
# Chat Data App
![]()
Erstellen Sie in 30 Minuten eine ChatPDF-App über Millionen von Dokumenten mit LangChain und MyScale
Das Chatten mit GPT über ein einzelnes wissenschaftliches Papier ist relativ einfach, indem Sie das Dokument als Kontext für das Sprachmodell bereitstellen. Das Chatten mit Millionen von Forschungspapieren ist ebenfalls einfach... solange Sie die richtige Vektordatenbank wählen.
Große Sprachmodelle (LLM) sind leistungsstarke NLP-Tools. Einer der größten Vorteile von LLMs wie ChatGPT ist, dass Sie sie verwenden können, um Tools zu erstellen, mit denen Sie mit Dokumenten interagieren (oder chatten) können, z. B. mit PDF-Kopien von Forschungs- oder wissenschaftlichen Papieren, basierend auf ihren Themen und nicht auf anderen nicht verwandten Fragen.
Es gibt bereits viele Implementierungen von Chat-mit-Dokument-Apps, wie ChatPaper (opens new window), OpenChatPaper (opens new window) und DocsMind (opens new window). Viele dieser Implementierungen scheinen jedoch kompliziert zu sein und verfügen nur über einfache Suchfunktionen, die auf grundlegenden Metadaten wie Jahr und Thema basieren.
Daher macht es Sinn, eine ChatPDF-ähnliche App zu entwickeln, um mit Millionen von wissenschaftlichen / Forschungspapieren zu interagieren. Sie können mit den Daten in natürlicher Sprache chatten und sowohl semantische als auch strukturelle Attribute kombinieren, z. B. "Was ist ein neuronales Netzwerk? Bitte verwenden Sie Artikel, die von Geoffrey Hinton nach 2018 veröffentlicht wurden."
Der Hauptzweck dieses Artikels besteht darin, Ihnen dabei zu helfen, Ihre eigene ChatPDF-App zu erstellen, mit der Sie mit Millionen von wissenschaftlichen / Forschungspapieren unter Verwendung von LangChain und MyScale interagieren (chatten) können.
Diese App sollte etwa 30 Minuten dauern, um erstellt zu werden.
Aber bevor wir anfangen, werfen wir einen Blick auf das folgende diagrammatische Workflow des gesamten Prozesses:
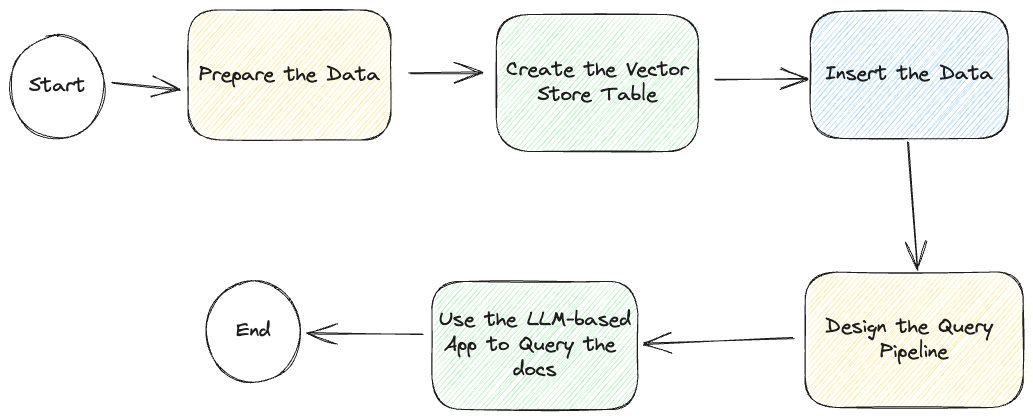
Obwohl wir beschreiben, wie diese LLM-basierte Chat-App entwickelt wird, haben wir eine Beispiel-App auf GitHub (opens new window), einschließlich Zugriff auf eine schreibgeschützte Vektordatenbank (opens new window), die den App-Erstellungsprozess weiter vereinfacht.
# Daten vorbereiten
Wie in diesem Bild beschrieben, ist der erste Schritt, die Daten vorzubereiten.
Wir empfehlen Ihnen, unsere öffentliche Datenbank für diese App zu verwenden. Die Anmeldeinformationen finden Sie in der Beispielkonfiguration:
.streamlit/secrets.toml. Oder Sie können den Anweisungen unten folgen, um Ihre eigene Datenbank zu erstellen. Die Erstellung der Datenbank dauert etwa 20 Minuten.
