
Whenever the word database is mentioned, relational databases (opens new window) have long been the default choice for data storage due to their simplicity and ease of use. However, in today’s data-driven world, the growing importance of unstructured data, such as text, images, and audio, has led to the emergence of vector databases (opens new window) as a viable alternative.
Unlike traditional databases, which are restricted to primitive data types integers and strings, vector databases store and manage data as vectors. This allows them to handle unstructured data efficiently, making them exceedingly popular. In recent years, many companies have provided vector databases and vector search services. So a series of articles will make a comprehensive comparison of MyScale (opens new window) and some other popular vector databases, with Pinecone as the first one. Pinecone (opens new window) is a close-sourced specialized vector database designed to efficiently handle high-dimensional vector data. It excels at storing, indexing, and querying vector embeddings, making it an ideal solution for similarity search and machine learning applications that require real-time and high-dimensional vector operations.
Before the comparison of MyScale and Pinecone, let me briefly introduce some important concepts related to vector databases.
# Why is Vector Search Important
A vector can represent several things: an array of values, some textual data, spatial data, images, and so on. We all know how easy it is to perform the basic vector arithmetic or take the dot products to find their alignment/similarity.
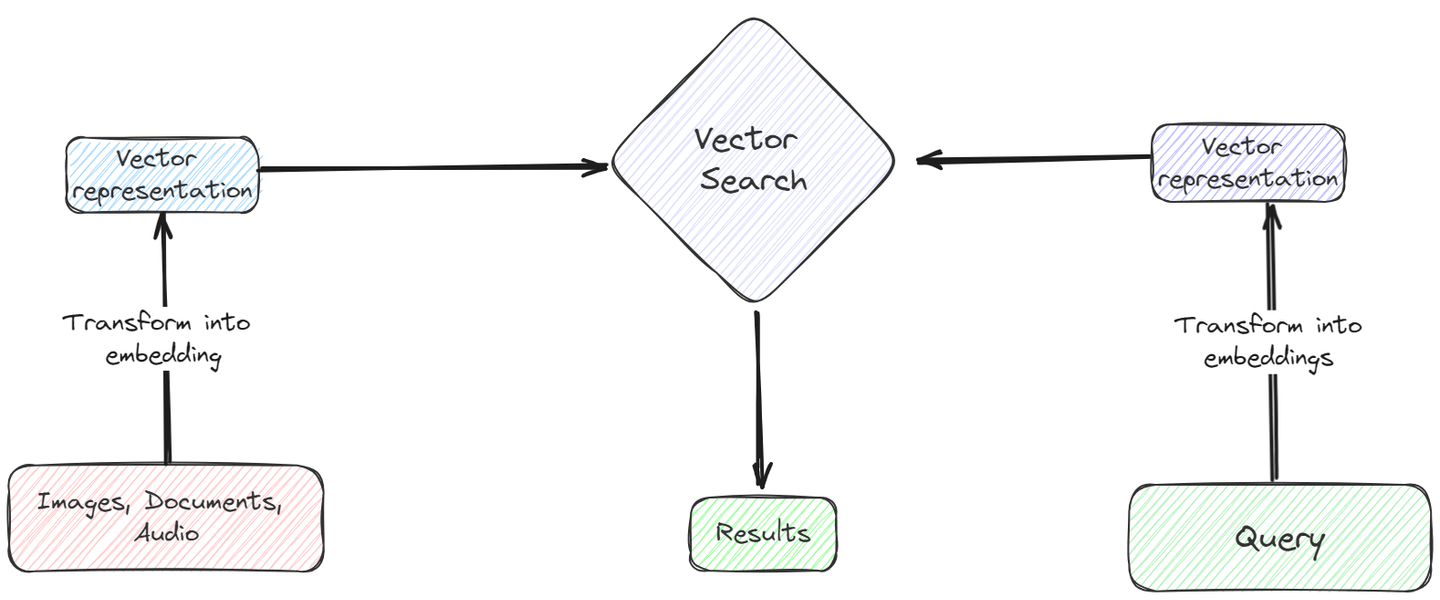
By using some suitable embeddings, the unstructured data can be stored in the vector databases in the form of vectors. Then primitive similarity measures like Cosine similarity or even Euclidean distance can be used to quickly and efficiently perform similarity searches on the vectors. This vector search (opens new window) is much faster and cost-effective compared to traditional databases, making it well-suited for handling large volumes of unstructured data effectively.
