
現代の世界では、大規模言語モデル(LLM) (opens new window)は、人間が書いたテキストを模倣する能力によって世界を変えてきました。これらのモデルは、新しいコンテンツの作成やスマートな応答の提供などのタスクにおいて非常に優れたスキルを持っており、AIのフィールドをさらに推進しています。これらのモデルは大量のデータで訓練されていますが、そのデータに含まれる情報しか知りませんので、最新の情報を提供することは困難です。これにより、古い回答や誤った情報が生成される可能性があります。これは情報幻覚として知られています。
これらの問題に対処するために、リトリーバル増強生成(RAG)と呼ばれる動的なフレームワークが開発されました。RAGは、従来のLLMの強みとリトリーバルシステムを組み合わせることで、これらのモデルの使用ケースを拡張します。
# RAGとは?
RAGは、LLMのパフォーマンスを向上させるために設計された戦略的な拡張です。テキスト生成中に情報を取得するステップを組み込むことで、RAGはモデルの応答が正確で最新のものであることを保証します。 RAGは大きく進化し、2つの主要なモードが開発されました。
- Naive RAG: これは最も基本的なバージョンであり、システムは単にナレッジベースから関連する情報を取得し、それをLLMに直接渡して応答を生成します。
- Advanced RAG: このバージョンはさらに進化しています。リトリーバルの前後に追加の処理ステップを追加することで、取得した情報を洗練させます。これらのステップにより、生成される応答の品質と正確性が向上し、モデルの出力とシームレスに統合されることが保証されます。
# Naive RAG
Naive RAGは、RAGエコシステムの最初に設計されたバージョンです。リトリーバルデータとLLMモデルを組み合わせるための非常にシンプルな方法で、ユーザーに効率的な応答を提供します。
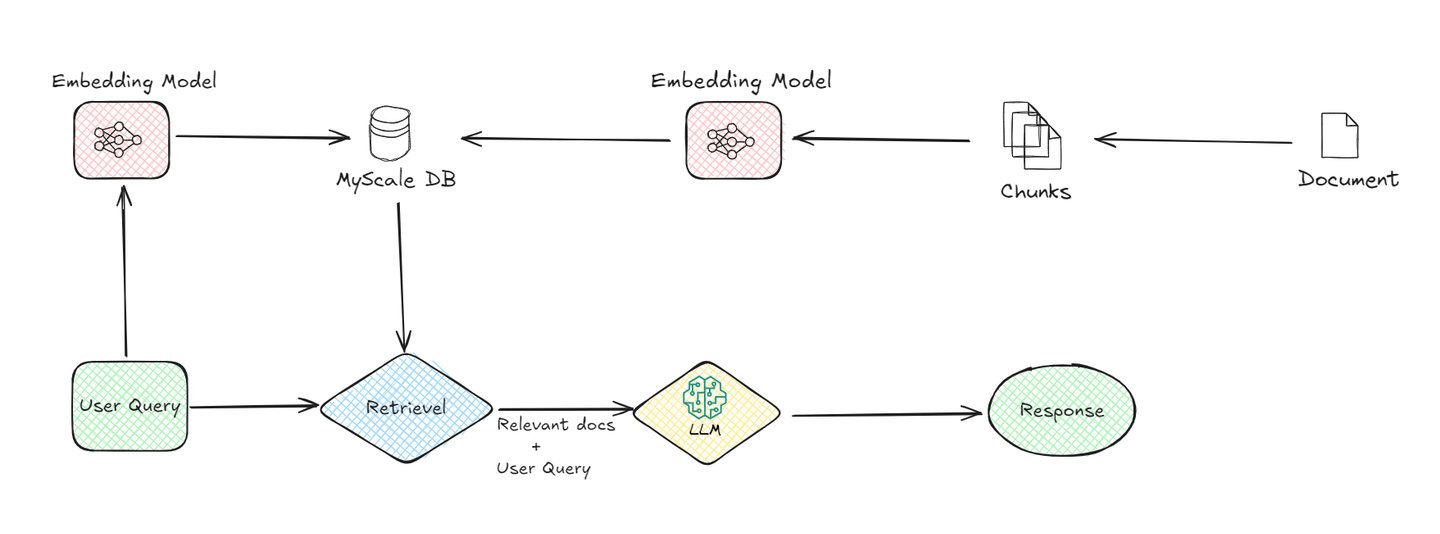
基本的なシステムは以下のコンポーネントから構成されます:
# 1. ドキュメントのチャンキング:
プロセスは、ドキュメントをより小さなチャンクに分割することから始まります。これは、より管理しやすく処理しやすいためです。たとえば、長いドキュメントの場合、セグメントに分割され、後で関連する情報を取得するためにシステムが容易になります。
