
# 聊天数据应用
![]()
在 30 分钟内使用 LangChain 和 MyScale 构建一个能够处理数百万份文档的 ChatPDF 应用
与 GPT 聊天关于一篇学术论文相对来说比较简单,只需要将该论文作为语言模型的上下文提供即可。与数百万份研究论文聊天也很简单...只要你选择了正确的向量数据库。
大型语言模型(LLM)是强大的自然语言处理工具。LLM 的最大优势之一是,你可以使用它们构建工具,让你能够根据文档的主题而不是其他无关的问题与文档进行交互(或聊天),比如基于 PDF 格式的研究或学术论文副本。
已经存在许多聊天与文档应用的实现,比如ChatPaper (opens new window)、OpenChatPaper (opens new window)和DocsMind (opens new window)。但是,许多这些实现似乎过于复杂,只提供了基本的关键字搜索过滤器,过滤基于年份和主题等基本元数据的搜索结果。
因此,开发一个类似 ChatPDF 的应用来与数百万份学术/研究论文进行交互是有意义的。你可以使用自然语言与数据进行交流,结合语义和结构属性,例如:“什么是神经网络?请使用 Geoffrey Hinton 在 2018 年之后发表的文章。”
本文的主要目的是帮助你构建自己的 ChatPDF 应用,使用 LangChain 和 MyScale 与数百万份学术/研究论文进行交互。
创建这个应用大约需要 30 分钟的时间。
但在开始之前,让我们先看一下整个过程的下面的流程图:
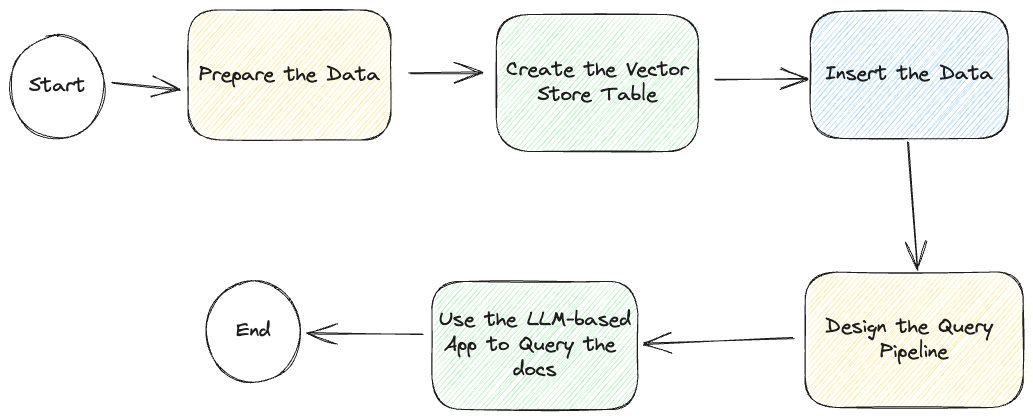
即使我们描述了如何开发这个基于 LLM 的聊天应用,我们在GitHub (opens new window)上有一个示例应用,包括对一个只读向量数据库 (opens new window)的访问,进一步简化了应用的创建过程。
# 准备数据
如图所示,第一步是准备数据。
我们建议你使用我们的开放数据库来创建这个应用。凭据在示例配置文件中:
.streamlit/secrets.toml。或者你可以按照下面的说明创建自己的数据库。创建数据库大约需要 20 分钟的时间。
我们从Macrocosm 网站 (opens new window)通过 Alexandria Index 获取了我们的数据:一个可用的摘要列表和 arXiv ID。使用这些数据并查询 arXiv Open API,我们可以显著提升查询体验,获取更丰富的元数据,包括年份、主题、发布日期、类别和作者。
我们已经在我们的公共数据库中准备好了数据。你可以使用下面的凭据直接使用 arxiv 数据集进行操作:
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
OPENAI_API_KEY = "<your-openai-key>"
或者你可以按照这里 (opens new window)的说明创建自己的数据集,使用 SQL 或 LangChain。
太好了。让我们继续下一步。
# LangChain
第二个选项是使用 LangChain 将数据插入到表中,以更好地控制数据插入过程。
将以下代码片段添加到你的应用代码中:
# ! unzstd data-*.jsonl.zstd
import json
from langchain.docstore.document import Document
def str2doc(_str):
j = json.loads(_str)
return Document(page_content=j['abstract'], metadata=j['metadata'])
with open('func_call_data.jsonl') as f:
docs = [str2doc(l) for l in f.readlines()]
# 设计查询流程
大多数基于 LLM 的应用程序需要一个自动化的查询流程,用于查询并返回查询的答案。
基于 LLM 的聊天应用通常需要在查询模型(LLM)之前检索参考文献。
让我们逐步了解应用程序如何回答用户的查询,如下图所示:
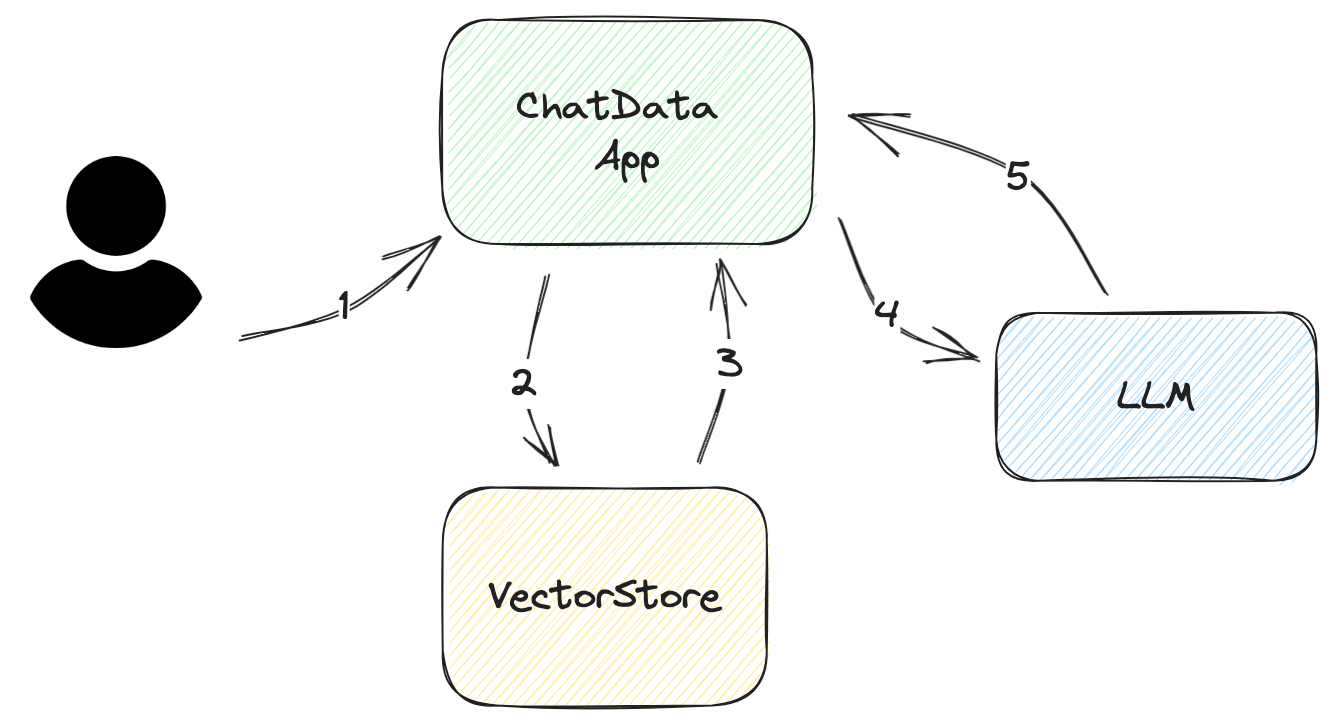
询问用户的输入/问题 这个输入应该尽可能简洁。在大多数情况下,它应该是最多几句话。
从用户的输入构建数据库查询 对于向量数据库来说,查询很简单。你只需要从向量数据库中提取相关的嵌入即可。然而,为了提高准确性,建议对查询进行过滤。
例如,假设用户只想要最新的论文,而不是返回的嵌入中的所有论文,但返回的嵌入包含了所有的研究论文。为了解决这个问题,你可以在查询中添加元数据过滤器,以过滤出正确的信息。
解析从 VectorStore 检索到的文档 从向量存储返回的数据不是 LLM 能够理解的原生格式。你必须解析它并将其插入到你的提示模板中。有时你需要向这些模板添加更多的元数据,比如创建日期、作者或文档类别。这些元数据将帮助 LLM 提高其答案的质量。
向 LLM 提问 只要你熟悉 LLM 的 API 并且正确设计了提示,这个过程就很简单。
获取答案 对于简单的应用程序来说,返回答案很简单。但是,如果问题很复杂,需要额外的努力来为用户提供更多的信息;例如,添加 LLM 的源数据。此外,通过向提示中添加参考编号,可以帮助你找到源数据,并通过避免重复内容(如文档标题)来减小提示的大小。
