
# Aplicación de Datos de Chat
![]()
Construye una aplicación de ChatPDF sobre millones de documentos con LangChain y MyScale en 30 minutos
Chatear con GPT sobre un solo artículo académico es relativamente sencillo al proporcionar el documento como contexto del modelo de lenguaje. Chatear con millones de artículos de investigación también es simple... siempre y cuando elijas la base de datos vectorial correcta.
Los modelos de lenguaje grandes (LLM) son herramientas poderosas de procesamiento del lenguaje natural (NLP). Uno de los beneficios más significativos de los LLM, como ChatGPT, es que puedes utilizarlos para construir herramientas que te permitan interactuar (o chatear) con documentos, como copias en PDF de artículos de investigación o académicos, basándote en sus temas y no en otras preguntas no relacionadas.
Ya existen muchas implementaciones de aplicaciones de chat con documentos, como ChatPaper (opens new window), OpenChatPaper (opens new window) y DocsMind (opens new window). Sin embargo, muchas de estas implementaciones parecen complicadas, con utilidades de búsqueda simplistas que solo ofrecen búsquedas básicas de palabras clave filtrando por metadatos básicos como el año y el tema.
Por lo tanto, tiene sentido desarrollar una aplicación similar a ChatPDF para interactuar con millones de artículos de investigación/académicos. Puedes chatear con los datos en lenguaje natural combinando atributos semánticos y estructurales, por ejemplo: "¿Qué es una red neuronal? Por favor, utiliza artículos publicados por Geoffrey Hinton después de 2018".
El propósito principal de este artículo es ayudarte a construir tu propia aplicación de ChatPDF que te permita interactuar (chatear) con millones de artículos de investigación/académicos utilizando LangChain y MyScale.
Esta aplicación debería tardar unos 30 minutos en crearse.
Pero antes de empezar, echemos un vistazo al siguiente diagrama del flujo de trabajo de todo el proceso:
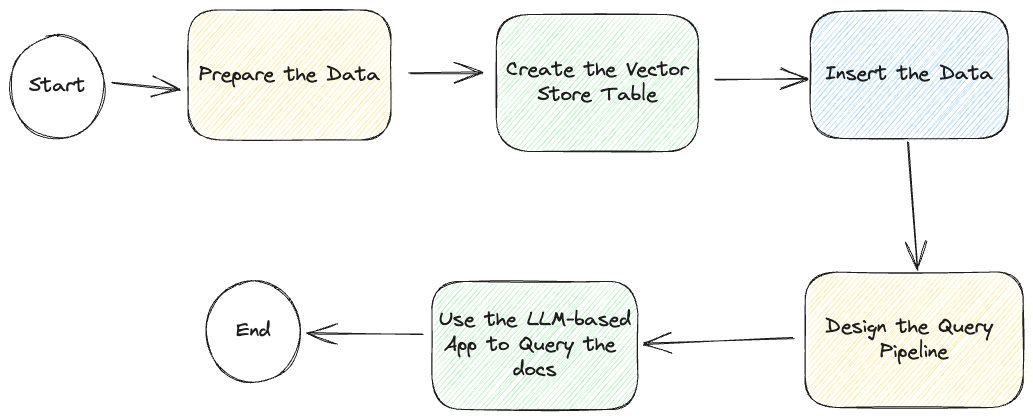
Aunque describimos cómo desarrollar esta aplicación de chat basada en LLM, tenemos una aplicación de muestra en GitHub (opens new window), que incluye acceso a una base de datos vectorial de solo lectura (opens new window), simplificando aún más el proceso de creación de la aplicación.
# Preparar los datos
Como se describe en esta imagen, el primer paso es preparar los datos.
Te recomendamos que utilices nuestra base de datos abierta para esta aplicación. Las credenciales se encuentran en la configuración de ejemplo:
.streamlit/secrets.toml. O puedes seguir las instrucciones a continuación para crear tu propia base de datos. Se tarda unos 20 minutos en crear la base de datos.
