
Update (2023-10-17): Check out our new blog post Comparing MyScale with Postgres and OpenSearch: An Exploration into Integrated Vector Databases (opens new window) for a comprehensive comparison between MyScale and PostgreSQL.
The rapid growth of AI and ML applications, particularly those involving large-scale data analysis, has increased demand for vector databases that can efficiently store, index, and query vector embeddings. Therefore, vector databases like MyScale, Pinecone, and Qdrant continue to be developed and expanded to meet these requirements.
At the same time, traditional databases continue to improve their vector data storage and retrieval capabilities. For instance, the well-known relational database PostgreSQL and its pgvector extension (opens new window) provide similar functionality, albeit less effectively than a well-optimized vector database.
There are significant differences in performance, accuracy, and other aspects when using a general-purpose database like PostgreSQL. These differences can lead to bottlenecks in performance and data scale. To address these issues, upgrading to a more efficient vector database like MyScale is recommended.
What sets MyScale apart from other specialized vector databases is its ability to provide full SQL support without compromising on high performance. This makes the migration process from PostgreSQL to MyScale much smoother and simpler.
To add value to this statement, let’s consider a use case where we have vector data stored in a PostgreSQL database but have performance and data scale bottlenecks. Therefore, as a solution, we have decided to upgrade to MyScale.
# Migrate Data From PostgreSQL to MyScale
A core part of upgrading to MyScale from PostgreSQL is to migrate the data from the old to the new database. Let's look at how this is done.
Note:
To demonstrate how to migrate data from PostgreSQL to MyScale, we must set up both databases even though our use case notes that we already have vector data in a PostgreSQL database.
Before we begin, it's important to note that we will use the following environments and datasets:
# Environments
| Database | Tier | DB Version | Extension Version |
|---|---|---|---|
| PostgreSQL on Supabase (opens new window) | Free (up to 500MB database space) | 15.1 | pgvector 4.0 |
| MyScale (opens new window) | Development (up to 5 million 768-dimensional vectors) | 0.10.0.0 |
# Dataset
We used the first 1M rows (1,000,448 rows exactly) from the LAION-400-MILLION OPEN DATASET (opens new window) for this exercise to demonstrate a scenario where the data scale continues to increase after migration.
Note:
This dataset has 400 million entries, each consisting of a 512-dimensional vector.
# Load the Data into PostgreSQL
If you already know about PostgreSQL and pgvector, you can skip ahead to the migration process by clicking here.
The first step is to load the data into a PostgreSQL database by working through the following step-by-step guide:
# Create PostgreSQL Database and Set Environment Variables
Create a PostgreSQL instance with pgvector in Supabase as follows:
- Navigate to the Supabase website (opens new window) and log in.
- Create an organization and name it.
- Wait for the organization and its database to be created.
- Enable the
pgvectorextension.
The following GIF describes this process further.

Once the PostgreSQL database has been created and pgvector enabled, the next step is to configure the following three environment variables to establish the connection to PostgreSQL using psql:
export PGHOST=db.qwbcctzfbpmzmvdnqfmj.supabase.co
export PGUSER=postgres
export PGPASSWORD='********'
Additionally, run the following script to increase the memory and request duration limits, making sure any SQL queries we run are not interrupted:
$ psql -c "SET maintenance_work_mem='300MB';"
SET
$ psql -c "SET work_mem='350MB';"
SET
$ psql -c "SET statement_timeout=4800000;"
SET
$ psql -c "ALTER ROLE postgres SET statement_timeout=4800000;";
ALTER ROLE
# Create a PostgreSQL Data Table
Execute the following SQL statement to create a PostgreSQL data table. Ensure both the vector columns (text_embedding and image_embedding) are of type vector(512).
Note:
The vector columns must be consistent with our data's vector dimensions.
$ psql -c "CREATE TABLE laion_dataset (
id serial,
url character varying(2048) null,
caption character varying(2048) null,
similarity float null,
image_embedding vector(512) not null,
text_embedding vector(512) not null,
constraint laion_dataset_not_null_pkey primary key (id)
);"
# Insert the Data Into the PostgreSQL Table
Insert the data in batches of 500K rows.
Note:
We have only inserted the first set of 500K rows to test how successfully the data was inserted before adding the rest.
$ wget https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion_dataset.sql.tar.gz
$ tar -zxvf laion_dataset.sql.tar.gz
$ cd laion_dataset
$ psql < laion_dataset_id_lt500K.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
# Build an ANN Index
The next step is to create an index that uses Approximate Nearest Neighbor search (ANN).
Note:
Set the lists parameter to 1000 as the expected number of rows in the data table is 1M rows. (https://github.com/pgvector/pgvector#indexing (opens new window))
$ psql -c "CREATE INDEX ON laion_dataset
USING ivfflat (image_embedding vector_cosine_ops)
WITH (lists = 1000);";
CREATE INDEX
# Run a SQL Query
The last step is to test that everything works by executing the following SQL statement:
$ psql -c "SET ivfflat.probes = 100;
SELECT id, url, caption, image_embedding <=> (SELECT image_embedding FROM laion_dataset WHERE id=14358) AS dist
FROM laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;"
If your result set looks like ours, we can proceed.
