
この記事では、MyScale という統合ベクトルデータベースと、従来の 2 つのデータベースである PostgreSQL と OpenSearch を比較します。両方のデータベースは、最近ベクトル類似性検索をツールボックスに追加しました。
注意:
私たちはオープンソースプロジェクト vector-db-benchmark (opens new window) で、MyScaleおよび他のベクトルデータベース製品のベンチマーク結果を継続的に更新しています。
大規模言語モデル(LLM)の登場により、検索エンジン、コード生成ツール、データ分析ツールなど、さまざまなアプリケーションに会話型インターフェースを統合することへの関心が高まっています。ベクトル類似性検索は、これを可能にするための重要な技術であり、検索補完生成(RAG)を通じて LLM のパフォーマンスを向上させる (opens new window)のに重要な役割を果たしています。
市場にはさまざまなベクトルデータベース製品があります。一部はベクトルインデックスに特化した専門のベクトルデータベースであり、他のものは統合ベクトルデータベースまたはベクトル検索をサポートするために拡張された汎用データベースです。
さらに、統合ベクトルデータベースには、次のような専門のベクトルデータベースにはないいくつかの利点があります。
- ベクトルと構造化データを同じデータベースに格納するため、より複雑なフィルタリング検索や SQL とベクトルの結合クエリを容易にします。
- SQL などの強力で広く使用されているクエリ言語を使用して、構造化データとベクトルデータの分析を行います。
- 汎用データベースの成熟したツールと統合を活用します。
- 専門のデータベースの専門スキルの追加の労力とライセンスコストを削減します。
比較している 3 つの統合ベクトルデータベースは次のように並びます。
- MyScaleは、ClickHouse をベースに開発された統合ベクトルデータベースであり、ベクトル類似性検索と完全な SQL サポートを組み合わせています。
- PostgreSQLは、pgvector (opens new window)拡張機能を介してベクトル検索をサポートしています。
- OpenSearchは、バージョン 2.9.0 (opens new window)でニューラル(ベクトル)検索を組み込んでいます。
以下で説明するように、包括的なベンチマーク評価により、MyScale はフィルタリングされたベクトル検索の精度、パフォーマンス、コスト効率、およびインデックスの構築時間のすべての面で他の製品を大きく上回っています。重要なことに、MyScale はさまざまなフィルタ比率で健全な検索精度と QPS を提供する唯一のテスト済みの製品です。
また、MyScale は専門のベクトルデータベースにも勝る性能を発揮します。詳細については、この記事 (opens new window)とオープンソースのベンチマーク (opens new window)を参照してください。以下の図に示すように、完全な SQL サポートと高速なベクトル検索パフォーマンスの組み合わせにより、MyScale は AI/LLM 関連データ(構造化およびベクトル化)の管理において魅力的な選択肢となります。
# ベンチマークのセットアップ
MyScale、OpenSearch、および 2 つの Postgres ベクトル検索拡張機能についてベンチマークを実施しました。詳細は以下に示します。
| データベース | Pod タイプ | 月額費用(USD) | ノート |
