
ベクトルデータベース (opens new window)とベクトル検索 (opens new window)は、印象的な速度とスケーラビリティを備えているため、急速に人気を集めています。これらのデータベースは、従来の機械学習モデルとは異なり、ユークリッド距離 (opens new window)、コサイン類似度 (opens new window)などの効率的な類似度尺度を活用して、広範なトレーニングを必要とせずに高速な検索結果を提供します。この効率性と、MLベースの代替手段と比較してのコスト効果の高さから、さまざまなアプリケーションにおいて魅力的なソリューションとなっています。
ベクトルデータベースの増加する景気に鑑みると、特定のニーズに合った適切なデータベースを選択することは困難です。スループット、コスト、機能性などの要素は、理想的な適合度を決定する上で重要な役割を果たします。
この記事は、2つの主要な競合製品であるMyScaleDB (opens new window)とQdrant (opens new window)の詳細な比較について掘り下げます。両データベースは独自の利点を提供しており、包括的な分析が情報を提供し、意思決定をサポートするために不可欠です。
注: ベクトルデータベースに初めて触れる方は、このシリーズの最初の記事 (opens new window)から始めることをおすすめします。これにより、この強力なテクノロジーの基礎的な理解が得られます。
# MyScaleDBとQdrantの紹介
# MyScaleDB
MyScaleDBは、AIアプリケーションとソリューションに最適化されたクラウドネイティブデータベースです。オープンソースで高いスケーラビリティを持つClickHouseデータベース (opens new window)を基盤として構築されており、MyScaleDBは以下のような魅力的な利点を提供しています。
- AIのための統合プラットフォーム: MyScaleDBは、構造化データとベクトル化データをシームレスに管理および処理することで、AIワークフローを効率化します。これにより、複雑なデータパイプラインの必要性がなくなり、開発プロセスが簡素化されます。
- 妥協のないパフォーマンス: 最先端のOLAPデータベースアーキテクチャを活用することで、MyScaleDBはベクトル化データの操作において優れたパフォーマンスを提供します。このアーキテクチャにより、クエリの実行が高速化され、要求の厳しいAIワークロードに最適です。
- SQLによるシンプルさ: MyScaleDBはSQLの普遍性を取り入れており、開発者が広く採用されているなじみのある言語を使用してデータベースと対話することができます。これにより、専門的なクエリ言語を学ぶ必要がなくなり、開発サイクルが加速し、生産性が向上します。
- 高度な検索のためのMSTGインデックス: MyScaleDBは、高いデータ密度と最適化された検索パフォーマンスを実現するために設計された先進的なインデックスアルゴリズムであるMulti-Scale Tree Graph Algorithm (MSTG) (opens new window)アルゴリズムを利用しています。MSTGは、基本的なベクトル検索とフィルタリングされたベクトル検索 (opens new window)の両方で優れたパフォーマンスを発揮し、関連情報の迅速かつ正確な検索を保証します。