# What are SQL Vector Databases
Apart from specialized vector databases, some SQL databases have extended the capabilities to provide vector search as well. These integrated solutions, known as SQL vector databases (opens new window), aim to provide vector-based similarity search capabilities within the structured data environment and enable to manage both vector and structured data within a unified database framework.
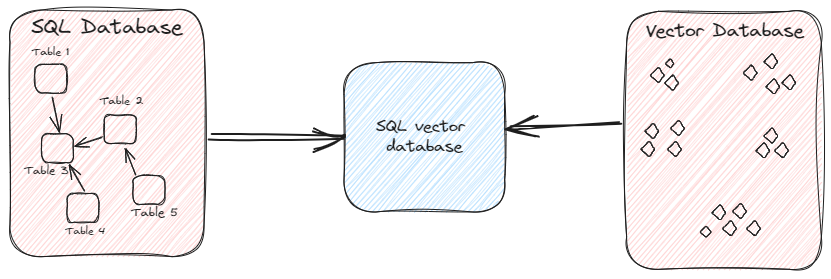
Among SQL vector databases, MyScale is an open-source option that extends ClickHouse’s capabilities. It's the only integrated database that has been able to outperform even specialized vector databases (opens new window) in terms of speed and performance.
# Importance in the Realm of LLMs
With the advent of LLMs, inevitably their applications are spreading in different areas. These foundational models can be adapted to specific requirements of applications using a number of methods that can be broadly classified into two types: fine-tuning (opens new window) and RAG (opens new window).
In fine-tuning, we use the existing model and fine-tune it onto the new/relevant data. Since it involves learning, it is computationally quite expensive. Despite techniques like LoRA, etc., still some handsome GPUs are required to fine-tune LLMs.
RAG (opens new window), on the other hand, does not involve traditional learning processes. Instead, it uses vector embeddings for vector search. This method utilizes primitive similarity measures, making the search process significantly faster.
Up until now, we have covered almost all the basic concepts. Let's now proceed to compare the two databases, MyScale and Pinecone.
# Hosting
Hosting is a critical aspect to consider when choosing a database solution, as it significantly impacts performance, scalability, and management. A robust hosting option ensures that your database can handle varying loads, remain accessible, and be easily maintained. Additionally, understanding hosting options helps determine whether you need to deploy the database locally using your own resources or opt for a cloud-hosted service.
Both options can be utilized in a cloud-based mode by creating instances in the cloud. Pinecone operates solely as a proprietary cloud service, while MyScale provides both a cloud version, MyScale Cloud (opens new window), and an open-source version available at https://github.com/myscale/myscaledb. The open-source version can be launched using the following Docker command:
docker run --name MyScale --net=host myscale/MyScale:1.6
Additionally, MyScale Cloud offers a free tier, allowing you to sign up quickly and start (opens new window) experimenting. For more details, please check the quick start document (opens new window).
# Core Functionalities
# Query Language and API Support
One key consideration when adopting a new database technology is the ease of integration with existing development workflows and familiarity with the query language. Luckily, MyScale saves the trouble by using SQL which we use for relational databases.
MyScale doesn’t end here as it also provides integrated various developer tools such as Python Client (opens new window), Node.js (opens new window), Go Client (opens new window), ClientJDBC Driver (opens new window), and HTTPS Interface (opens new window).
TL;DR:
Both Pinecone and MyScale offer SDKs in various languages, but MyScale has a distinct advantage with its full SQL support.
# Supported Data Types
Pinecone is dedicated to vector storage only. MyScale, on the other hand, is much more versatile and allows us to store different data types from text to images.
We can make a table that has both scalar and vector attributes seamlessly. Due to the SQL interface, it sounds like making a normal relational DB table. This SQL code will create a table with body_vector of length 512.
CREATE TABLE default.wiki_abstract(
id UInt64,
body String,
title String,
url String,
body_vector Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 512
)
ENGINE = MergeTree
ORDER BY id;
Also, since it uses the tabular format, there’s no restriction on the row length. Hence document size isn’t limited, unlike its competitor.