Wir haben unsere Daten bezogen: eine verwendbare Liste von Abstracts und arXiv-IDs aus dem Alexandria Index über die Macrocosm-Website (opens new window). Mit diesen Daten und der Abfrage der arXiv Open API können wir das Abfrageerlebnis erheblich verbessern, indem wir eine viel reichhaltigere Metadatenmenge abrufen, einschließlich Jahr, Thema, Veröffentlichungsdatum, Kategorie und Autor.
Wir haben die Daten in unserem öffentlichen Datenbankzugriff vorbereitet. Sie können die folgenden Anmeldeinformationen verwenden, um direkt mit dem arxiv-Datensatz zu arbeiten:
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
OPENAI_API_KEY = "<your-openai-key>"
Oder Sie können den Anweisungen hier (opens new window) folgen, um Ihren eigenen Datensatz in SQL oder LangChain zu erstellen.
Großartig. Gehen wir zum nächsten Schritt über.
# LangChain
Die zweite Option besteht darin, die Daten mithilfe von LangChain in die Tabelle einzufügen, um eine bessere Kontrolle über den Daten-Einführungsprozess zu haben.
Fügen Sie den folgenden Codeausschnitt zum Code Ihrer App hinzu:
# ! unzstd data-*.jsonl.zstd
import json
from langchain.docstore.document import Document
def str2doc(_str):
j = json.loads(_str)
return Document(page_content=j['abstract'], metadata=j['metadata'])
with open('func_call_data.jsonl') as f:
docs = [str2doc(l) for l in f.readlines()]
# Entwerfen Sie die Abfrage-Pipeline
Die meisten LLM-basierten Anwendungen benötigen eine automatisierte Pipeline zum Abfragen und Zurückgeben einer Antwort auf die Abfrage.
Chat-mit-LLM-Apps müssen in der Regel Referenzdokumente abrufen, bevor sie ihre Modelle (LLMs) abfragen.
Schauen wir uns den schrittweisen Workflow an, der beschreibt, wie die App die Fragen des Benutzers beantwortet, wie im folgenden Diagramm dargestellt:
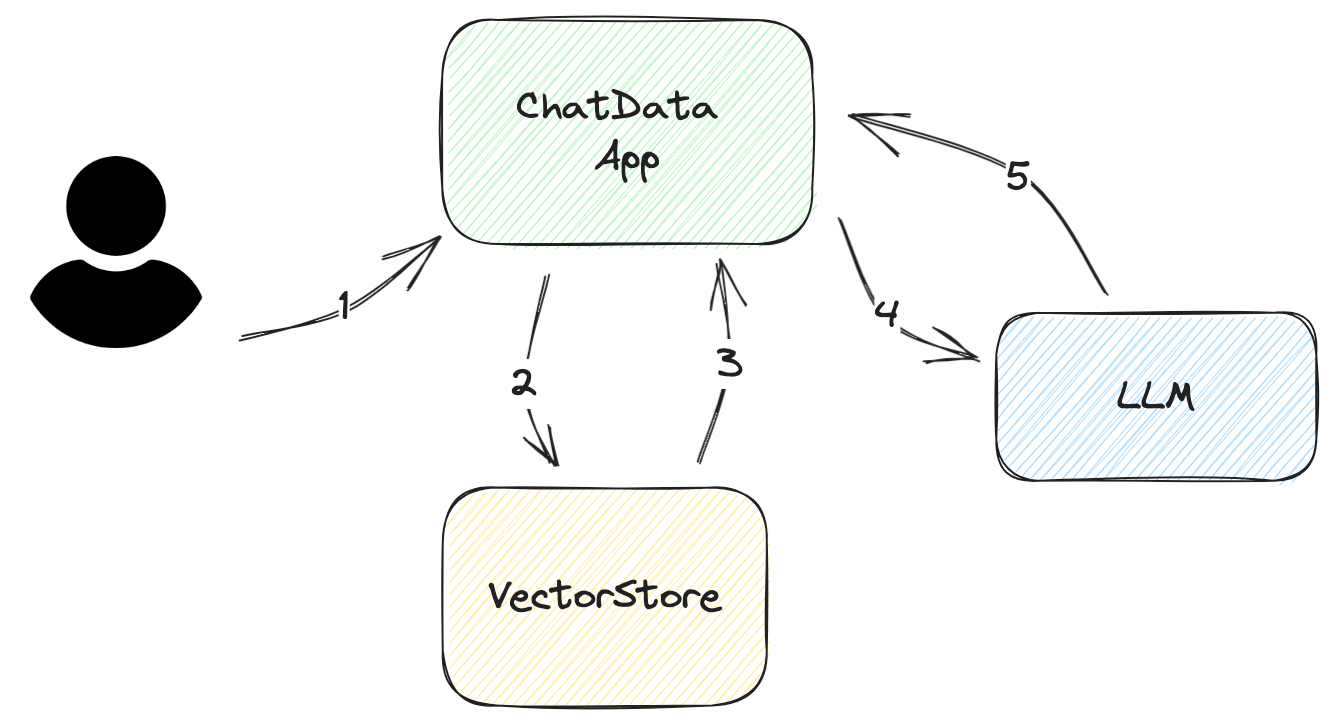
Fragen Sie nach der Eingabe/Fragen des Benutzers Diese Eingabe sollte so prägnant wie möglich sein. In den meisten Fällen sollte sie höchstens einige Sätze lang sein.
Erstellen Sie eine DB-Abfrage aus der Eingabe/Fragen des Benutzers Die Abfrage ist einfach für Vektordatenbanken. Alles, was Sie tun müssen, ist, die relevante Einbettung aus der Vektordatenbank zu extrahieren. Für eine bessere Genauigkeit ist es jedoch ratsam, Ihre Abfrage zu filtern.
Angenommen, der Benutzer möchte nur die neuesten Papiere anstelle aller Papiere in der zurückgegebenen Einbettung, aber die zurückgegebene Einbettung enthält alle Forschungspapiere. Um diese Herausforderung zu lösen, können Sie Metadatenfilter zur Abfrage hinzufügen, um die richtigen Informationen herauszufiltern.
Analysieren Sie die abgerufenen Dokumente aus VectorStore Die aus dem Vektorstore zurückgegebenen Daten liegen nicht in einem nativen Format vor, das das LLM versteht. Sie müssen sie analysieren und in Ihre Prompt-Vorlagen einfügen. Manchmal müssen Sie diesen Vorlagen weitere Metadaten hinzufügen, wie das Erstellungsdatum, die Autoren oder die Dokumentenkategorien. Diese Metadaten helfen dem LLM, die Qualität seiner Antwort zu verbessern.
Fragen Sie das LLM Dieser Prozess ist einfach, solange Sie mit der API des LLM vertraut sind und geeignete Prompts entworfen haben.
Holen Sie die Antwort ab Die Rückgabe der Antwort ist für einfache Anwendungen einfach. Wenn die Frage jedoch komplex ist, ist zusätzlicher Aufwand erforderlich, um dem Benutzer weitere Informationen zur Verfügung zu stellen. Beispielsweise kann das Hinzufügen von Referenznummern zum Prompt helfen, die Quelle zu finden und die Größe des Prompts zu reduzieren, indem wiederholte Inhalte vermieden werden, wie der Titel des Dokuments.
In der Praxis bietet LangChain ein gutes Framework, mit dem Sie arbeiten können. Wir haben die folgenden Funktionen verwendet, um diese Pipeline aufzubauen:
RetrievalQAWithSourcesChainSelfQueryRetriever
# SelfQueryRetriever
Diese Funktion definiert die Interaktion zwischen dem VectorStore und Ihrer App. Tauchen wir tiefer ein, wie ein Self-Query-Retriever funktioniert, wie im folgenden Diagramm dargestellt:
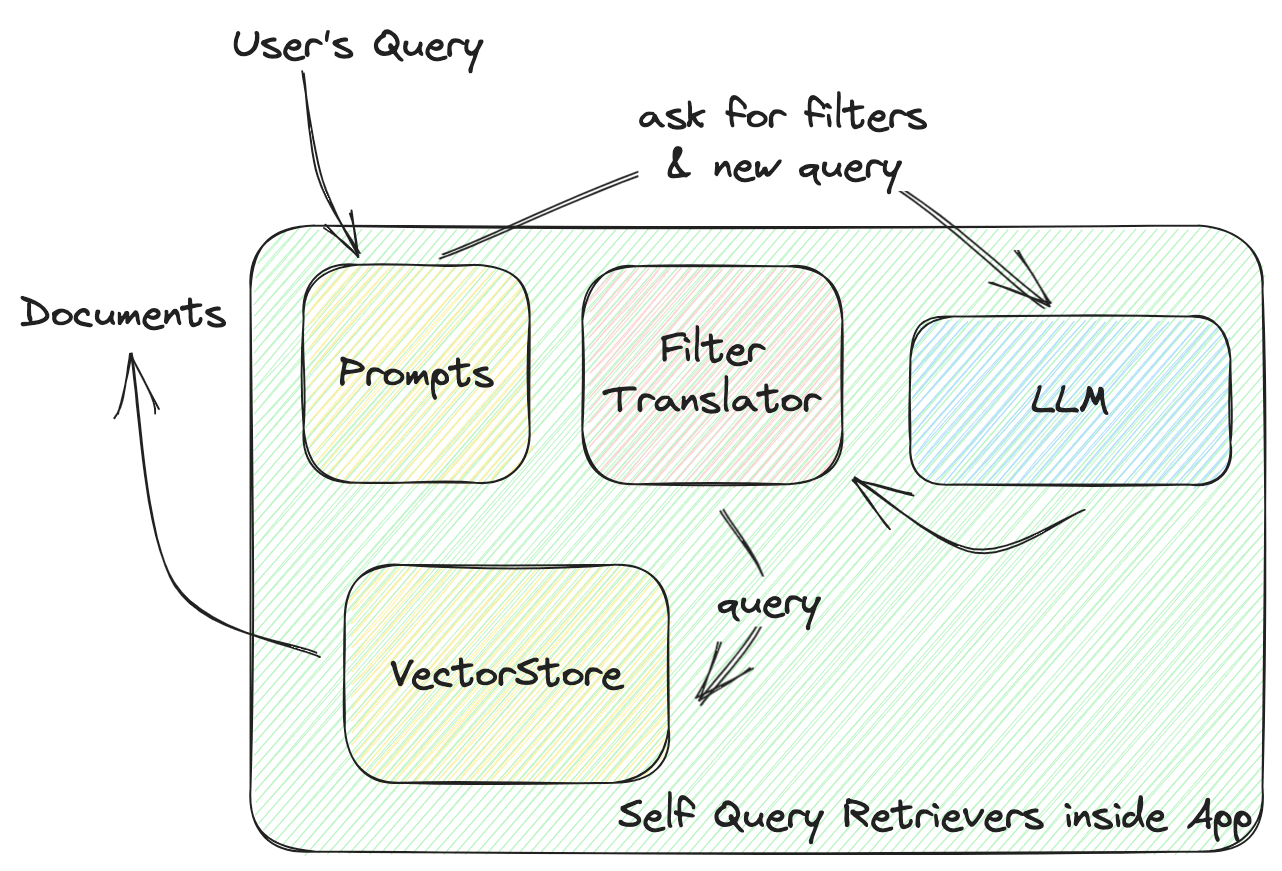
LangChains SelfQueryRetriever definiert einen universellen Filter für jeden VectorStore, einschließlich mehrerer Vergleicher zum Vergleichen von Werten und Operatoren, die diese Bedingungen kombinieren, um einen Filter zu bilden. Das LLM generiert eine Filterregel basierend auf diesen Vergleichern und Operatoren. Alle VectorStore-Anbieter implementieren einen FilterTranslator, um den gegebenen universellen Filter in die richtigen Argumente zu übersetzen, die den VectorStore aufrufen.
LangChains universelle Lösung bietet ein vollständiges Paket für neue Operatoren, Vergleicher und VectorStore-Anbieter. Sie sind jedoch auf die vordefinierten Elemente darin beschränkt.
Im Kontext des Prompt-Filters enthält MyScale leistungsstärkere und flexiblere Filter. Wir haben weitere Datentypen wie Listen und Zeitstempel sowie weitere Funktionen wie die Musterübereinstimmung von Zeichenfolgen und CONTAIN-Vergleicher für Listen hinzugefügt, um mehr Optionen für die Datenspeicherung und die Abfragegestaltung zu bieten.
Wir haben zu den Self-Query-Retrievers von LangChain beigetragen, um sie leistungsfähiger zu machen. Dadurch werden Self-Query-Retrievers bereitgestellt, die dem LLM mehr Freiheit bei der Gestaltung der Abfrage bieten.
Schauen Sie sich an, was MyScale mit Metadatenfiltern noch tun kann (opens new window).