# 2. 埋め込みモデル:
埋め込みモデルは、RAGシステムの重要な部分です。ドキュメントのチャンクとユーザーのクエリの両方を数値形式に変換します。これは、コンピュータが数値データをより理解しやすくするために必要です。埋め込みモデルは、テキストの意味を数学的な方法で表現するために高度な機械学習技術を使用します。たとえば、ユーザーが質問をすると、モデルはこの質問をクエリの意味を捉えた数値のセットに変換します。
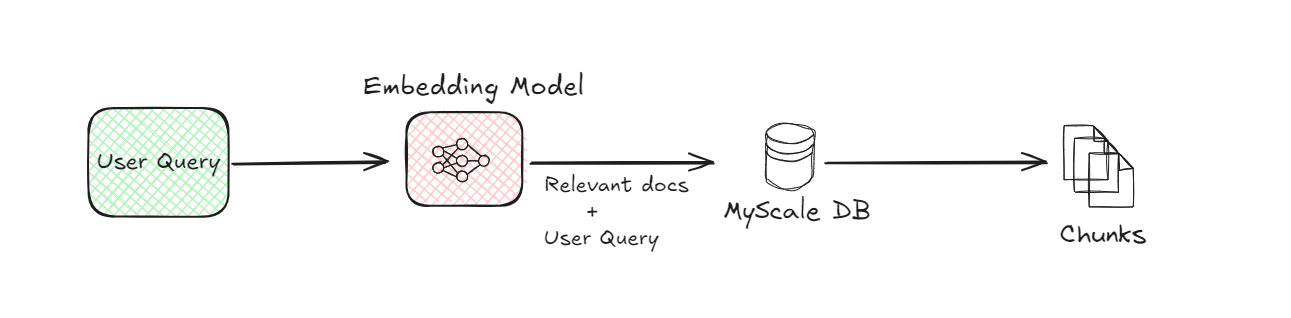
# 3. ベクトルデータベース(MyScaleDB):
ドキュメントのチャンクが埋め込みに変換されると、それらはベクトルデータベース (opens new window)(例:MyScaleDB (opens new window))に格納されます。ベクトルデータベースは、これらの埋め込みを効率的に格納および取得するために設計されています。ユーザーがクエリを送信すると、システムはベクトルデータベースを使用して、クエリの埋め込みとデータベースに格納されている埋め込みを比較して、最も関連性の高いドキュメントのチャンクを見つけます。この比較により、ユーザーが求めているものに最も類似しているチャンクを特定することができます。
# 4. リトリーバル:
ベクトルデータベースが関連するドキュメントのチャンクを特定すると、それらがリトリーバルされます。このリトリーバルプロセスは重要であり、最終的な応答の生成に使用される情報を絞り込む役割を果たします。基本的にはフィルターの役割を果たし、最も関連性の高いデータのみが次のステージに渡されることを保証します。
# 5. LLM(大規模言語モデル):
関連するチャンクがリトリーバルされると、LLMが引き継ぎます。LLMの役割は、リトリーバルされた情報を理解し、ユーザーのクエリに対して明瞭な応答を生成することです。LLMは、ユーザーのクエリとリトリーバルされたチャンクを使用して、関連性があるだけでなく、文脈に適した応答を提供します。このモデルはデータを解釈し、ユーザーが簡単に理解できる自然言語で応答を形成する責任があります。
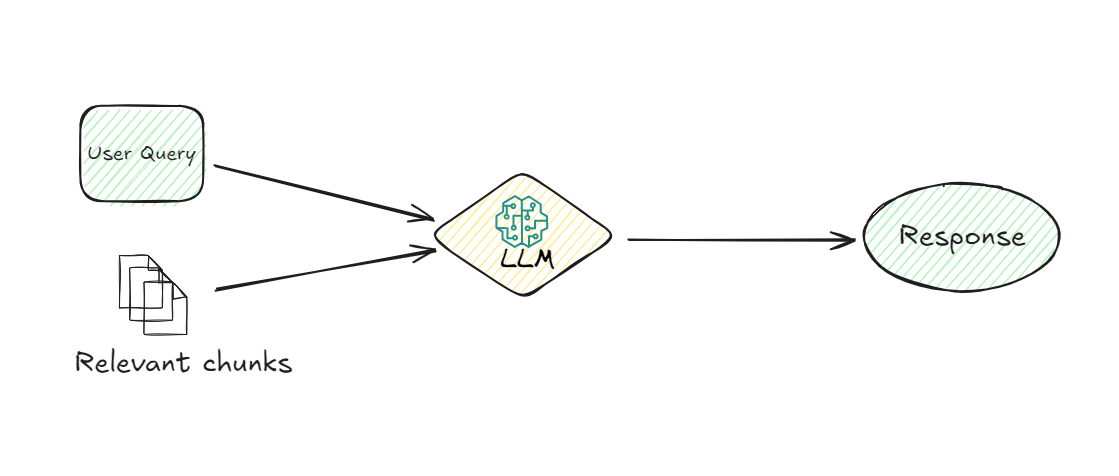
# 6. 応答生成:
最後に、システムはLLMによって処理された情報に基づいて応答を生成します。この応答は、ユーザーに対して求めていた情報を明確かつ簡潔に提供します。
ユーザーのクエリから最終的な応答までのデータの流れを理解することで、Naive RAGシステムの各コンポーネントがユーザーが正確で関連性の高い情報を受け取るために重要な役割を果たしていることがわかります。
