
随着数据量和复杂性的不断增长,可扩展的NoSQL数据库解决方案正成为传统关系型数据库的热门替代方案。其中一种备受关注的类型是矢量数据库。矢量数据库承诺通过高维矢量搜索而不是传统的SQL查询来组织和检索数据,从而提供先进的语义搜索能力,根据数据的含义和相似性进行操作。
在选择矢量数据库之前,您需要仔细考虑一些关键因素,以确保它能够满足您当前和未来的应用和分析需求。这就是我们将在本博客中讨论的内容。这些因素分为三个主要类别:矢量数据库的核心功能、操作考虑因素以及可用性和生态系统。让我们开始吧!
# 核心功能
矢量数据库的核心功能包括性能、索引方法、查询语言和API支持,以及数据模型和架构。
# 性能
在选择矢量数据库时,性能至关重要,因为它确保应用程序运行平稳,便于高效搜索相似项、最近邻矢量和数据分析。矢量数据库的性能可以通过以下因素来衡量:
- 每秒查询数(QPS): 这衡量了数据库每秒可以处理多少个查询。较高的QPS意味着数据库可以支持更多并发搜索,这对于需要实时数据分析或用户交互的应用程序至关重要。
- 平均查询延迟: 这是指数据库在进行查询后返回结果所需的时间。较低的延迟可以确保应用程序感觉更快,对用户更具响应性,提升整体用户体验。
- 数据导入时间: 新数据可以添加到数据库的速度非常重要,特别是在数据不断更新的动态环境中。高效的数据导入可以确保数据库始终是最新的,并准备好进行查询。
与其他矢量数据库相比,MyScaleDB具有出色的性能。对于较大的数据集,MyScaleDB在LAION 5M数据集上报告了增强的性能 (opens new window),在x1 pod上实现了390 QPS(每秒查询数),达到了95%的召回率,并保持了平均查询延迟为18ms。
MyScaleDB在数据导入时间方面也优于其他矢量数据库,完成了对5M数据点的任务,仅用了将近30分钟的时间。如果您注册,您可以免费使用x1 pod,该pod可以处理高达500万个矢量。
相关文章: MyScale如何胜过其他专门的矢量数据库? (opens new window)
# 索引方法
矢量数据库的关键在于它如何处理高维矢量数据。不同的矢量数据库使用不同的索引方法,以确保数据可以快速准确地被找到,保持整体组织和高效。以下是矢量数据库中常见的一些索引方法:
- k-d树是用于索引k维空间中的点的树结构。它们对于多维数据(如矢量)特别有用。k-d树将空间划分为区域,便于快速最近邻搜索。
- 球树类似于k-d树,但适用于具有可变密度的数据集。它们通过将数据集封装在超球体中来表示数据集,适用于最近邻搜索等应用。
- **局部敏感哈希(LSH)**是一种概率方法,用于将输入项哈希到具有高概率映射到相同桶中的相似项。它适用于近似相似性搜索,适用于推荐系统等应用。
- 基于图的索引将数据表示为图,其中节点和边被表示为矢量和关系。这种索引有助于捕捉复杂关系,通常用于社交网络分析等应用。
- 倒排文件(IVF)矢量索引是一种在高维矢量空间中进行高效相似性搜索的方法,使用聚类将矢量划分为Voronoi单元,其中每个单元对应一个质心,并构建倒排索引以在查询期间快速定位给定单元内的矢量。
- **产品量化(PQ)**方法将矢量划分为较小的子矢量,并独立地量化它们。它适用于高维数据,并常用于图像检索应用。PQ可以与基于图的索引以及IVF有效地结合使用。
- 空间哈希将矢量空间划分为单元格,并根据其位置将每个矢量分配给一个单元格。这种方法适用于空间查询,并常用于计算机图形学和计算机辅助设计。
许多算法在处理大规模数据集时面临限制,特别是当索引大小显著增加时,需要将所有矢量数据存储在内存中。多尺度树图(MSTG) (opens new window)是由MyScaleDB开发的,它通过将分层树聚类与图遍历以及内存与快速NVMe SSD相结合,克服了这些限制。MSTG显著降低了IVF/HNSW的资源消耗,同时保持了出色的性能。它构建快速,搜索快,而且在不同的过滤搜索比率下保持快速和准确,同时资源和成本效益高。