在实践中,LangChain 有一个很好的工作框架。我们使用以下函数来构建这个流程:
RetrievalQAWithSourcesChainSelfQueryRetriever
# SelfQueryRetriever
这个函数定义了向量存储和你的应用程序之间的交互。让我们深入了解一下自查询检索器的工作原理,如下图所示:
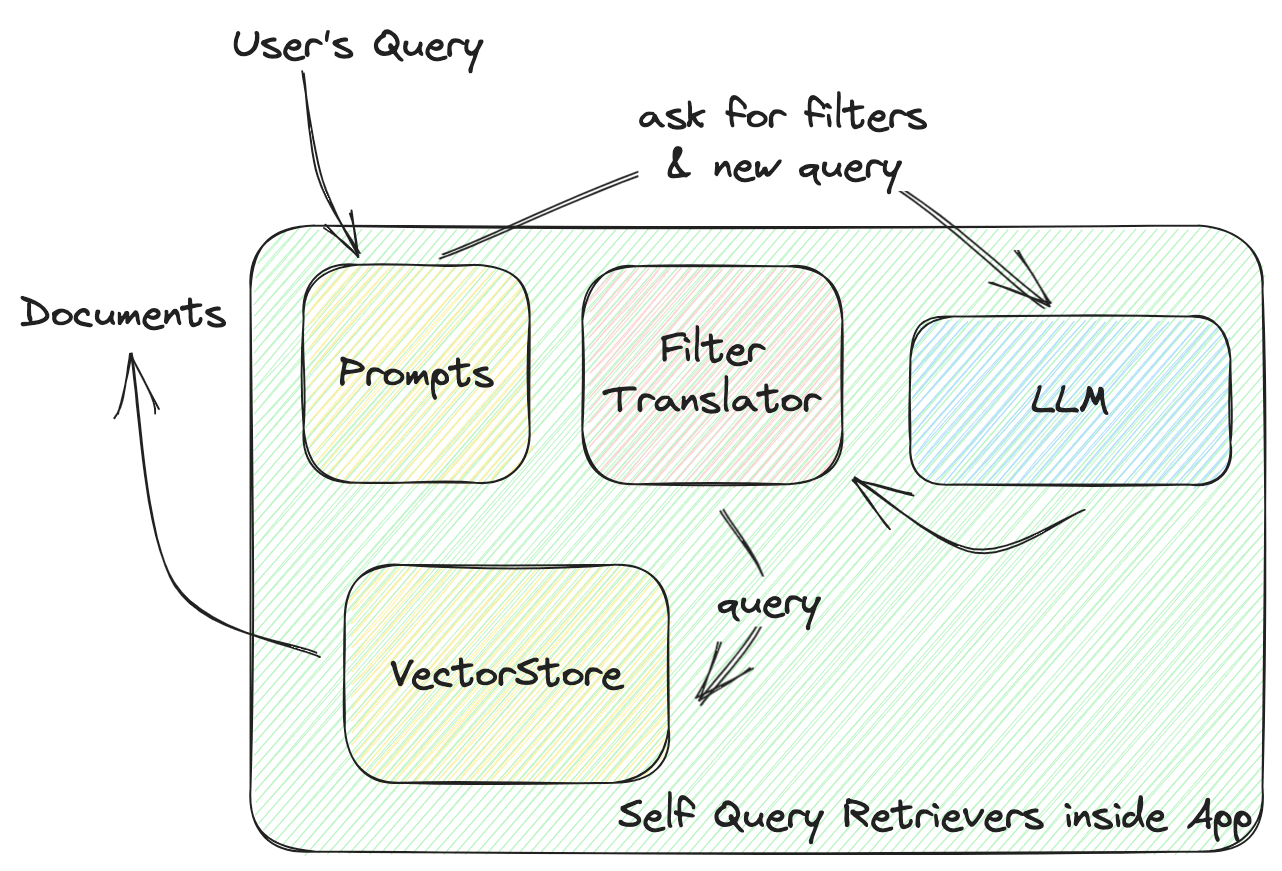
LangChain 的SelfQueryRetriever为每个 VectorStore 定义了一个通用的过滤器,包括几个comparators用于比较值和operators,将这些条件组合成一个过滤器。LLM 将根据这些comparators和operators生成一个过滤规则。所有的 VectorStore 提供者都将实现一个FilterTranslator,将给定的通用过滤器转换为调用 VectorStore 的正确参数。
LangChain 的通用解决方案为新的运算符、比较器和向量存储提供了一个完整的包。但是,你只能使用其中预定义的元素。
在提示过滤器的上下文中,MyScale 包含了更强大和灵活的过滤器。我们添加了更多的数据类型,如列表和时间戳,以及更多的函数,如字符串模式匹配和列表的CONTAIN比较器,为数据存储和查询设计提供了更多的选项。
我们为 LangChain 的自查询检索器做出了贡献,使其更加强大,从而提供了更多的自由度给 LLM 在设计查询时。
查看MyScale 如何使用元数据过滤器 (opens new window)。
以下是使用 LangChain 编写的代码:
from langchain.vectorstores import MyScale
from langchain.embeddings import HuggingFaceInstructEmbeddings
# 假设你的数据已经准备好在 MyScale Cloud 上
embeddings = HuggingFaceInstructEmbeddings()
doc_search = MyScale(embeddings)
# 定义元数据字段及其类型
# 描述很重要。这是 LLM 知道如何使用该元数据的地方。
metadata_field_info=[
AttributeInfo(
name="pubdate",
description="The year the paper is published",
type="timestamp",
),
AttributeInfo(
name="authors",
description="List of author names",
