
大型语言模型(LLM)在从知识库中检索上下文后,可以更可靠地提供真实答案,这就是检索增强生成(RAG)的原理。我们之前的博客讨论了RAG的性能优势 (opens new window)和成本与延迟的可行性 (opens new window)。在本博客中,我们将为您介绍RAG管道的高级用法:使用 MyScale 构建检索增强生成(RAG)的聊天机器人。您还可以在我们的 HuggingFace 空间 (opens new window)上尝试它。
注意:
访问 MyScale 的HuggingFace空间 (opens new window)以尝试我们的聊天机器人。
![]()
聊天机器人与单轮问答任务有所不同。以下是区别之处:
单轮问答任务:
在单轮问答任务中,用户与系统之间的交互通常包括用户提出的一个问题和系统提供的直接回答。这些被称为问答对。
聊天机器人:
然而,聊天机器人与用户之间的对话更加复杂和广泛,包括多轮的讨论。聊天机器人可以处理持续的对话和后续问题,跟踪多次交互中的上下文。
为了实现这一点,聊天机器人需要存储用户的完整聊天历史,包括之前的对话和上次函数调用的操作(或结果)。其次,聊天机器人的内存应该能够同时为不同的用户提供服务,将他们的对话彼此分开。如果设置不正确,这可能是一个重大挑战。好消息是,MyScale通过其SQL兼容性和基于角色的访问控制 (opens new window)功能为这个挑战提供了完美的解决方案,使您能够轻松管理数百万用户的聊天历史。
聊天机器人也可以从RAG中受益,但并不是每个聊天都需要RAG。例如,当用户要求将一种语言翻译成另一种语言时,将RAG加入其中不会增加此请求的价值。因此,我们必须让聊天机器人决定何时以及在何处在其搜索查询中使用RAG。
我们如何实现这一点?
幸运的是,OpenAI提供了一个函数调用API,我们可以使用它来将MyScale作为外部函数调用插入检索管道 (opens new window)。
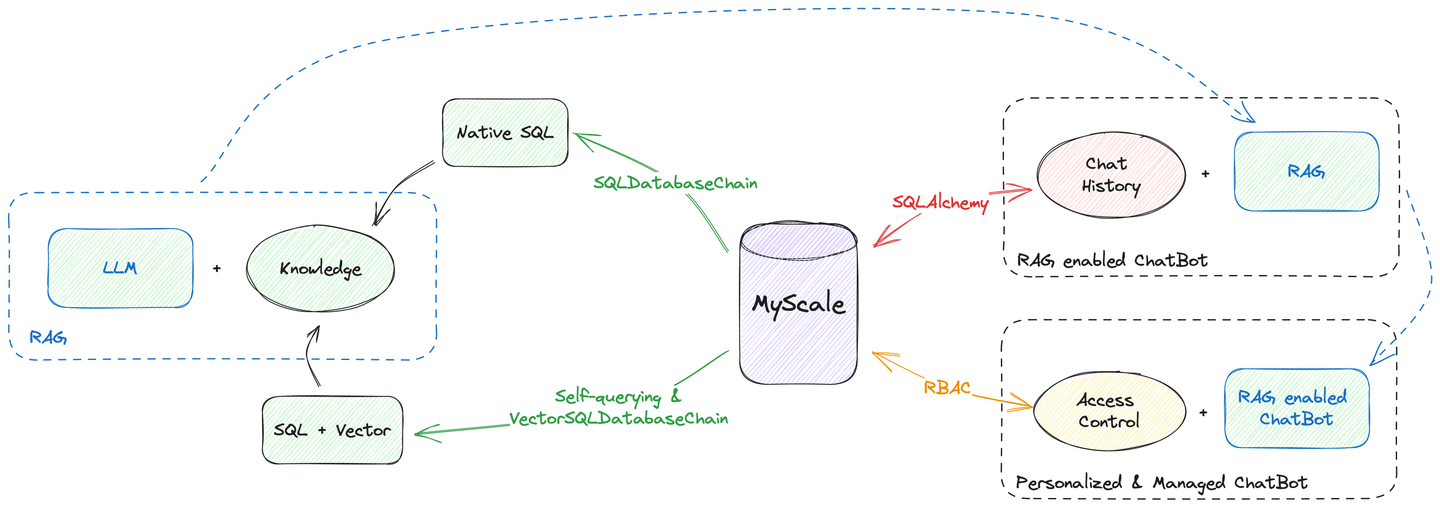
此外,MyScale能够完成从向量搜索到聊天历史管理的所有数据托管工作。如上图所示,您可以使用MyScale作为唯一的数据源构建聊天机器人。您不需要担心数据分散在不同的数据库和引擎中。
那么,让我们看看如何实现!