# 查询语言和API支持
查询语言和应用程序编程接口(API)支持定义了用户与数据库的交互方式和信息检索方式。它们是评估矢量数据库是否用户友好、适应性强且能够无缝集成到各种技术生态系统中的关键因素。这些组件使用户能够通过与数据库交互来提取有价值的见解,实现流畅有效的数据管理体验。
MyScaleDB是一种全功能矢量数据库,完全兼容SQL,不仅简化了复杂的数据操作、语义搜索和结构化数据查询,还使其成为几乎所有开发人员都可以利用现有的SQL知识开始使用矢量数据库并处理数据任务的理想选择。同时,MyScaleDB的API支持实现了与其他系统的自动化和集成。
# 数据模型和架构
矢量数据库的数据模型和架构是其存储和访问数据的蓝图,这影响存储效率、查询性能、可扩展性和开发人员体验。MyScaleDB使用混合数据模型,结合了结构化数据和矢量数据表示的优势,这意味着它可以有效地存储表格数据(如传统数据库)和高维矢量数据。
# 操作考虑因素
让我们讨论矢量数据库的可扩展性、安全性和监控作为操作考虑因素。
# 可扩展性
可扩展性是指数据库在不降低性能或功能的情况下处理不断增长的数据量和用户需求的能力。在矢量数据库中,有两种类型的扩展:垂直扩展和水平扩展。垂直扩展意味着扩展硬件和软件的计算能力。而水平扩展则是添加额外的服务器节点。这对于未来保护您的矢量数据库并确保它能够支持您的AI应用的增长至关重要。MyScaleDB提供了垂直扩展。
# 安全性
矢量数据库中的安全性包含保护数据本身和数据库系统功能的各个方面。在选择矢量数据库时,要寻找诸如加密、访问控制、身份验证机制、网络安全和灾难恢复等功能,因为它们是保护数据安全的数字屏障。
MyScaleDB被像您这样的团队和组织所信任,原因有很多。
- MyScaleDB在完全托管和安全的AWS基础设施上运行多租户Kubernetes集群。
- 它确保客户数据存储在隔离的容器中。
- 除了API服务调用之外,严禁访问您的数据。
- MyScaleDB专门监控操作指标以保持系统的健康和性能。
- MyScaleDB已经达到了SOC 2 Type 1合规性,符合世界顶级的信息安全标准。
# 监控
监控在选择矢量数据库时起着至关重要的作用,原因有很多。它为我们提供了洞察和进度跟踪,以便及时做出性能优化、持续改进和适应性方面的决策。
MyScaleDB提供全面的监控工具,可跟踪性能指标、资源利用率和安全事件,实时提供有关数据库健康和活动的见解。
相关文章: 通过检索增强生成实现性能提升 (opens new window)
# 可用性和生态系统
可用性和生态系统包括定价、文档、社区、支持和生态系统集成。
# 社区和支持
社区支持在有效使用矢量数据库方面起着至关重要的作用。它赋予用户权力,鼓励协作,并为各种应用和行业中的矢量数据库实现的持续改进和成功做出贡献。它还有助于调试问题并提出查询以进行澄清。MyScaleDB通过Discord (opens new window)、Twitter (opens new window)、LinkedIn (opens new window)和Medium (opens new window)等多个渠道提供全面的支持。您可以通过这些渠道及时获得MyScaleDB技术专家的回应。
# 定价
定价是选择矢量数据库的主要因素。对定价的清晰理解可以确保与矢量数据库的成本效益和可持续关系。了解不同数据库提供的定价模型,并评估其与您的预算和使用需求的一致性。