Hemos obtenido nuestros datos: una lista utilizable de resúmenes e identificadores de arXiv del Índice de Alejandría a través del sitio web de Macrocosm (opens new window). Utilizando estos datos e interrogando la API abierta de arXiv, podemos mejorar significativamente la experiencia de consulta al recuperar un conjunto de metadatos mucho más rico, que incluye el año, el tema, la fecha de publicación, la categoría y el autor.
Hemos preparado los datos en nuestro acceso público a la base de datos. Puedes utilizar las credenciales a continuación para jugar directamente con el conjunto de datos de arXiv:
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
OPENAI_API_KEY = "<your-openai-key>"
O puedes seguir las instrucciones aquí (opens new window) para crear tu propio conjunto de datos, en SQL o LangChain.
Genial. Pasemos al siguiente paso.
# LangChain
La segunda opción es insertar los datos en la tabla utilizando LangChain para tener un mejor control sobre el proceso de inserción de datos.
Agrega el siguiente fragmento de código al código de tu aplicación:
# ! unzstd data-*.jsonl.zstd
import json
from langchain.docstore.document import Document
def str2doc(_str):
j = json.loads(_str)
return Document(page_content=j['abstract'], metadata=j['metadata'])
with open('func_call_data.jsonl') as f:
docs = [str2doc(l) for l in f.readlines()]
# Diseñar el Pipeline de Consulta
La mayoría de las aplicaciones basadas en LLM necesitan un pipeline automatizado para realizar consultas y devolver una respuesta a la consulta.
Las aplicaciones de chat con LLM generalmente deben recuperar documentos de referencia antes de consultar a sus modelos (LLMs).
Veamos el flujo de trabajo paso a paso que describe cómo la aplicación responde a las consultas del usuario, como se ilustra en el siguiente diagrama:
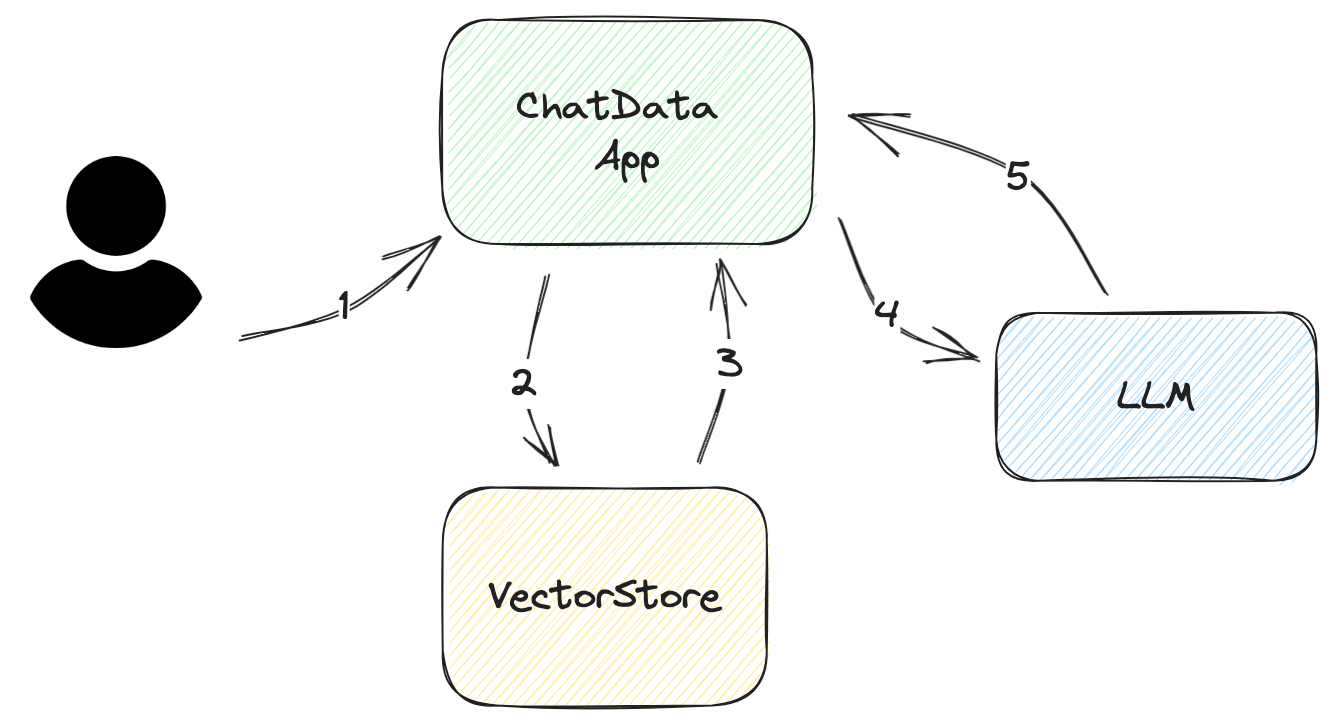
Pedir la entrada/preguntas del usuario Esta entrada debe ser lo más concisa posible. En la mayoría de los casos, debería ser como máximo varias frases.
Construir una consulta a la base de datos a partir de la entrada del usuario La consulta es simple para las bases de datos vectoriales. Todo lo que necesitas hacer es extraer el embedding relevante de la base de datos vectorial. Sin embargo, para obtener una mayor precisión, es recomendable filtrar la consulta.
Por ejemplo, supongamos que el usuario solo quiere los artículos más recientes en lugar de todos los artículos en el embedding devuelto, pero el embedding devuelto incluye todos los artículos de investigación. Para resolver este desafío, puedes agregar filtros de metadatos a la consulta para filtrar la información correcta.
Analizar los documentos recuperados de VectorStore Los datos devueltos por la base de datos vectorial no están en un formato nativo que el LLM entienda. Debes analizarlos e insertarlos en tus plantillas de consulta. A veces necesitas agregar más metadatos a estas plantillas, como la fecha de creación, los autores o las categorías del documento. Estos metadatos ayudarán al LLM a mejorar la calidad de su respuesta.
Preguntar al LLM Este proceso es sencillo siempre y cuando estés familiarizado con la API del LLM y hayas diseñado correctamente las plantillas.
Obtener la respuesta Devolver la respuesta es sencillo para aplicaciones simples. Pero si la pregunta es compleja, se requiere un esfuerzo adicional para proporcionar más información al usuario; por ejemplo, agregar los datos fuente del LLM. Además, agregar números de referencia a la consulta puede ayudarte a encontrar la fuente y reducir el tamaño de la consulta evitando repetir contenido, como el título del documento.
En la práctica, LangChain tiene un buen marco de trabajo. Utilizamos las siguientes funciones para construir este pipeline:
RetrievalQAWithSourcesChainSelfQueryRetriever
# SelfQueryRetriever
Esta función define la interacción entre VectorStore y tu aplicación. Profundicemos en cómo funciona un recuperador de autoconsulta, como se ilustra en el siguiente diagrama:
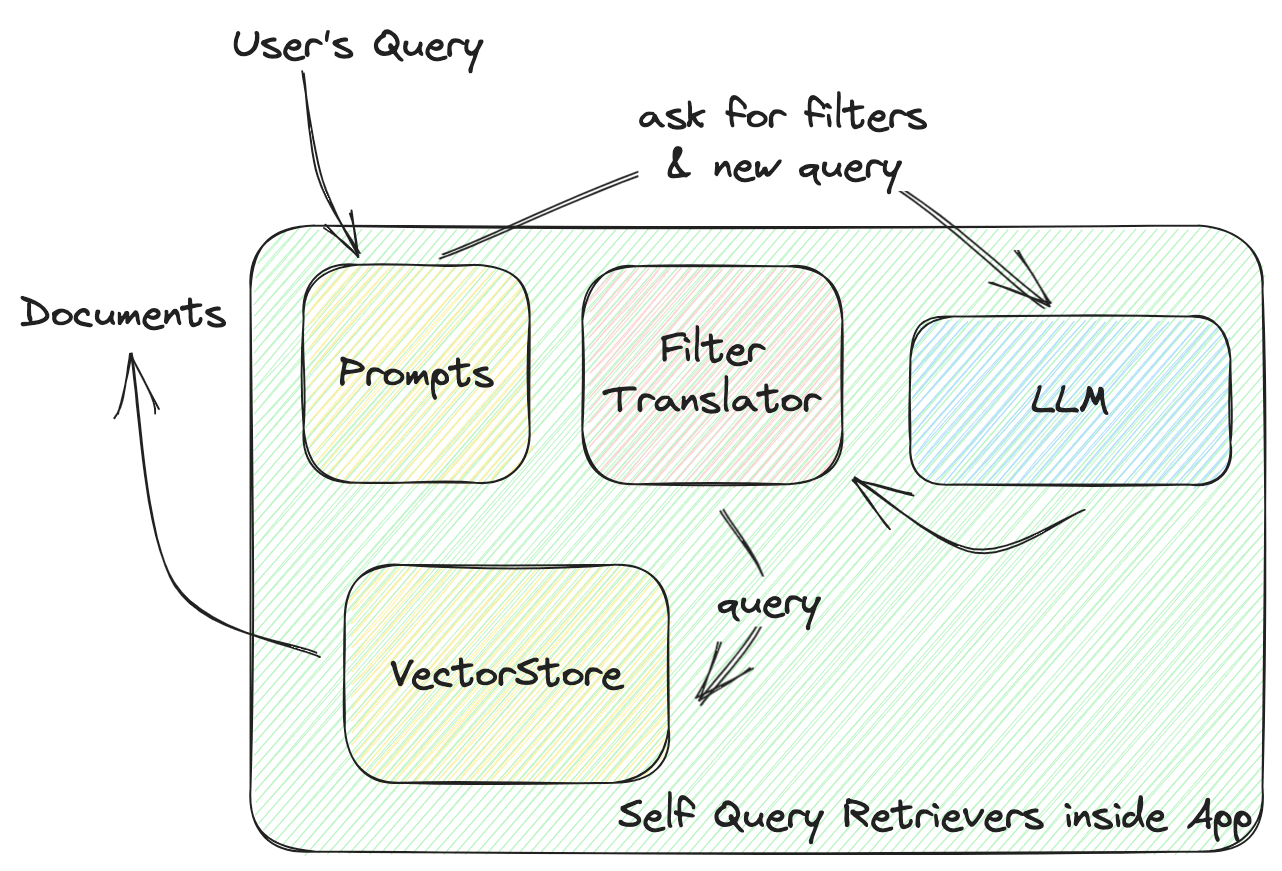
El recuperador de autoconsulta de LangChain (SelfQueryRetriever) define un filtro universal para todas las bases de datos vectoriales, que incluye varios comparadores para comparar valores y operadores para combinar estas condiciones y formar un filtro. El LLM generará una regla de filtro basada en estos comparadores y operadores. Todos los proveedores de bases de datos vectoriales implementarán un FilterTranslator para traducir el filtro universal dado a los argumentos correctos que llamen a la base de datos vectorial.
La solución universal de LangChain proporciona un paquete completo para nuevos operadores, comparadores y proveedores de bases de datos vectoriales. Sin embargo, estás limitado a los elementos predefinidos que contiene.
En el contexto del filtro de consulta, MyScale incluye filtros más potentes y flexibles. Hemos añadido más tipos de datos, como listas y marcas de tiempo, y más funciones, como coincidencia de patrones de cadena y comparadores CONTAIN para listas, lo que ofrece más opciones para el almacenamiento y el diseño de consultas de datos.
Contribuimos a los recuperadores de autoconsulta de LangChain para hacerlos más potentes, lo que resulta en recuperadores de autoconsulta que proporcionan más libertad al LLM al diseñar la consulta.
Mira qué más puede hacer MyScale con los filtros de metadatos (opens new window).