# Qdrant
Qdrantは、もう1つの現代的なベクトルデータベースです。オープンソースであり、Dockerおよびクラウドの両方で利用可能です。Qdrantの特徴は以下の通りです。
- 高度な圧縮: Qdrantは、バイナリ量子化 (opens new window)を使用して、任意の数値ベクトル埋め込みをブール値のベクトルに変換します。これにより、最大40倍の高速な検索パフォーマンスが実現されます。
- マルテナンシーサポート: ペイロードベースのパーティショニングを持つ単一のコレクションを持つことをマルテナンシー (opens new window)と呼びます。Qdrantは、複数のユーザーがインスタンスを共有するためにこれをサポートしています。
- I/O Uring (opens new window): Qdrantは、
io_uringをサポートしており、OSのシステムコールのオーバーヘッドを軽減するためにスループットを向上させます。
MyScaleDBとQdrantが提供する機能を理解したら、次は主な違いに焦点を当てましょう。これらの違いにより、パフォーマンスからユニークな機能まで、特定のニーズと優先事項に最も適したデータベースを特定することができます。
# ベクトルデータベースのホスティングの柔軟性:重要な考慮事項
データベースソリューションを評価する際、ホスティングはパフォーマンス、スケーラビリティ、管理の容易さに大きな影響を与える重要な要素となります。適切なホスティングオプションを選択することで、データベースは変動するワークロードを優雅に処理し、高い可用性を維持し、管理のオーバーヘッドを最小限に抑えることができます。
ホスティングに関して、MyScaleDBとQdrantの両方はオープンソース版、クラウドベースのソリューション、オンプレミスのソリューションを提供しています。クラウドホスティングには無料および有料のティアがあり、詳細については以下で説明します。
# クラウドホスティング
MyScaleDBクラウド (opens new window)では、無料のポッドを利用して500万個の768次元ベクトルをサポートできます。こちら (opens new window)でサインアップし、詳しい手順についてはMyScaleDBクイックスタート (opens new window)をご覧ください。
Qdrantは、前払い費用なしで永久に利用できる1GBの無料クラスタを提供しています。Qdrantを使用するには、クラウドのクイックスタート (opens new window)をご覧ください。
# オンプレミス
オンプレミスソリューションでは、Dockerイメージが一般的なオプションです。MyScaleDBのDockerイメージを起動するには、次のようにします。
docker run --name MyScaleDB --net=host MyScaleDB/MyScaleDB:1.6
次に、ClickHouseクライアントを使用してデータベースに接続します。
docker exec -it MyScaleDBdb clickhouse-client
同様に、QdrantもDockerを使用してローカルで実行できます。
docker run -p 6333:6333 qdrant/qdrant
# コア機能
ホスティングオプションはデータベースのアクセシビリティとスケーラビリティの基盤を築きますが、真の違いはコア機能にあります。このセクションでは、各プラットフォームの重要な機能を分析し、ベクトルベースのデータ処理の複雑さにどのように対応しているかを明らかにします。