MyScaleDB提供多种定价选项 (opens new window),包括为小型应用程序提供的免费服务。它还提供标准套餐用于AI服务和企业套餐用于大型组织。MyScaleDB将存储和计算分开计费,这意味着只有在运行查询时才收取计算费用。最近,MyScaleDB推出了一个新的容量优化的pod,仅需每月68美元,可以容纳1000万个768维矢量,让您轻松创建功能强大的GenAI应用程序而不会让您破产。
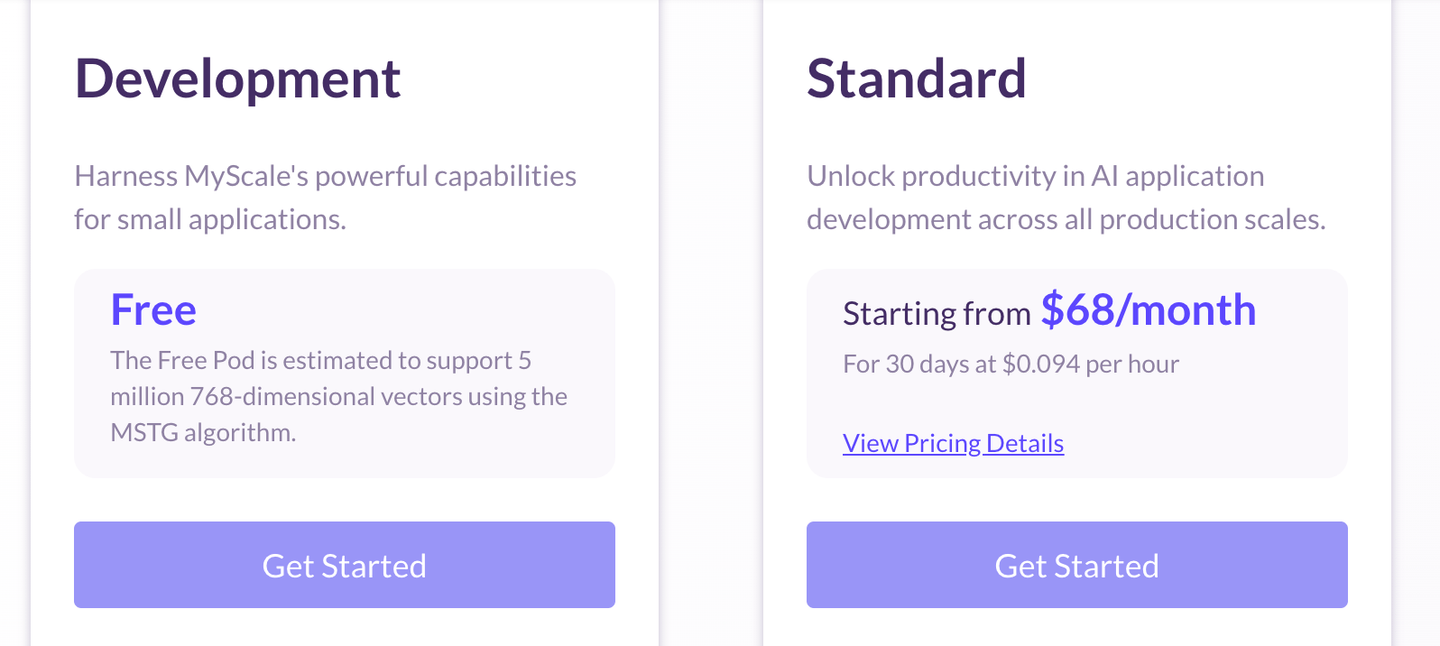
如果您对数据矢量的大小有估计,您还可以使用价格估算器计算价格。
# 生态系统集成
让我们讨论以下生态系统集成:
开发者工具:开发者工具在选择适合您的项目的正确矢量数据库时至关重要。它可以通过集成您熟悉的现有开发者工具来提高生产力和效率。MyScaleDB已经集成了各种开发者工具,如Python客户端 (opens new window)、Node.js (opens new window)、Go客户端 (opens new window)、ClientJDBC驱动程序 (opens new window)和HTTPS接口 (opens new window)。
大型语言模型(LLM):LLM集成通过解锁高级语义搜索、数据的语境化、个性化推荐、知识增强和对话界面等功能,显著扩展了矢量数据库的能力。MyScaleDB提供多种LLM集成,包括OpenAI (opens new window)、LangChain (opens new window)、LangChain JS/TS (opens new window)和LlamaIndex (opens new window)。
相关文章: 使用矢量数据库进行高级Facebook事件数据分析 (opens new window)
# 文档
详细文档的可用性在选择矢量数据库时非常重要。它有助于理解功能、高效开发、集成、长期支持,并确保平滑的学习曲线。
MyScaleDB提供广泛而详细的文档,包括用户指南 (opens new window)、教程 (opens new window)、博客 (opens new window)、示例应用 (opens new window)和API集成 (opens new window)文档,以及Discord和Twitter等活跃的支持渠道。

# 比较
让我们将MyScaleDB与一些热门的矢量数据库进行比较。
| 功能 | MyScaleDB | Pinecone | Weaviate | Milvus | Qdrant |
|---|---|---|---|---|---|
| 开源 | 是 | 否 | 是 | 是 | 是 |
| SQL | 是 | 否 | 否 | 否 | 否 |
| 云部署 | 是 | 是 | 是 | 是 | 是 |
| 查询语言 | SQL和SDK | SDK | GraphQL | C++、Python SDK | SDK |
| LLM集成 | Llamalindex、LangChain | Llamalindex、LangChain | Llamalindex、LangChain | Llamalindex、LangChain | Llamalindex、LangChain |
| 费用 | 免费和付费套餐 | 付费套餐 | 14天免费和付费套餐 | 付费套餐 | 免费和付费套餐 |
# 结论
选择正确的矢量数据库并不容易,我们已经讨论了在选择任何矢量数据库之前可以考虑的不同因素,包括涵盖核心功能、操作考虑因素、可用性和生态系统集成的三个主要类别。
此外,如果高效处理大规模数据量和处理数据复杂性是您的首要选择标准,请考虑使用MyScaleDB。通过结合ClickHouse和MSTG算法的优势,MyScaleDB在速度和精度上为复杂和大规模的矢量搜索提供了具有成本效益的解决方案。
您还可以在以下内容中找到MyScaleDB与其他竞争对手之间的基准报告:



