
この高度化RAGパイプラインシリーズでは、埋め込みモデル、インデックス作成手法、チャンク化技術などの他の要素が効率的なシステムの基盤をどのように構築するかについて説明してきました。今回は、このパイプラインの非常に重要な部分であるベクトル検索について探っていきます。
データベースの重要な能力は、その検索パフォーマンスにあります。ウェブ検索からオブジェクト識別まで、その応用範囲は広大であり、検索の効率性、多様性、正確性に大きく依存します。わずかに遅れたり不正確な(または限定的な)検索が、満足した顧客と二度と戻ってこない顧客の違いになることを、企業は十分認識しています。
ベクトル検索は、現代の検索システムにおいて不可欠です。セマンティック検索を実現し、取得されるデータがクエリと文脈的に一致することを保証します。ベクトル検索の基本的な考え方は、各項目を高次元ベクトルとして表現することです。このベクトルの各次元は項目の特徴や特性を表します。2つの項目間の類似性は、そのベクトル表現間の距離として測定されます。
# ベクトルインデックスの概要
インデックス作成は、ベクトル検索を支える重要な要素です。検索を高速、効率的、かつ有意義なものにするのがインデックス作成です。テーブルで検索を実行する前に、まずインデックスを作成する必要があります。このプロセスは、関連する結果を迅速に取得できるようデータを整理するものです。では、まず「インデックス (opens new window)」に注目しましょう。
インデックスを追加する際の考慮事項は以下の通りです:
- インデックスはベクトル列(
Array(Float32))またはテキスト列にのみ作成できます。 - ベクトル列に対しては、配列の最大長を事前に指定することが重要です。これにより、データ構造の一貫性が保たれ、インデックスが効率的に動作します。
- インデックスは主に類似性検索に使用されるため、インデックス作成時に類似性メトリックを定義する必要があります。例えば、「Cosine」類似性はベクトル比較の最も一般的なメトリックの一つです。
インデックスは効率的なベクトル検索の基盤であり、適切なデータを見つけるために必要な時間と計算負荷を大幅に削減します。適切なインデックス作成戦略を選び、これらの考慮事項を理解することで、システムの性能に大きな違いが生まれます。
# 例
MyScale (opens new window)でインデックスを追加するのは、SQLテーブルに追加するのと同様の手順です。以下は、テーブルを定義し、そこにベクトル列を追加する例です。
CREATE TABLE test_float_vector
(
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ENGINE = MergeTree
ORDER BY id
ご覧の通り、インデックスを追加する前に必要な最大長制約を追加しています。
ALTER TABLE default.test_float_vector
ADD VECTOR INDEX data_index data
TYPE MSTG ('metric_type=Cosine');