# 利点
- 実装の簡単さ: RAGは、リトリーバルと生成を直接統合するため、複雑な変更や追加のコンポーネントを必要とせずに言語モデルの拡張を行うのに簡単です。
- ファインチューニングの不要: RAGの最も重要な利点の1つは、LLMのファインチューニング (opens new window)を必要としないことです。これにより、時間と運用コストが節約され、RAGシステムの迅速な展開が可能になります。
- 正確性の向上: 最新の情報を活用することで、Naive RAGは生成される応答の正確性を大幅に向上させます。これにより、出力が関連性があり、最新のデータを反映していることが保証されます。
- 幻覚の低減: RAGは、リアルな事実データに基づいた応答を生成することで、LLMが不正確な情報や捏造された情報を生成する一般的な問題を軽減します。
- 拡張性と柔軟性: Naive RAGのシンプルさにより、既存のリトリーバルや生成コンポーネントに大幅な変更を加えることなく、さまざまなアプリケーションにスケーリングすることが容易です。この柔軟性により、最小限のカスタマイズでさまざまなドメインに展開することができます。
# 欠点
- 処理の制約: 取得した情報は、さらなる処理や洗練なしに直接使用されるため、生成された応答の一貫性の問題が生じる可能性があります。
- リトリーバルの品質への依存: 最終的な出力の品質は、リトリーバルモジュールが最も関連性の高い情報を見つける能力に大きく依存します。悪いリトリーバルは、正確性や関連性の低い応答をもたらす可能性があります。
- スケーラビリティの問題: データセットが成長するにつれて、リトリーバルプロセスが遅くなり、全体的なパフォーマンスと応答時間に影響を与える可能性があります。
- 文脈の制約: Naive RAGは、クエリの広範な文脈を理解するのに苦労する場合があり、正確ではあるがユーザーの意図と完全に一致しない応答が生成される可能性があります。
これらの利点と欠点を検討することで、Naive RAGがどこで優れているか、どのような課題に直面する可能性があるかを包括的に理解することができます。これにより、改善の余地が生まれ、Advanced RAGの開発の機会が生まれます。
# Advanced RAG
Naive RAGの基盤を築いたAdvanced RAGは、プロセスに洗練さを加えます。Naive RAGとは異なり、Advanced RAGは、応答の関連性と全体的な品質を最適化するための追加の処理ステップを導入します。