# Indexing
There are several indexing algorithms used in vector databases, such as IVF and KD trees. Pinecone uses the Hierarchical Navigable Small Worlds (HNSW) algorithm and the FreshDiskANN algorithm. FreshDiskANN is designed for efficient real-time updates, supporting high recall and performance for large-scale datasets.
MyScale introduces the Multi-Scale Tree Graph (MSTG) (opens new window), an algorithm combining hierarchical tree clustering and graph-based search. MSTG outperforms contemporary algorithms by providing faster searches with reduced resource consumption. If there were a single reason to choose MyScale over Pinecone, MSTG would be compelling enough.
# Filtered Vector Search
Pinecone offers metadata filtering with support for up to 40KB of metadata per vector. This metadata can include strings, numbers, and booleans, which allows for detailed, attribute-based searches. Pinecone's single-stage filtering mechanism limits the search to items meeting the specified criteria, making the process faster and more accurate by avoiding brute-force searches.
MyScale optimizes filtered vector search (opens new window) using its MSTG algorithm alongside ClickHouse's advanced indexing and parallel processing capabilities. Besides, pre-filtering strategy is also adopted to narrow the dataset before the main vector search, enhancing performance and accuracy. ClickHouse’s column-oriented storage, vectorized query execution, advanced indexing, and parallel processing make it an ideal foundation of MyScale for large datasets, maintaining speed and precision without the drawbacks of post-filtering.
TL;DR:
Pinecone excels in detailed, attribute-based searches with rich metadata support. However, MyScale offers superior performance and scalability for large datasets with its pre-filtering strategy and SQL-based architecture.
# Full-Text Search
MyScale also offers advanced full-text search (opens new window) (FTS) features using the Tantivy library, including fuzzy and wildcard searches, and BM25 algorithm-based relevance scoring. This setup enables MyScale to intuitive and efficient access to unstructured text data, allowing users to search based on topics or key ideas. MyScale now offers a robust and efficient solution for complex text search requirements. To create a basic FTS index, you can follow the following syntax:
-- Create full text search index
ALTER TABLE [table_name] ADD INDEX [index_name] [column_name]
TYPE fts;
-- Make query
SELECT
id,
title,
body,
TextSearch(body, 'non-profit institute in Washington') AS score
FROM default.en_wiki_abstract
ORDER BY score DESC
LIMIT 5;
In contrast, Pinecone is only designed for vector search and does not include built-in full-text search capabilities.
TL;DR:
This full-text search feature of MyScale makes it a more versatile choice for applications that need comprehensive data querying and analysis.
# LLM APIs Integration
There’s not much to separate them here as both of them support common APIs like LangChain, LlamaIndex, etc. To give a better idea, I will provide a basic code here that uses the LangChain with MyScale.
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
output = docsearch.similarity_search("How LLMs operate?", 3)
# Pricing
Both Pinecone and MyScale provide a free tier. It’s very helpful as often new users want to just try a new tool before being able to reach a consensus on whether to implement it (or not). For new users, Pinecone's free tier offers up to 2GB of storage, which can handle approximately 300,000 vectors with 1,536 dimensions each.
On the other hand, MyScale offers free storage for up to 5 million 768-dimensional vectors, which can accommodate approximately 2.5 million 1,536-dimensional vectors. This is significantly higher than Pinecone's free tier, making MyScale a more attractive option for users who need to manage larger datasets without initial costs.
Both Pinecone and MyScale provide users with performance and storage-optimized pods according to their requirements. This flexibility allows users to choose the best solution based on their specific needs. When it comes to pricing, MyScale is significantly cheaper compared to Pinecone.