Aquí tienes el código para ello, escrito utilizando LangChain:
from langchain.vectorstores import MyScale
from langchain.embeddings import HuggingFaceInstructEmbeddings
# Suponiendo que tus datos están listos en MyScale Cloud
embeddings = HuggingFaceInstructEmbeddings()
doc_search = MyScale(embeddings)
# Define los campos de metadatos y sus tipos
# Las descripciones son importantes. Ahí es donde el LLM sabe cómo utilizar esos metadatos.
metadata_field_info=[
AttributeInfo(
name="pubdate",
description="The year the paper is published",
type="timestamp",
),
AttributeInfo(
name="authors",
description="List of author names",
type="list[string]",
),
AttributeInfo(
name="title",
description="Title of the paper",
type="string",
),
AttributeInfo(
name="categories",
description="arxiv categories to this paper",
type="list[string]"
),
AttributeInfo(
name="length(categories)",
description="length of arxiv categories to this paper",
type="int"
),
]
# Ahora construye un recuperador con LLM, una base de datos vectorial y la información de tus metadatos
retriever = SelfQueryRetriever.from_llm(
OpenAI(openai_api_key=st.secrets['OPENAI_API_KEY'], temperature=0),
doc_search, "Scientific papers indexes with abstracts", metadata_field_info,
use_original_query=True)
# RetrievalQAWithSourcesChain
Esta función construye las consultas que contienen los documentos.
Los datos deben formatearse en cadenas legibles por el LLM, como JSON o Markdown, que contengan la información del documento.
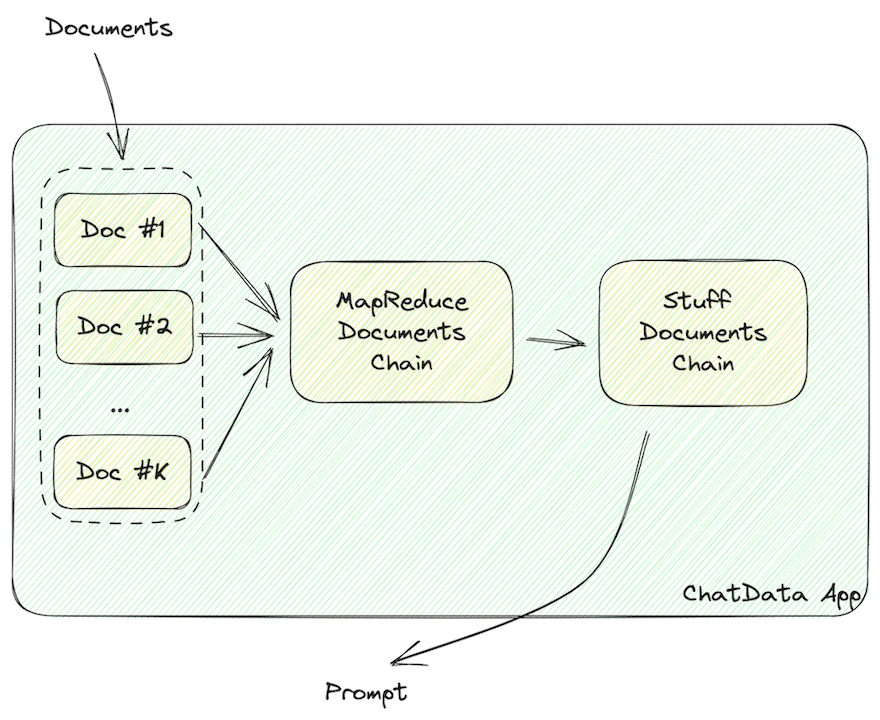
Como se destaca arriba, una vez que se han recuperado los datos del vector store, deben formatearse en cadenas legibles por el LLM, como JSON o Markdown.
LangChain utiliza las siguientes cadenas para construir estas cadenas legibles por el LLM:
MapReduceDocumentsChainStuffDocumentsChain
MapReduceDocumentChain recopila todos los documentos que devuelve la base de datos vectorial y los normaliza en un formato estándar. Mapea los documentos a una plantilla de consulta y los concatena. StuffDocumentChain trabaja en esos documentos formateados, insertándolos como contexto con descripciones de tareas como prefijos y ejemplos como sufijos.