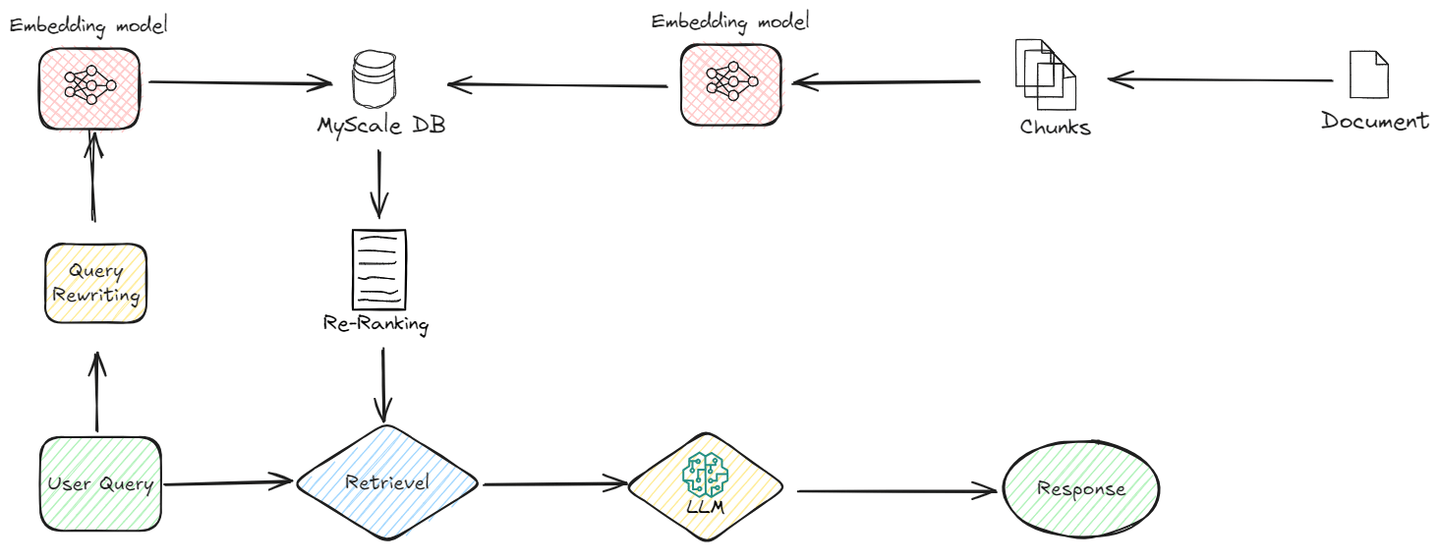
Advanced RAGの動作を理解しましょう:
# リトリーバル前の最適化
Advanced RAGでは、実際のリトリーバルが行われる前に、リトリーバルプロセス自体を洗練します。このフェーズでは、次のようなことが行われます:
# インデックスの改善
インデックスメソッド (opens new window)は、データベース内のデータを効率的に組織化して取得するために重要な役割を果たします。伝統的なインデックスメソッド(例:Bツリー (opens new window)やハッシュインデックス (opens new window))は、この目的に広く使用されてきました。ただし、これらのアルゴリズムの検索速度は、データサイズが増加するにつれて低下します。したがって、より効率的なインデックスメソッドが大規模なデータセットに対して必要です。MyScaleのMSTG(Multi-Strategy Tree-Graph) (opens new window)インデックスアルゴリズムは、そのような進歩の一例です。このアルゴリズムは、速度とパフォーマンスの面で他のインデックスメソッドを上回ります。
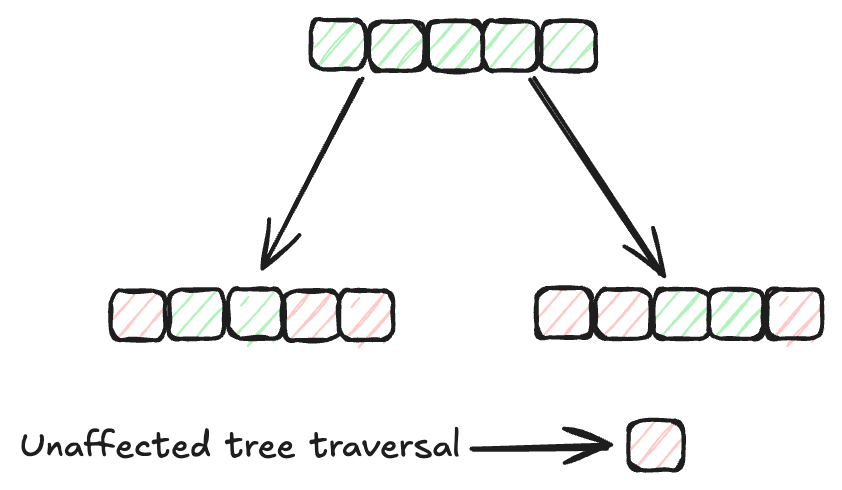
MSTGは、階層グラフ (opens new window)とツリー構造 (opens new window)の両方の利点を組み合わせています。通常、グラフアルゴリズムはフィルタリングされていない検索に対しては高速ですが、フィルタリングされた検索には効率的ではありません。一方、ツリーアルゴリズムはフィルタリングされた検索に優れていますが、フィルタリングされていない検索には遅くなります。これらの2つのアプローチを組み合わせることで、MSTGはフィルタリングされていない検索とフィルタリングされた検索の両方において高いパフォーマンスと正確性を実現し、さまざまな検索シナリオに対して堅牢な選択肢となります。
# クエリの書き換え
リトリーバルプロセスが開始される前に、元のユーザークエリは正確性と関連性を向上させるためにいくつかの改善を受けます。このステップにより、リトリーバルシステムが最も関連性の高い情報を取得できるようになります。ここでは、クエリの書き換え、拡張、変換などの技術が使用されます。たとえば、ユーザーのクエリが広範すぎる場合、クエリの書き換えによってより具体的な文脈や特定の用語が追加され、クエリの拡張によって類義語や関連する用語が追加され、より広範な関連ドキュメントをキャプチャすることができます。
