
大規模データベースのクエリの効率を向上させるためのデータベース最適化技術を探しているソフトウェア開発者として想像してみてください。従来のSQLデータベースでは、「B-Treeインデックス」や単に「インデックス」といったキーワードを使用して関連するブログや記事を見つけるかもしれません。しかし、このキーワードベースのアプローチでは、「SQLチューニング」や「インデックス戦略」といった異なるが関連するフレーズを使用する重要なブログや記事を見落とす可能性があります。
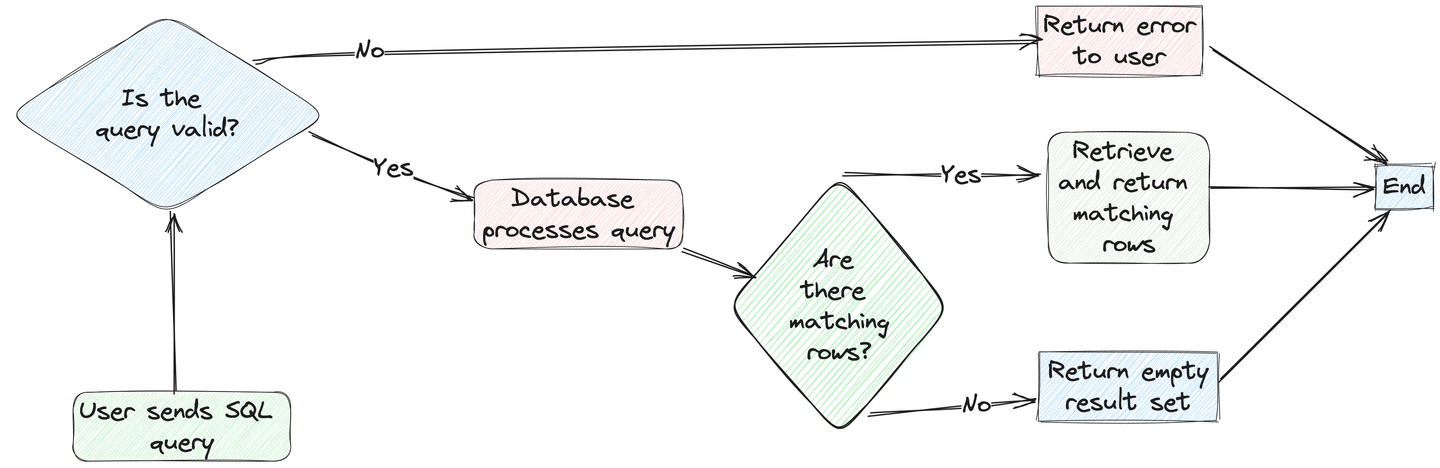
別のシナリオを考えてみましょう。特定の技術の正確な名前はわからないが、文脈は把握している場合です。従来のデータベースは正確なキーワードの一致に依存しているため、文脈だけで検索することはできません。
そのため、単純なキーワードの一致を超えて、意味的な類似性に基づいて結果を提供する検索技術が必要です。それがベクトル検索の役割です。従来のキーワードの一致技術とは異なり、ベクトル検索はクエリの意味をデータベースのエントリと比較し、より関連性の高い正確な結果を返します。
このブログでは、ベクトル検索に関連するすべての内容について説明し、基本的な概念からより高度な技術に移っていきます。まずは、ベクトル検索の概要から始めましょう。
# ベクトル検索の概要
ベクトル検索は、テキストの単純な一致ではなく、検索クエリとデータエントリの文脈的な意味を一致させる高度なデータ検索技術です。この技術を実装するためには、まず検索クエリとデータセットの特定の列を数値表現(ベクトル埋め込み)に変換する必要があります。次に、クエリベクトルとデータベース内のベクトル埋め込みとの距離(コサイン類似度またはユークリッド距離)を計算します。そして、これらの計算された距離に基づいて、最も近いまたは最も類似したエントリを特定します。最後に、クエリベクトルに対して最も距離の小さい上位k個の結果を返します。
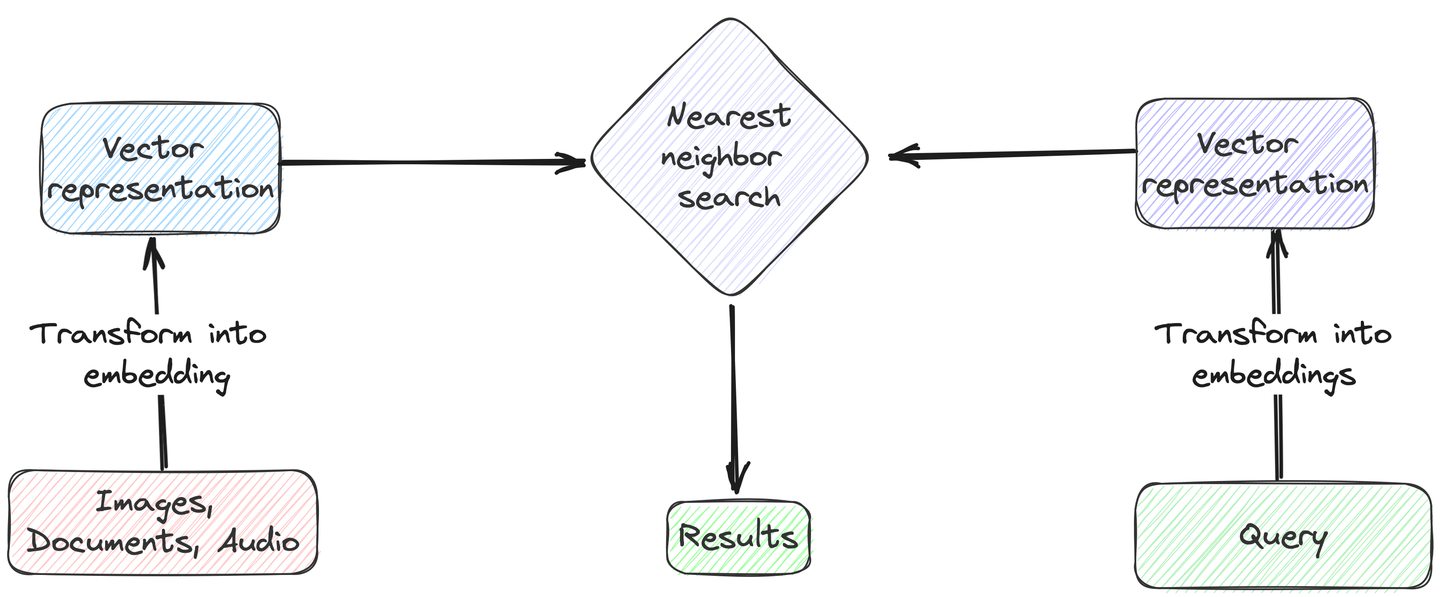