これらの機能を理解することで、各データベースがベクトルベースのデータ処理の主要なタスクをどのように処理し、どのデータベースが特定のニーズに最も適しているかを把握することができます。
# クエリ言語とAPIサポート
クエリ言語と利用可能なAPIサポートの選択は、開発者の生産性と統合の容易さに重要な役割を果たします。MyScaleDBとQdrantがこれらの側面にどのように対応しているかを見てみましょう。
# マルチ言語サポート:
- Qdrant: Qdrantは、Python (opens new window)、Java (opens new window)、Go (opens new window)、.Net (opens new window)、Rust (opens new window)、TypeScript/JavaScript (opens new window)向けのSDKを備えた広範なマルチ言語サポートを誇っています。この言語サポートの幅広さにより、さまざまなテクノロジースタックとのシームレスな統合が可能です。
- MyScaleDB: MyScaleDBは、Python、Java、Go、Node.JS (opens new window)向けのSDKを提供し、人気のあるプログラミング言語をしっかりとサポートしています。
両データベースともに、立派なマルチ言語サポートを提供していますが、MyScaleDBはSQLの独自の利用方法により、他とは一線を画しています。MyScaleDBでは従来のSQLクエリを使用することができ、ベクトルデータベースや従来のデータベースの組み合わせなど、さまざまなデータベースとの統合もシームレスに動作します。
SELECT id, date, label,
distance(data, {target_row_data}) AS dist
FROM default.myscale_search
ORDER BY dist LIMIT 10
MyScaleDBのdistanceメソッドは、指定されたベクトルと特定の列に格納されているすべてのベクトルとの間の類似度を計算します。
注: SQLで作業する場合は、間違いなくMyScaleDBが選択肢になります。
# サポートされるデータ型
多様なデータ型を扱う能力は、どのデータベースにとっても重要ですが、ベクトルデータベースも例外ではありません。MyScaleDBとQdrantをサポートするデータ型について比較してみましょう。
# Qdrantの柔軟なJSONアプローチ
Qdrantは、JSONペイロードの柔軟性を活用して、以下のようなさまざまなデータ型を格納およびクエリできます。
- キーワード: テキストベースの検索とフィルタリングに使用します。
- 整数と浮動小数点数: 数値データと範囲クエリに使用します。
- ネストされたオブジェクトと配列: 複雑なデータ構造を表現するために使用します。
このJSON中心のアプローチにより、データモデリングの柔軟性が向上し、さまざまなユースケースに対応できます。
# MyScaleDBのSQLによる柔軟性
MyScaleDBは、フルSQL互換性を活用してデータ型のサポートをさらに進化させています。これにより、ベクトルデータだけでなく、整数、浮動小数点数、文字列、日付などの従来のデータ型を含むさまざまなデータ型を管理できます。
- 構造化データ: 整数、浮動小数点数、文字列、日付などの従来のリレーショナルデータ型。