# ダイナミック埋め込み
Naive RAGでは、すべてのタイプのデータに対して単一の埋め込みモデルが使用される場合があり、効率が低下する可能性があります。一方、Advanced RAGでは、特定のタスクやドメインに基づいて埋め込みを微調整し調整します。つまり、埋め込みモデルは、特定のクエリやデータセットに必要な文脈理解をより正確に捉えるためにトレーニングまたは適応されます。
ダイナミック埋め込みを使用することで、システムはより効率的かつ正確になります。なぜなら、埋め込みが特定のタスクの微妙なニュアンスにより一致しているからです。
# ハイブリッド検索
Advanced RAGは、異なる検索戦略を組み合わせてリトリーバルのパフォーマンスを向上させるハイブリッド検索 (opens new window)アプローチも活用しています。これには、キーワードベースの検索、意味ベースの検索、ニューラルベースの検索などが含まれる場合があります。たとえば、MyScaleDBは、フィルタリングされたベクトル検索 (opens new window)と全文検索 (opens new window)をサポートしており、SQLフレンドリーな構文を持つため、複雑なSQLクエリの使用が可能です。このハイブリッドアプローチにより、クエリの性質に関係なく、システムは高い関連性で情報を取得できるようになります。
# リトリーバル後の処理
リトリーバルプロセスの後、Advanced RAGはそこで終わりません。取得したデータをさらに処理して、最終的な出力の品質と関連性を確保します。
# 再ランキング
リトリーバルプロセスの後、Advanced RAGは情報をさらに洗練するための追加のステップを踏みます。このステップは再ランキングと呼ばれ、最も関連性の高く有用なデータを優先的に処理します。最初に、システムはユーザーのクエリに関連する複数の情報を取得します。しかし、この情報のすべてが同じ価値を持つわけではありません。再ランキングは、クエリにどれだけ近いか、コンテキストにどれだけ適合するかなどの追加の要素に基づいて、このデータをソートします。
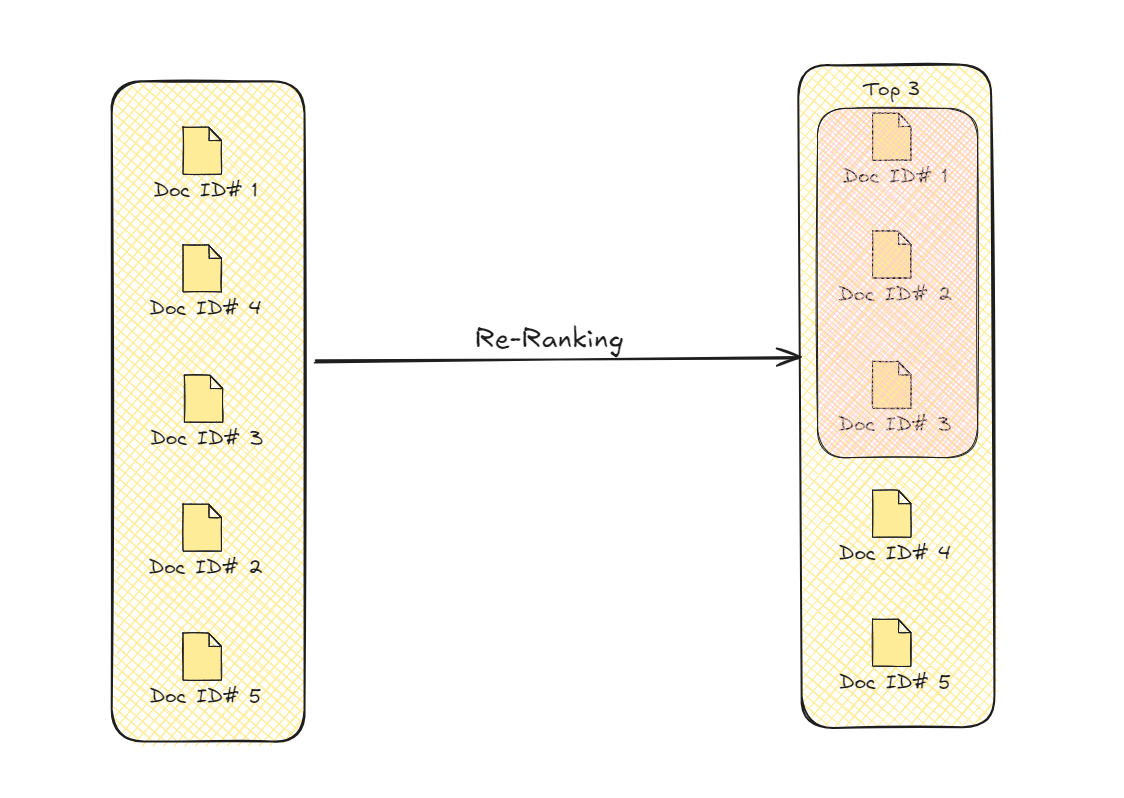
再ランキングにより、関連性の高い情報がトップに配置されます。これにより、生成される応答が正確であり、一貫性があり、ユーザーのニーズに直接対応していることが保証されます。このプロセスでは、意味的な関連性や文脈的な適切さなどのさまざまな基準を使用して情報を並べ替えます。この洗練により、最終的な応答はより焦点を絞り、精度が向上し、出力の全体的な品質が向上します。