# ベクトル検索の典型的なシナリオ
- 類似性検索: 与えられたベクトルに類似した特徴空間内の他のベクトルを検索するために使用され、画像、音声、テキスト分析などのさまざまな分野で広く応用されています。
- レコメンデーションシステム: ユーザーとアイテム(映画、製品、音楽など)のベクトル表現を分析することで、個別のレコメンデーションを実現します。
- 自然言語処理: テキストデータの意味的な類似性を検索し、意味的な検索と関連性分析をサポートします。
- 質問応答(QA)システム: 入力質問に最も類似したベクトル表現を持つ関連するパッセージを検索します。最終的な回答は、質問と取得したパッセージに基づいた大規模言語モデル(LLM)によって生成されます。
ブルートフォースのベクトル検索は、データセットが小さい場合やクエリが単純な場合には非常に効果的です。しかし、データセットが大きくなるか、クエリが複雑になると、パフォーマンスが低下し、いくつかの欠点が生じます。
# ベクトル検索の実装上の課題
データセットのサイズが増加すると、単純なベクトル検索の使用に関連するいくつかの問題が生じます。具体的には次のような課題があります。
- パフォーマンス: 上記で説明したように、ブルートフォースのベクトル検索は、クエリベクトルとデータベース内のすべてのベクトルとの距離を計算します。小規模なデータセットではうまく機能しますが、ベクトルの数が数百万に増えると、数百万のエントリ間の距離を計算するための検索時間と計算コストが増加します。
- スケーラビリティ: データは現在指数関数的に増加しており、ブルートフォースのベクトル検索では大規模なデータセットをクエリする際に同じ速度と精度で結果を得ることは非常に困難です。これには、大量のデータを管理しながら同じ速度と精度を維持するための革新的な方法が必要です。
- 構造化データとの統合: 単純なアプリケーションでは、構造化データのクエリにはSQLクエリが使用され、非構造化データのクエリにはベクトル検索が使用されますが、アプリケーションではしばしば両方の機能が必要です。これらを統合することは技術的に難しい場合があります。ベクトル検索を利用し、同時にSQLのWHERE句をフィルタリングに適用する場合、データの種類とサイズの増加により、クエリ処理時間が増加します。
