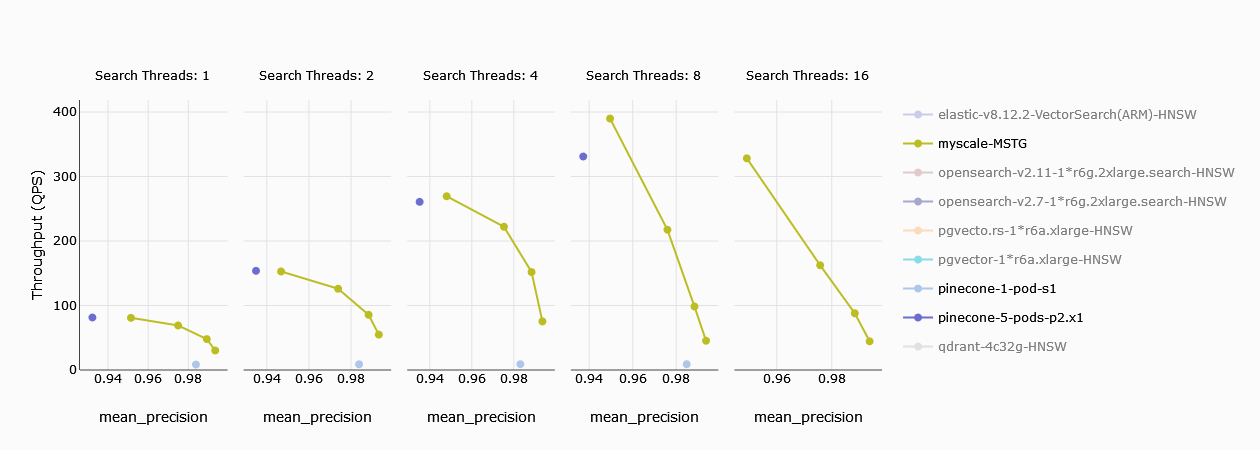
TL;DR:
Pineconeのs1ポッドはMyScaleには敵いませんが、5つのp2ポッドは同等のパフォーマンスを発揮することができます。Pineconeはリコールが94%に制限されるため、MyScaleのように99%のリコールを達成することはできません。
# 平均クエリレイテンシ
次に興味深いメトリクスは、平均クエリレイテンシです。これは、クエリの処理にかかる平均時間を測定するものです。比較では、Pineconeのs1ポッドはMyScaleには匹敵せず、5つのp2ポッドは競争力があります。
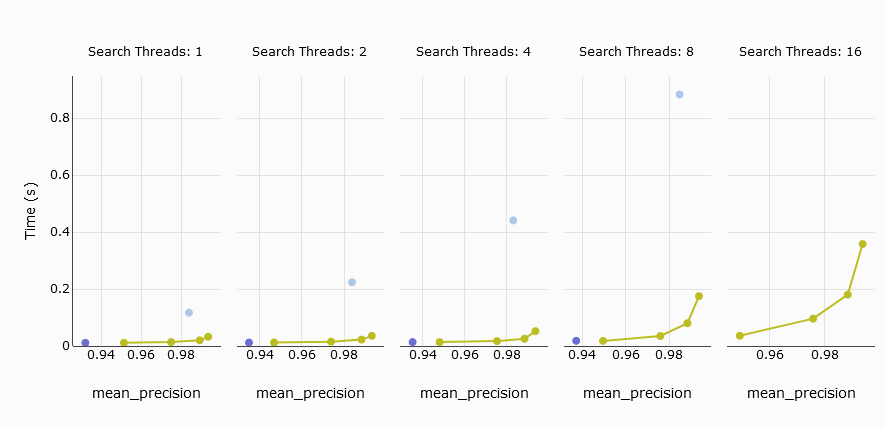
比較をより明確にするために、s1ポッドを除外し、5つのp2ポッドとMyScaleに焦点を当てた結果を見てみましょう。結果からわかるように、MyScaleとPineconeは低い精度では平均クエリレイテンシが似ています。しかし、スレッド数が8以上になると、MyScaleの平均クエリレイテンシが大幅に増加します。
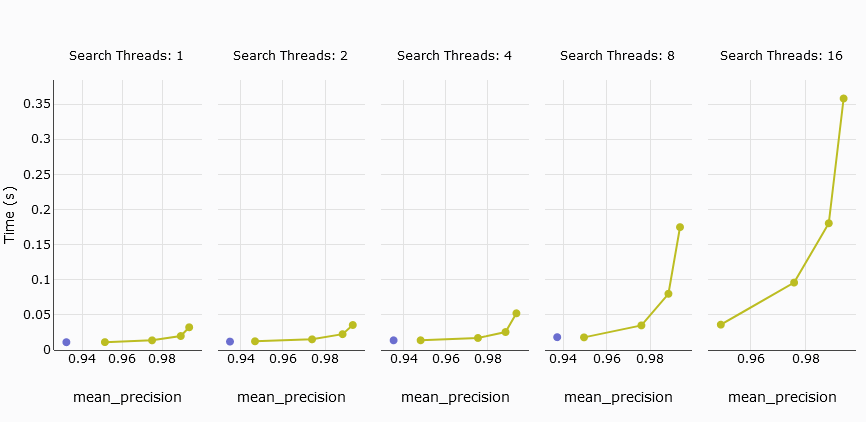
TL;DR:
Pineconeの5つのp2ポッドとMyScaleを比較すると、低い精度では平均クエリレイテンシが似ています。しかし、PineconeはMyScaleのようにリコールを99%以上に調整することができないため、最大リコールが94%に制限されます。
# データインジェスション時間
もう1つ有用なメトリクスは、データインジェスション時間です。データをアップロードしてデータベースを構築するのにかかる時間を測定します。
5百万のデータポイントに対して、MyScaleは約30分でタスクを完了しました。一方、Pineconeのs1は約53分かかります。
# コスト比較
この比較では、パフォーマンスが同等の単一の標準MyScaleポッドと比較して、5つのp2ポッドを使用しました。しかし、5つのp2ポッドのコストは月額約600ドルであり、MyScaleの5倍の価格です。この明確なコスト差は、MyScaleの優れたコスト効果を強調しており、同じパフォーマンスを低コストで提供しています。
| データベース | ポッドタイプ | 月額コスト($) | ノート |