# コンテキストの圧縮
関連するドキュメントをフィルタリングした後でも、再ランキングアルゴリズムを使用していても、フィルタリングされたドキュメント内にはユーザーのクエリに対して無関係なデータが含まれている場合があります。この余分なデータを削除するプロセスをコンテキストの圧縮と呼びます。このステップは、関連するドキュメントをLLMに渡す直前に適用され、LLMが最も関連性の高い情報のみを受け取るようにします。これにより、LLMは最も適切な結果を提供することができます。
# 利点
これらのアプローチの違いをよりよく理解するために、Advanced RAGがNaive RAGに比べて提供する具体的な利点を探ってみましょう。
- 再ランキングによるより高い関連性: 再ランキングにより、最も関連性の高い情報が最初に表示されるため、最終的な応答の正確性と流れが向上します。
- より良い文脈のためのダイナミック埋め込み: ダイナミック埋め込みは、特定のタスクにカスタマイズされており、さまざまなクエリに対してより正確に理解し、応答することができます。
- ハイブリッド検索によるより正確なリトリーバル: ハイブリッド検索は、複数の戦略を組み合わせてデータを効果的に検索するため、結果の関連性と精度が向上します。
- コンテキストの圧縮による効率的な応答: コンテキストの圧縮により、不要な詳細が削除され、プロセスが高速化され、焦点を絞った高品質な回答が得られます。
- より良いユーザークエリの理解: リトリーバル前にクエリを書き換え、拡張することで、Advanced RAGはユーザークエリを完全に理解し、より正確で関連性の高い結果を提供します。
Advanced RAGは、言語モデルによって生成される応答の品質を大幅に向上させる重要な進歩です。洗練されたフィルタリングや再ランキングなどの追加の処理ステップを追加することで、Naive RAGで見られる一貫性や関連性などの主要な問題に効果的に対処します。
# 比較分析:Naive RAG vs. Advanced RAG
Naive RAGとAdvanced RAGを比較することで、Advanced RAGがNaive RAGの基本的なフレームワークを拡張している様子がわかります。Advanced RAGは、精度、効率性、リトリーバルの全体的な品質を向上させるための主要な改善点を導入しています。
