
ベクトルデータベースは、数十億のレコードの中に格納された類似したオブジェクトの高速な検索を提供します。しかし、特定の条件に一致する関連オブジェクトを検索することにも興味があるかもしれません。これをフィルタリングされたベクトル検索と呼びます。MyScale (opens new window)の助けを借りれば、フィルタリングされたベクトル検索を新たなレベルに引き上げることができます。
ほとんどのベクトルインデックスやベクトルストアは、専用のインデックスサービスとして機能します。これらはMongoDB のクエリとプロジェクション演算子 (opens new window)の一部をサポートしており、条件の辞書を入力することができます。
サポートされるデータ型や比較演算子は実装によって異なりますが、ほとんどのインターフェースでは文字列、等しい整数、基本的な値の比較のみをサポートしています。これらのベクトルインデックスは、データベースとは異なり、複雑なデータ型や条件を扱うために設計されていません。そのため、このデータを格納するための外部のデータベースソリューションが必要ですが、このデータを使用してフィルタリングされたベクトル検索を実行することはできません。この解決策は機能しますが、複雑で制限があります。
実際には、より良い解決策が存在し、存在すべきです。ベクトル検索はデータベースと統合することで、現在よりも堅牢になることができます。MyScale は、標準のWHERE句を使用して、複雑な条件とデータ型を持つフィルタリングされたベクトル検索を同時に処理することができます。
# プリフィルタリングとポストフィルタリング
フィルタリングされたベクトル検索の実装は、次の 2 つのタイプに分類されます。
- プリフィルタリングされたベクトル検索
- ポストフィルタリングされたベクトル検索
例えば:
ユーザーJack、Jan、John のチャット履歴を含むテーブルがあり、フィルタリングされたベクトル検索クエリを使用して、与えられたクエリベクトルに類似した Jack のチャット履歴を取得したいとします。
注意:
各レコードにはユーザーマークと特徴ベクトルがあります。簡単のため、ベクトルを数値に変換します。