Agrega el siguiente fragmento de código al código de tu aplicación para que tu aplicación formatee los datos del vector store en documentos legibles por el LLM.
chain = RetrievalQAWithSourcesChain.from_llm(
llm=OpenAI(openai_api_key=st.secrets['OPENAI_API_KEY'], temperature=0.
retriever=retriever,
return_source_documents=True,)
# Ejecutar la Cadena
Con estos componentes, ahora podemos buscar y responder a las preguntas del usuario con una base de datos vectorial escalable.
¡Pruébalo tú mismo!
ret = st.session_state.chain(st.session_state.query, callbacks=[callback])
# Puedes encontrar la respuesta del LLM en el campo `answer`
st.markdown(f"### Respuesta del LLM\n{ret['answer']}\n### Referencias")
# y los documentos fuente en `sources` y `source_documents`
docs = ret['source_documents']
¿No responde?
# Añadir Callbacks
La cadena funciona bien, pero podrías tener una queja: ¡Necesita ser más rápida!
Sí, la cadena será lenta, ya que construirá una consulta vectorial filtrada (una llamada al LLM), recuperará datos de VectorStore y preguntará al LLM (otra llamada al LLM). En consecuencia, el tiempo total de ejecución será de aproximadamente 10-20 segundos.
No te preocupes; LangChain te respalda. Incluye Callbacks (opens new window) que puedes utilizar para aumentar la capacidad de respuesta de tu aplicación. En nuestro ejemplo, hemos añadido varias funciones de callback para actualizar una barra de progreso:
class ChatArXivAskCallBackHandler(StreamlitCallbackHandler):
def __init__(self) -> None:
# Tendrás una barra de progreso cuando se inicialice este callback
self.progress_bar = st.progress(value=0.0, text='Buscando en la base de datos...')
self.status_bar = st.empty()
self.prog_value = 0.0
# Puedes utilizar los nombres de las cadenas para controlar el progreso
self.prog_map = {
'langchain.chains.qa_with_sources.retrieval.RetrievalQAWithSourcesChain': 0.2,
'langchain.chains.combine_documents.map_reduce.MapReduceDocumentsChain': 0.4,
'langchain.chains.combine_documents.stuff.StuffDocumentsChain': 0.8
}
def on_llm_start(self, serialized, prompts, **kwargs) -> None:
pass
def on_text(self, text: str, **kwargs) -> None:
pass
def on_chain_start(self, serialized, inputs, **kwargs) -> None:
# el nombre está en una lista, así que puedes unirlos en cadenas.
cid = '.'.join(serialized['id'])
if cid != 'langchain.chains.llm.LLMChain':
self.progress_bar.progress(value=self.prog_map[cid], text=f'Running Chain `{cid}`...')
self.prog_value = self.prog_map[cid]
else:
self.prog_value += 0.1
self.progress_bar.progress(value=self.prog_value, text=f'Running Chain `{cid}`...')
def on_chain_end(self, outputs, **kwargs) -> None:
pass
Ahora tu aplicación tendrá una bonita barra de progreso como la nuestra.

# En conclusión
¡Así es como se debe construir una aplicación de LLM con LangChain!
Hoy hemos proporcionado una breve descripción general de cómo construir una aplicación de LLM simple que chatea con el VectorStore de MyScale, y también hemos explicado cómo utilizar las cadenas en el pipeline de consulta.
Esperamos que este artículo te ayude cuando diseñes la arquitectura de tu aplicación basada en LLM desde cero.
También puedes pedir ayuda en nuestro servidor de Discord (opens new window). Estaremos encantados de ayudarte, ya sea con bases de datos vectoriales, aplicaciones de LLM u otras cosas fantásticas. ¡También puedes utilizar nuestra base de datos abierta para construir tus propias aplicaciones! ¡Creemos que puedes hacer aplicaciones más increíbles con este recuperador de autoconsulta con MyScale! ¡Feliz codificación!
¡Nos vemos en el siguiente artículo!