# 将检索器作为工具
RAG可以被视为一个外部函数。请参阅我们的OpenAI函数调用文档 (opens new window),了解有关创建提示以教导GPT使用MyScale向量存储作为工具的更多信息。
今天,我们将使用LangChain的检索器API,而不是向量存储,使用MyScale的高级过滤搜索来增强您的查询。之前,我们展示了如何使用自查询检索器 (opens new window)将您的问题转化为使用过滤器的向量搜索查询。我们还介绍了如何使用基于向量SQL数据库链构建的检索器 (opens new window)以SQL接口执行相同的操作。
注意:
这两个检索器只接受查询文本作为输入,因此将它们转化为聊天机器人工具很容易。
实际上,只需几行代码就可以将检索器转化为工具:
from langchain.agents.agent_toolkits import create_retriever_tool
retriever = ... # 自查询检索器 / 向量SQL数据库检索器
# 创建一个工具,以维基百科检索为例:
tool = create_retriever_tool(retriever,
"search_among_wikipedia",
"在维基百科中搜索并返回相关维基页面")
# 创建工具集
tools = [tool]
因此,您可以创建多个工具并将它们提供给单个聊天机器人。例如,如果您有多个知识库需要搜索,您可以为每个知识库开发工具,并让聊天机器人决定使用哪个工具。
# 记住对话
对话记忆对于聊天机器人至关重要。因为我们为聊天机器人提供了多个工具,我们还需要提供内存来存储这些工具的中间结果。这需要丰富的数据类型和先进的多租户支持,而MyScale擅长这方面。
以下Python脚本描述了如何为聊天机器人创建内存:
from langchain.memory import SQLChatMessageHistory
from langchain.memory.chat_message_histories.sql import BaseMessageConverter, DefaultMessageConverter
from langchain.agents.openai_functions_agent.agent_token_buffer_memory import AgentTokenBufferMemory
# MyScale凭据
MYSCALE_USER = ...
MYSCALE_PASSWORD = ...
MYSCALE_HOST = ...
MYSCALE_PORT = ...
database = 'chat'
# MyScale通过`clickhouse-sqlalchemy`包支持SQLAlchemy
conn_str = f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}'
# LangChain通过`clickhouse-sqlalchemy`包原生支持SQL数据库作为聊天历史后端
chat_memory = SQLChatMessageHistory(
# 会话ID应该是特定于用户的,它可以隔离会话
session_id,
# MyScale SaaS使用HTTPS连接
connection_string=f'{conn_str}/{database}?protocol=https',
# 这里我们自定义了消息转换器和表模式
custom_message_converter=DefaultClickhouseMessageConverter(name))
# AgentTokenBufferMemory将帮助我们存储来自用户、机器人和工具的所有中间消息
memory = AgentTokenBufferMemory(llm=llm, chat_memory=chat_memory)
MyScale还可以作为关系数据库使用。由于LangChain的SQLChatMessageHistory,您可以通过clickhouse-sqlalchemy将MyScale作为内存后端使用。在数据库中存储更多信息需要自定义消息转换器。
以下是如何定义内存的表模式:
import time
import json
import hashlib
from sqlalchemy import Column, Text
try:
from sqlalchemy.orm import declarative_base
except ImportError:
from sqlalchemy.ext.declarative import declarative_base
from clickhouse_sqlalchemy import types, engines
from langchain.schema.messages import BaseMessage, _message_to_dict, messages_from_dict
def create_message_model(table_name, DynamicBase): # type: ignore
# 在函数内部声明模型以获得动态表名
class Message(DynamicBase):
__tablename__ = table_name
# SQLChatMessageHistory将根据id对消息进行排序
# 所以这里我们将时间戳存储为id
id = Column(types.Float64)
# 会话ID用于隔离会话
session_id = Column(Text)
# 这是消息的真正主键
msg_id = Column(Text, primary_key=True)
# 消息类型,可以是HumanMessage / AIMessage或其他
type = Column(Text)
# JSON字符串中的附加消息
addtionals = Column(Text)
# 文本中的消息
message = Column(Text)
__table_args__ = (
# ReplacingMergeTree将根据主键去重
engines.ReplacingMergeTree(
partition_by='session_id',
order_by=('id', 'msg_id')),
{'comment': '存储聊天历史'}
)
return Message
class DefaultClickhouseMessageConverter(DefaultMessageConverter):
"""用于SQLChatMessageHistory的ClickHouse消息转换器。"""
def __init__(self, table_name: str):
# 为聊天内存创建表模式
self.model_class = create_message_model(table_name, declarative_base())
def to_sql_model(self, message: BaseMessage, session_id: str) -> Any:
tstamp = time.time()
msg_id = hashlib.sha256(f"{session_id}_{message}_{tstamp}".encode('utf-8')).hexdigest()
# 填充空白
return self.model_class(
id=tstamp,
msg_id=msg_id,
session_id=session_id,
type=message.type,
addtionals=json.dumps(message.additional_kwargs),
message=json.dumps({
"type": message.type,
"additional_kwargs": {"timestamp": tstamp},
"data": message.dict()})
)
def from_sql_model(self, sql_message: Any) -> BaseMessage:
# 将检索到的历史转换为消息对象
msg_dump = json.loads(sql_message.message)
msg = messages_from_dict([msg_dump])[0]
msg.additional_kwargs = msg_dump["additional_kwargs"]
return msg
现在,您拥有了一个由MyScale支持的完全功能的聊天内存。太棒了!