以下の画像は、NoSQL と SQL のクエリが Jack のチャット履歴を取得する方法を示しています。
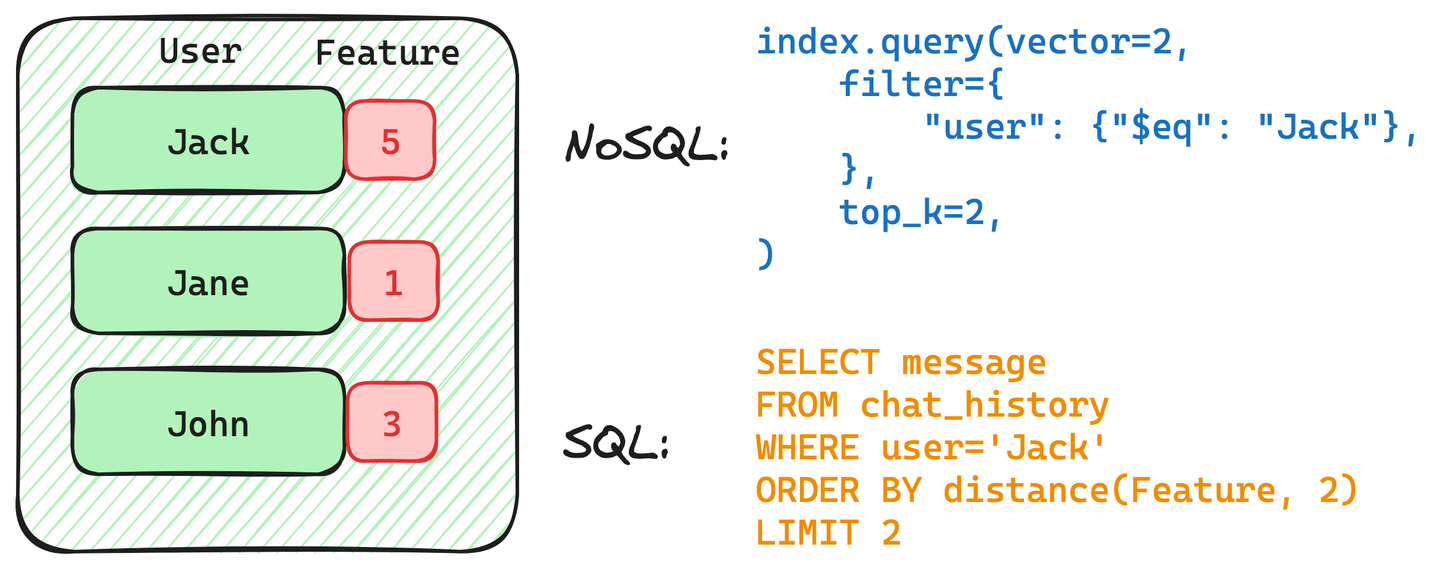
これらのクエリの両方には、ユーザーJack に対するフィルターが含まれています。ただし、このフィルターは実装によって異なる構造になる場合があります。
1. プリフィルタリングされたベクトル検索: プリフィルタリングされたベクトル検索では、エンジンはまずデータをスキャンし、与えられたフィルター条件に一致するレコードのみを保持します。このスキャンが完了すると、エンジンはプリフィルタリングされた候補に対してベクトル検索を実行します。
2. ポストフィルタリングされたベクトル検索: 一方、ポストフィルタリングされたベクトル検索では、まずベクトル検索を実行し、その結果を与えられたフィルター条件に基づいてフィルタリングします。
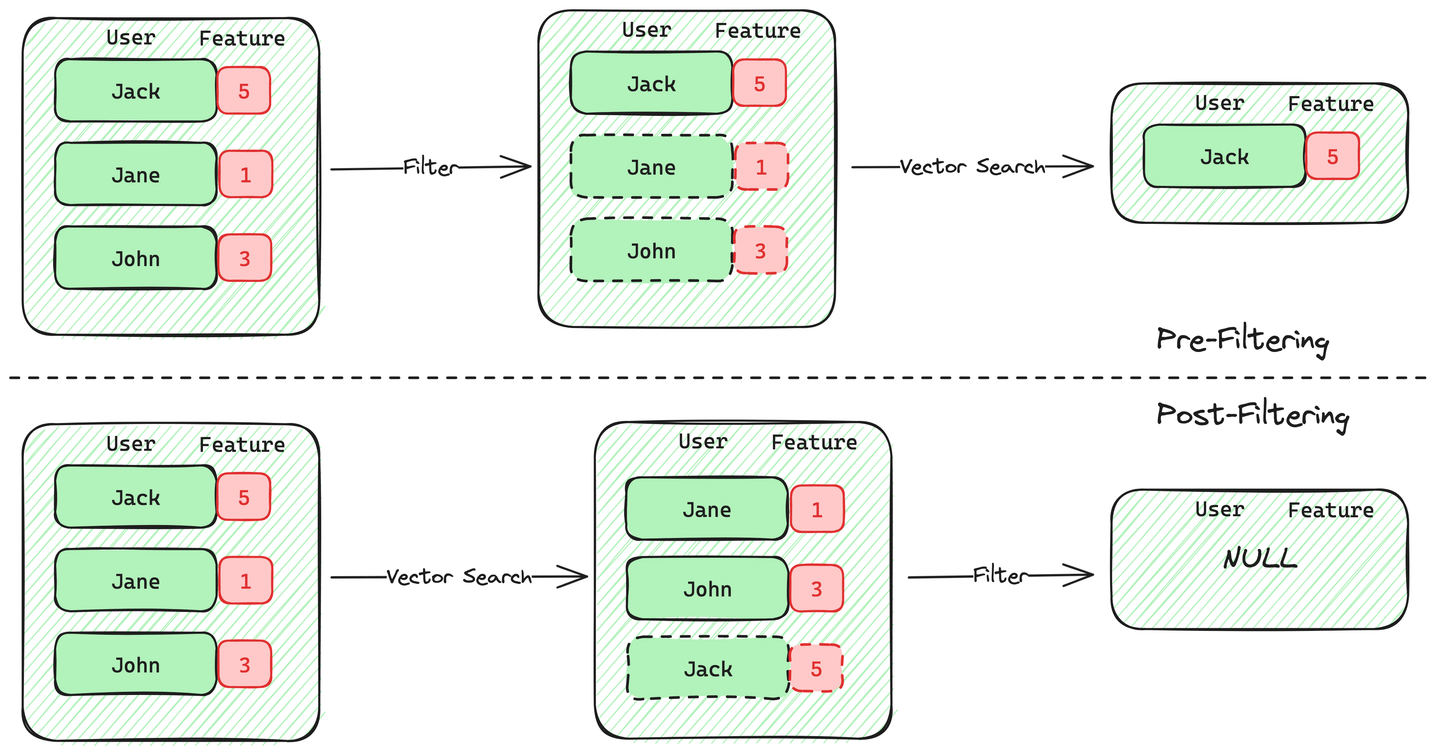
これらの 2 つの方法の間で、プリフィルタリングは、フィルタリングされたベクトル検索において精度と期待される動作の両方を満たす点でポストフィルタリングよりも優れています。ほとんどのベクトルデータベースは、ベクトル検索とプリフィルタリングをサポートしています。ただし、このプリフィルタリングは無料ではありません。プリフィルタリングは、計算量を増やし、フィルタリングされたベクトル検索のパフォーマンスを低下させます。ほとんどの実装では、パフォーマンスまたはフィルターの制限(データストレージやサポートされる比較演算子の制限など)のいずれかに苦しんでいます。
MyScale は、ClickHouse MergeTree エンジン (opens new window)から適応された列指向ストレージエンジン (opens new window)を使用しており、従来のフィルタに対して非常に高速であり、フィルタリングされたベクトル検索を他の実装よりも高速に行うことができます。さらに、テーブルの任意の列にフィルタを定義するために、シンプルな SQL のWHERE句を使用することができます。
# MyScale の WHERE 句でできること
MyScale は、ClickHouse (opens new window)の上に開発されているため、ClickHouse とまったく同じ機能を提供しています。
例えば:
| メソッド | その他 | MyScale |
|---|---|---|
| eq / neq | ✅ | ✅ |
| ge / gt / lt / le | ✅ | ✅ |
| include / exclude | ✅ | ✅ |
文字列パターンマッチ LIKE | ❌ | ✅ |
| タイムスタンプ/ジオデータ/JSON | ❌ | ✅ |
| 関数 | ❌ | ✅ |
| arrayFunction (opens new window) | ❌ | ✅ |
| サブクエリ | ❌ | ✅ |
MyScale のWHERE句がどのような機能を持っているかを示すいくつかの例を見てみましょう。
注意:
これらの例のコードは、Colab や GitHub のスペースで見つけることができます。
![]()
![]()
注意:
データ型や関数の詳細については、ClickHouse の公式ドキュメント (opens new window)を参照してください。
# 一般的な値の比較:=, !=, >, <, >=, <=
ほとんどのベクトルインデックスソリューションは、これらの操作を文字列や数値に対してサポートしています。MyScale では、次のように値の比較を記述することができます。
WHERE column = value
ここで、column はテーブル内の任意の列名であり、operation は=, !=, >, <, >=, <=のいずれかです。
注意:
列の型と値は同じである必要があります。
WHERE句に複数の条件を追加する場合は、論理演算子(ANDなど)を使用してそれらを接続します。
WHERE column_1 = value_1 AND column_2 >= value_2
# 集合演算子:Include, Exclude
MyScale は、INとNOT INのような集合演算子もサポートしています。
WHERE column IN (value_1, value_2, ...)
