
以前のブログ記事 (opens new window)で説明したように、ベクトル検索は、従来のキーワードマッチングよりも洗練された文脈に基づいたアプローチで情報検索を大きく進化させています。テキストを数値ベクトルに変換することで、検索クエリの文脈的な意味をデータと一致させ、検索結果の関連性を向上させることができます。
しかし、ベクトル検索には情報の損失が生じる可能性などの課題もあり、検索の精度を向上させるために追加の手法を採用する必要があります。
では、これらの追加手法とは何でしょうか?
この質問の簡単な答えは、ベクトル検索を使用して情報を検索する際に、2段階の検索システムを実装することが最も重要な「追加手法」の一つであるということです。
ここでは、MyScaleを使用した2段階の検索手法の実装手順をステップバイステップで紹介し、ベクトル検索と再ランキングを組み合わせて情報検索システムを効率的かつ効果的に最適化する方法を説明します。
# 再ランキングとは?
しかし、まずは再ランキングを定義し、なぜそれが2段階の検索プロセスの一部となるのか考えてみましょう。
簡潔に言えば、再ランキングはベクトル検索の文脈的な関連性を高めるために検索結果を再度並べ替えることです。ウィクショナリー (opens new window)によれば、「何度も再度ランキングすること、または異なる方法でランキングすること...(例えば)アルゴリズムは最適な結果に到達するまで何度も再ランキングを行う」とあります。
再ランキングは、しばしばクロスエンコーダーモデル (opens new window)と組み合わせて実装され、より洗練された結果セットを提供します。初期のベクトル検索とは異なり、ドキュメントをベクトルにまとめてからクエリを行うのではなく、再ランキングはクエリとドキュメントを一緒に処理し、関連性に基づいて検索結果をより精確に並べ替えます。
ただし、すべてには課題があります。再ランキングの利用には高い計算要求と大規模なデータセットの処理時の実用性の制約など、最も重要な課題があります。
# 2段階の検索システム
これらの課題に対処するために、2段階の検索システムが開発されました。このシステムは、ベクトル検索と再ランキングの強みを組み合わせ、まず広範な結果セットを取得するためのベクトル検索を行い、その後再ランキングを選択的に適用してより高い精度を実現します。
# MyScaleの2段階の検索システム
MyScaleの2段階の検索システムは、まずベクトル検索を行い、データベースをスキャンして検索クエリの意味に密接に一致するドキュメントの広範な範囲を選択し、膨大なデータセットを関連するサブセットに効率的に縮小します。
次に: このサブセットは再ランキング関数を使用して洗練され、類似スコアに基づいて注意深くソートされ、最終的な結果セットをユーザーの意図にできるだけ近づけます。
この2段階の検索システムを効率化するために、これらの再ランキング関数 (opens new window)をMyScaleに統合しました。これにより、シンプルなSQLクエリを介してこれらの関数にアクセスできるようになります。
注意:
これらの関数は高度な再ランキングAPIを利用しており、複雑なデータのソート操作を簡単に利用できるインターフェースを提供し、堅牢な検索機能を簡潔で効率的なユーザーエクスペリエンスに凝縮しています。
次の図に示すように、ユーザーは簡単なコマンドでこの2段階の検索メカニズムを開始し、ベクトル検索のサブクエリを組み込んで上位Nのドキュメントを返し、再ランキングクエリを使用してこの結果セットを微調整し、最も関連性の高いKのドキュメントを抽出することができます。
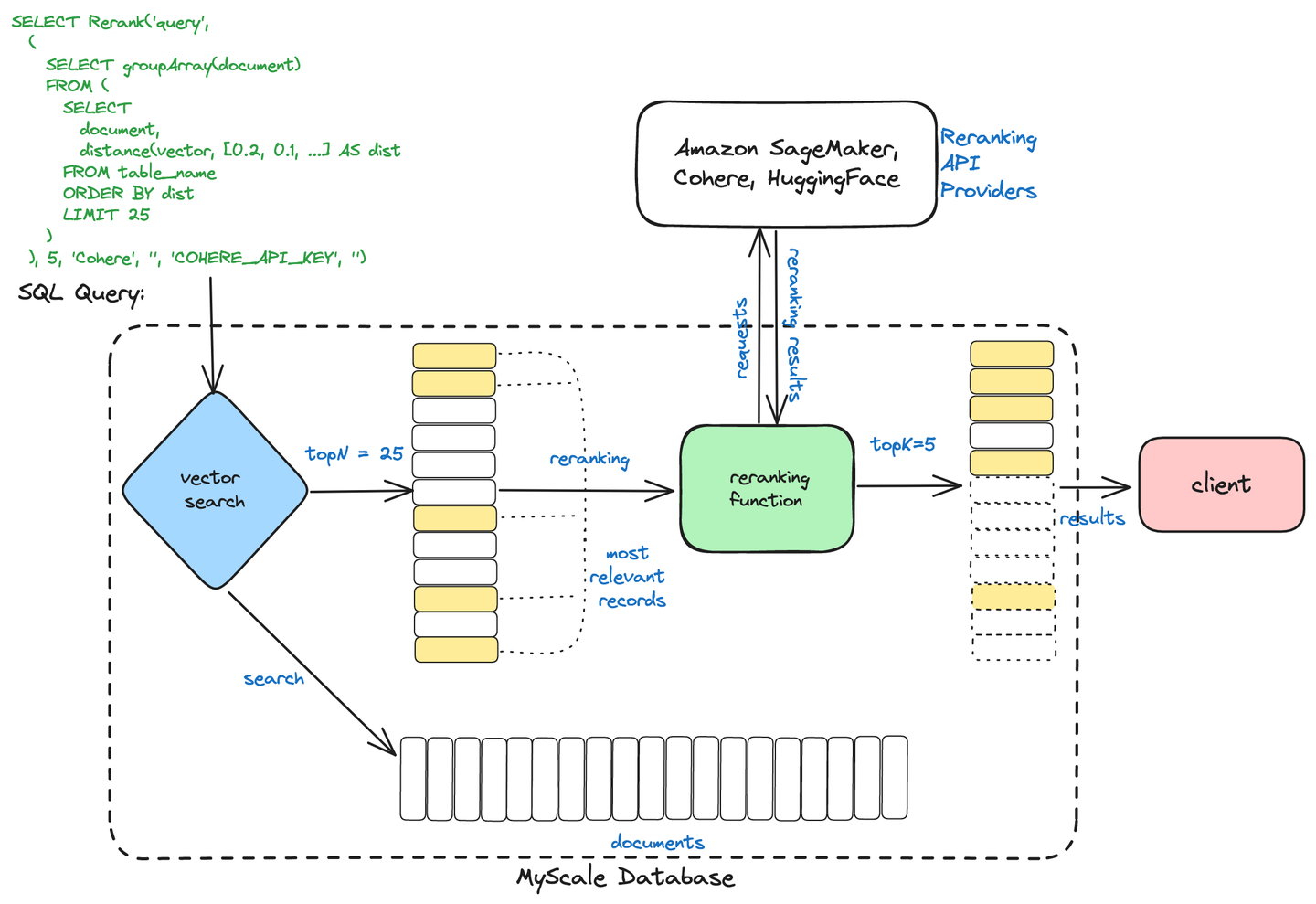
このシステムの効果は、パフォーマンスメトリクスで明らかです。OpenAI Embeddings (opens new window)を使用して分析した結果、検索の精度が大幅に向上しました。Hit Rateは0.854545から0.895455に向上し、MRR(Mean Reciprocal Rank)も0.640303から0.707652に上昇しました。これらの改善は、再ランキングを情報検索プロセスに統合することの価値を示しています。
注意:
評価方法と結果については、LlamaIndexのこのブログ (opens new window)で説明されている方法に従って、このnotebook (opens new window)で詳細に説明しています。