そして、伝統的なリレーショナルデータベースクエリのために使用するSQLと同じSQLを使用して、検索用語(「Levinが農民の問題に提案した解決策は何でしたか?」)に最も関連するドキュメントを取得できます。この検索フレーズは、まず埋め込みに変換する必要があります。これには、任意の埋め込みモデルまたはサービスを使用できます。埋め込み(input_embedding)を取得した後、そのクエリに最も関連するドキュメントを取得します。

注記:
MyScaleはEMBEDTEXT()関数も提供しており、直接使用可能です。Python(またはその他)のインターフェースやSQLで使用できます。
# インデックス作成アルゴリズム
上記の構文はユニークではありませんが、ベクトルインデックス作成 (opens new window)はバックエンドで少し異なる動作をします。通常、クラスタリングを利用し、その後に高速なトラバースのためにグラフやベクトルのツリーを使用します。適切なインデックス作成アルゴリズムを選択することは検索効率における重要な要素となります。以下は一般的なインデックス作成アルゴリズムの例です:
局所感度ハッシング(LSH): Locality-Sensitive Hashing(LSH)は、特殊なハッシュ関数を使用して類似するデータポイントを同じバケットにグループ化します。このプロセスにより、近い位置にある埋め込みやベクトルが同じハッシュテーブル内で衝突する可能性が高くなります。これにより高次元空間での検索が高速化され、近似最近傍タスクに最適です。
インバーテッドファイル(IVF) (opens new window): インバーテッドファイルインデックス(IVF)は、ベクトルをグループにクラスタリングすることで機能します。クエリベクトルが提供されると、システムはすべてのクラスタの中心点との距離を計算します。そして、クエリに最も近いクラスタ内を検索します。ただし、この検索はクラスタ中心に依存しているため(k近傍法に類似)、他のクラスタ内の近いベクトルが見逃される可能性があります。また、より良い結果を得るために複数のクラスタを検索する必要がある場合もあります。
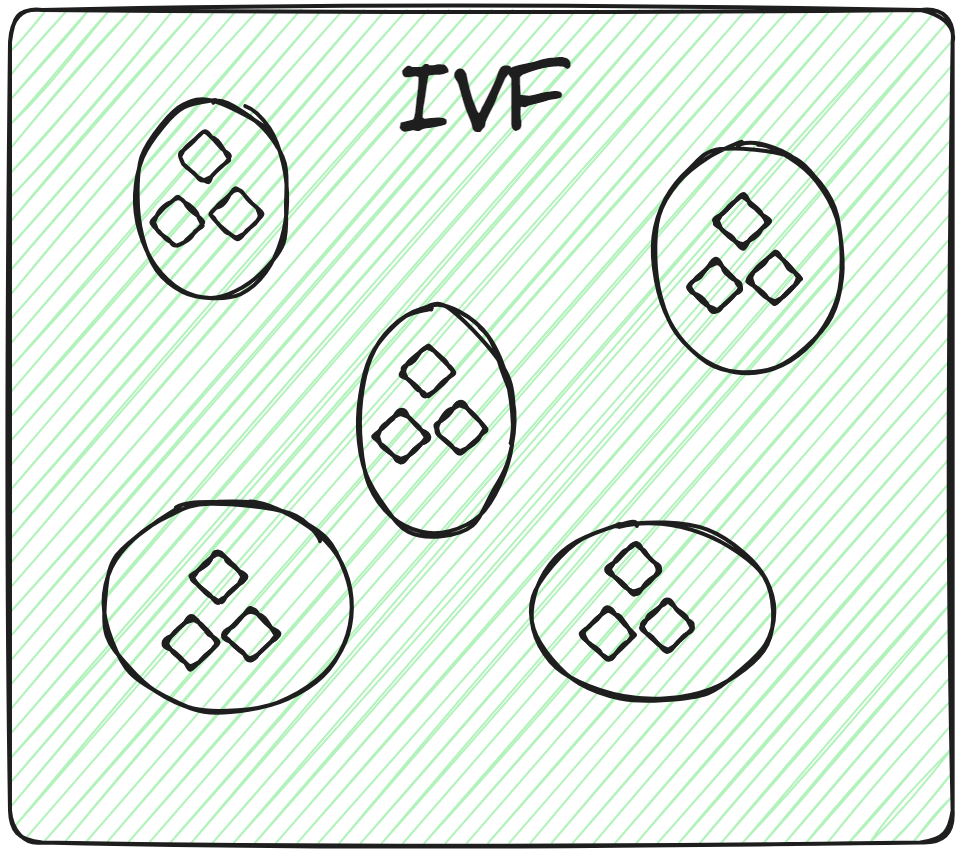
IVFには、IVF-Flat (opens new window)やIVF-PQ (opens new window)などのさまざまなバリエーションがあり、パフォーマンスやストレージにおけるトレードオフを提供します。
注記:
ベクトルデータベースが数百万のベクトルで急速に拡大する文脈では、適切なインデックス作成アルゴリズムを選択することがますます重要になります。1秒でも節約できれば、その価値は計り知れません。
- 階層的ナビゲート可能小世界(HNSW) (opens new window): HNSWは、階層的なグラフを構築することで機能します。これにより、ノードを検索する必要がある数を減らすことができ、高速化が可能になります。しかし、新しいベクトルを追加するたびに新しいグラフを作成するのは時間がかかります。
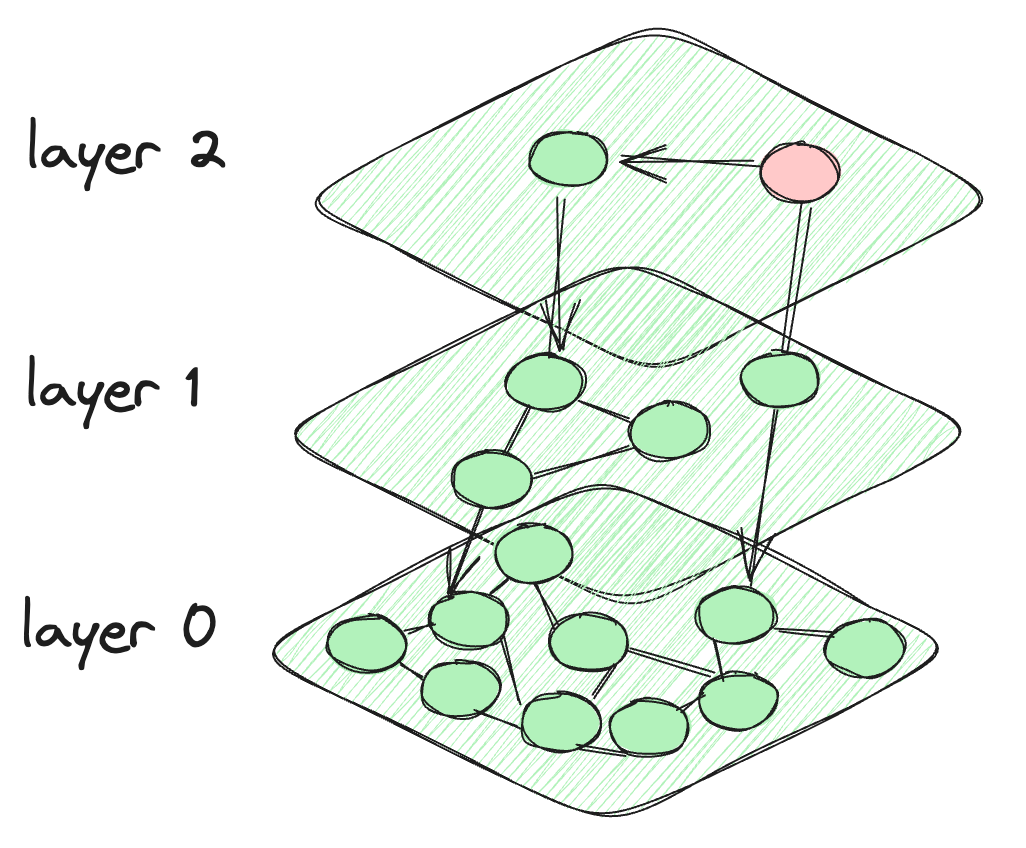
- マルチスケールツリーグラフ(MSTG) (opens new window): HNSWやIVFは非常に優れていますが、大規模データセットにスケールするとパフォーマンスの問題が生じます。グラフ検索は初期の収束に優れていますが、フィルタ検索では苦労する傾向があります。一方で、ツリー検索はフィルタ検索に適していますが遅いです。MSTGは階層グラフとツリーを組み合わせることで、両者の利点を活用します。
以下は、将来の(迅速な)参照のための要約表です:
| 番号 | アルゴリズム | 強み | 改善点 | 適した用途 |
|---|---|---|---|---|
| 1 | LSH | 高次元データ; 並列化サポート | メモリ使用量が多い; 遅い | 高次元のスパースデータ |
| 2 | IVF | 小規模および中規模データに適している | 近接クラスタが欠落する可能性; | 明確なクラスタを持つデータセット |
| 3 | HNSW | 高速 | 新しいエントリの追加時にリソース集約的; スケーラビリティ | 汎用的 |
| 4 | MSTG | 高速; スケーラブル; 高精度 | 新しいアルゴリズムのため成熟度が低い | 汎用的 |
# 基本的なベクトル検索
ベクトル検索は、高度なデータ検索技術であり、単純なテキストマッチングではなく、検索クエリとデータエントリの文脈的な意味の一致に焦点を当てています。この技術を実装するには、まず検索クエリとデータセットの特定の列の両方を数値表現、つまりベクトル埋め込みに変換する必要があります。
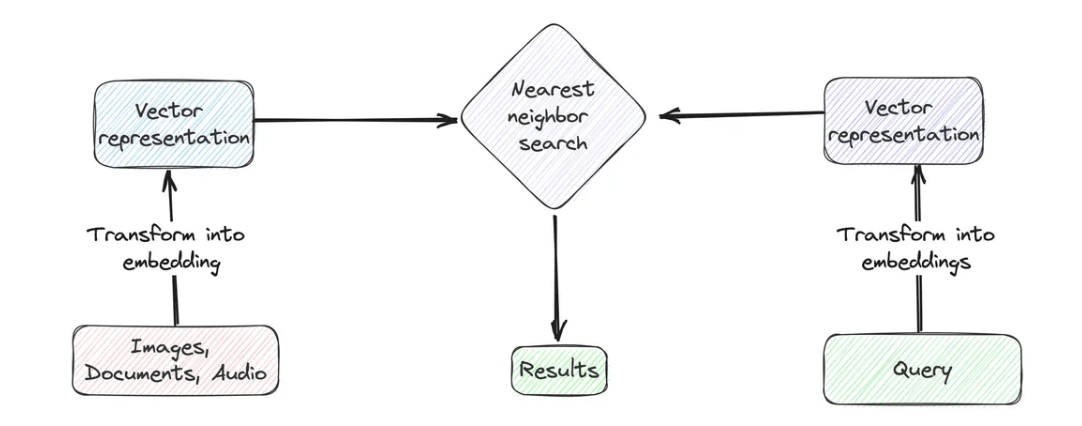
次に、クエリベクトルとデータベース内のベクトル埋め込み間の距離(コサイン類似性またはユークリッド距離)を計算します。その後、これらの計算された距離に基づいて、最も近いまたは最も類似するエントリを特定します。最後に、クエリベクトルに対する距離が最小のトップk件の結果を返します。
注記:
セマンティック検索は、ベクトル検索の基本定義に基づき、テキストの正確な用語ではなくその意味に基づいてより関連性の高い結果を返します。ただし、実際にはベクトル検索とセマンティック検索はしばしば同義で使用されます。
# フルテキスト検索
従来のSQL検索や正規表現は、特定の用語や特定のパターンを比較するだけで非常に限定されています。以下の例でその制約を示します。「ヴィーガンのための感謝祭」に関連するドキュメントを検索するためのSQL構文を使用しています。
| AND条件 | OR条件 |
|---|---|
SELECT
id,
title,
body
FROM
default.en_wiki_abstract
WHERE
body LIKE '%Thanksgiving%'
AND body LIKE '%vegans%'
ORDER BY
id
LIMIT
4;
| SELECT
id,
title,
body
FROM
default.en_wiki_abstract
WHERE
body LIKE '%Thanksgiving%'
OR body LIKE '%vegans%'
ORDER BY
id
LIMIT
4;
|
AND条件を適用すると結果は得られませんが、OR条件を使用すると、「Thanksgiving」または「vegans」のいずれかを含むドキュメントが取得されます。このアプローチは結果を取得しますが、すべてのドキュメントが両方の用語に関連性が高いとは限りません。

# 従来のSQL検索の制限
従来のSQL検索は非常に厳格で、セマンティックな類似性や表現の違いを考慮しません。例えば、SQLは「doctor applying anesthesia」と「doctor apply anesthesia」を完全に異なるフレーズとして扱うため、類似した一致が見落とされることがよくあります。
# フルテキスト検索の改善点
前者の場合は正確なフレーズに基づいて検索を行い、後者ではキーワードを使用して検索を実施します。フルテキスト検索は両方の方法をサポートしており、ユーザーの好みに基づいた柔軟性を提供します。厳格な従来のSQL検索とは異なり、フルテキスト検索はテキスト内の多少のばらつきを許容します。
# 動作の仕組み
フルテキスト検索のインデックス作成は以下の手順で行われます。
- トークン化 (Tokenization): テキストを小さな部分に分解します。単語トークン化ではテキストを「単語」に分割し、文トークン化では「文」に、文字トークン化では「文字」に分割します。
- レンマ化/ステミング (Lemmatization/Stemming): 単語をその「基本形」に分解します。例えば、「playing」は「play」に、「children」は「child」に変換されます。
- ストップワードの除去 (Stopwords Removal): 記事や前置詞などの情報量が少ない単語を除去します。デフォルトの「English」ストップワードフィルターは、記事や前置詞だけでなく、「when」「ourselves」「my」「doesn’t」「not」などの単語も削除します。
- インデックス作成 (Indexing): 前処理が完了したテキストを逆インデックスに保存します。
インデックス作成が完了すると、検索が適用できます。
スコアリングとランキング:BM25 (Best Match 25)
BM25は非常によく使用されるアルゴリズムで、ベクトル検索が埋め込み(または任意の一般的なベクトル)の類似性をランク付けする方法に似ています。BM25はTF-IDFの改良版であり、以下の3つの要素に依存します:
- 単語頻度(Term Frequency)
- 逆文書頻度(Inverse Document Frequency - 希少な単語を評価)
- 文書長の正規化(Document Length Normalization)
# 例
フルテキスト検索インデックスは、ftsタイプを指定することで簡単に追加できます。レンマ化またはステミングを選択するか、ストップワードフィルターを選択するかも指定可能です。
ALTER TABLE default.en_wiki_abstract
ADD INDEX body_idx body
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
クエリとの類似性に基づいて文書やテキストサンプルがランク付けされます。
SELECT
id,
title,
body,
TextSearch(body, 'thanksgiving for vegans') AS score
FROM default.en_wiki_abstract
ORDER BY score DESC
LIMIT 5;

# ハイブリッド検索
フルテキスト検索は一定の柔軟性を提供しますが、セマンティックに類似したテキストを見つける能力には限界があります。そのため、テキストの深い意味を捉える埋め込みに依存する必要があります。一方、フルテキスト検索には基本的なキーワード検索やテキスト一致に優れているという独自の利点があります。
一方で、埋め込みによるベクトル検索は、文書間のセマンティックマッチングや意味の深い理解において非常に優れています。しかし、短いテキストクエリの場合は効率が低下する可能性があります。
これら両方の利点を活用するために、ハイブリッド検索アプローチを採用できます。フルテキスト検索とベクトル検索を統合することで、より包括的で強力な検索体験を提供します。ユーザーはキーワードベースの検索の精度と埋め込みによる深いセマンティック理解の両方を享受することができ、幅広いユーザーのニーズやクエリタイプに対応することが可能になります。
# 例
さらに具体的に説明するために、例を使用します。同じwiki_abstract_miniテーブルを使用し、比較を容易にします。bodyにフルテキスト検索インデックスを追加し、対応する埋め込みにはベクトルインデックスを補完します。
ALTER TABLE default.wiki_abstract_mini
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
# ベクトルインデックスを作成
ALTER TABLE default.wiki_abstract_mini
ADD VECTOR INDEX body_vec_idx body_vector
TYPE MSTG('metric_type=Cosine');
ベクトル検索はテキストではなく埋め込みに直接適用されるため、ここではHugging Face経由でE5 Largeモデルを使用します。関数を作成することで、必要に応じて直接呼び出せるようになります。
CREATE FUNCTION EmbeddingE5Large
ON CLUSTER '{cluster}' AS (x) -> EmbedText (
concat('query: ', x),
'HuggingFace',
'https://api-inference.huggingface.co/models/intfloat/multilingual-e5-large',
'hf_xxxx',
''
);
# ハイブリッド検索関数
HybridSearch()関数は、ベクトル検索とテキスト検索の利点を組み合わせた検索方法です。このアプローチにより、長いテキストのセマンティックな理解が強化されるだけでなく、短いテキストにおけるベクトル検索のセマンティックな課題も克服します。
SELECT
id,
title,
body,
HybridSearch('fusion_type=RSF', 'fusion_weight=0.6')(body_vector, body, EmbeddingE5Large('Charted by the BGLE'), ' BGLE') AS score
FROM default.wiki_abstract_mini
ORDER BY score DESC
LIMIT 5;

# マルチモーダル検索
ハイブリッド検索はフルテキスト検索とベクトル検索を組み合わせたものです。一方で、マルチモーダル検索はさらに進化した手法で、画像、動画、音声、テキストなど、異なる種類のデータを対象に検索を行うことを可能にします。
この概念はコントラスト学習 (opens new window)に基づいており、マルチモーダル検索は以下のようなシンプルなメカニズムで動作します:
- CLIP(Contrastive Language–Image Pretraining) (opens new window)のような統一モデルが、画像やテキストなどのさまざまなデータタイプを処理し、それらを埋め込みに変換します。
- これらの埋め込みは単一の共有ベクトル空間にマッピングされ、異なるデータタイプ間で比較可能になります。
- データの元の形式に関係なく、クエリの埋め込みに最も近い埋め込みが返されます。
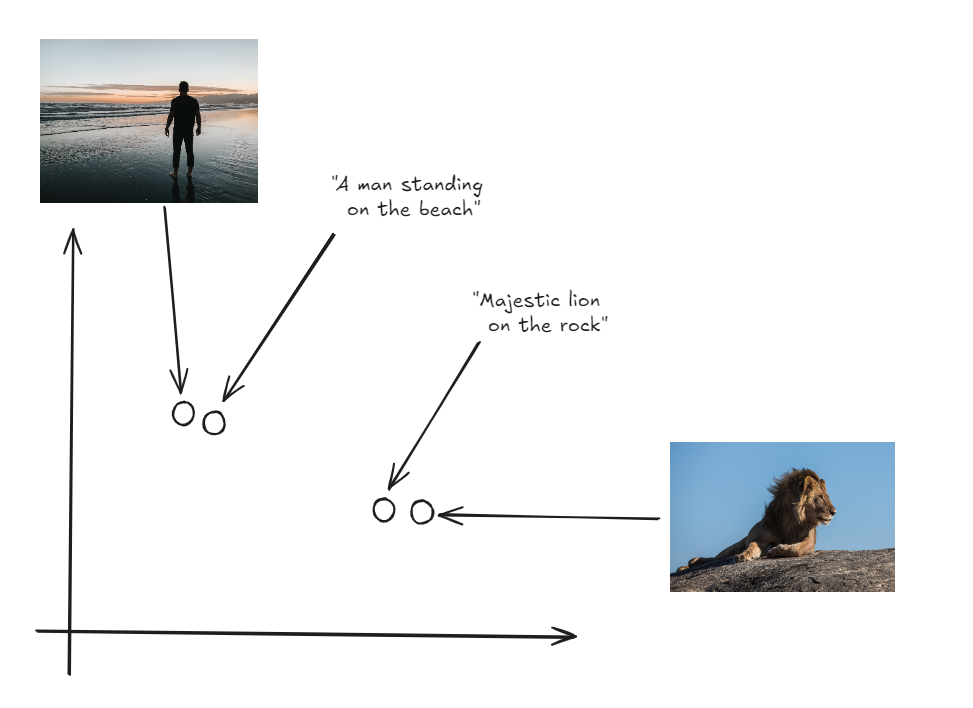
このアプローチにより、画像、テキスト、音声、動画など、単一のクエリに基づいて多様で関連性の高い結果を取得できます。例えば、テキスト説明を提供して画像を検索 (opens new window)したり、音声クリップを使用して動画を見つけたりすることができます。
すべてのデータタイプを単一のベクトル空間に整列させることで、異なるモデルからの結果を統合する必要がなくなります。これにより、ベクトルデータベースがどれほど強力で柔軟であるかを示し、さまざまなデータソースからシームレスにデータを取得できるようになります。
# 結論
ベクトルデータベースは、データの保存方法に革命をもたらしました。高速性を向上させるだけでなく、人工知能やビッグデータ分析など、さまざまな分野での活用が可能です。この技術の中核を成すのは、検索機能です。
MyScaleは、ベクトル検索 (opens new window)、フルテキスト検索 (opens new window)、ハイブリッド検索 (opens new window)という3種類の検索を提供しています。インデックスアルゴリズムを網羅し、これらの多様な検索機能を提供することで、MyScaleはさまざまなドメインやユースケースにおけるデータ取得の課題に対応する力をユーザーに与えます。本記事で紹介した例が、これらの検索機能を理解し、効果的に活用するための参考になれば幸いです。