# Pricing for capacity-optimized pods
The following table is ideal for users who require higher storage capacity for their applications. It showcases the pricing and capacity options available for both MyScale and Pinecone under the capacity-optimized category.
| Pod Type (MyScale) | Pod Size | MyScale Base Price ($/hour) | MyScale Estimated Capacity | Pod Type (Pinecone) | Pinecone Base Price ($/hour) | Pinecone Approximate Capacity |
|---|---|---|---|---|---|---|
| Capacity-optimized Pod | x 1 | $0.094/hour | 10 million vectors | s1 | $0.11 | 5 million vectors |
| Capacity-optimized Pod | x 2 | $0.189/hour | 20 million vectors | s1 | $0.22 | 10 million vectors |
| Capacity-optimized Pod | x 4 | $0.378/hour | 40 million vectors | s1 | $0.44 | 20 million vectors |
| Capacity-optimized Pod | x 8 | $0.756/hour | 80 million vectors | s1 | $0.89 | 40 million vectors |
| Capacity-optimized Pod | x 16 | $1.511/hour | 160 million vectors | - | - | - |
| Capacity-optimized Pod | x 32 | $3.022/hour | 320 million vectors | - | - | - |
MyScale's capacity-optimized pods are reasonably priced and offer higher capacity. Compared to Pinecone, MyScale provides the ability to store more vectors at a lower cost per hour.
# Pricing for Performance Optimized Pods
The following table is ideal for users who prioritize performance over capacity. It highlights the pricing and capacity options available for both MyScale and Pinecone under the performance-optimized category.
| Pod Type (MyScale) | Pod Size | MyScale Base Price ($/hour) | MyScale Estimated Capacity | Pod Type (Pinecone) | Pinecone Base Price ($/hour) | Pinecone Approximate Capacity |
|---|---|---|---|---|---|---|
| Standard Pod | x 1 | $0.167/hour | 5 million vectors | P2 | $0.17 | 1 million vectors |
| Standard Pod | x 2 | $0.333/hour | 10 million vectors | P2 | $0.33 | 2 million vectors |
| Standard Pod | x 4 | $0.667/hour | 20 million vectors | P2 | $0.67 | 4 million vectors |
| Standard Pod | x 8 | $1.333/hour | 40 million vectors | P2 | $1.33 | 8 million vectors |
| Standard Pod | x 16 | $2.667/hour | 80 million vectors | - | - | - |
| Standard Pod | x 32 | $5.333/hour | 160 million vectors | - | - | - |
In terms of storage-optimized pods, MyScale offers a more cost-effective solution with the ability to store a greater number of vectors compared to Pinecone. This makes MyScale an excellent choice for users looking for a budget-friendly option that doesn't compromise on capacity.
TL;DR:
MyScale stands out as a better option in terms of both performance and cost, providing more storage capacity at lower prices compared to Pinecone, making it ideal for users who need to manage large-scale data efficiently.
# Benchmarking
Now, we will compare the performance between MyScale and Pinecone by benchmarking them on some key metrics. Throughout the comparison, we will use MyScale with MSTG, while two variants of Pinecone (1 node and 5 pods) will be used.
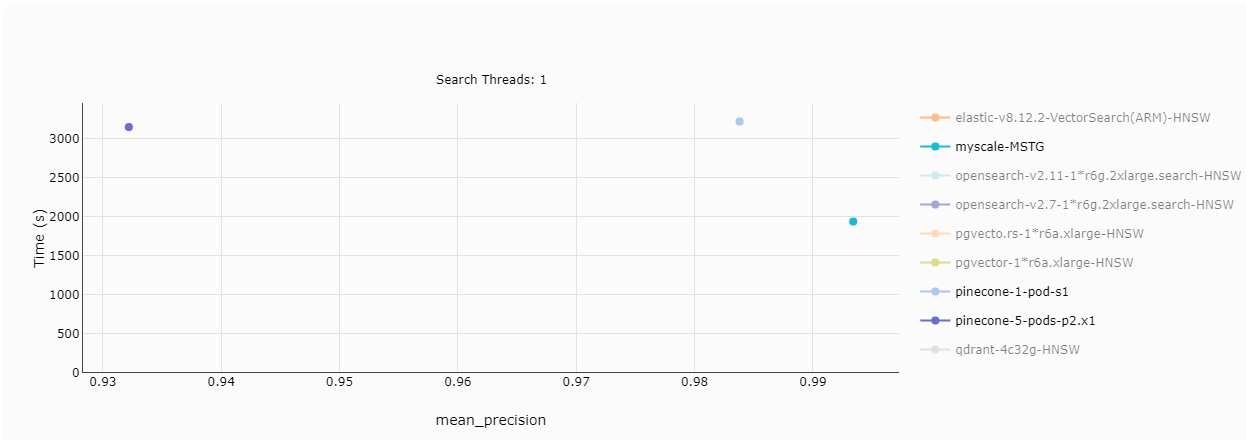
# Throughput (Queries per second)
Throughput is a fundamental measure of system performance, and customers are naturally interested in the number of queries handled per second. In single-threaded searches, Pinecone’s s1 pod significantly lags behind MyScale. However, five p2 pods from Pinecone can handle a comparable number of queries per second. When the thread count increases to 2, the performance gap widens, and at 8 threads, even the five p2 pods begin to fall behind.
Note: In the graphs, yellow represents MyScale, and the four different points indicate varying levels of precision. Higher precision requires more computation. A limitation of Pinecone is its inability to adjust precision like MyScale, resulting in a maximum recall of only 94%.
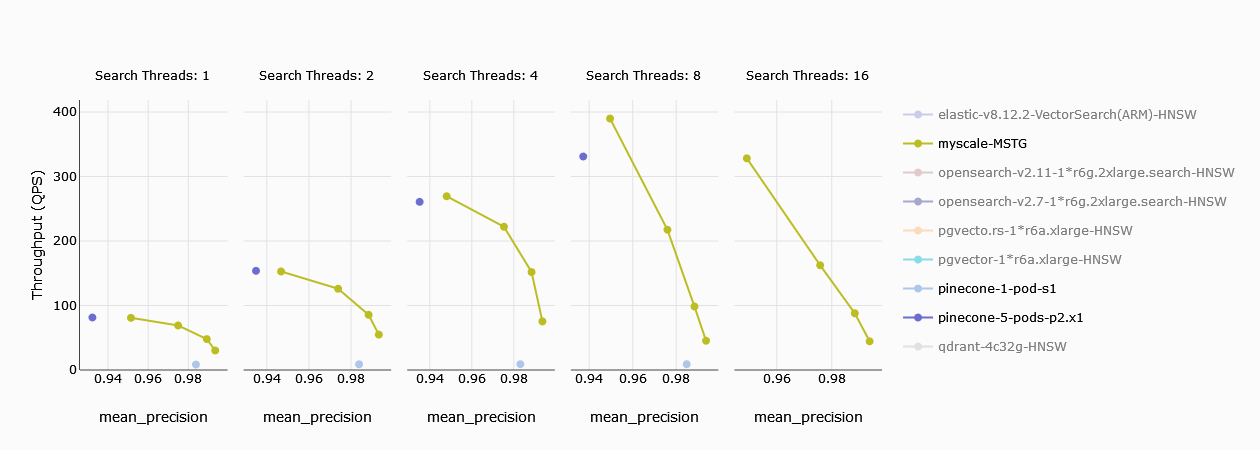
TL;DR:
Pinecone's s1 pod cannot compete with MyScale, but five p2 pods can match its performance. Pinecone's lack of precision tuning prevents it from achieving 99% recall, unlike MyScale.
# Average Query Latency
The next metric of interest is average query latency, which measures the average time taken to process a query. In our comparison, the s1 pod from Pinecone does not match MyScale, while the five p2 pods are competitive.
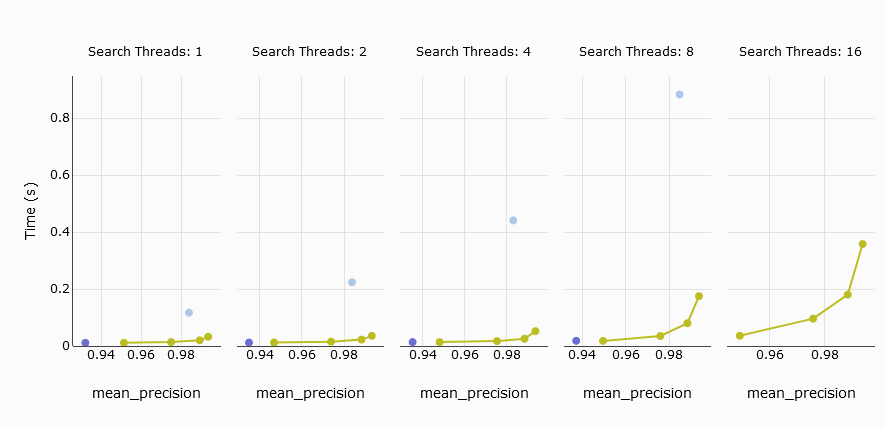
To enhance the comparison, we exclude the s1 pod and focus on the five p2 pods against MyScale. The results show that MyScale and Pinecone exhibit similar delays with up to 4 threads. However, MyScale's average query latency increases significantly when the number of threads reaches 8 or more.
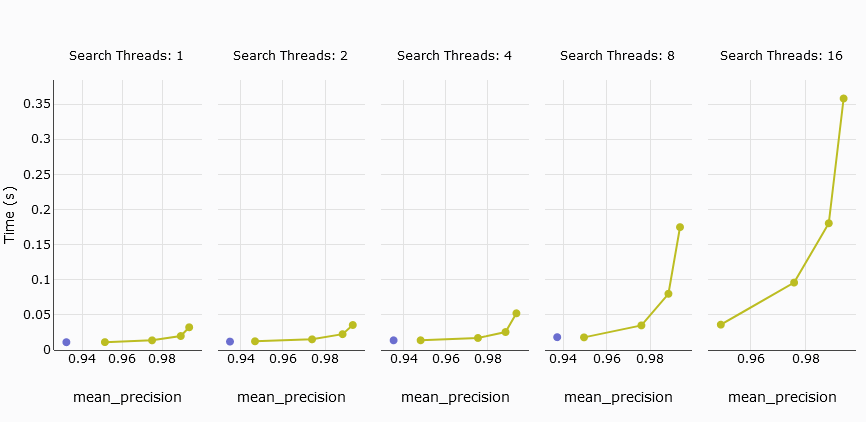
TL;DR:
When comparing Pinecone's five p2 pods with MyScale, both exhibit similar average query latency at low precision. However, Pinecone cannot adjust its precision to achieve a recall greater than 94%, unlike MyScale.
# Data Ingestion Time
Another useful metric is the data ingestion time - how long does it take to upload and build the database.
MyScale had the fastest ingestion time for 5 million data points, completing the task in about 30 minutes. Pinecone s1 takes approximately 53 minutes.
# Cost Comparison
We utilized five p2 pods in this comparison, which offer performance comparable to a single standard MyScale pod. However, the cost of five p2 pods amounts to approximately $600 per month, making them five times more expensive than MyScale. This stark cost difference highlights MyScale's superior cost-effectiveness, providing the same performance at a fraction of the price.
| Database | Pod Type | Monthly Cost ($) | Notes |
|---|---|---|---|
| MyScale | Standard Pod of Size x1 | 120 | Provides comparable throughput and latency to five Pinecone p2 pods |
| MyScale | Capacity-optimized Pod | 68 | Cost-effective option for capacity optimization |
| Pinecone | s1.x1 Pod | 80 | Optimized for storage |
| Pinecone | 5 x p2.x1 Pods | 600 | Performance-optimized via horizontal scaling |
Despite MyScale’s higher per-pod cost compared to Pinecone’s s1 pod, it provides comparable throughput and latency to five pods of Pinecone p2 at only one-fifth the cost.
**TL;DR:**
MyScale’s standard pod is far more cost-effective, offering similar performance to five of Pinecone’s p2 pods, which are five times more expensive.

# Conclusion
When comparing MyScale and Pinecone, MyScale stands out with its SQL-based integration, versatile data type support, and superior performance with the MSTG algorithm. MyScale offers faster query throughput and data ingestion times, cost-effective storage options, and full-text search capabilities. This makes it a great choice for managing large, diverse datasets.
Pinecone is strong in detailed, attribute-based searches with rich metadata support. However, MyScale's open-source nature, scalability, and performance advantages make it a more versatile and powerful option. MyScale’s edge in performance, flexibility, and cost makes it ideal for handling diverse and large-scale data management needs.
If you have any suggestions, please reach out to us through Twitter (opens new window) or Discord (opens new window).