|---|---|---|---|
| MyScale (opens new window) | Pod サイズ:x1 | 120 | 現在は開発ティア (opens new window)で無料です。 |
| pgvector (opens new window)を使用した Postgres | db.r6g.xlarge (opens new window)(4C 32GB) | 329 | Amazon RDS for PostgreSQL |
| pgvecto.rs (opens new window)を使用した Postgres | db.r6g.xlarge (opens new window)(4C 32GB) | 329 | Amazon RDS for PostgreSQL |
| AWS OpenSearch Service (opens new window) | r6g.2xlarge.search (opens new window)(8C 64GB) | 488 | Amazon OpenSearch Service ドメイン |
ベクトル検索とフィルタリングされたベクトル検索のテストには、LAION 2B images (opens new window)データセットから生成された 500 万個の 768 次元ベクトルを使用しました。
注意:
完全なコード、データセット、および結果は、ベンチマークページ (opens new window)にあります。
各データベースがすべてのベクトルをホストできる最小のポッドタイプを選択しました。
最新バージョンの pgvector と pgvecto.rs は、PostgreSQL クラウドサービスで広く採用されていないため、ベンチマーク実行時には自己ホスティングを選択しました。ただし、比較のために上記の表には Amazon RDS for PostgreSQL の価格も含めています。
注意:
Supabase (opens new window)やTimeScaleDB (opens new window)などの PostgresSQL クラウドサービスは、類似のハードウェア構成に対してより高いコストがかかる場合があります。
OpenSearch では、r6g.xlarge.search(32GB メモリ)インスタンスでベクトルインデックスを構築しようとしたところ問題が発生したため、r6g.2xlarge.search(64GB メモリ)を選択しました。要約に示されているように、MyScale は最もコスト効率の高い統合ベクトルデータベースです。
# ベンチマーク結果
以下に結果をまとめました。
# ベクトル検索
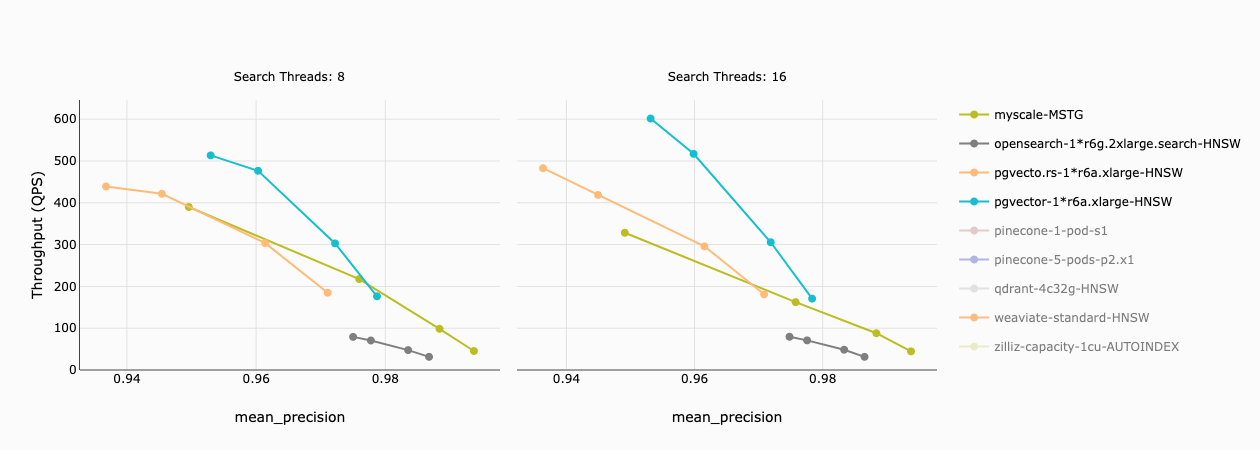
以下のグラフでは、x 軸は精度を、y 軸は各ベクトルデータベースのスループット(QPS)を表しています。次のことがわかりました。
- MyScale と 2 つの Postgres 拡張機能は、精度 97%で同様のスループットを持っています。
- pgvector と pgvecto.rs は、より低い精度でより高いスループットを実現できますが、MyScale よりもはるかに高いコストがかかります。
- OpenSearch はすべての精度で他のデータベースに比べて速度が遅いです。
# フィルタリングされたベクトル検索
実際のシナリオでは、純粋なベクトル検索だけでは十分ではありません。ベクトルには通常、メタデータが付属しており、ユーザーはこのメタデータに 1 つ以上のフィルタを適用する必要があります。