# 聊天内存管理
用户的对话历史是宝贵的资产,必须妥善保管。LangChain的聊天内存已经通过session_id进行了会话隔离的控制 (opens new window)。
数百万用户可能与您的聊天机器人进行交互,这使得内存管理变得具有挑战性。幸运的是,我们有几个“技巧”来帮助管理所有这些用户的聊天历史。
MyScale支持通过为用户创建不同的表、分区或主键来进行数据隔离。由于在数据库中创建太多的表会使系统负载过重,我们建议您采用基于元数据过滤的多租户策略 (opens new window)。更具体地说,您可以为用户创建分区而不是表,或者使用主键对其进行排序。这将帮助您从数据库中快速检索数据,比搜索和存储更高效。
在这种情况下,我们建议使用基于主键的解决方案。将session_id添加到主键列表中将提高检索特定用户聊天历史的速度。
# 这里我们修改了SQLAlchemy模型
def create_message_model(table_name, DynamicBase): # type: ignore
class Message(DynamicBase):
__tablename__ = table_name
id = Column(types.Float64)
session_id = Column(Text, primary_key=True)
msg_id = Column(Text, primary_key=True)
type = Column(Text)
addtionals = Column(Text)
message = Column(Text)
__table_args__ = (
engines.ReplacingMergeTree(
# ||| 这将为每1,000个会话创建一个分区
# vvv (太多的分区会拖慢系统)
partition_by='sipHash64(session_id) % 1000',
# 这里我们按会话ID和消息ID排序
# 这样会加快检索速度
order_by=('session_id', 'msg_id')),
{'comment': '存储聊天历史'}
)
return Message
注意:
如果您想了解更多关于多租户策略 (opens new window)的信息,请参阅我们的文档。
# 将它们组合起来
现在,我们已经拥有了构建带有RAG的聊天机器人所需的所有组件。让我们将它们组合起来,如下面的代码片段所示:
from langchain.agents import AgentExecutor
from langchain.schema import SystemMessage
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import MessagesPlaceholder
from langchain.agents.openai_functions_agent.base import OpenAIFunctionsAgent
# 初始化OpenAI LLM
chat_model_name = "gpt-3.5-turbo"
OPENAI_API_BASE = ...
OPENAI_API_KEY = ...
# 创建LLM
chat_llm = ChatOpenAI(model_name=chat_model_name, temperature=0.6, openai_api_base=OPENAI_API_BASE, openai_api_key=OPENAI_API_KEY)
# 启动提示以鼓励聊天机器人使用搜索功能
_system_message = SystemMessage(
content=(
"尽力回答问题。"
"可以使用任何可用的工具查找相关信息。"
"在调用搜索函数时,请保留查询中的所有细节。"
)
)
# 创建函数调用提示
prompt = OpenAIFunctionsAgent.create_prompt(
system_message=_system_message,
# 这是您将从数据库中放置的聊天历史的位置
extra_prompt_messages=[MessagesPlaceholde(variable_name="history")],
)
# 我们使用OpenAI函数代理
agent = OpenAIFunctionsAgent(llm=chat_llm, tools=tools, prompt=prompt)
# 将所有组件组合在一起
executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
# 我们将所有这些中间步骤存储在数据库中,因此我们需要这个
return_intermediate_steps=True,
)
这样,您就拥有了一个带有AgentExecutor的RAG-enabled聊天机器人。您可以使用一行简单的代码与它交谈:
response = executor({"input": "你好!"})
注意:所有聊天历史都存储在executor.memory.chat_memory.messages下。如果您想要渲染来自内存的消息的参考,请参考我们在GitHub上的实现 (opens new window)。

# 总结
MyScale在高性能向量搜索方面表现出色,并提供了SQL数据库的所有功能。您可以将其用作向量数据库和SQL数据库。此外,它还具有高级功能,如访问控制,用于管理用户和应用程序。
本博客演示了如何使用MyScale构建聊天机器人,将其作为唯一的数据源。将聊天机器人与单个数据库集成可以确保数据的完整性、安全性和一致性。它还通过存储记录的引用来减少数据冗余,提高数据访问和共享,并结合先进的访问控制。这可以显著提高可靠性和质量,使您的聊天机器人成为一个可以根据业务需求进行扩展的现代化服务。
在huggingface (opens new window)上尝试我们的聊天机器人,或者使用GitHub (opens new window)上的代码自己运行它!同时,加入我们的Twitter (opens new window)和Discord (opens new window)社区,分享您的想法。
# 参考资料:
- https://myscale.com/blog/zh/teach-your-llm-vector-sql/ (opens new window)
- https://myscale.com/docs/zh/advanced-applications/chatdata/ (opens new window)
- https://myscale.com/docs/zh/sample-applications/openai-function-call/ (opens new window)
- https://python.langchain.com/docs/modules/memory/ (opens new window)
- https://python.langchain.com/docs/integrations/memory/sql_chat_message_history (opens new window)
- https://python.langchain.com/docs/use_cases/chatbots (opens new window)
- https://python.langchain.com/docs/use_cases/question_answering/how_to/conversational_retrieval_agents (opens new window)