これらの課題に対する解決策として、効率的なベクトルインデックス技術が利用可能です。
# 一般的なベクトルインデックス技術
大規模なベクトルデータの課題に対処するために、効率的な近似ベクトル検索を実現するためのさまざまなインデックス技術が使用されています。いくつかの技術について見ていきましょう。
# 階層的ナビゲーション可能小世界(HSNW)
HNSWアルゴリズムは、マルチレイヤーグラフ構造を活用してベクトルを格納し、効率的に検索するためのアルゴリズムです。各レイヤーでは、ベクトルは同じレイヤーの他のベクトルだけでなく、下位のレイヤーのベクトルとも接続されます。この構造により、近くのベクトルを効率的に探索することができます。上位のレイヤーには少数のノードが含まれており、階層を下るにつれてノードの数が指数関数的に増加します。最下層にはデータベース内のすべてのデータポイントが含まれます。この階層的な設計がHNSWアルゴリズムの特徴的なアーキテクチャを定義しています。
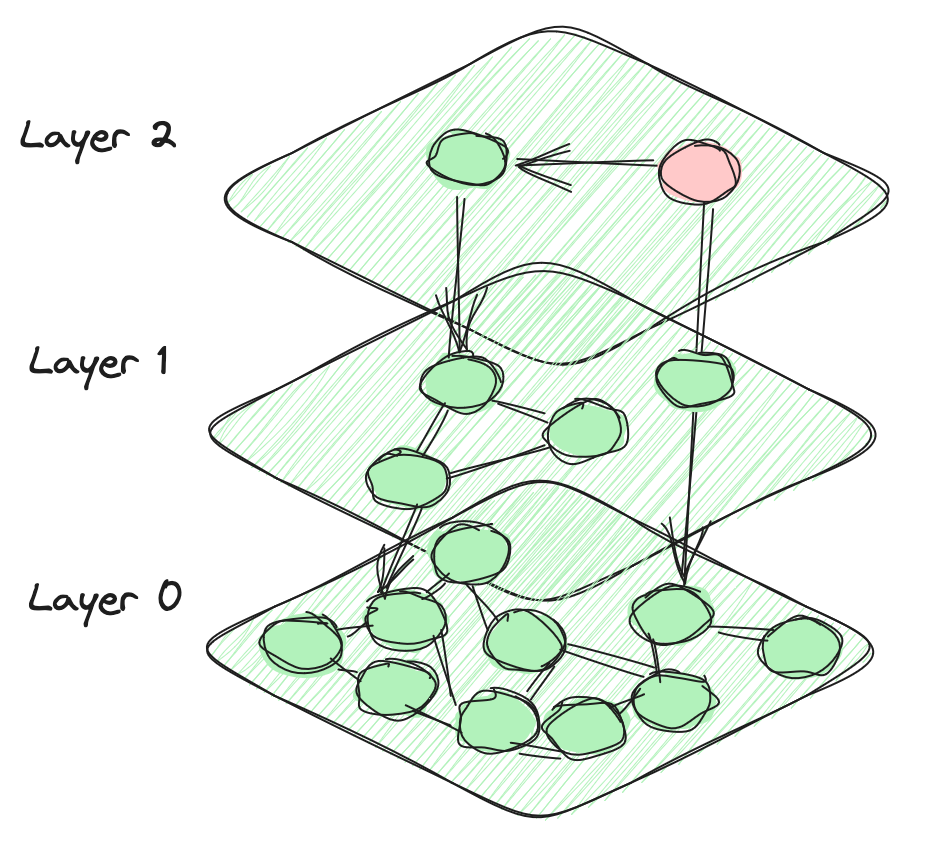
検索プロセスは、選択されたベクトルから始まり、現在の位置に最も近いベクトルに対して、現在のレイヤーと前のレイヤーの接続されたベクトルとの距離を計算します。この方法は貪欲であり、常に現在の位置に最も近いベクトルに進みながら繰り返し処理を行い、接続されたベクトルの中で最も近いベクトルを特定します。HNSWインデックスは通常、単純なベクトル検索に優れていますが、構築にはかなりのリソースと時間が必要です。また、これらの条件下では、グラフの接続性が低下するため、フィルタリングされた検索の精度と効率性が大幅に低下することがあります。
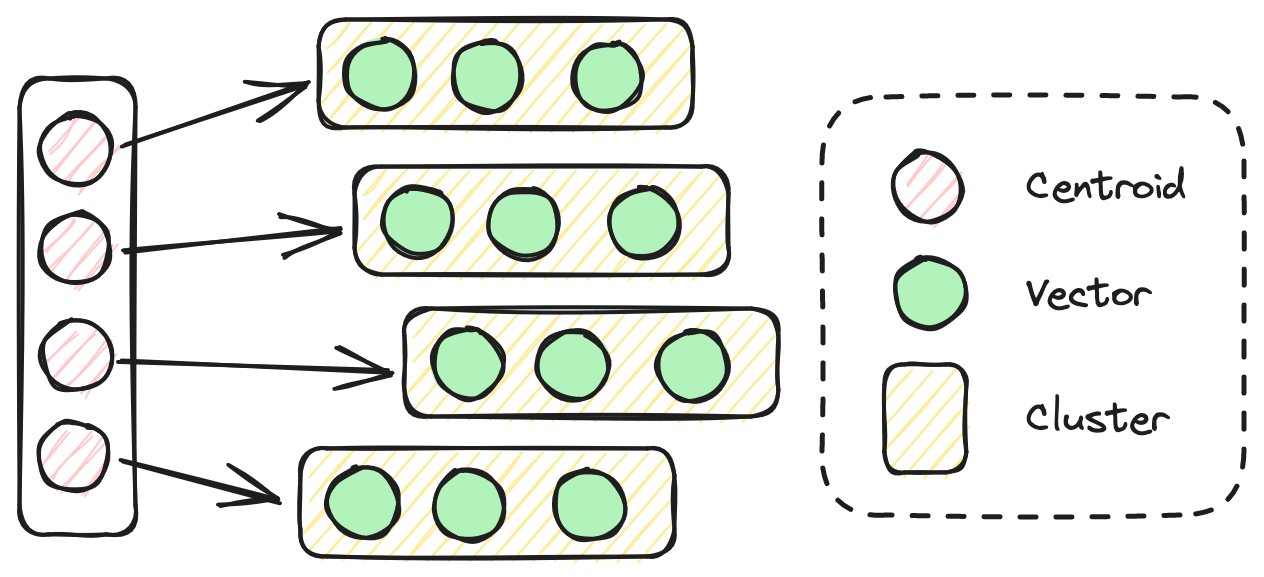