|---|---|---|---|
| MyScale | 標準ポッド of サイズ x1 | 120 | 5つのPinecone p2ポッドと同等のスループットとレイテンシを提供します |
| MyScale | 容量最適化ポッド | 68 | 容量最適化のための費用対効果の高いオプション |
| Pinecone | s1.x1 ポッド | 80 | ストレージに最適化されています |
| Pinecone | 5 x p2.x1 ポッド | 600 | パフォーマンスに最適化されており、水平スケーリングによるものです |
MyScaleの標準ポッドは、同等のスループットとレイテンシを提供するため、非常にコスト効果が高くなっています。一方、Pineconeのs1ポッドと比較して、5つのp2ポッドのコストは約5倍です。
TL;DR:
MyScaleの標準ポッドは、同等のパフォーマンスを提供するために、Pineconeの5つのp2ポッドと比較して5倍のコストがかかります。MyScaleは、容量に優れたストレージ最適化ポッドを提供し、初期コストなしでより大規模なデータセットを管理する必要があるユーザーにとって魅力的な選択肢です。
# 結論
MyScaleとPineconeを比較すると、MyScaleはSQLベースの統合、多様なデータ型のサポート、MSTGアルゴリズムによる優れたパフォーマンスなどで優れています。MyScaleは、より高速なクエリスループットとデータインジェスション時間、費用効果の高いストレージオプション、フルテキスト検索機能を提供しています。これにより、大規模で多様なデータセットを管理するための優れた選択肢となります。
Pineconeは、豊富なメタデータサポートを備えた詳細な属性ベースの検索に強みを持っています。しかし、MyScaleのオープンソース性、スケーラビリティ、パフォーマンスの優位性により、より多機能で強力な選択肢となっています。MyScaleのパフォーマンス、柔軟性、コストの優位性により、さまざまな大規模データ管理ニーズに最適なソリューションとなります。
ご意見やご提案がありましたら、**Twitter (opens new window)またはDiscord (opens new window)**までお気軽にお問い合わせください。