- JSON: セミストラクチャ化されたデータやネストされたオブジェクトの処理に使用します。
- ジオスパシャルデータ: 位置ベースのクエリと空間解析に使用します。
- 時系列データ: タイムスタンプ付きデータの格納と分析に使用します。
MyScaleDBは、単一のプラットフォーム内でベクトルデータとさまざまな従来のデータ型を処理できる能力を持つため、大きな利点となります。この統合アプローチにより、データ管理が簡素化され、データの隔離がなくなり、異なるデータ型をまたがる強力なクエリが可能となります。
以下は、MyScaleDBが管理できるさまざまなカラムを含むテーブルの例です。
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 768
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
このSQLコマンドは、構造化データとベクトル化データを含むテーブルを作成し、ベクトルのサイズを768とし、idでソートすることでクエリの最適化を行います。
TL;DR: 両方のデータベースは、幅広い数値とテキストのデータ型を効果的にサポートしていますが、MyScaleDBは、高度なSQL互換性、強力なOLAP機能、ジオスパシャルデータや時系列データなどの複雑なデータ構造への包括的なサポートなど、さらに進化しています。
# インデックス
インデックスに関しては、QdrantはHierarchical Navigable Small World (HNSW) (opens new window)アルゴリズムを使用していますが、これは標準的なベクトル検索には効果的ですが、フィルタリングされた検索操作には苦労します。
MyScaleDBは、Multi-Scale Tree Graph (MSTG)アルゴリズムを導入することで、この制限に対処しています。MSTGは、階層的なツリークラスタリングとグラフベースの検索を組み合わせることで、検索の速度とパフォーマンスを大幅に向上させます。これにより、標準的なベクトル検索と複雑なフィルタリングされたベクトル検索の両方において非常に効率的な検索が可能となります。
ちなみに、MyScaleDBとQdrantの両方はマルチベクトル検索をサポートしています。
注: MSTGは現代のインデックスアルゴリズムよりも優れており、MyScaleDBは標準的なベクトル検索とフィルタリングされたベクトル検索の両方で大きな利点を持っています。
# フルテキスト検索
フルテキスト検索 (opens new window)は、Qdrant(バージョン0.10.0以降)とMyScaleDBの両方で利用可能です。Qdrantは、トークン化とテキストフィールドのインデックス作成をサポートすることで、特定の単語やフレーズに基づいて検索やフィルタリングを行うことができます。

一方、MyScaleDBは、Tantivyライブラリを使用しており、正確かつ効率的なドキュメントの検索にBM25アルゴリズムを活用しています。
# Qdrantの例
以下は、Qdrantでフルテキストインデックス(通常はペイロードインデックスと呼ばれます)を作成する例です。
from qdrant_client import QdrantClient, models
client = QdrantClient(url="<http://localhost:6333>")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