# 逆ベクトルファイル(IVF)インデックス
IVFインデックスは、クラスタのセントロイドを逆インデックスとして使用することで、高次元データの効率的な検索を実現します。ベクトルは幾何学的な近接性に基づいてクラスタに分割され、各クラスタのセントロイドが簡略化された表現として使用されます。クエリベクトルに最も類似したアイテムを検索する場合、アルゴリズムはまずクエリに最も近いセントロイドを特定します。次に、セントロイドに関連するベクトルのリスト内でのみ検索を行います。IVFはHNSWと比較して構築には時間がかかりませんが、検索プロセスでは精度と速度が低下します。


# MyScaleの活用:ソリューションと実際の応用
SQLベクトルデータベースであるMyScale (opens new window)は、複雑なクエリを処理し、高速なデータの取得、効率的な大量データの格納を可能にするよう設計されています。専門のベクトルデータベースを凌駕する (opens new window)理由は、ClickHouseに基づく高速なSQL実行エンジンと独自のマルチスケールツリーグラフ(MSTG)アルゴリズムを組み合わせているからです。MSTGはツリーとグラフベースのアルゴリズムの利点を組み合わせ、MyScaleが高速にビルドし、高速に検索し、異なるフィルタリング検索比率で速度と精度を維持することを可能にします。
では、MyScaleが非常に役立ついくつかの実際の応用を見てみましょう。
- 知識ベースのQAアプリケーション: QAシステムを開発する際には、MyScaleは自己クエリと柔軟なフィルタリングにより、ドキュメントから高度に関連性の高い結果を簡単に取得できる理想的なベクトルデータベースです。さらに、MyScaleはスケーラビリティに優れており、複数のユーザーを同時に簡単に管理できます。詳細については、抽象的なQA (opens new window)のドキュメントを参照してください。また、高度なアルゴリズムを使用して自己クエリを利用することで、検索結果の精度と速度を向上させることができます。