以下のグラフは、フィルタ比率が 1%のデータセットにおける MyScale(および他の統合ベクトルデータベース)のスループットを示しています。フィルタ比率 1%は、フィルタ条件が適用された後に残るベクトル数(1%x 5M ベクトル)が 50,000 であることを意味します。
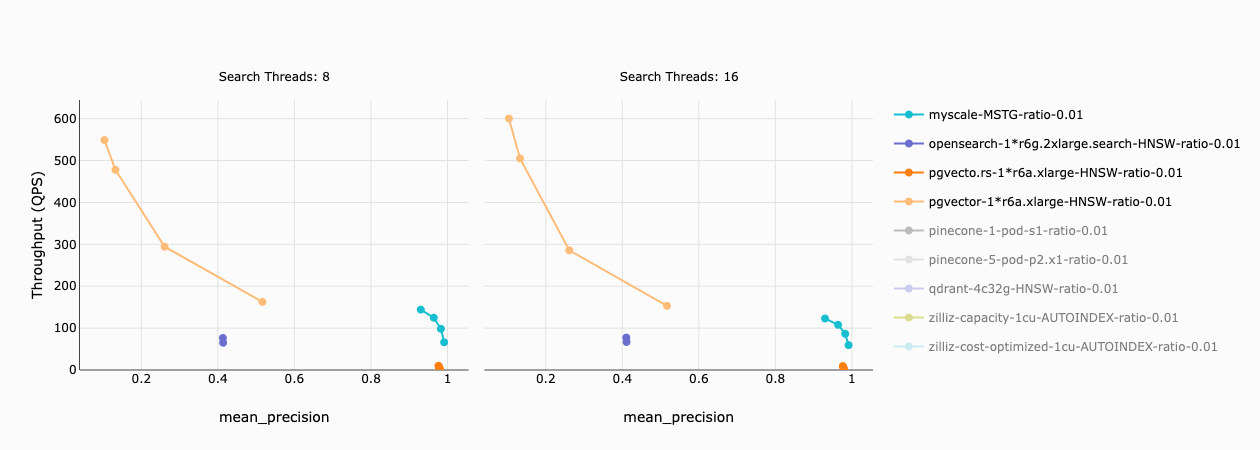
次の情報がわかりました。
- pgvector と OpenSearch の精度は低く(50%未満)、実用的にはほとんど使用できません。
- pgvecto.rs のスループットは比較的低く(10 QPS 未満)、MyScale のスループット(66〜144 QPS)と精度(93%〜99%)は健全です。
これらのデータベースでフィルタリングされたベクトル検索を実装する際には、主に 2 つのアプローチがあります。
# ポストフィルタリング
この方法では、まずベクトル検索が行われ、その後、フィルタに一致しない結果が削除されます。ただし、この方法には 2 つの重要な欠点があります。
- 第一に、検索対象の要素数は予測できません。フィルタは既に候補リストを減らした状態に適用されるためです。
- 第二に、フィルタが非常に制限的で、つまり、データセットのサイズに対してデータポイントのわずかな割合のみに一致する場合、元のベクトル検索に一致するデータが含まれていない可能性があります。
# プリフィルタリング
pgvector と OpenSearch の低い精度は、ポストフィルタリングの使用に起因します。対照的に、MyScale と pgvecto.rs は、プリフィルタリングとして知られる異なるアプローチを使用しています。フィルタはまず適用され、ビットマップがベクトルインデックスに渡されてベクトル検索が行われます。
ベンチマーク中、pgvecto.rs が使用する HNSW アルゴリズムは、フィルタ比率が低い場合に性能が低下しました。さらに、PostgreSQL の行ベースのストレージは、プリフィルタリングで必要な大規模なスキャン操作に対してフレンドリーではないため、最適なパフォーマンスが得られませんでした。一方、MyScale は、ClickHouse の高速な列指向 SQL 実行エンジン (opens new window)と当社独自のMSTG ベクトルインデックスアルゴリズム (opens new window)を組み合わせることで、この問題を克服しています。
# コスト効率の評価:純粋なベクトル検索とフィルタリングされたベクトル検索
データベースを選択する際には、単なるパフォーマンスだけでなく、投資から得られる価値も考慮する必要があります。特に 95%の精度などの高い精度でのコスト効率は、大規模なベクトル検索を実行する企業にとって重要な基準となります。
# 純粋なベクトル検索
コスト効率を明確に把握するために、各データベースの月額費用を、約 95%の精度で達成できるクエリ毎秒(QPS)との関係で調査し、各データベースの 100 QPS あたりのコストを示しています。
次の結果からわかるように、MyScale は最も優れたコスト効率を提供し、最も近い競合他社を最低 1.8 倍上回っています。
| データベース | 100 QPS あたりの月額費用(USD) |
|---|---|
| MyScale | 30 |
| pgvector | 54 |
| pgvecto.rs | 79 |
| OpenSearch | 613 |