min_token_len=2,
max_token_len=15,
lowercase=True,
),
)
このQdrantのコードスニペットでは、単語の長さや大文字と小文字の区別などのパラメータに基づいて、テキストフィールドをトークン化してテキストインデックスを設定しています。
# MyScaleDBの例
MyScaleDBの例では、英語のストップワードを使用したstemトークナイザーを使用しています。この場合、テーブルen_wiki_abstractを使用しています(この例 (opens new window)では詳細に使用されています)。
ALTER TABLE default.en_wiki_abstract
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
注: 両方のデータベースは、効果的なソリューションを提供しているため、フルテキスト検索の点ではあまり差がありません。
# フィルタリングされた検索
MyScaleDBは、MSTGアルゴリズムとビットマスキング技術を組み合わせることで、フィルタリングされたベクトル検索を最適化しています。この組み合わせにより、ClickHouseの高度なインデックスと並列処理の機能を活用することで、MyScaleDBは大規模なデータセットを効率的に処理することができます。事前フィルタリング戦略を利用することで、MyScaleDBはメインのベクトル検索の前にデータセットを絞り込み、最も関連性の高いデータのみを処理するため、パフォーマンスと精度の両方が大幅に向上します。
Qdrantは、フィルタリング可能なバージョンのHNSWアルゴリズム (opens new window)を使用し、検索プロセス中にフィルタを適用して関連するノードのみを考慮するようにしています。
# ジオ検索
MyScaleDBとQdrantの両方がジオ検索をサポートしています。MyScaleDBには、ジオスパシャル関数をサポートするいくつかのジオスパシャル関数 (opens new window)があります。たとえば、次の関数は地球上の2点間の距離を求めます(多様体としての地球を想定しています)。
greatCircleDistance(lon1Deg, lat1Deg, lon2Deg, lat2Deg)
# LLM APIの統合
ベクトル検索の最大の応用は、LLM(Language Models)とRAG(Retrieval-Augmented Generation)です。QdrantとMyScaleDBの両方は、LlamaIndex (opens new window)、LangChain (opens new window)、Hugging Face (opens new window)など、いくつかのLLM APIの統合をサポートしています。
# 価格設定
QdrantとMyScaleDBの両方は、フリーミアムの価格設定モデルを採用しており、実験や小規模なプロジェクトに適した無料のティアと、要求の厳しいワークロードに対応するためのよりパワフルな有料のティアを提供しています。重要なことは、両プラットフォームともに、クレジットカード情報を提供することなく無料のオファーを利用できることです。
# 無料ティア
- Qdrant: 無料ティアでは、1GBのストレージ容量を提供しています。