- 大規模AIチャットボット: 大規模なチャットボットを開発することは困難な課題です。特に、多数のユーザーを同時に管理し、それらを個別に処理する必要があります。さらに、チャットボットは正確な回答を提供する必要があります。MyScaleは、SQL互換のロールベースのアクセス制御 (opens new window)と大規模なマルチテナンシー (opens new window)を通じて、チャットボットの構築を簡素化しています。これにより、複数のユーザーを管理することができます。
- 画像検索: セマンティックまたは類似画像検索を実行するシステムを作成している場合、MyScaleは成長する画像データを簡単に処理し、パフォーマンスとリソース効率を維持します。また、メタデータや視覚的なコンテンツに基づいて画像をマッチングするために、より複雑なSQLクエリやベクトル結合クエリを書くこともできます。詳細な情報については、画像検索プロジェクト (opens new window)のドキュメントを参照してください。
これらの実際の応用に加えて、MyScaleのSQLとベクトルの機能を組み合わせることで、レコメンデーションシステム (opens new window)、オブジェクト検出アプリケーション (opens new window)など、さまざまな応用を開発することができます。
# 結論
ベクトル検索は、ベクトル埋め込み内の意味を解釈することにより、従来の用語の一致を超えます。このアプローチは、テキストだけでなく、画像、音声、さまざまなマルチモーダルな非構造化データにも適用されます。しかし、この技術は計算とストレージの要件、高次元ベクトルの意味的な曖昧さなどの課題に直面しています。MyScaleは、SQLとベクトル検索を革新的に統合した統一された高性能で費用効果の高いシステムによってこれらの問題を解決します。この統合により、QAシステムからAIチャットボット、画像検索まで、さまざまなアプリケーションが可能になり、その汎用性と効率性が示されます。
最後に、Twitter (opens new window)とDiscord (opens new window)で私たちとつながってください。あなたの洞察を聞いて議論することが大好きです。