# MyScaleの2段階の検索システムの実装
では、実際の例を通じてMyScaleの2段階の検索システムをよりよく理解してみましょう。具体的には、MyScaleのドキュメントに記載されている抽象的なQA (opens new window)のサンプルアプリケーションを改善することに焦点を当てます。
注意:
必要な変更は、元の例のクエリフェーズ (opens new window)のみです。テーブルとデータは同じままです。
元の抽象的なQAアプリケーションでは、質問を別のリトリーバーを使用して埋め込みに変換し、検索クエリを実行して上位k個の候補を見つけます。次のSQLステートメントでは、MyScaleの埋め込み関数を使用して、これらの手順を1つのSQLコマンドに統合しています。
SELECT summary,
distance(
summary_feature,
CohereEmbedText('what is the difference between bitcoin and traditional money?')
) AS dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist LIMIT 10
このSQLステートメントでは、次のコードスニペットで定義されているカスタムの埋め込み関数CohereEmbedTextを使用しています。
CREATE FUNCTION CohereEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(
x,
'Cohere',
'',
'YOUR_COHERE_API_KEY',
'{"model":"embed-english-light-v3.0", "input_type":"search_query"}')
さらに、次のコードスニペットに示すように、再ランキング関数を導入してプロセスをさらに効率化します。詳細は関数のドキュメント (opens new window)を参照してください:
CREATE FUNCTION CohereRerank ON CLUSTER '{cluster}'
AS (x,y,z) -> Rerank(
x, y, z, 'Cohere', '', 'YOUR_COHERE_API_KEY', '');
これらの関数を使用して、次のSQLステートメントを使用して2段階の検索システムを実装できます:
SELECT
tupleElement(arrayElement, 2) AS summary,
tupleElement(arrayElement, 3) AS score
FROM (
SELECT arrayJoin(CohereRerank('what is the difference between bitcoin and traditional money?',
(SELECT groupArray(summary)
FROM (
SELECT summary, distance(summary_feature, CohereEmbedText('what is the difference between bitcoin and traditional money?')) as dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist
LIMIT 50
)
), 10
)) AS arrayElement
)
このSQLステートメントは、次の手順で2段階の検索システムを実装しています:
- 検索結果を10から50に拡張して、関連情報を見逃さないようにします。
- groupArray (opens new window)を使用して、上位50の候補を配列にグループ化し、再ランキングのために準備します。
CohereRerank関数を使用して関連性に基づいてこれらの候補を再度並べ替え、最も関連性の高い10の要約を抽出します。- arrayJoin (opens new window)(複数の行に展開するための)とtupleElement (opens new window)(結果行から指定された列を抽出するための)を使用して、結果を構造化してユーザーに表示しやすくします。

# 結論
MyScaleの2段階の検索システムは、現代の検索技術におけるシンプルさと効率性の力を具体的に示しています。ベクトル検索と高度な再ランキング関数を組み合わせたような複雑なプロセスでも、1つのシンプルなSQLクエリでシームレスに実行することができます。このアプローチにより、複雑な検索プロセスがより多くのユーザーにアクセス可能になるだけでなく、MyScaleが強力で使いやすいデータ検索および分析ツールを提供するということも強調されます。