- MyScaleDB: MyScaleDBの無料ティアははるかに寛大で、最大500万個の768次元ベクトルを格納することができます。これをQdrantのプラットフォームで実現するには、約275ドル/月の有料プランが必要です。
# 有料ティア
有料ティアでは、QdrantとMyScaleDBの両方がGCP、Azure、AWSの3種類のクラウドホスティングを提供しています。通常、AzureとAWSの方がコストが高く、GCPが最も経済的なオプションです。
有料ティアでは、QdrantのGCPホスティングとMyScaleDBを比較します。MyScaleDBでは、容量最適化オプションとパフォーマンス最適化オプションの両方を考慮し、一貫した768次元のベクトルサイズを使用します。
| 容量 | Qdrant($/時間) | ノード数 | MyScaleDB 容量最適化($/時間) | ポッド数 | MyScaleDB パフォーマンス最適化($/時間) | ポッド数 |
|---|---|---|---|---|---|---|
| 1000万個 | 0.75 | 1 | 0.09 | 1 | 0.33 | 2 |
| --- | --- | --- | --- | --- | --- | --- |
| 2000万個 | 1.5 | 1 | 0.19 | 2 | 0.67 | 4 |
| 4000万個 | 3.02 | 2 | 0.38 | 4 | 1.33 | 8 |
| 8000万個 | 4.52 | 3 | 0.76 | 8 | 2.67 | 16 |
| 1億6000万個 | 9.05 | 6 | 1.51 | 16 | 5.33 | 32 |
| 3億2000万個 | 16.58 | 11 | 3.02 | 32 | 10.66 | 64 |
MyScaleDBの容量最適化ポッドでは、1つのポッドあたり1000万個のベクトルを取得できます。一方、パフォーマンス最適化設定では、より低いレイテンシとなり、結果としてストレージ用のポッドが増えます。Qdrantの最も経済的な設定よりも、MyScaleDBのパフォーマンス最適化ポッドの方がはるかに安価です。
また、MyScaleDBは線形なスケーリングファクターを持つ一方、Qdrantはより非対称なパターンを示していることがわかります。
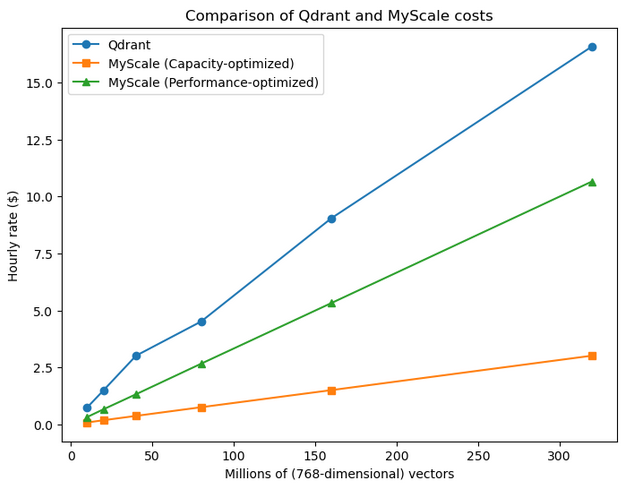
注: 価格に関しては、無料ティアまたは有料ティアのどちらにおいても、MyScaleDBには敵いません。
# ベンチマーク
前述の機能比較は有益な情報を提供しますが、客観的なベンチマークはMyScaleDBとQdrantのパフォーマンス能力をより具体的に理解するのに役立ちます。
# スループット(クエリ数/秒)
スループットは、通常クエリ数/秒(QPS)で測定され、データベースが効率的に同時リクエストを処理する能力を直接反映します。ベンチマーク結果は明らかに、MyScaleDBのスループットがQdrantよりも優れていることを示しています。さらに、同時スレッド数が増加するにつれて、パフォーマンスの差は大幅に広がり、MyScaleDBが重いワークロード下でも優れたスケーラビリティを示しています。
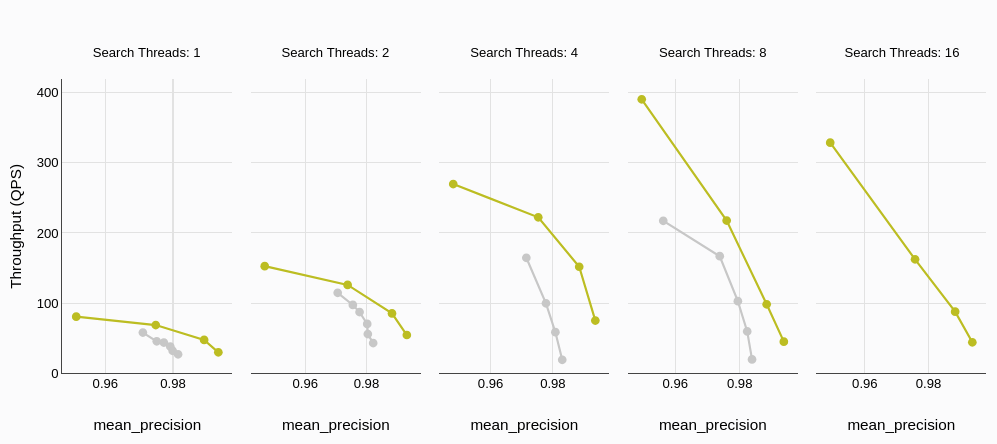
# 平均クエリレイテンシ
平均クエリレイテンシは、ミリ秒または秒単位で測定され、データベースがクエリを処理し結果を返すまでの平均時間を表します。低いレイテンシは、リアルタイムアプリケーションやユーザーエクスペリエンスにおいて重要な要素です。