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.0749262628626345 | |
| 195973 | cat sitting in front and looking at camera isolated on white background Stock Photo | 0.0929287358264965 | |
| 83158 | Abyssinian Cat Pictures | 0.105731256045087 | |
| 432425 | Russian blue kitten Stock Images | 0.108455925228164 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white Norwegian Forest Cat, on white background royalty free stock image | 0.111603095925331 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.115501832572401 | |
| 281881 | Sealpoint Ragdoll lying on white background Stock Images | 0.121348724151614 | |
| 497148 | Frightened black kitten standing in front of white background | 0.127657010206311 | |
| 490374 | Lying russian blue cat Stock Photo | 0.129595023570348 | |
| 401134 | Maine coon cat on pastel pink Stock Image | 0.130214431419139 |
# Insert the Rest of the Data
Add the rest of the data to the PostgreSQL table. This is important to validate the performance of pgvector at scale.
$ psql < laion_dataset_id_ge500K_lt1m.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
ERROR: cannot execute INSERT in a read-only transaction
ERROR: cannot execute INSERT in a read-only transaction
As you can see from this script's output (and the following image), inserting the rest of the data returns errors. Supabase sets the PostgreSQL instance to read-only mode, preventing storage consumption beyond its free tier limits.
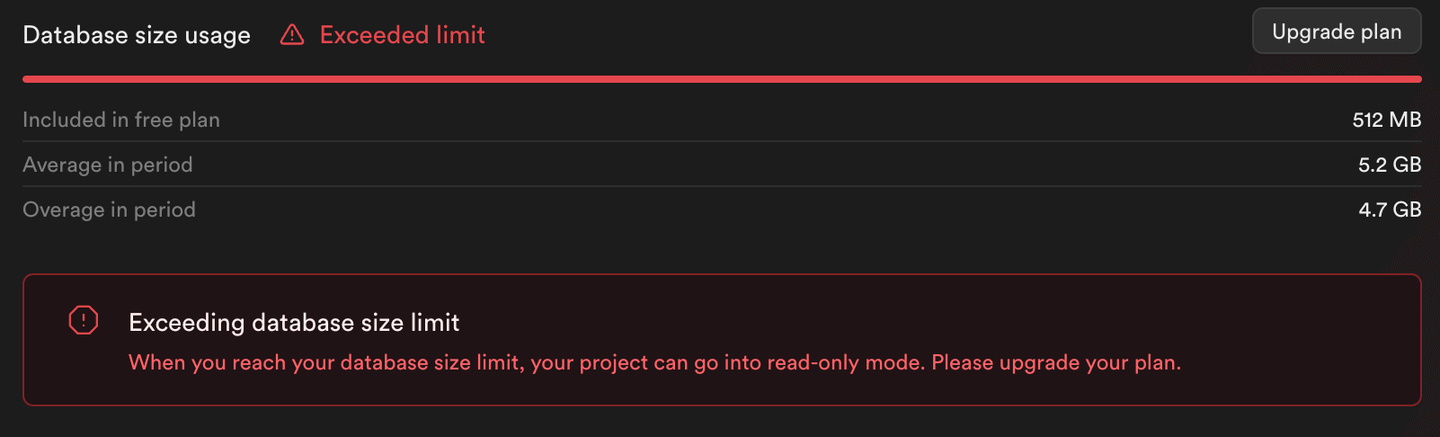
Note:
Only 500K rows have been inserted into the PostgreSQL table and not 1M rows.
# Migrate to MyScale
Let's now migrate the data to MyScale by following the step-by-step guide described below:
Note:
Not only is MyScale an high-performant integrated vector database, but benchmarking reports that MyScale can outperform other specialized vector databases with respect to search performance, accuracy, and resource utilization. MyScale's proprietary vector indexing algorithm, Multi-Scale Tree Graph (MSTG), utilizes local NVMe SSD as a cache disk, significantly increasing the supported index scale when compared to in-memory situations.
# Create a MyScale Cluster
The first step is to create and launch a new MyScale cluster.
- Navigate to the Clusters page (opens new window) and click the +New Cluster button to launch a new cluster.
- Name your cluster.
- Click Launch to run the cluster.
The following image describes this process further:
# Create a Data Table
Once the cluster is running, execute the following SQL script to create a new database table:
CREATE TABLE laion_dataset
(
`id` Int64,
`url` String,
`caption` String,
`similarity` Nullable(Float32),
`image_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(image_embedding) = 512,
`text_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(text_embedding) = 512
)
ENGINE = MergeTree
ORDER BY id;
# Migrating Data from PostgreSQL
When you have created the database table, use the PostgreSQL() table engine (opens new window) to migrate the data from PostgreSQL easily.