Hier ist der Code dafür, der mit LangChain geschrieben wurde:
from langchain.vectorstores import MyScale
from langchain.embeddings import HuggingFaceInstructEmbeddings
# Angenommen, Ihre Daten sind auf MyScale Cloud bereit
embeddings = HuggingFaceInstructEmbeddings()
doc_search = MyScale(embeddings)
# Definieren Sie Metadatenfelder und ihre Typen
# Beschreibungen sind wichtig. Hier erfährt das LLM, wie es diese Metadaten verwenden kann.
metadata_field_info=[
AttributeInfo(
name="pubdate",
description="The year the paper is published",
type="timestamp",
),
AttributeInfo(
name="authors",
description="List of author names",
type="list[string]",
),
AttributeInfo(
name="title",
description="Title of the paper",
type="string",
),
AttributeInfo(
name="categories",
description="arxiv categories to this paper",
type="list[string]"
),
AttributeInfo(
name="length(categories)",
description="length of arxiv categories to this paper",
type="int"
),
]
# Erstellen Sie jetzt einen Retriever mit LLM, einem Vektorstore und Ihren Metadateninformationen
retriever = SelfQueryRetriever.from_llm(
OpenAI(openai_api_key=st.secrets['OPENAI_API_KEY'], temperature=0),
doc_search, "Scientific papers indexes with abstracts", metadata_field_info,
use_original_query=True)
# RetrievalQAWithSourcesChain
Diese Funktion erstellt die Prompts, die die Dokumente enthalten.
Die Daten sollten in LLM-lesbare Zeichenketten formatiert sein, wie JSON oder Markdown, die die Informationen des Dokuments enthalten.
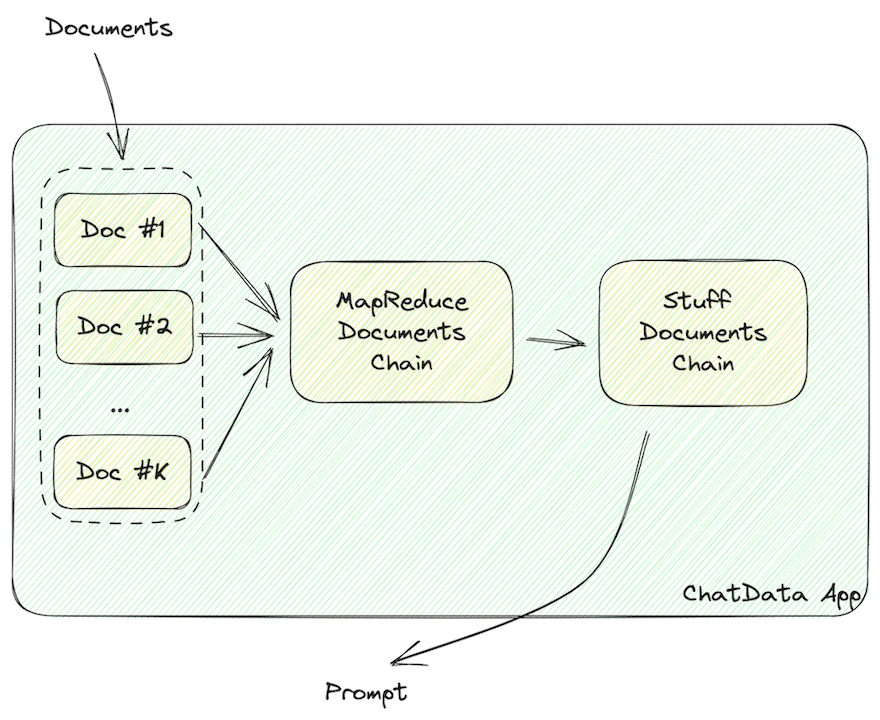
Wie oben hervorgehoben, müssen die abgerufenen Dokumentdaten in LLM-lesbare Zeichenketten formatiert werden, wie JSON oder Markdown.
LangChain verwendet die folgenden Chains, um diese LLM-lesbaren Zeichenketten zu erstellen:
MapReduceDocumentsChainStuffDocumentsChain
MapReduceDocumentChain sammelt alle Dokumente, die der Vektorstore zurückgibt, und normalisiert sie in ein standardisiertes Format. Es ordnet die Dokumente einer Prompt-Vorlage zu und fügt sie zusammen. StuffDocumentChain arbeitet an diesen formatierten Dokumenten und fügt sie als Kontext mit Aufgabenbeschreibungen als Präfix und Beispielen als Suffixe ein.