ベンチマーク結果は、MyScaleDBの平均クエリレイテンシがQdrantよりも著しく低いことを一貫して示しています。この傾向は、スレッド数が異なる場合でも一貫しており、MyScaleDBが高い同時性下でも低いレイテンシを維持できることを示しています。
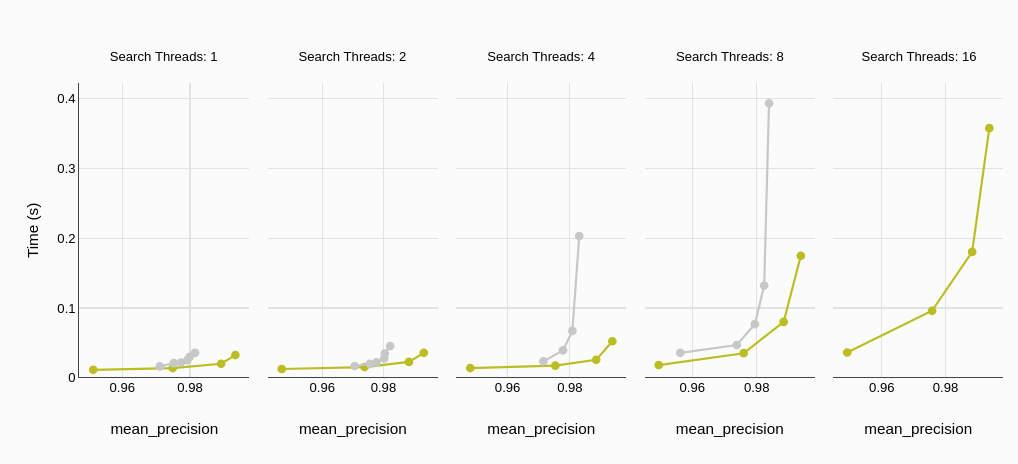
実際のアプリケーションにおいては、P95(95パーセンタイル)のレイテンシも同様の傾向が見られ、MyScaleDBの低いレイテンシが強調されます。
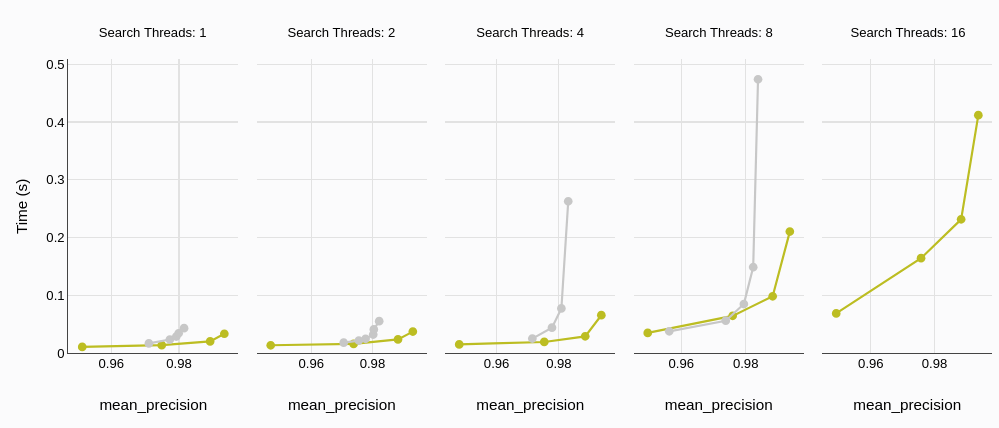
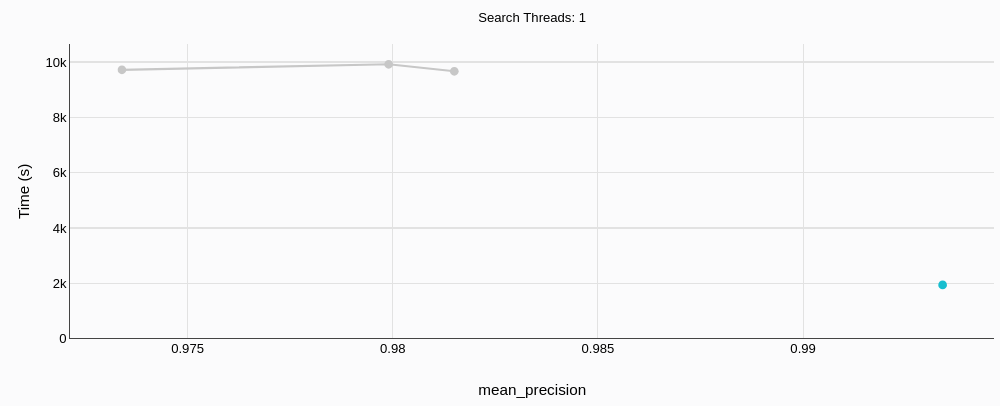
# ビルド時間
MyScaleDB(緑色;右下の小さな点)は、より高い精度を持ちながらも、ほぼ5倍速くビルドすることができます。
# 月額費用
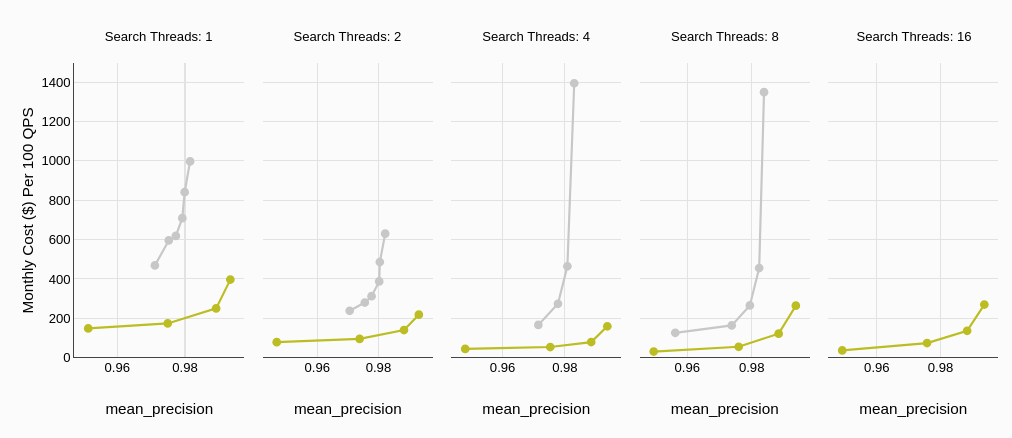
コスト効率は、適切なデータベースソリューションを選択する際の重要な要素です。価格のセクションで強調されているように、MyScaleDBは一般的にQdrantよりも手頃なオプションを提供しており、特に高同時性のシナリオでは、MyScaleDBのコストがはるかに低いです。
このグラフは、検索スレッド数に関して説明しています。Qdrantのコスト(灰色)は、検索スレッド数が増加するにつれて急激に上昇する傾向があります。対照的に、MyScaleDBははるかに低いコストプロファイルを維持し、より高いスレッド数でも比較的安定しています。

# 結論
QdrantとMyScaleDBは、ベクトルデータベースの急速に進化する景気の中で注目すべき競合製品です。Qdrantは市場での長い存在感から広く採用されており、スパースベクトルのサポートや効率的な量子化技術などの魅力的な機能を提供しています。
しかし、MyScaleDBは、以下の主要な領域で重要な利点を持つ強力な代替手段として浮上しています。
- パフォーマンスとスケーラビリティ: MyScaleDBは、ベンチマークで一貫してQdrantを上回り、優れたスループット、低いレイテンシ、要求の厳しいワークロードに対する印象的なスケーラビリティを実証しています。
- コスト効率: MyScaleDBは、寛大な無料ティアと有料プランのコストがQdrantよりもはるかに低いため、魅力的な価値提案を提供しています。特に高同時性のシナリオでは、MyScaleDBのコストがはるかに低いです。
- 統合データ管理: MyScaleDBは、単一のプラットフォーム内でベクトルデータと多様な従来のデータ型を管理できる能力を持つため、データパイプラインが簡素化され、異なるデータ型をまたがる強力なクエリが可能となります。
- SQLによるシンプルさ: MyScaleDBは、SQLの使い慣れた表現力を活用して開発を効率化し、広く採用されている言語を使用してベクトルデータと対話することができます。
最終的な選択肢は、特定の要件と優先事項によって異なります。特にスパースベクトルのサポートや特定の機能が重要な場合は、Qdrantが適切な選択肢となるかもしれません。ただし、パフォーマンス、スケーラビリティ、コスト効率、統合データ管理が重要な要素である場合、MyScaleDBが明らかなリーダーとなります。
自身のユニークなデータ処理とアプリケーション要件に合わせて、慎重に評価し、この比較の洞察を活用して、情報に基づいた意思決定を行うことをお勧めします。