これは、一連の行を選択したい場合に便利です。同様に、これらの集合演算子を他の条件と組み合わせるために論理演算子を使用することができます。
# 配列の演算子
has関数を使用して、要素が配列に含まれているかどうかをチェックすることができます。
WHERE has(column, value_1)
# 文字列パターンマッチング
MyScale では、キーワードLIKEを使用して文字列のパターンマッチングを行うことができます。
WHERE column_1 LIKE '%value%'
この条件は、column_1にvalueを含む値に一致します。この文字列パターンマッチング演算子は、MySQL が提供する多くの演算子の 1 つです。他には、NOT LIKE、正規表現を使用したmatch、ngramSearchなどがあります。
注意:
LIKE演算子の詳細については、ClickHouse の公式ドキュメント (opens new window)を参照してください。
# 日時の比較
MyScale には、日時の比較関数も含まれています。
WHERE dateDiff('hour', column_datetime, toDateTime('2018-01-02 23:00:00')) >= 25;
このWHERE句は、column_datetimeが与えられた日時よりも 25 時間以上後の行に対応します。この関数は、秒、分、日、月もサポートしています。
注意:
詳細についてはこちら (opens new window)を参照してください。
# ジオデータの比較
MyScale は、ルートプランニングやジオメトリ解析に便利なH3 Index (opens new window)やS2 Geometry (opens new window)などの強力なツールを扱うことができます。
例えば、H3 Index を使用して、指定されたエリア内の地理データをフィルタリングすることができます。
WHERE h3CellAreaM2(column_h3) > 1000
また、特定の H3 Index までの距離を追加することもできます。
WHERE h3Distance(column_h3, value_h3) > 10
# JSONカラムを使用した任意のオブジェクト
MyScale では、JSON をオブジェクトとして格納し、その属性でフィルタリングすることができます。
JSONデータ型を使用して、JSON 文字列をテーブルにインポートし、以下のWHERE句を使用して結果をフィルタリングすることができます。
WHERE column_json.attr_1 = value_1
ネストされた属性でフィルタリングすることもできます。
WHERE column_json.attr_1.attr_2 = value_1
これは実験的な機能 (opens new window)ですが、非常に強力です。私たちはこれらのオブジェクトをLangChain (opens new window)やLlamaIndex (opens new window)のベクトルストアの実装で使用しています。
# 値関数
MyScale には、WHERE句で利用できる多くの列データ処理関数が含まれています。
WHERE abs(column_1) > 5
複数の列をWHERE句に含めることもできます。
WHERE column_1 + column_2 + column_3 > 10