Fügen Sie den folgenden Codeausschnitt zum Code Ihrer App hinzu, damit Ihre App die Daten des Vektorstores in LLM-lesbare Dokumente formatiert.
chain = RetrievalQAWithSourcesChain.from_llm(
llm=OpenAI(openai_api_key=st.secrets['OPENAI_API_KEY'], temperature=0.
retriever=retriever,
return_source_documents=True,)
# Führen Sie die Chain aus
Mit diesen Komponenten können wir jetzt mit einem skalierbaren Vektorstore nach den Fragen des Benutzers suchen und sie beantworten.
Probieren Sie es selbst aus!
ret = st.session_state.chain(st.session_state.query, callbacks=[callback])
# Sie können die Antwort vom LLM im Feld `answer` finden
st.markdown(f"### Answer from LLM\n{ret['answer']}\n### References")
# und Quelldokumente in `sources` und `source_documents`
docs = ret['source_documents']
Nicht reaktionsschnell?
# Fügen Sie Callbacks hinzu
Die Chain funktioniert einwandfrei, aber Sie könnten eine Beschwerde haben: Sie muss schneller sein!
Ja, die Chain wird langsam sein, da sie eine gefilterte Vektorabfrage erstellt (ein LLM-Aufruf), Daten aus dem VectorStore abruft und das LLM befragt (ein weiterer LLM-Aufruf). Infolgedessen beträgt die Gesamtausführungszeit etwa 10-20 Sekunden.
Keine Sorge, LangChain hat Sie abgedeckt. Es enthält Callbacks (opens new window), die Sie verwenden können, um die Reaktionsfähigkeit Ihrer App zu erhöhen. In unserem Beispiel haben wir mehrere Callback-Funktionen hinzugefügt, um eine Fortschrittsanzeige zu aktualisieren:
class ChatArXivAskCallBackHandler(StreamlitCallbackHandler):
def __init__(self) -> None:
# Sie haben eine Fortschrittsanzeige, wenn dieser Callback initialisiert wird
self.progress_bar = st.progress(value=0.0, text='Datenbank wird durchsucht...')
self.status_bar = st.empty()
self.prog_value = 0.0
# Sie können Chain-Namen verwenden, um den Fortschritt zu steuern
self.prog_map = {
'langchain.chains.qa_with_sources.retrieval.RetrievalQAWithSourcesChain': 0.2,
'langchain.chains.combine_documents.map_reduce.MapReduceDocumentsChain': 0.4,
'langchain.chains.combine_documents.stuff.StuffDocumentsChain': 0.8
}
def on_llm_start(self, serialized, prompts, **kwargs) -> None:
pass
def on_text(self, text: str, **kwargs) -> None:
pass
def on_chain_start(self, serialized, inputs, **kwargs) -> None:
# der Name ist in einer Liste, sodass Sie sie zu Zeichenketten verbinden können.
cid = '.'.join(serialized['id'])
if cid != 'langchain.chains.llm.LLMChain':
self.progress_bar.progress(value=self.prog_map[cid], text=f'Running Chain `{cid}`...')
self.prog_value = self.prog_map[cid]
else:
self.prog_value += 0.1
self.progress_bar.progress(value=self.prog_value, text=f'Running Chain `{cid}`...')
def on_chain_end(self, outputs, **kwargs) -> None:
pass
Jetzt hat Ihre App eine hübsche Fortschrittsanzeige wie unsere.

# Zusammenfassung
So wird eine LLM-App mit LangChain erstellt!
Heute haben wir einen kurzen Überblick darüber gegeben, wie man eine einfache LLM-App erstellt, die mit dem MyScale VectorStore chattet, und erklärt, wie man Chains in der Abfrage-Pipeline verwendet.
Wir hoffen, dass Ihnen dieser Artikel hilft, wenn Sie Ihre LLM-basierte App-Architektur von Grund auf entwerfen.
Sie können auch auf unserem Discord-Server (opens new window) um Hilfe bitten. Wir helfen Ihnen gerne weiter, sei es bei Vektordatenbanken, LLM-Apps oder anderen fantastischen Dingen. Sie können auch unsere öffentliche Datenbank verwenden, um Ihre eigenen Apps zu erstellen! Wir sind der Meinung, dass Sie mit diesem Self-Query-Retriever mit MyScale noch beeindruckendere Apps erstellen können! Viel Spaß beim Coden!
Wir sehen uns im nächsten Artikel!