# フィルタリングされたベクトル検索(フィルタ比率 1%)
ただし、多くの実世界のシナリオでは、純粋なベクトル検索以上の要件があります。データセットにフィルタリングが適用され、結果が絞り込まれることがよくあります。フィルタ比率が 1%のフィルタリングされたベクトル検索のコスト効率を評価すると、状況は変わります。**特に、pgvector と OpenSearch は 50%を超える精度を達成できませんでした。**この低い精度はほとんどの場合で使用できないため、この分析では N/A としています。
| データベース | 100 QPS あたりの月額費用(USD) |
|---|---|
| MyScale | 96 |
| pgvector | N/A |
| pgvecto.rs | 3290 |
| OpenSearch | N/A |
結論として、MyScale は純粋なベクトル検索でトップランナーの地位を保ちながら、フィルタリングされたベクトル検索でもその優位性がより顕著です。優れたパフォーマンスを最小のコストで提供する MyScale は、企業にとって最適な投資リターンを保証します。高い精度、コスト効率、パフォーマンスの組み合わせにより、MyScale は統合ベクトルデータベースを効果的に活用する組織にとって優れた選択肢となります。
# インデックスの構築時間
ベクトルをベクトルデータベースに挿入した後、ベクトル検索を実行する前にベクトルインデックスを作成する必要があります。インデックスの構築時間は、高速な検索結果にとって重要です。4 つの異なるベクトルデータベースのインデックスの構築時間は、次の表に示されています。
| データベース | アップロードと構築時間 |
|---|---|
| MyScale | 32 分 |
| Pgvector | 10.9 時間 |
| Pgvecto.rs | 80 分 |
| OpenSearch | 45 分 |
これらの結果からわかるように、MyScale は最も高速な構築時間で明らかなリーダーです。pgvector は並列ビルドのサポートがないため、HNSW ベクトルインデックスの構築が非常に遅いです。高速なインデックスの構築は、アプリケーションが多くのベクトルを挿入および更新する必要がある場合(大規模なオンラインチャット、ドキュメント編集など)、およびインデックスの構築とベクトル検索のリソース競合を減らすために重要です。
# 結論
徹底的な分析の結果、MyScale は競合他社を常に上回り、フィルタリングされたベクトル検索と迅速なインデックスの構築時間で優れたパフォーマンスを発揮します。テストされた製品の中で、さまざまなフィルタ比率で高い検索精度と QPS を提供する唯一の統合ベクトルデータベースは MyScale です。MyScale の他の製品との違いは、優れたコスト効率も兼ね備えていることであり、堅牢な統合ベクトルデータベースの選択肢として、また財務的に賢明な選択肢として浮上します。統合ベクトルデータベースの機能を活用しようとする組織にとって、パフォーマンス、精度、コスト効率の非常に優れた組み合わせが MyScale を際立たせます。

# さらなる探求
パフォーマンスの面で MyScale が専門のベクトルデータベースにどのように対抗しているかについて、この記事 (opens new window)を読むことをおすすめします。
また、PostgreSQL から MyScale にベクトルデータを移行することを検討している場合は、このガイド (opens new window)が貴重な洞察とステップバイステップの手順を提供します。