INSERT INTO default.laion_dataset
SELECT id, url, caption, similarity, image_embedding, text_embedding
FROM PostgreSQL('db.qwbcctzfbpmzmvdnqfmj.supabase.co:5432',
'postgres', 'laion_dataset',
'postgres', '************')
SETTINGS min_insert_block_size_rows=65505;
Note:
The setting min_insert_block_size_rows is added to limit the number of rows inserted per batch, preventing excessive memory usage.
# Confirm the Total Number of Rows Inserted
Use the SELECT count(*) statement to confirm whether all the data has migrated to MyScale from the PostgreSQL table.
SELECT count(*) FROM default.laion_dataset;
The following result set shows the migration is successful because this query returns 500K (500000) rows.
| count() |
|---|
| 500000 |
# Build Database Table Index
The next step is to build an index with the index type MSTG and metric_type (distance calculation method) as cosine.
ALTER TABLE default.laion_dataset
ADD VECTOR INDEX laion_dataset_vector_idx image_embedding
TYPE MSTG('metric_type=cosine');
Once this ALTER TABLE statement has finished executing, the next step is to check the index's status. Run the following script and if the status returns as Built, the index was successfully created.
SELECT database, table, type, status FROM system.vector_indices;
| database | table | type | status |
|---|---|---|---|
| default | laion_dataset | MSTG | Built |
# Execute an ANN Query
Run the following script to execute an ANN query using the MSTG index we have just created.
SELECT id, url, caption,
distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)
) AS dist
FROM default.laion_dataset where id!=14358 ORDER BY dist ASC LIMIT 10;
If the following result table is consistent with the results from the PostgreSQL query, our data migration is successful.
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.0749262628626345 | |
| 195973 | cat sitting in front and looking at camera isolated on white background | 0.0929287358264965 | |
| 83158 | Abyssinian Cat Pictures | 0.105731256045087 | |
| 432425 | Russian blue kitten Stock Images | 0.108455925228164 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white... | 0.111603095925331 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.115501832572401 | |
| 281881 | Sealpoint Ragdoll lying on white background Stock Images | 0.121348724151614 | |
| 497148 | Frightened black kitten standing in front of white background | 0.127657010206311 | |
| 490374 | Lying russian blue cat Stock Photo | 0.129595023570348 | |
| 401134 | Maine coon cat on pastel pink Stock Image | 0.130214431419139 |

# Insert the Rest of the Data Into the MyScale table
Let's add the rest of the data to the MyScale table.
# Import Data from CSV/Parquet
The good news is that we can import the data directly from the Amazon S3 bucket using the following MyScale method:
INSERT INTO laion_dataset
SELECT * FROM s3(
'https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion-1m-pic-vector.csv',
'CSV',
'id Int64, url String, caption String, similarity Nullable(Float32), image_embedding Array(Float32), text_embedding Array(Float32)')
WHERE id >= 500000 SETTINGS min_insert_block_size_rows=65505;
This automates the data insertion process, reducing the time spent manually adding the rows in 500K batches.
# Confirm the Total Number of Rows Inserted
Once again, run the following SELECT count(*) statement to confirm whether all the data from the S3 bucket has been imported into MyScale.
SELECT count(*) FROM default.laion_dataset;
The following result set shows that the correct number of rows have been imported.
| count() |
|---|
| 1000448 |
Note:
The free pod of MyScale can store a total of 5M 768-dimensional vectors.
# Execute an ANN Query
We can use the same SQL query as we used above to perform queries on a dataset of 1M rows.
To refresh your memory, here is the SQL statement again:
SELECT id, url, caption, distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)) AS dist
FROM default.laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;
Here is the query result set, including the newly-added data:
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.07492614 | |
| 195973 | cat sitting in front and looking at camera isolated on white background Stock Photo | 0.09292877 | |
| 693487 | Russian Blue cat, mysterious cat, friendly cat, Frances Simpson, cat breeds, cats breed | 0.09316337 | |
| 574275 | Mixed-breed cat, Felis catus, 6 months old Royalty Free Stock Photo | 0.09820753 | |
| 83158 | Abyssinian Cat Pictures | 0.10573125 | |
| 797777 | Male Cat Names For Orange Cats | 0.10775411 | |
| 432425 | Russian blue kitten Stock Images | 0.10845572 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white... | 0.1116029 | |
| 864554 | Rear view of a Maine Coon kitten sitting, looking up, 4 months old, isolated on white | 0.11200631 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.11550176 |
# In Conclusion
This discussion describes how migrating vector data from PostgreSQL to MyScale is straightforward. And even as we increase the data volume in MyScale by migrating data from PostgreSQL and importing new data, MyScale continues to exhibit reliable performance irrespective of the size of the dataset. The colloquial phrase: The bigger, the better, rings true in this regard. MyScale's performance remains reliable even when querying super-large datasets.
Therefore, if your business experiences data scale or performance bottlenecks, we strongly recommend migrating your data to MyScale using the steps outlined in this article.