| 基準 | Naive RAG | Advanced RAG |
|---|---|---|
| 正確性と関連性 | 取得した情報を使用して基本的な正確性を提供します。 | 高度なフィルタリング、再ランキング、より良いコンテキストの使用により、正確性と関連性を向上させます。 |
| データのリトリーバル | 基本的な類似性チェックを使用し、関連するデータを見逃す可能性があります。 | ハイブリッド検索やダイナミック埋め込みなどの技術を使用してリトリーバルを最適化し、関連性と正確性の高いデータを確保します。 |
| クエリの最適化 | クエリを直接的な方法で処理し、ほとんど改善を行いません。 | クエリの書き換えやメタデータの追加などの方法を使用してクエリの処理を改善し、リトリーバルをより正確にします。 |
| スケーラビリティ | データサイズが増えると効率が低下し、リトリーバルに影響を与える可能性があります。 | 大規模なデータセットを効率的に処理できるように設計されており、インデックスやリトリーバルの方法を改善してパフォーマンスを維持します。 |
| マルチステージリトリーバル | リトリーバルを1回行い、重要なデータを見逃す可能性があります。 | 再ランキングやコンテキストの圧縮などのステップを含むマルチステージのプロセスを使用し、初期結果を洗練して最終的な出力が正確で関連性の高いものになるようにします。 |

# 結論
Naive RAGとAdvanced RAGの選択時には、アプリケーションの具体的なニーズを考慮してください。Naive RAGは、速度と直感的な実装が優先されるより単純なユースケースに適しています。深い文脈理解が重要ではないシナリオでLLMのパフォーマンスを向上させます。一方、Advanced RAGは、より複雑なアプリケーションに適しており、洗練されたフィルタリングや再ランキングなどの追加の処理ステップにより、正確性と一貫性が向上します。大規模なデータセットや複雑なクエリの処理にはAdvanced RAGが適しています。
MyScaleは、スケーラブルで効率的なリトリーバルソリューションを提供することで、これらの進歩をさらに高めています。洗練されたインデックス (opens new window)とデータ処理技術により、情報の取得速度と正確性が向上し、RAGシステムのパフォーマンスが向上します。MyScaleを活用することで、開発者はAdvanced RAGのメソッドを最適化し、AIシステムの改善と正確で関連性の高い情報の提供能力を向上させることができます。