# 配列関数
配列関数は非常に強力ですが、特にベクトル検索では非常に有用です。ドキュメント (opens new window)では、フューションショット分類器の最終的なロジット計算や勾配計算において、MyScale の配列関数を紹介しています。
ClickHouse には、配列関数に関する素晴らしいドキュメント (opens new window)があります。
注意:
MyScale で配列関数に関するサポートが必要な場合は、discord (opens new window)に参加して質問してください。
# サブクエリのサポート
サブクエリは、クエリ内のクエリです。以下のように、別のSELECTクエリを使用してWHERE句を書くこともできます。
WHERE column_1 IN (SELECT ... FROM another_table WHERE ...)

# フィルタリングされたベクトル検索のパフォーマンス
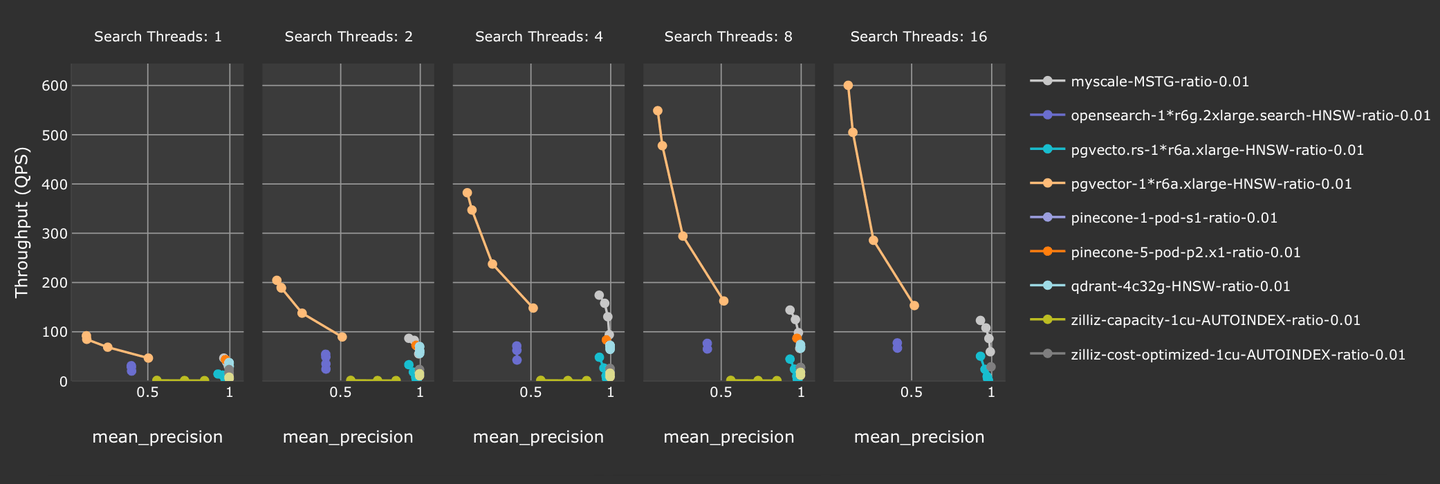
vector-db-benchmark (opens new window)でフィルタリングされたベクトル検索のパフォーマンスを調査しました。クエリ中にランダムな浮動小数点数をフィルターマークとして追加したlaion-768-5m-ip-probabilityを使用しました。また、MyScale と他の人気のあるベクトルデータベースソリューションをテストしました。以下のグラフは、MyScale が他のベクトルデータベースソリューションの多くを上回り、より高いスループットでより良い精度を提供していることを示しています。
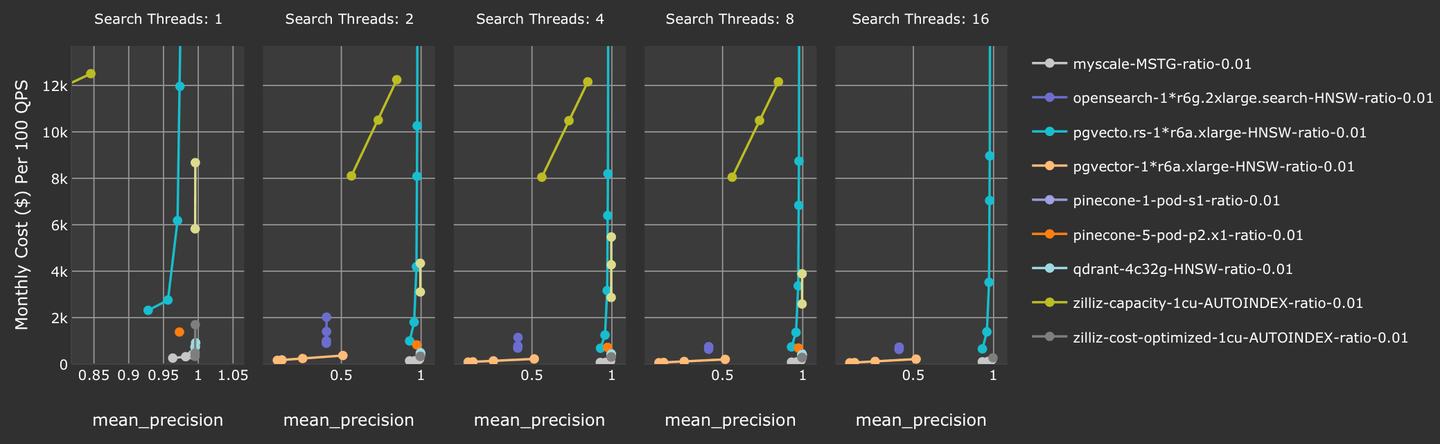
さらに、MyScale は、精度が 90%以上の場合において、テストされたすべてのベクトルデータベースの中で最もコスト効率が良い結果を達成しています。pgvector や pgvector.rs などの他の SQL 統合ベクトルデータベースと比較した場合、MyScale は、フィルタリングされた検索のための本番用の精度とスループットを実現している唯一の SQL とベクトル統合データベースです。
注意:
詳細については、pgvector と MyScale を比較する (opens new window)ブログを参照してください。
まとめると、MyScale は、より高いスループットでより良い精度を提供し、より低コストであります。製品ラインの s1 ポッドでは、無料で登録ユーザー全員が 5 百万のベクトルとさまざまなデータ型と関数をサポートしています。
# 結論
フィルタリングされた検索は、ベクトルデータベースにおいて一般的なクエリの一種であり、特定の基準やフィルタに基づいて類似したベクトルやデータポイントを検索することができます。テキストや画像の埋め込みなど、ベクトルとして表現できるデータを扱う場合に特に有用です。
MyScale は、AI 技術に SQL のパワーを組み込んでおり、フィルタリングされた検索はその一例です。ベクトルデータベースに対してより洗練された柔軟なクエリ機能を提供することができます。AI と SQL を組み合わせることで、複雑なデータ操作や検索を行い、価値ある洞察を抽出し、パターンを発見し、さまざまな分析タスクを実行することが容易になります。
AI アプリケーションに SQL をどのように活用できるかに興味がある場合は、今すぐdiscord (opens new window)またはTwitter (opens new window)で参加してください。