type="list[string]",
),
AttributeInfo(
name="title",
description="Title of the paper",
type="string",
),
AttributeInfo(
name="categories",
description="arxiv categories to this paper",
type="list[string]"
),
AttributeInfo(
name="length(categories)",
description="length of arxiv categories to this paper",
type="int"
),
]
# 现在使用 LLM、向量存储和你的元数据信息构建一个检索器
retriever = SelfQueryRetriever.from_llm(
OpenAI(openai_api_key=st.secrets['OPENAI_API_KEY'], temperature=0),
doc_search, "Scientific papers indexes with abstracts", metadata_field_info,
use_original_query=True)
# RetrievalQAWithSourcesChain
这个函数构建包含文档的提示。
数据应该被格式化为 LLM 可读的字符串,比如包含文档信息的 JSON 或 Markdown。
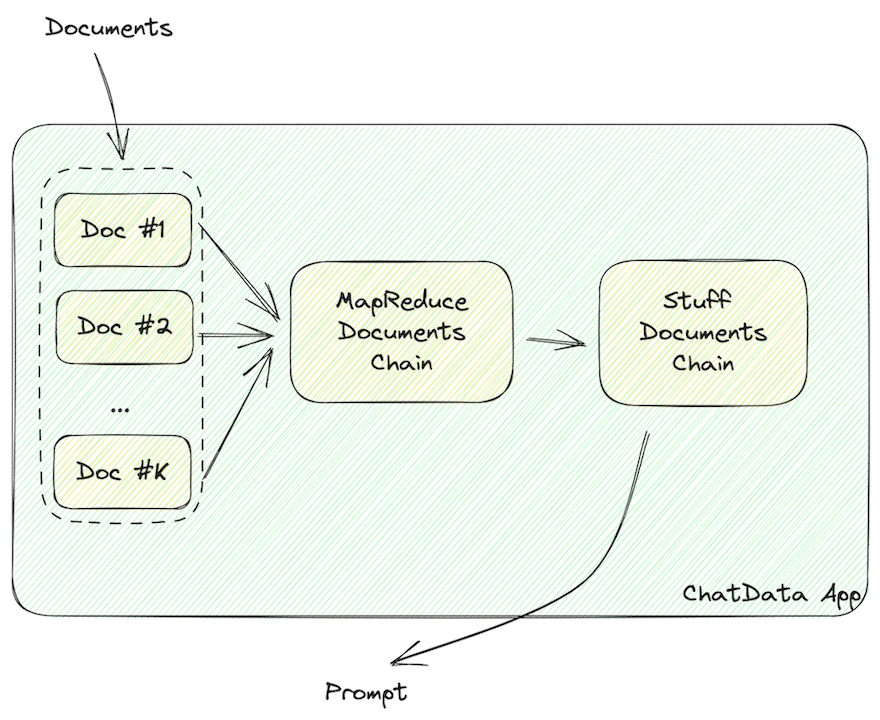
如上所示,一旦从向量存储中检索到文档数据,它必须被格式化为 LLM 可读的字符串,比如 JSON 或 Markdown。
LangChain 使用以下链来构建这些 LLM 可读的字符串:
MapReduceDocumentsChainStuffDocumentsChain
MapReduceDocumentChain收集向量存储返回的所有文档,并将它们标准化为一个标准格式。它将文档映射到一个提示模板,并将它们连接在一起。StuffDocumentChain在这些格式化的文档上工作,将它们作为上下文插入到任务描述的前缀和示例的后缀中。
将以下代码片段添加到你的应用程序代码中,这样你的应用程序将把向量存储的数据格式化为 LLM 可读的文档。
chain = RetrievalQAWithSourcesChain.from_llm(
llm=OpenAI(openai_api_key=st.secrets['OPENAI_API_KEY'], temperature=0.
retriever=retriever,
return_source_documents=True,)
# 运行链
有了这些组件,我们现在可以使用可扩展的向量存储搜索和回答用户的问题。
自己试试吧!
ret = st.session_state.chain(st.session_state.query, callbacks=[callback])
# 你可以在字段`answer`中找到 LLM 的答案
st.markdown(f"### Answer from LLM\n{ret['answer']}\n### References")
# 并且在`sources`和`source_documents`中找到源文档
docs = ret['source_documents']
响应不够?
# 添加回调函数
链的工作很好,但你可能会有一个抱怨:它需要更快!
是的,链会很慢,因为它会构建一个经过过滤的向量查询(一个 LLM 调用),从向量存储中检索数据并向 LLM 提问(另一个 LLM 调用)。因此,总执行时间大约为 10~20 秒。
别担心,LangChain 可以帮助你。它包含了Callbacks (opens new window),你可以使用它们来提高应用程序的响应性。在我们的示例中,我们添加了几个回调函数来更新进度条:
class ChatArXivAskCallBackHandler(StreamlitCallbackHandler):
def __init__(self) -> None:
# 当初始化这个回调时,你将有一个进度条
self.progress_bar = st.progress(value=0.0, text='Searching DB...')
self.status_bar = st.empty()
self.prog_value = 0.0
# 你可以使用链的名称来控制进度
self.prog_map = {
'langchain.chains.qa_with_sources.retrieval.RetrievalQAWithSourcesChain': 0.2,
'langchain.chains.combine_documents.map_reduce.MapReduceDocumentsChain': 0.4,
'langchain.chains.combine_documents.stuff.StuffDocumentsChain': 0.8
}
def on_llm_start(self, serialized, prompts, **kwargs) -> None:
pass
def on_text(self, text: str, **kwargs) -> None:
pass
def on_chain_start(self, serialized, inputs, **kwargs) -> None:
# 名称是一个列表,所以你可以将它们连接成字符串。
cid = '.'.join(serialized['id'])
if cid != 'langchain.chains.llm.LLMChain':
self.progress_bar.progress(value=self.prog_map[cid], text=f'Running Chain `{cid}`...')
self.prog_value = self.prog_map[cid]
else:
self.prog_value += 0.1
self.progress_bar.progress(value=self.prog_value, text=f'Running Chain `{cid}`...')
def on_chain_end(self, outputs, **kwargs) -> None:
pass
现在你的应用程序将有一个漂亮的进度条,就像我们的一样。

# 总结
这就是使用 LangChain 构建 LLM 应用的方法!
今天我们简要介绍了如何构建一个简单的 LLM 应用,该应用与 MyScale VectorStore 进行交互,并解释了如何在查询流程中使用链。
我们希望本文能够帮助你从头开始设计基于 LLM 的应用程序架构。
你也可以在我们的Discord 服务 (opens new window)上寻求帮助。无论是关于向量数据库、LLM 应用程序还是其他令人惊奇的东西,我们都很乐意帮助你。你也可以使用我们的开放数据库来构建自己的应用程序!我们相信你可以使用这个带有 MyScale 的自查询检索器构建更棒的应用程序!祝你编程愉快!
我们在下一篇文章中见!
 京公网安备 11010802042981号
京公网安备 11010802042981号